
Traiter des documents avec l'analyseur de mise en page de Gemini
L'analyseur de mise en page de Document AI est un service avancé d'analyse de texte et de compréhension de documents qui convertit le contenu non structuré de fichiers complexes en informations très structurées, précises et lisibles par machine. Il combine les modèles spécialisés de reconnaissance optique de caractères (OCR) de Google avec les capacités d'IA générative de Gemini. Il comprend la structure complète du document, en identifiant des éléments tels que les tableaux, les figures, les listes et les en-têtes, tout en préservant les relations contextuelles entre eux, par exemple les paragraphes qui appartiennent à un en-tête.
Il est conçu pour résoudre un problème essentiel pour la recherche et la génération augmentée de récupération (RAG) : l'OCR standard aplatit les documents, détruisant le contexte et la structure qui ajoutent une signification précieuse, comme les en-têtes, les tableaux et les listes.
Cas d'utilisation principaux
- OCR de documents : il peut analyser le texte et les éléments de mise en page tels que les titres, les en-têtes, les pieds de page, la structure des tableaux et les figures à partir de documents PDF.
- Recherche et RAG haute fidélité : son utilisation principale consiste à préparer des documents pour les pipelines de recherche et de RAG. En créant des blocs sensibles au contexte, il améliore considérablement la qualité de la récupération et la précision des réponses générées.
- Ingestion de données structurées : il peut analyser des documents complexes (tels que des dépôts 10-K ou des rapports) et indexer du contenu structuré (comme des tableaux analysés ou des descriptions d'images) dans des bases de données, comme illustré avec BigQuery.
Fonctionnement
L'analyseur de mise en page de Gemini traite les documents dans un pipeline en plusieurs étapes conçu pour préserver la signification sémantique :
- Analyse et structure : le document est ingéré. Tous les éléments sont identifiés et organisés dans un format arborescent. Ce
DocumentLayoutchamp proto préserve la hiérarchie inhérente du document. - Annotation et verbalisation : Aperçu Les fonctionnalités génératives de Gemini sont utilisées pour verbaliser des éléments visuels complexes. Les figures, les graphiques et les tableaux sont annotés avec des descriptions textuelles enrichies.
- Blocage et augmentation : le document analysé et ses annotations sont utilisés pour créer des blocs sémantiquement cohérents. Ces blocs sont augmentés avec des informations contextuelles, telles que leurs en-têtes ancestraux, afin de s'assurer que la signification du bloc est préservée même lorsqu'il est récupéré de manière isolée.
Versions des outils de traitement
Les modèles suivants sont disponibles pour l'analyseur de mise en page. Pour modifier les versions des modèles, consultez Gérer les versions de l'outil de traitement.
Pour envoyer une demande d'augmentation de quota (DAQ) pour le quota de l'outil de traitement par défaut, suivez les étapes décrites dans Gérer votre quota.
| Version de modèle | Description | Version disponible | Date de disponibilité |
|---|---|---|---|
pretrained-layout-parser-v1.0-2024-06-03 |
Version en disponibilité générale pour l'analyse de la mise en page des documents. Il s'agit de la version de l'outil de traitement pré-entraînée par défaut. | Stable | 3 juin 2024 |
pretrained-layout-parser-v1.5-2025-08-25 |
Version preview optimisée par le LLM Gemini 2.5 Flash pour une meilleure analyse de la mise en page des fichiers PDF. Recommandée pour ceux qui souhaitent tester de nouvelles versions. | Version candidate | 25 août 2025 |
pretrained-layout-parser-v1.5-pro-2025-08-25 |
Version preview optimisée par le LLM Gemini 2.5 Pro pour une meilleure analyse de la mise en page des fichiers PDF. La latence de la version 1.5-pro est supérieure à celle de la version 1.5. | Version candidate | 25 août 2025 |
pretrained-layout-parser-v1.6-pro-2025-12-01 |
Version preview optimisée par le LLM Gemini 3.0 Pro. | Version candidate | 1er décembre 2025 |
pretrained-layout-parser-v1.6-2026-01-13 |
Version preview optimisée par le LLM Gemini 3.0 Flash. | Version candidate | 13 janvier 2026 |
Capacités clés
Dans la suite de cette documentation, l'analyseur de mise en page de Gemini fait référence aux versions de l'outil de traitement de l'analyseur de mise en page pré-entraîné basées sur Gemini, telles que pretrained-layout-parser-v1.5-2025-08-25 et pretrained-layout-parser-v1.5-pro-2025-08-25. L'analyseur de mise en page de Gemini est compatible avec les fonctionnalités clés suivantes.
Analyse avancée de la table
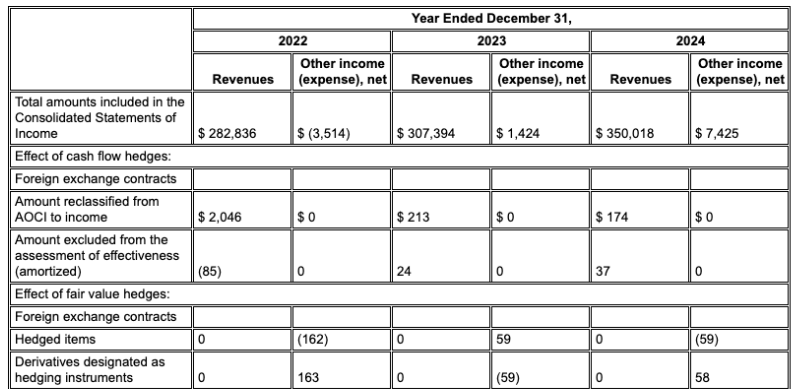
Les tableaux des rapports financiers ou des manuels techniques sont un point de défaillance courant pour le RAG. L'analyseur de mise en page de Gemini excelle dans l'extraction de données à partir de tableaux complexes avec des cellules fusionnées et des en-têtes complexes.
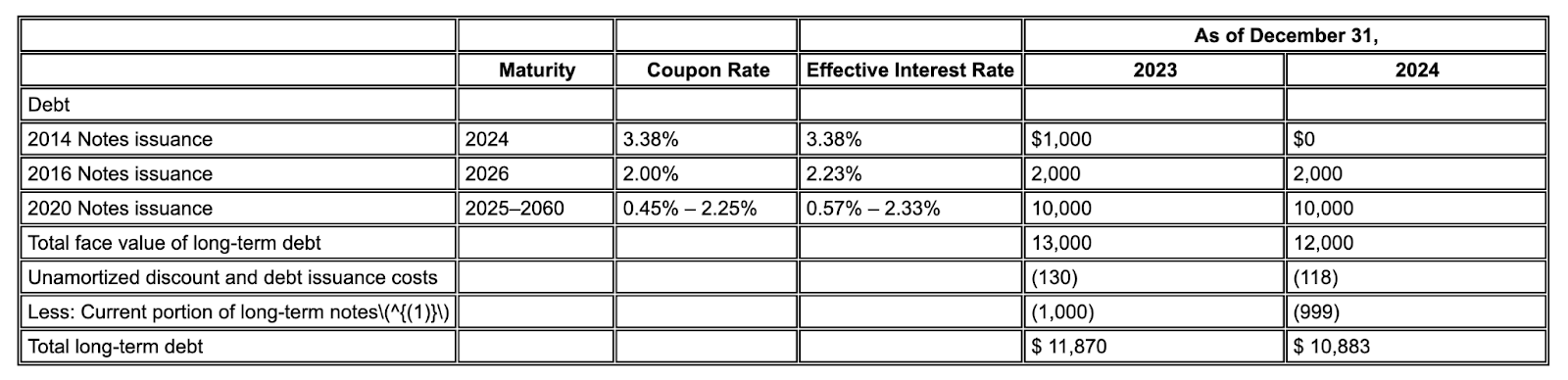
Exemple : Dans ce dépôt 10-K d'Alphabet, l'analyseur d'un concurrent ne parvient pas à aligner correctement les en-têtes et les cellules, ce qui entraîne une mauvaise interprétation des données financières. L'analyseur de mise en page de Gemini analyse avec précision l'ensemble de la structure du tableau, en préservant l'intégrité des données.
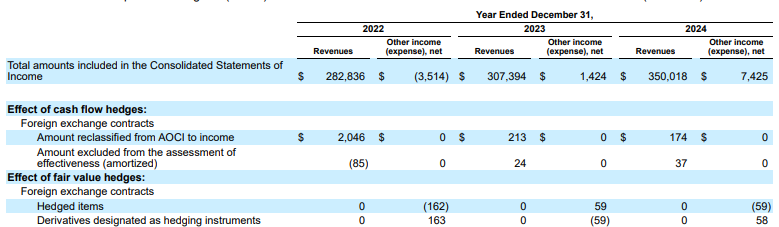
Figure 1 : La source de ce document d'entrée est "Alphabet 2024 SEC Form 10-K", page 72.
L'analyseur du concurrent ne détecte pas correctement l'alignement des cellules et des colonnes, et hallucine des valeurs.
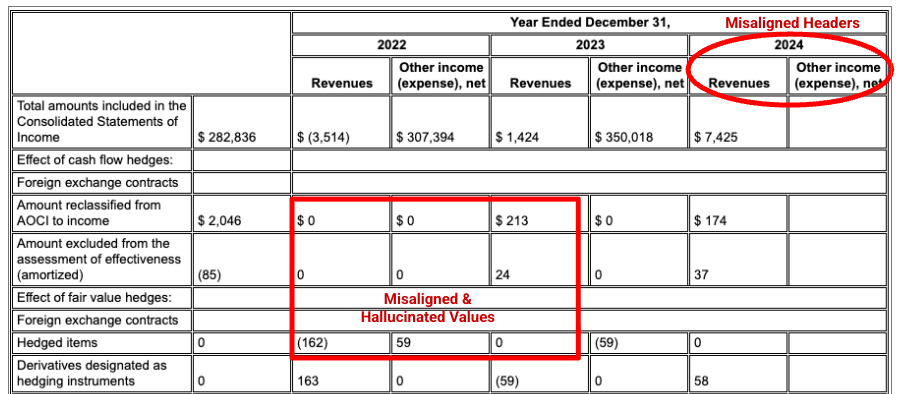
L'analyseur de mise en page de Gemini aligne correctement les colonnes et fournit des valeurs précises.
Minimisation des hallucinations
Contrairement aux analyseurs basés sur des LLM purs qui tentent de lire du texte qui n'existe pas, l'analyseur de mise en page de Gemini est basé sur l'OCR avancé, ce qui le rend plus précis dans le contenu réel du document. Cela réduit considérablement les hallucinations.
Exemple : Dans cet extrait 10-K, un modèle concurrent hallucine et insère du texte incorrect. L'analyseur de mise en page de Gemini fournit une extraction propre et précise du texte présent sur la page.
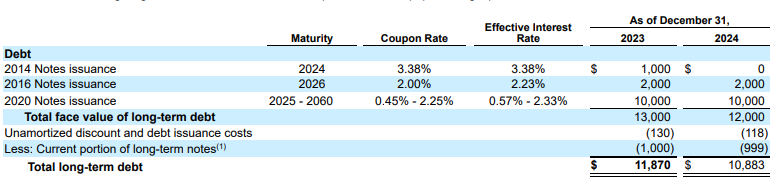
Figure 2 : Document d'entrée (Alphabet 2024 10k p75)
Les modèles concurrents hallucinent des valeurs.
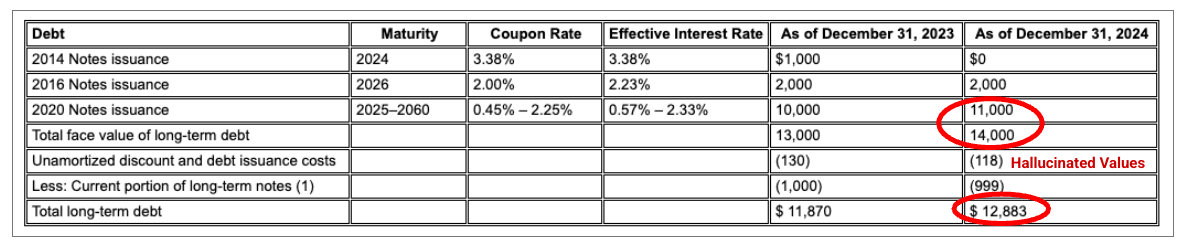
L'analyseur de mise en page de Gemini identifie correctement les valeurs dans les images et les tableaux.
Blocage tenant compte de la mise en page
Les analyseurs standards créent souvent des blocs supprimés de leur contexte d'origine, en séparant un paragraphe de son en-tête. L'analyseur de mise en page de Gemini comprend la hiérarchie du document. Il crée des blocs sensibles au contexte qui incluent le contenu des en-têtes ancestraux et des en-têtes de tableau. Un bloc récupéré contient non seulement le texte, mais également le contexte structurel nécessaire pour une réponse précise du LLM.
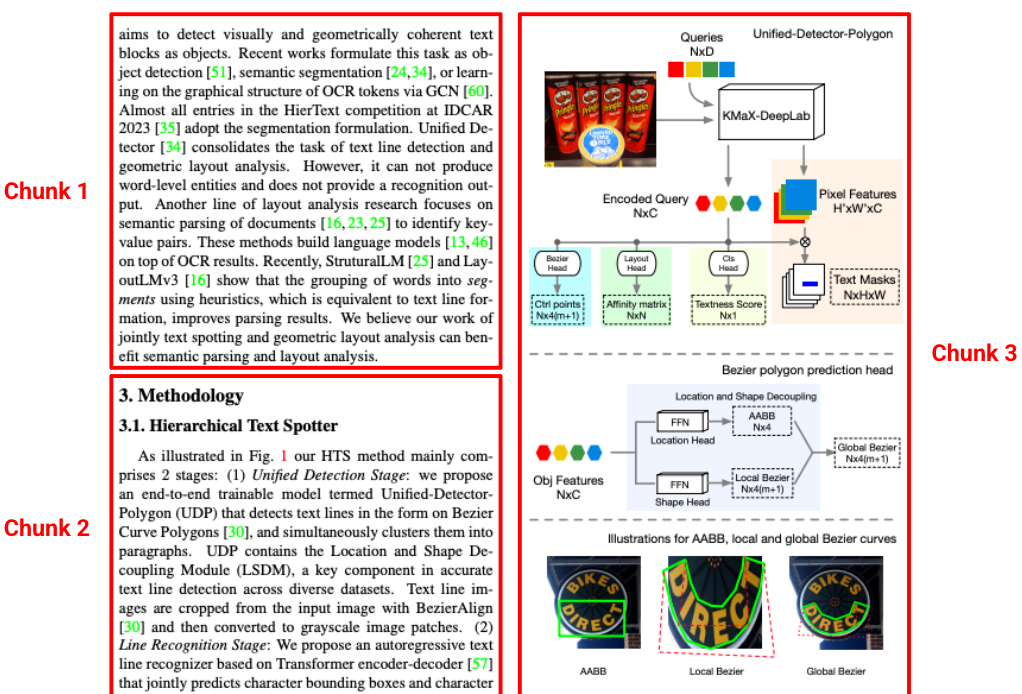
Figure 3 : La source de cette image est "Hierarchical Text Spotter for Joint Text Spotting and Layout Analysis" de Shangbang Long, Siyang Qin, Yasuhisa Fujii, Alessandro Bissacco et Michalis Raptis.
Annotation de la mise en page
L'annotation de l'analyseur de mise en page peut identifier la présence d'images ou de tableaux dans les documents analysés. Lorsqu'ils sont trouvés, ils sont annotés sous forme de bloc de texte descriptif avec les informations représentées dans l'image et le tableau.
Par exemple, lors du traitement d'un rapport bancaire, l'analyseur ne voit pas seulement une image. Il génère une description détaillée et extrait les points de données des trois graphiques circulaires, ce qui rend ces données disponibles pour la récupération.
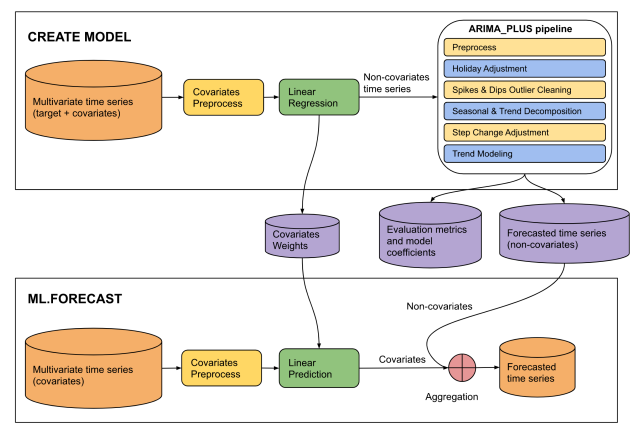
Figure 4 : La source de cette entrée est un PDF enregistré de "The CREATE MODEL statement for ARIMA_ PLUS_XREG models" sur le site Google Cloud.
This diagram illustrates a two-phase machine learning pipeline for time series
forecasting: "CREATE MODEL" and "ML.FORECAST".
**CREATE MODEL Phase:**
* **Input Data:** The process begins with multivariate time series (target +
covariates).
* **Covariates Preprocess:** The covariates from the multivariate time series
undergo covariates preprocess.
* **Linear Regression:** The preprocessed covariates are fed into a linear
regression model. The output of this step is non-covariates time series.
* **ARIMA_PLUS pipeline:** The "Non-covariates time series" then enters an
"ARIMA_PLUS pipeline".
* **Outputs of CREATE MODEL:** The results from the ARIMA_PLUS pipeline, along
with data from the linear regression step, generate three outputs: covariates
weights, evaluation metrics and model coefficients and forecasted time series
(non-covariates).
**ML.FORECAST Phase:**
* **Input Data:** This phase starts with "Multivariate time series (covariates)".
* **Covariates Preprocess:**
* **Linear Prediction:** The preprocessed covariates are fed into a linear
prediction step.
* **Aggregation:** The covariates (predicted contribution from covariates)
are then combined with the forecasted time series (non-covariates) obtained
from the CREATE MODEL phase.
* **Final Output:** The result of the aggregation is the forecasted time
series, which is the final prediction of the target variable.
**Overall Flow:**
The diagram shows a two-stage forecasting approach. In the CREATE MODEL stage,
a model is built to separate the target time series into components influenced
by covariates and components that are not. The non-covariate component is then
processed and forecasted using an ARIMA_PLUS pipeline. The covariate component's
relationship with the target is captured by linear regression weights. In the
ML.FORECAST stage, these learned components are combined with future covariate
data to produce a final forecast.
Limites
Les limites suivantes s'appliquent :
- Traitement en ligne :
- Taille maximale du fichier d'entrée : 20 Mo pour tous les types de fichiers
- Maximum de 15 pages par fichier PDF
- Traitement par lot :
- Taille maximale d'un seul fichier : 1 Go pour les fichiers PDF
- Maximum de 500 pages par fichier PDF
Détection de la mise en page par type de fichier
Le tableau suivant répertorie les éléments que l'analyseur de mise en page peut détecter par type de fichier de document.
| Type de fichier | Type MIME | Éléments détectés | Limites |
|---|---|---|---|
| HTML | text/html |
paragraphe, tableau, liste, titre, en-tête, en-tête de page, pied de page | Sachez que l'analyse repose fortement sur les balises HTML. Par conséquent, la mise en forme basée sur CSS peut ne pas être capturée. |
application/pdf |
figure, paragraphe, tableau, titre, en-tête, en-tête de page, pied de page | Les tableaux qui s'étendent sur plusieurs pages peuvent être divisés en deux tableaux. | |
| DOCX | application/vnd.openxmlformats-officedocument.wordprocessingml.document |
paragraphe, tableaux sur plusieurs pages, liste, titre, éléments d'en-tête | Les tableaux imbriqués ne sont pas acceptés. |
| PPTX | application/vnd.openxmlformats-officedocument.presentationml.presentation |
paragraphe, tableau, liste, titre, éléments d'en-tête | Pour que les en-têtes soient identifiés avec précision, ils doivent être marqués comme tels dans le fichier PowerPoint. Les tableaux imbriqués et les diapositives masquées ne sont pas acceptés. |
| XLSX | application/vnd.openxmlformats-officedocument.spreadsheetml.sheet |
tableaux dans des feuilles de calcul Excel, compatibles avec les valeurs INT,
FLOAT, et STRING |
La détection de plusieurs tableaux n'est pas acceptée. Les feuilles, lignes ou colonnes masquées peuvent également avoir un impact sur la détection. Les fichiers contenant jusqu'à 5 millions de cellules peuvent être traités. |
| XLSM | application/vnd.ms-excel.sheet.macroenabled.12 |
feuille de calcul avec macro activée, compatible avec les valeurs INT,
FLOAT, et STRING |
La détection de plusieurs tableaux n'est pas acceptée. Les feuilles, lignes ou colonnes masquées peuvent également avoir un impact sur la détection. |
Étape suivante
- Consultez la liste des outils de traitement.
- Créez un classifieur personnalisé.
- Utilisez Enterprise Document OCR pour détecter et extraire du texte.
- Consultez Envoyer une requête de traitement par lot de documents pour découvrir comment gérer les réponses.