
עיבוד מסמכים באמצעות כלי לניתוח פריסות של Gemini
כלי ניתוח הפריסה של Document AI הוא שירות מתקדם לניתוח טקסט ולהבנת מסמכים, שממיר תוכן לא מובנה מקבצים מורכבים למידע מובנה, מדויק וקריא למחשב. הוא משלב בין מודלים מיוחדים של Google לזיהוי תווים אופטי (OCR) לבין יכולות ה-AI הגנרטיבי של Gemini. הוא מבין את המבנה המלא של המסמך ומזהה אלמנטים כמו טבלאות, איורים, רשימות וכותרות, תוך שמירה על הקשרים ביניהם, למשל אילו פסקאות שייכות לאיזו כותרת.
הוא נועד לפתור בעיה קריטית בחיפוש וב-Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG): טכנולוגיית OCR רגילה משטחת מסמכים, וכך הורסת את ההקשר והמבנה שמוסיפים משמעות חשובה, כמו כותרות, טבלאות ורשימות.
תרחישים עיקריים לדוגמה
- זיהוי תווים אופטי (OCR) במסמכים: הוא יכול לנתח טקסט ורכיבי פריסה כמו כותרת, כותרת עליונה, כותרת תחתונה, מבנה טבלה ואיורים ממסמכי PDF.
- חיפוש באיכות גבוהה ו-RAG: השימוש העיקרי בו הוא הכנת מסמכים לחיפוש ולצינורות RAG. היכולת הזו משפרת באופן משמעותי את איכות השליפה ואת הדיוק של התשובות שנוצרות.
- הטמעה של נתונים מובְנים: הוא יכול לנתח מסמכים מורכבים (כמו דוחות או מסמכי 10-K) ולבצע אינדוקס של תוכן מובנה (כמו טבלאות מנותחות או תיאורי תמונות) במסדי נתונים, כמו שמוצג ב-BigQuery.
איך זה עובד?
מנתח הפריסה של Gemini מעבד מסמכים בצינור רב-שלבי שנועד לשמר את המשמעות הסמנטית:
- ניתוח ומבנה: המסמך מוזן למערכת. כל הרכיבים מזוהים ומאורגנים בפורמט של עץ. שדה הפרוטו
DocumentLayoutהזה שומר על ההיררכיה הטבועה במסמך. - הערות והסברים: תצוגה מקדימה יכולות ה-AI הגנרטיבי של Gemini משמשות להסבר מילולי של רכיבים ויזואליים מורכבים. הערות מפורטות בטקסט מתווספות לתרשימים, לטבלאות ולנתונים.
- חלוקה לחלקים והגדלה: המסמך המנותח וההערות שלו משמשים ליצירת חלקים בעלי קוהרנטיות סמנטית. החלקים האלה מועשרים במידע הקשרי, כמו כותרות האב שלהם, כדי להבטיח שהמשמעות של החלק תישמר גם אם הוא יאוחזר בנפרד.
גרסאות המעבד
אלה המודלים שזמינים לניתוח פריסה. כדי לשנות את גרסאות המודלים, אפשר לעיין במאמר בנושא ניהול גרסאות המעבד.
כדי להגיש בקשה להגדלת מכסה (QIR) למכסת ברירת המחדל של המעבד, פועלים לפי השלבים במאמר ניהול המכסה.
| גרסת המודל | תיאור | ערוץ הפצה | תאריך הפצה |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
גרסה זמינה לכלל המשתמשים לניתוח פריסת מסמכים. זוהי גרסת ברירת המחדל של המעבד שעבר אימון מראש. | יציב | 3 ביוני 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
גרסת טרום-השקה (Preview) שמבוססת על מודל שפה גדול (LLM) של Gemini 2.5 Flash, לניתוח טוב יותר של פריסות בקובצי PDF. מומלץ למי שרוצה להתנסות בגרסאות חדשות. | גרסה מועמדת להפצה | 25 באוגוסט 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
גרסת טרום-השקה שמבוססת על מודל שפה גדול (LLM) של Gemini 2.5 Pro לניתוח טוב יותר של פריסות בקובצי PDF. זמן האחזור בגרסה 1.5-pro גבוה יותר מאשר בגרסה 1.5. | גרסה מועמדת להפצה | 25 באוגוסט 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
גרסת טרום-השקה (Preview) שמבוססת על מודל שפה גדול (LLM) של Gemini 3.0 Pro. | גרסה מועמדת להפצה | 1 בדצמבר 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
גרסת טרום-השקה שמבוססת על מודל שפה גדול (LLM) של Gemini 3.0 Flash. | גרסה מועמדת להפצה | 13 בינואר 2026 |
יכולות עיקריות
בהמשך המסמך הזה, Gemini layout parser מתייחס לגרסאות של מעבד Gemini מבוסס-מודל מאומן מראש לניתוח פריסות, כמו pretrained-layout-parser-v1.5-2025-08-25 ו-pretrained-layout-parser-v1.5-pro-2025-08-25. מנתח הפריסה של Gemini תומך ביכולות המרכזיות הבאות.
ניתוח מתקדם של טבלאות
טבלאות בדוחות פיננסיים או במדריכים טכניים הן נקודת כשל נפוצה ב-RAG. מנתח הפריסה של Gemini מצטיין בחילוץ נתונים מטבלאות מורכבות עם תאים ממוזגים וכותרות מורכבות.
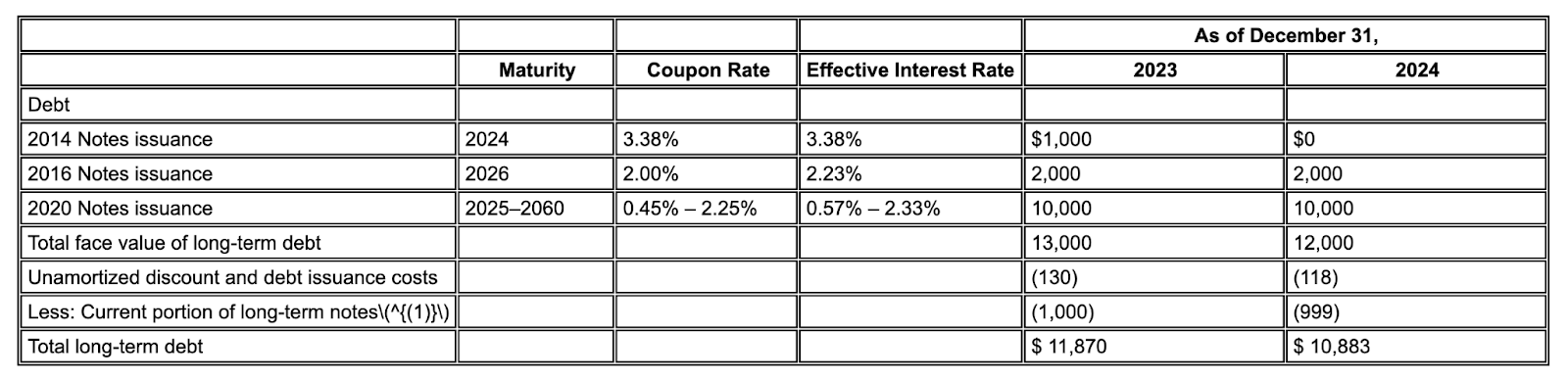
דוגמה: בדוח 10-K של Alphabet, מנתח (parser) של מתחרה לא מצליח ליישר כראוי את הכותרות והתאים, ומפרש לא נכון את הנתונים הפיננסיים. מנתח הפריסה של Gemini מנתח בצורה מדויקת את כל מבנה הטבלה, ושומר על שלמות הנתונים.
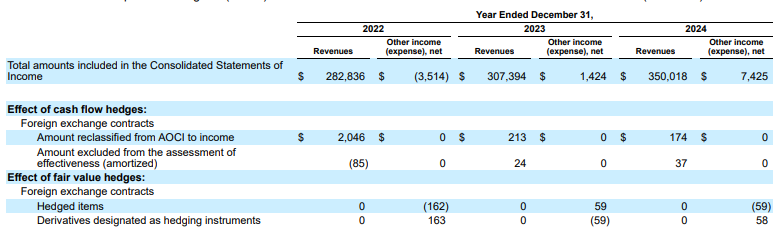
איור 1. המקור של מסמך הקלט הזה הוא Alphabet 2024 SEC Form 10-K, עמוד 72.
הכלי לניתוח נתוני מתחרים לא מזהה בצורה נכונה את היישור של התאים והעמודות, ומציג ערכים שגויים.
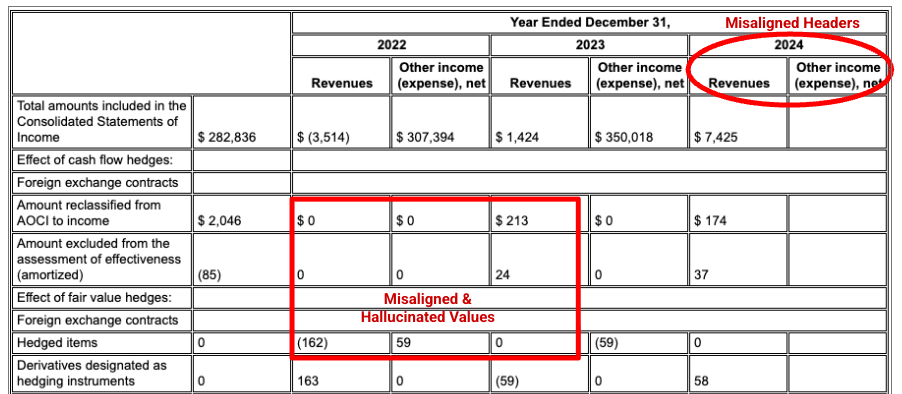
מנתח הפריסה של Gemini מיישר את העמודות בצורה נכונה ומספק ערכים מדויקים.
הזיות מופחתות
בניגוד למנתחי פריסה שמבוססים על LLM בלבד ומנסים לקרוא טקסט שלא קיים, מנתח הפריסה של Gemini מבוסס על OCR מתקדם, ולכן הוא מתבסס על התוכן בפועל של המסמך. התוצאה היא הרבה פחות הזיות.
דוגמה: בקטע הזה מתוך דוח 10-K, מודל של מתחרה מבצע הזיה ומוסיף טקסט שגוי. כלי הניתוח של פריסת Gemini מספק חילוץ נקי ומדויק של הטקסט שמופיע בדף בלבד.
איור 2. מסמך קלט (Alphabet 2024 10k p75)
מודלים של מתחרים יפיקו ערכים הזויים.
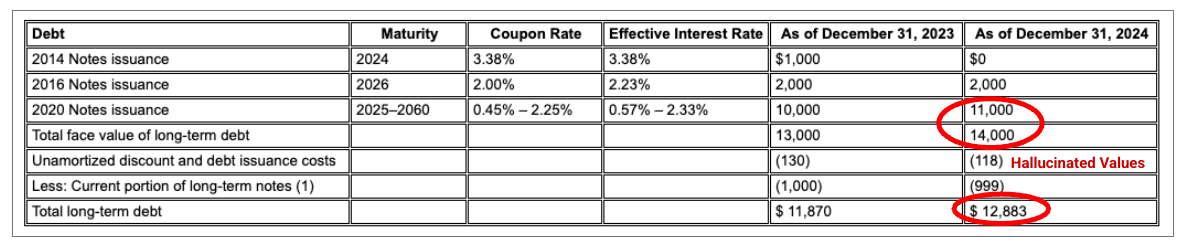
מנתח הפריסה של Gemini מזהה ערכים בתמונות ובטבלאות בצורה נכונה.
חלוקה לחלקים בהתאם לפריסה
מנתחי נתונים רגילים יוצרים לעיתים קרובות נתחים שמוסרים מההקשר המקורי שלהם, ומפרידים בין פסקה לכותרת שלה. מנתח הפריסה של Gemini מבין את ההיררכיה של המסמך. הוא יוצר נתחים מודעים-הקשר שכוללים תוכן מכותרות ראשיות ומכותרות של טבלאות. חלק מאוחזר מכיל לא רק את הטקסט, אלא גם את ההקשר המבני שדרוש לתשובה מדויקת של מודל שפה גדול (LLM).
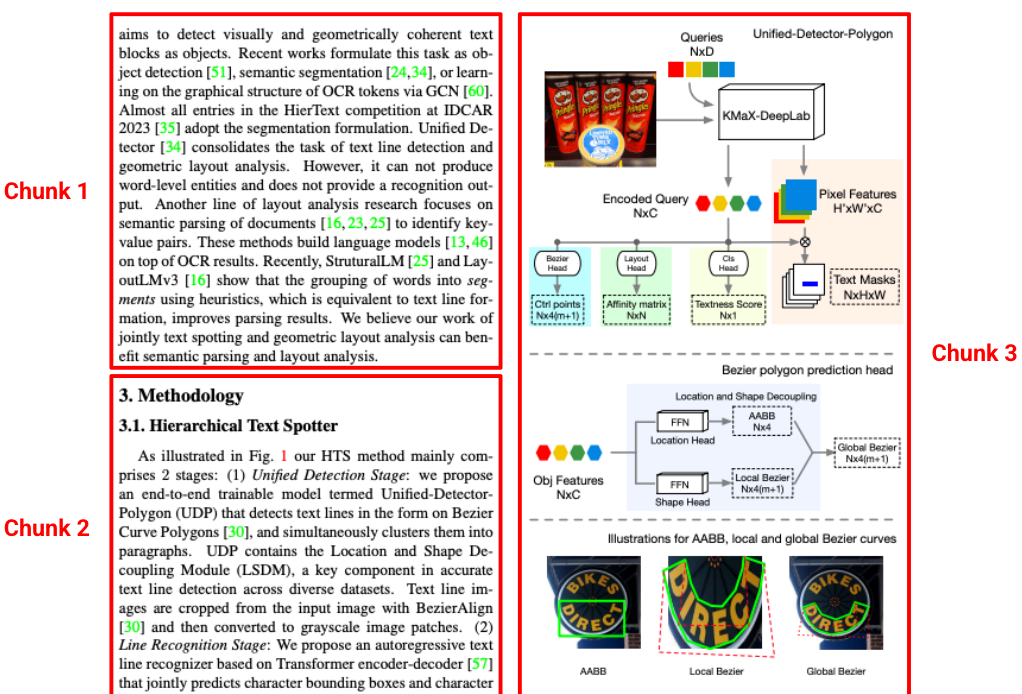
איור 3. מקור התמונה הוא מתוך המאמר Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis מאת Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco ו-Michalis Raptis.
הערה לגבי פריסה
הערות של מנתח פריסות יכולות לזהות אם יש תמונות או טבלאות במסמכים מנותחים. כשהם נמצאים, הם מסומנים כבלוק טקסט תיאורי עם המידע שמוצג בתמונה ובטבלה.
לדוגמה, כשמעבדים דוח בנק, מנתח התוכן לא רואה רק תמונה. הוא יוצר תיאור מפורט ושולף את נקודות הנתונים מכל שלושת תרשימי העוגה, כך שהנתונים האלה יהיו זמינים לאחזור.
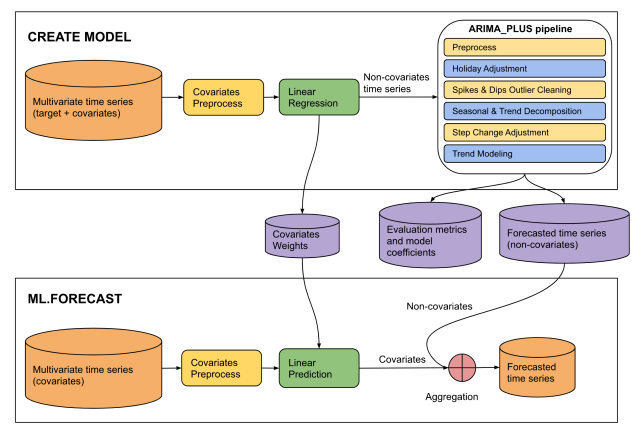
איור 4. המקור של הקלט הזה הוא קובץ PDF שמור של הצהרת CREATE MODEL למודלים של ARIMA_ PLUS_XREG באתר Google Cloud.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
מגבלות
ההגבלות הבאות חלות:
- עיבוד אונליין:
- גודל הקובץ המקסימלי הוא 20MB לכל סוגי הקבצים
- עד 15 עמודים לכל קובץ PDF
- עיבוד באצווה:
- גודל קובץ PDF מקסימלי של 1GB
- עד 500 דפים לכל קובץ PDF
זיהוי פריסה לפי סוג קובץ
בטבלה הבאה מפורטים האלמנטים שמנתח הפריסה יכול לזהות לפי סוג קובץ המסמך.
| סוג קובץ | סוג MIME | רכיבים שזוהו | מגבלות |
|---|---|---|---|
| HTML | text/html |
paragraph, table, list, title, heading, page header, page footer | חשוב לדעת שהניתוח מסתמך במידה רבה על תגי HTML, ולכן יכול להיות שעיצוב מבוסס-CSS לא יתועד. |
application/pdf |
figure, paragraph, table, title, heading, page header, page footer | יכול להיות שטבלאות שמתפרסות על פני כמה דפים יפוצלו לשתי טבלאות. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
פסקה, טבלאות בכמה דפים, רשימה, כותרת, אלמנטים של כותרת | אין תמיכה בטבלאות שהן רכיב בתוך רכיב. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
paragraph, table, list, title, heading elements | כדי שהכותרות יזוהו בצורה מדויקת, צריך לסמן אותן ככותרות בקובץ PowerPoint. אין תמיכה בטבלאות מוטמעות ובשקפים מוסתרים. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
טבלאות בגיליונות אלקטרוניים של Excel, עם תמיכה בערכים INT,
FLOAT ו-STRING |
אין תמיכה בזיהוי של כמה טבלאות. יכול להיות שגם גיליונות, שורות או עמודות מוסתרים ישפיעו על הזיהוי. אפשר לעבד קבצים עם עד 5 מיליון תאים. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
גיליון אלקטרוני עם מאקרו מופעל, שתומך בערכים INT,
FLOAT ו-STRING |
אין תמיכה בזיהוי של כמה טבלאות. יכול להיות שגם גיליונות, שורות או עמודות מוסתרים ישפיעו על הזיהוי. |
המאמרים הבאים
- רשימת המעבדים
- יוצרים מסווג תוכן מותאם אישית.
- אפשר להשתמש ב-Enterprise Document OCR כדי לזהות ולחלץ טקסט.
- כדי לדעת איך לטפל בתשובות, אפשר לעיין במאמר בנושא שליחת בקשה לעיבוד קבוצת מסמכים.