
Antes de comenzar
Si aún no lo hiciste, configura un proyecto Google Cloud y dos (2) buckets de Cloud Storage.
Configura tu proyecto
- Accede a tu cuenta de Google Cloud . Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instala Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a la gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and Cloud Run functions APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instala Google Cloud CLI.
-
Si usas un proveedor de identidad externo (IdP), primero debes acceder a la gcloud CLI con tu identidad federada.
-
Para inicializar gcloud CLI, ejecuta el siguiente comando:
gcloud init
Crea o usa dos buckets de Cloud Storage en tu proyecto
Necesitarás dos buckets de Cloud Storage en tu proyecto: uno para los archivos de entrada y otro para los de salida.
- En la consola de Google Cloud , ve a la página Buckets de Cloud Storage.
- Haz clic en Crear.
- En la página Crear un bucket, ingresa la información de tu bucket. Para ir al paso siguiente, haz clic en Continuar.
-
En la sección Primeros pasos, haz lo siguiente:
- Ingresa un nombre único a nivel global que cumpla con los requisitos de nombre de los buckets.
- Para agregar una
etiqueta de bucket,
expande la sección Etiquetas (),
haz clic en add_box
Agregar etiqueta y especifica una
keyy unvaluepara tu etiqueta.
-
En la sección Elige dónde almacenar tus datos, haz lo siguiente:
- Selecciona un tipo de ubicación
- Elige una ubicación en la que se almacenen de forma permanente los datos de tu bucket en el menú desplegable Tipo de ubicación.
- Si seleccionas el tipo de ubicación birregional, también puedes habilitar la replicación turbo con la casilla de verificación correspondiente.
- Para configurar la replicación bucket buckets, selecciona
Agregar replicación entre bucket a través del Servicio de transferencia de almacenamiento y
sigue estos pasos:
Configura la replicación entre buckets
- En el menú Bucket, selecciona un bucket.
En la sección Configuración de replicación, haz clic en Configurar para configurar los parámetros del trabajo de replicación.
Aparecerá el panel Configurar la replicación entre buckets.
- Para filtrar los objetos que se replicarán por prefijo de nombre de objeto, ingresa un prefijo con el que quieras incluir o excluir objetos y, luego, haz clic en Agregar un prefijo.
- Para establecer una clase de almacenamiento para los objetos replicados, selecciona una clase de almacenamiento en el menú Clase de almacenamiento. Si omites este paso, los objetos replicados usarán la clase de almacenamiento del bucket de destino de forma predeterminada.
- Haz clic en Listo.
-
En la sección Elige cómo almacenar tus datos, haz lo siguiente:
- Selecciona una clase de almacenamiento predeterminada para el bucket o Autoclass para la administración automática de clases de almacenamiento de los datos de tu bucket.
- Para habilitar el espacio de nombres jerárquico, en la sección Optimizar el almacenamiento para cargas de trabajo con uso intensivo de datos, selecciona Habilitar el espacio de nombres jerárquico en este bucket.
- En la sección Elige cómo controlar el acceso a los objetos, selecciona si tu bucket aplica o no la prevención del acceso público y elige un método de control de acceso para los objetos del bucket.
-
En la sección Elige cómo proteger los datos de objetos, haz lo siguiente:
- Selecciona cualquiera de las opciones de Protección de datos que
desees configurar para tu bucket.
- Para habilitar la eliminación no definitiva, haz clic en la casilla de verificación Política de eliminación no definitiva (para la recuperación de datos) y especifica la cantidad de días que deseas conservar los objetos después de la eliminación.
- Para configurar el control de versiones de objetos, haz clic en la casilla de verificación Control de versiones de objetos (para el control de versión) y especifica la cantidad máxima de versiones por objeto y la cantidad de días después de los cuales vencen las versiones no actuales.
- Para habilitar la política de retención en objetos y buckets, haz clic en la casilla de verificación Retención (para cumplimiento) y, luego, haz lo siguiente:
- Para habilitar el bloqueo de retención de objetos, haz clic en la casilla de verificación Habilitar la retención de objetos.
- Para habilitar el Bloqueo del bucket, haz clic en la casilla de verificación Establecer política de retención del bucket y elige una unidad de tiempo y una duración para tu período de retención.
- Para elegir cómo se encriptarán los datos de tus objetos, expande la sección Encriptación de datos () y selecciona un método de encriptación de datos.
- Selecciona cualquiera de las opciones de Protección de datos que
desees configurar para tu bucket.
-
En la sección Primeros pasos, haz lo siguiente:
- Haz clic en Crear.
Crear una plantilla de flujo de trabajo
Para crear y definir una plantilla de flujo de trabajo, copia y ejecuta los siguientes comandos en una ventana de la terminal local o en Cloud Shell.
- Crea la plantilla de flujo de trabajo.
gcloud dataproc workflow-templates create wordcount-template \ --region=us-central1
- Agrega el trabajo de conteo de palabras a la plantilla de flujo de trabajo.
-
Especifica tu output-bucket-name antes de ejecutar el comando (tu función proporcionará el bucket de entrada).
Después de insertar el nombre de bucket de salida, este debe leerse de la siguiente manera:
gs://your-output-bucket/wordcount-output". -
El ID del paso "conteo" es obligatorio y, además, identifica el trabajo hadoop agregado.
gcloud dataproc workflow-templates add-job hadoop \ --workflow-template=wordcount-template \ --step-id=count \ --jar=file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ --region=us-central1 \ -- wordcount gs://input-bucket gs://output-bucket-name/wordcount-output
-
Especifica tu output-bucket-name antes de ejecutar el comando (tu función proporcionará el bucket de entrada).
Después de insertar el nombre de bucket de salida, este debe leerse de la siguiente manera:
- Usa un clúster administrado y de un solo nodo para ejecutar el flujo de trabajo. Managed Service para Apache Spark creará el clúster, ejecutará el flujo de trabajo en él y, luego, borrará el clúster cuando este se complete.
gcloud dataproc workflow-templates set-managed-cluster wordcount-template \ --cluster-name=wordcount \ --single-node \ --region=us-central1 - Haz clic en el nombre de
wordcount-templateen la página Flujos de trabajo de Managed Service para Apache Spark en la consola de Google Cloud para abrir la página Detalles de la plantilla de flujo de trabajo. Confirme los atributos de la plantilla de conteo de palabras.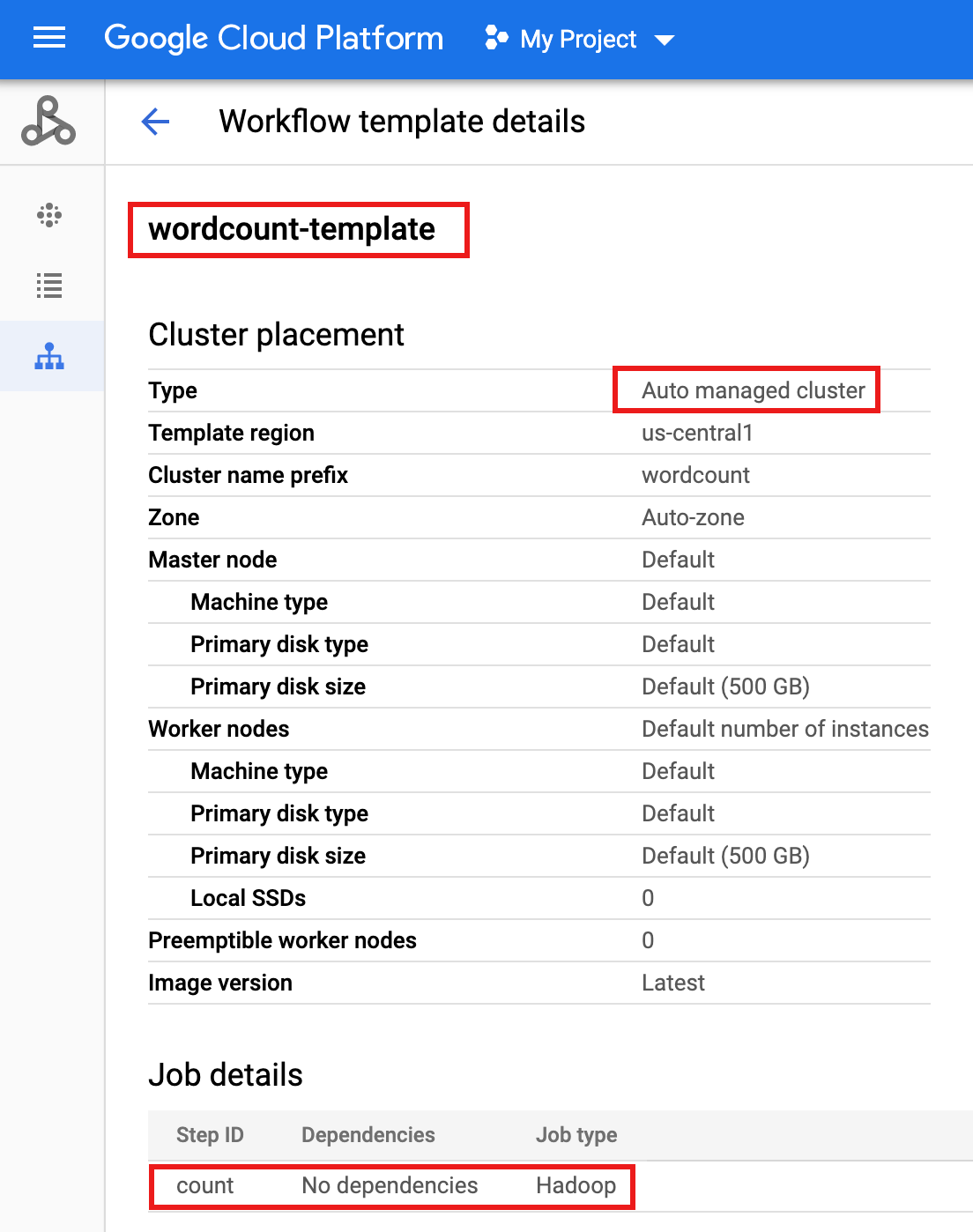
Parametriza la plantilla de flujo de trabajo
Parametriza la variable del bucket de entrada que se pasará a la plantilla de flujo de trabajo.
- Exporta la plantilla de flujo de trabajo a un archivo de texto
wordcount.yamlpara la parametrización.gcloud dataproc workflow-templates export wordcount-template \ --destination=wordcount.yaml \ --region=us-central1
- Con un editor de texto, abre
wordcount.yamly, luego, agrega un bloque deparametersal final del archivo YAML para que el INPUT_BUCKET_URI de Cloud Storage se pueda pasar comoargs[1]al conteo de palabras.A continuación, se muestra un ejemplo de un archivo YAML exportado. Puedes implementar uno de estos dos enfoques para actualizar tu plantilla:
- Copia y pega todo el archivo para reemplazar tu
wordcount.yamlexportado después de reemplazar your-output_bucket por el nombre de tu depósito de salida. - Copia y pega solo la sección
parametersal final del archivowordcount.yamlexportado.
jobs: - hadoopJob: args: - wordcount - gs://input-bucket - gs://your-output-bucket/wordcount-output mainJarFileUri: file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar stepId: count placement: managedCluster: clusterName: wordcount config: softwareConfig: properties: dataproc:dataproc.allow.zero.workers: 'true' parameters: - name: INPUT_BUCKET_URI description: wordcount input bucket URI fields: - jobs['count'].hadoopJob.args[1] - Copia y pega todo el archivo para reemplazar tu
- Importa el archivo de texto
wordcount.yamlcon parámetros. Escribe “Y” cuando se te solicite reemplazar la plantilla.gcloud dataproc workflow-templates import wordcount-template \ --source=wordcount.yaml \ --region=us-central1
Crea una Cloud Function
Abre la página Cloud Run Functions en la consola deGoogle Cloud y, luego, haz clic en CREAR FUNCIÓN.
En la página Crear función, ingresa o selecciona la siguiente información:
- Nombre: Recuento de palabras.
- Memoria asignada: Mantén la selección predeterminada.
- Trigger:
- Cloud Storage
- Tipo de evento: Finalizar/Crear.
- Bucket: Selecciona tu bucket de entrada (consulta Crea un bucket de Cloud Storage en tu proyecto). Cuando se agrega un archivo a este bucket, la función activará el flujo de trabajo. El flujo de trabajo ejecutará la aplicación de recuento de palabras, que procesará todos los archivos de texto en el bucket.
Código de origen:
- Editor directo
- Entorno de ejecución: Node.js 8
- Pestaña
INDEX.JS: Reemplaza el fragmento de código predeterminado por el siguiente código y, luego, edita la líneaconst projectIdpara proporcionar -your-project-id- (sin un "-" al principio ni al final).
const dataproc = require('@google-cloud/dataproc').v1; exports.startWorkflow = (data) => { const projectId = '-your-project-id-' const region = 'us-central1' const workflowTemplate = 'wordcount-template' const client = new dataproc.WorkflowTemplateServiceClient({ apiEndpoint: `${region}-dataproc.googleapis.com`, }); const file = data; console.log("Event: ", file); const inputBucketUri = `gs://${file.bucket}/${file.name}`; const request = { name: client.projectRegionWorkflowTemplatePath(projectId, region, workflowTemplate), parameters: {"INPUT_BUCKET_URI": inputBucketUri} }; client.instantiateWorkflowTemplate(request) .then(responses => { console.log("Launched Dataproc Workflow:", responses[1]); }) .catch(err => { console.error(err); }); };- Pestaña
PACKAGE.JSON: Reemplaza el fragmento de código predeterminado por el siguiente código.
{ "name": "dataproc-workflow", "version": "1.0.0", "dependencies":{ "@google-cloud/dataproc": ">=1.0.0"} }- Función que se ejecutará: Insert: "startWorkflow".
Haga clic en CREAR.
Prueba la función
Copia el archivo público
rose.txten tu bucket para activar la función. Inserta your-input-bucket-name (el bucket que se usa para activar la función) en el comando.gcloud storage cp gs://pub/shakespeare/rose.txt gs://your-input-bucket-name
Espera 30 segundos y, luego, ejecuta el siguiente comando para verificar que la función se haya completado correctamente.
gcloud functions logs read wordcount
... Function execution took 1348 ms, finished with status: 'ok'
Para ver los registros de la función desde la página de lista Funciones en la consola de Google Cloud , haz clic en el nombre de la función
wordcounty, luego, en VER REGISTROS en la página Detalles de la función.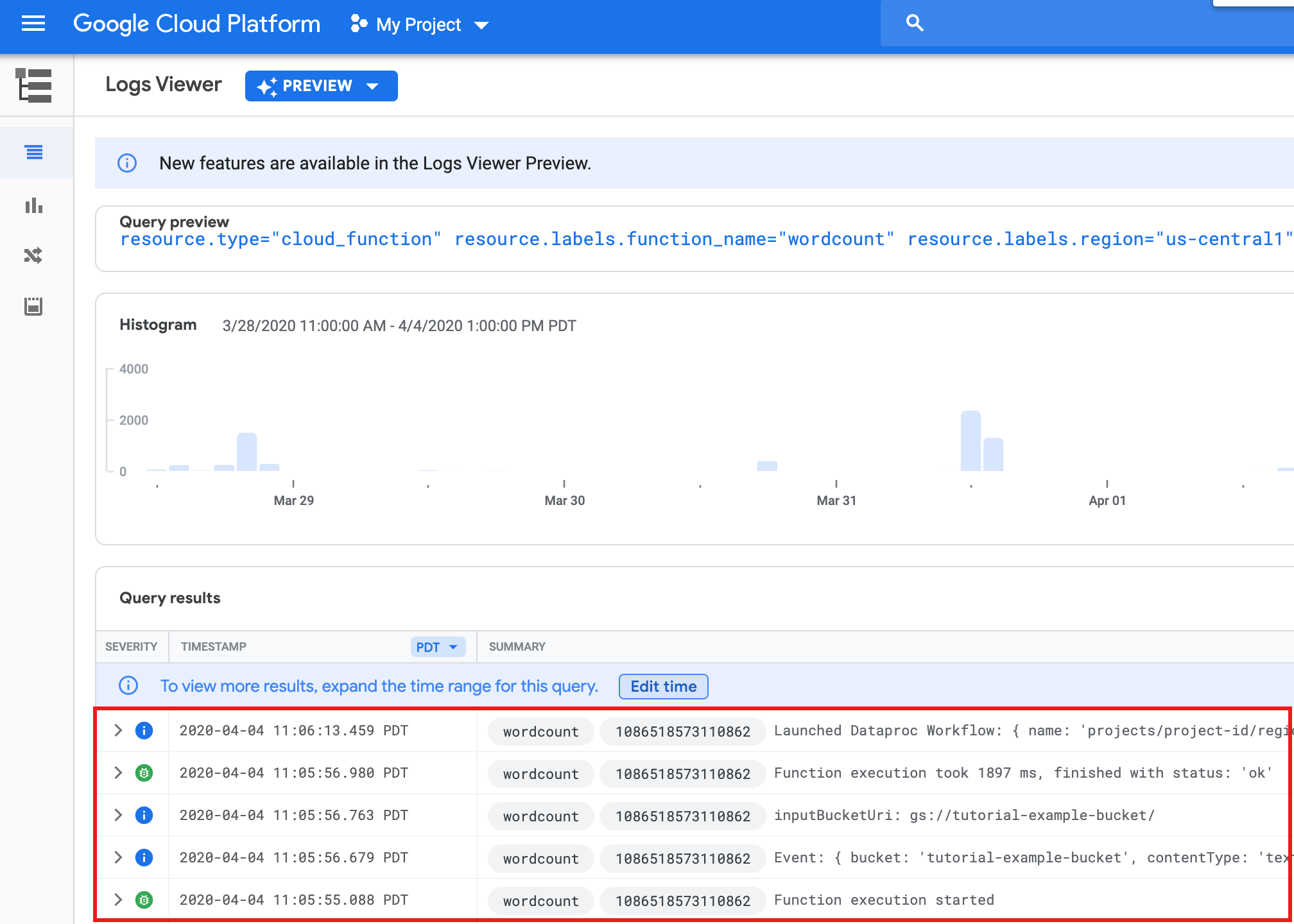
Puedes ver la carpeta
wordcount-outputen tu bucket de salida desde la página Navegador de Storage en la consola deGoogle Cloud .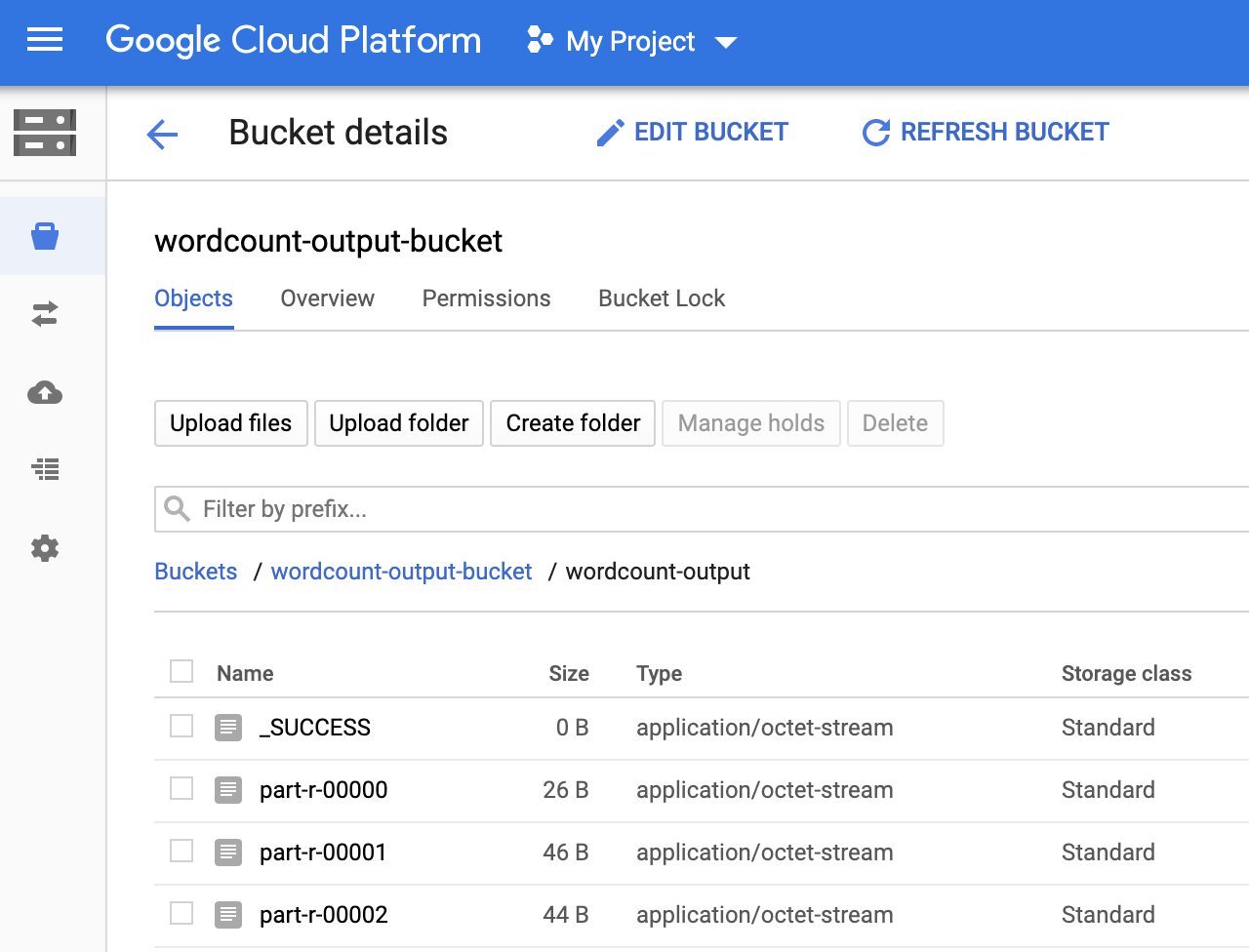
Una vez que se completa el flujo de trabajo, los detalles del trabajo persisten en la consola deGoogle Cloud . Haz clic en el trabajo
count...que aparece en la página Trabajos de Managed Service para Apache Spark para ver los detalles del trabajo de flujo de trabajo.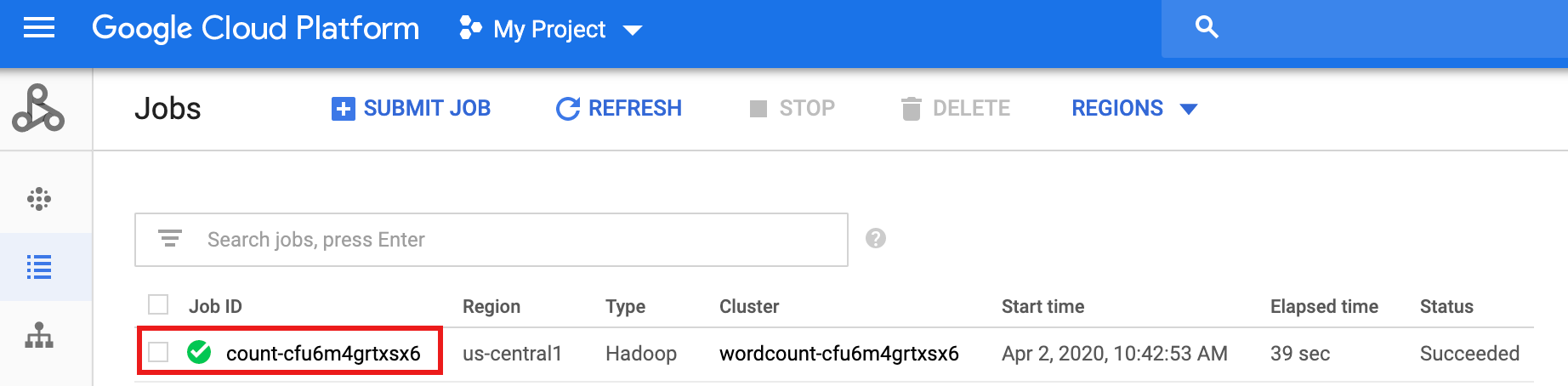
Realiza una limpieza
El flujo de trabajo de este instructivo borra su clúster administrado cuando se completa. Para evitar costos recurrentes, puedes borrar otros recursos asociados con este instructivo.
Borra un proyecto
- En la Google Cloud consola, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borra depósitos de Cloud Storage
- En la Google Cloud consola, ve a la página Buckets de Cloud Storage.
- Haz clic en la casilla de verificación del bucket que deseas borrar.
- Para borrar el bucket, haz clic en Borrar y sigue las instrucciones.
Borra tu plantilla de flujo de trabajo
gcloud dataproc workflow-templates delete wordcount-template \ --region=us-central1
Borra tu función de Cloud Functions
Abre la página Cloud Run Functions en la consola de Google Cloud , selecciona la casilla a la izquierda de la función wordcount y, luego, haz clic en Borrar.
¿Qué sigue?
- Consulta la Descripción general de las plantillas de flujos de trabajo de Managed Service para Apache Spark.
- Consulta Soluciones de programación del flujo de trabajo.