
Processar documentos com o analisador de layout do Gemini
O analisador de layout da Document AI é um serviço avançado de análise de texto e compreensão de documentos que converte conteúdo não estruturado de arquivos complexos em informações altamente estruturadas, precisas e legíveis por máquina. Ele combina os modelos especializados de reconhecimento óptico de caracteres (OCR, na sigla em inglês) do Google com os recursos de IA generativa do Gemini. Ele entende a estrutura completa do documento, identificando elementos como tabelas, figuras, listas e cabeçalhos, preservando as relações contextuais entre eles, como quais parágrafos pertencem a qual cabeçalho.
Ele foi projetado para resolver um problema crítico para a pesquisa e a geração aumentada de recuperação (RAG, na sigla em inglês): o OCR padrão achata os documentos, destruindo o contexto e a estrutura que adicionam significado valioso, como cabeçalhos, tabelas e listas.
Principais casos de uso
- OCR de documentos:ele pode analisar texto e elementos de layout, como cabeçalho, cabeçalho, rodapé, estrutura de tabela e figuras de documentos PDF.
- Pesquisa e RAG de alta fidelidade:o uso principal é preparar documentos para pipelines de pesquisa e RAG. Ao criar blocos com reconhecimento de contexto, ele melhora muito a qualidade da recuperação e a precisão das respostas geradas.
- Ingestão de dados estruturados: ele pode analisar documentos complexos (como arquivos ou relatórios 10-K) e indexar conteúdo estruturado (como tabelas analisadas ou descrições de imagens) em bancos de dados, conforme demonstrado com o BigQuery.
Como funciona
O analisador de layout do Gemini processa documentos em um pipeline de várias etapas projetado para preservar o significado semântico:
- Analisar e estruturar:o documento é ingerido. Todos os elementos são identificados e organizados em um formato de árvore. Esse campo proto
DocumentLayoutpreserva a hierarquia inerente do documento. - Anotar e verbalizar: Pré-lançamento Os recursos generativos do Gemini são usados para verbalizar elementos visuais complexos. Figuras, gráficos e tabelas são anotados com descrições textuais detalhadas.
- Blocos e aumento:o documento analisado e as anotações são usados para criar blocos semanticamente coerentes. Esses blocos são aumentados com informações contextuais, como os cabeçalhos ancestrais, para garantir que o significado do bloco seja preservado mesmo quando recuperado isoladamente.
Versões do processador
Os seguintes modelos estão disponíveis para o analisador de layout. Para mudar as versões do modelo, consulte Gerenciar versões do processador.
Para fazer uma Solicitação de Aumento de Cota (QIR, na sigla em inglês) para a cota padrão de processador, siga as etapas em Gerenciar sua cota.
| Versão do modelo | Descrição | Canal de lançamento | Data de lançamento |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
Versão de disponibilidade geral para análise de layout de documentos. Essa é a versão padrão do processador pré-treinado. | Estável | 3 de junho de 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
Versão de pré-lançamento com tecnologia do LLM Gemini 2.5 Flash para melhor análise de layout em arquivos PDF. Recomendado para quem quer testar novas versões. | Versão candidata a lançamento | 25 de agosto de 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Versão de pré-lançamento com tecnologia do LLM Gemini 2.5 Pro para melhor análise de layout em arquivos PDF. A versão 1.5-pro tem latência maior que a 1.5. | Versão candidata a lançamento | 25 de agosto de 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Versão de pré-lançamento com tecnologia do LLM Gemini 3.0 Pro. | Versão candidata a lançamento | 1º de dezembro de 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
Versão de pré-lançamento com tecnologia do LLM Gemini 3.0 Flash. | Versão candidata a lançamento | 13 de janeiro de 2026 |
Principais recursos
Nesta documentação, o analisador de layout do Gemini se refere a versões de processador de analisador de layout pré-treinado com base no Gemini, como pretrained-layout-parser-v1.5-2025-08-25 e pretrained-layout-parser-v1.5-pro-2025-08-25. O analisador de layout do Gemini oferece suporte aos seguintes recursos principais.
Análise avançada de tabela
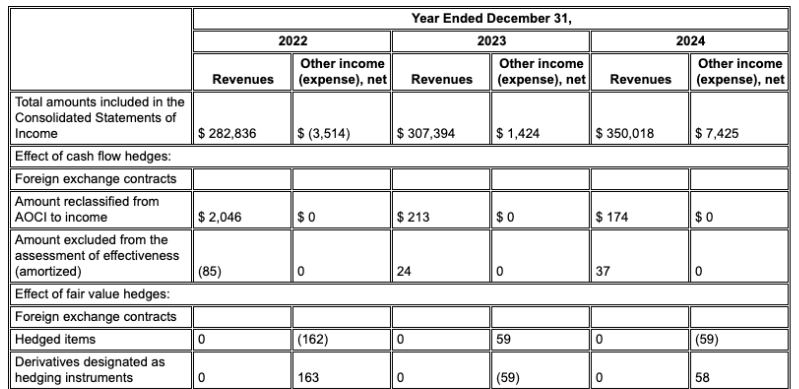
As tabelas em relatórios financeiros ou manuais técnicos são um ponto de falha comum para a RAG. O analisador de layout do Gemini é excelente na extração de dados de tabelas complexas com células mescladas e cabeçalhos complexos.
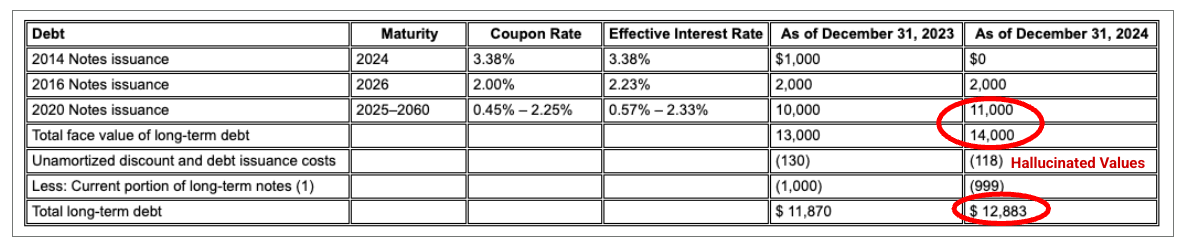
Exemplo: neste arquivo 10-K da Alphabet, o analisador de um concorrente não consegue alinhar corretamente os cabeçalhos e as células, interpretando mal os dados financeiros. O analisador de layout do Gemini analisa com precisão toda a estrutura da tabela, preservando a integridade dos dados.
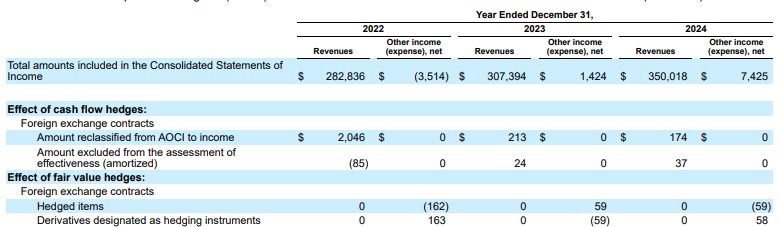
Figura 1. A origem desse documento de entrada é "Alphabet 2024 SEC Form 10-K", página 72.
O analisador do concorrente não detecta corretamente o alinhamento de células e colunas e alucina valores.
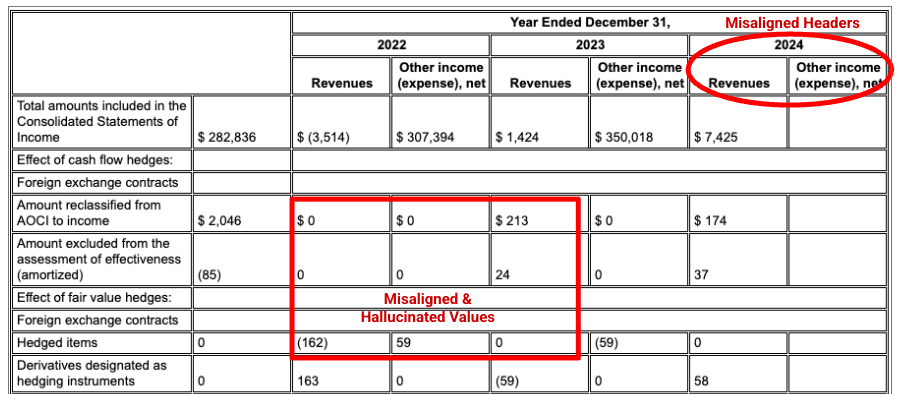
O analisador de layout do Gemini alinha as colunas corretamente e fornece valores precisos.
Redução de alucinações
Ao contrário dos analisadores puros baseados em LLM que tentam ler textos que não existem, a base do analisador de layout do Gemini no OCR avançado o fundamenta no conteúdo real do documento. Isso leva a um número significativamente menor de alucinações.
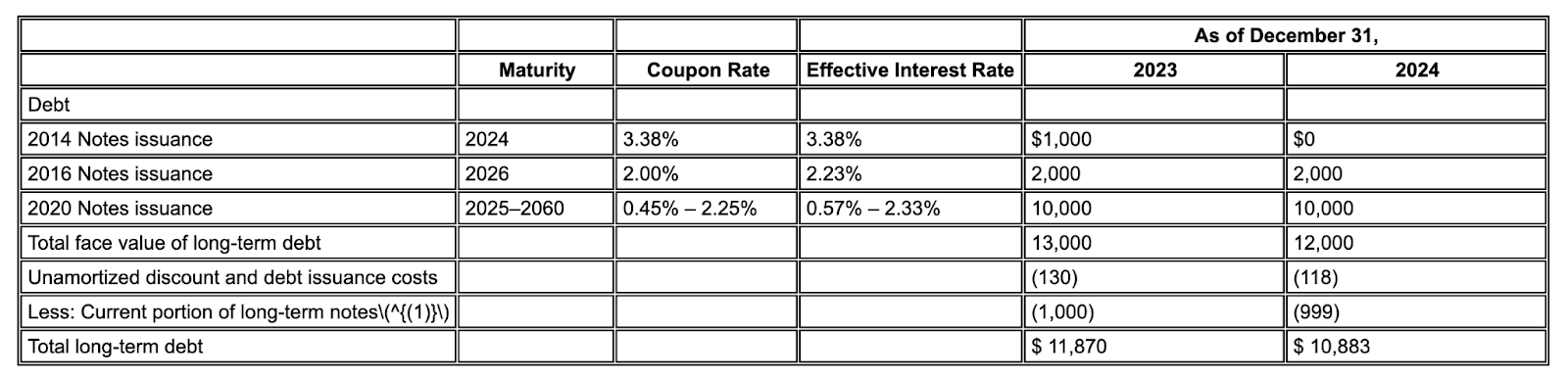
Exemplo: neste trecho 10-K, um modelo concorrente alucina e insere texto incorreto. O analisador de layout do Gemini fornece uma extração limpa e precisa de apenas o texto presente na página.
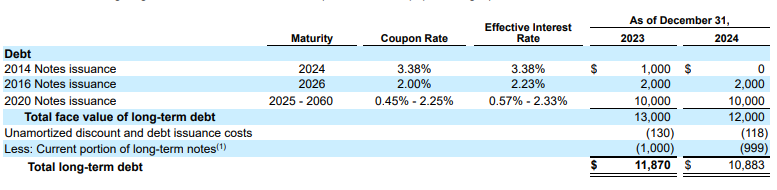
Figura 2. Documento de entrada (Alphabet 2024 10k p75)
Os modelos concorrentes vão alucinar valores.
O analisador de layout do Gemini identifica corretamente os valores em imagens e tabelas.
Blocos com reconhecimento de layout
Os analisadores padrão geralmente criam blocos removidos do contexto original, separando um parágrafo do cabeçalho. O analisador de layout do Gemini entende a hierarquia do documento. Ele cria blocos com reconhecimento de contexto que incluem conteúdo de cabeçalhos ancestrais e cabeçalhos de tabela. Um bloco recuperado contém não apenas o texto, mas também o contexto estrutural necessário para uma resposta precisa do LLM.
Figura 3. A origem dessa imagem é "Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis", de Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco e Michalis Raptis.
Anotação de layout
A anotação do analisador de layout pode identificar se há imagens ou tabelas em documentos analisados. Quando encontrados, eles são anotados como um bloco de texto descritivo com as informações representadas na imagem e na tabela.
Por exemplo, ao processar um relatório bancário, o analisador não vê apenas uma imagem. Ele gera uma descrição detalhada e extrai os pontos de dados de todos os três gráficos de pizza, disponibilizando esses dados para recuperação.
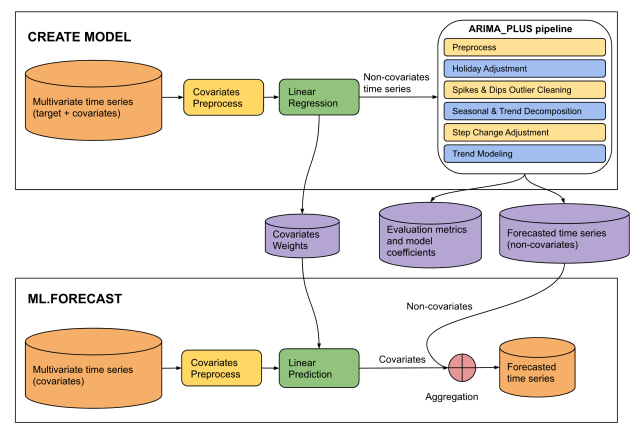
Figura 4. A origem dessa entrada é um PDF salvo de "A instrução CREATE MODEL para modelos ARIMA_ PLUS_XREG" no site do Google Cloud.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
Limitações
Considere as seguintes limitações:
- Processamento on-line:
- Tamanho máximo do arquivo de entrada de 20 MB para todos os tipos de arquivo
- Máximo de 15 páginas por arquivo PDF
- Processamento em lote:
- Tamanho máximo de arquivo único de 1 GB para arquivos PDF
- Máximo de 500 páginas por arquivo PDF
Detecção de layout por tipo de arquivo
A tabela a seguir lista os elementos que o analisador de layout pode detectar por tipo de arquivo de documento.
| Tipo de arquivo | Tipo MIME | Elementos detectados | Limitações |
|---|---|---|---|
| HTML | text/html |
parágrafo, tabela, lista, título, cabeçalho, cabeçalho de página, rodapé da página | A análise depende muito das tags HTML. Portanto, a formatação baseada em CSS pode não ser capturada. |
application/pdf |
figura, parágrafo, tabela, título, cabeçalho, cabeçalho de página, rodapé da página | As tabelas que abrangem várias páginas podem ser divididas em duas tabelas. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
parágrafo, tabelas em várias páginas, lista, título, elementos de cabeçalho | Tabelas aninhadas são indisponíveis. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
parágrafo, tabela, lista, título, elementos de cabeçalho | Para que os cabeçalhos sejam identificados com precisão, eles precisam ser marcados como tal no arquivo do PowerPoint. Tabelas aninhadas e slides ocultos são indisponíveis. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
tabelas em planilhas do Excel, com suporte a INT,
FLOAT, e STRING valores |
A detecção de várias tabelas está indisponível. Planilhas, linhas ou colunas ocultas também podem afetar a detecção. É possível processar arquivos com até 5 milhões de células. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
planilha com macro ativada, com suporte a valores INT,
FLOAT, e STRING |
A detecção de várias tabelas está indisponível. Planilhas, linhas ou colunas ocultas também podem afetar a detecção. |
A seguir
- Consulte a lista de processadores.
- Crie um classificador personalizado.
- Use o Enterprise Document OCR para detectar e extrair texto.
- Consulte Enviar uma solicitação de documentos de processo em lote para saber como processar respostas.