
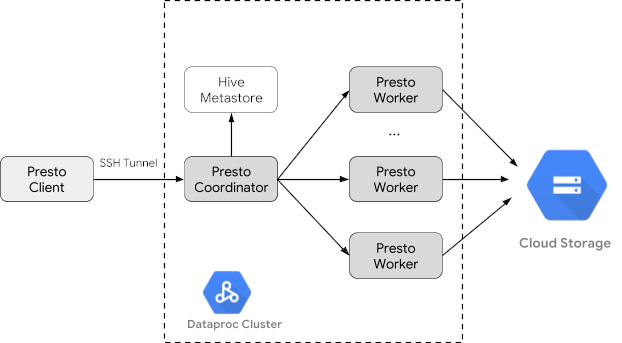
O Trino (antigo Presto) é um mecanismo de consulta SQL distribuído, desenvolvido para consultar grandes conjuntos de dados distribuídos em uma ou mais origens de dados heterogêneas. O Trino pode consultar Hive, MySQL, Kafka e outras fontes de dados por meio de conectores. Neste tutorial, mostramos como fazer as seguintes tarefas:
- Instalar o serviço Trino em um cluster do Managed Service for Apache Spark
- Consultar dados públicos de um cliente Trino instalado em sua máquina local que se comunica com um serviço Trino em seu cluster
- Executar consultas a partir de um aplicativo Java que se comunica com o serviço Trino no cluster usando o driver JDBC do Java para Trino.
Objetivos
- Extrair os dados do BigQuery
- Carregar os dados no Cloud Storage como arquivos CSV
- Transformar dados:
- Expor os dados como uma tabela externa Hive para tornar os dados pesquisáveis pelo Trino
- Converter os dados do formato CSV para o formato Parquet para agilizar as consultas
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
Se você ainda não tiver feito isso, crie um Google Cloud projeto e um bucket do Cloud Storage para armazenar os dados usados neste tutorial. 1. Como configurar o projeto- Faça login na sua conta do Google Cloud . Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho de nossos produtos em situações reais. Clientes novos também recebem US$ 300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instale a CLI do Google Cloud.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc, Compute Engine, Cloud Storage, and BigQuery APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
Instale a CLI do Google Cloud.
-
Ao usar um provedor de identidade (IdP) externo, primeiro faça login na gcloud CLI com sua identidade federada.
-
Para inicializar a gcloud CLI, execute o seguinte comando:
gcloud init
- No console do Google Cloud , acesse a página Buckets do Cloud Storage.
- Clique em Criar.
- Na página Criar um bucket, insira as informações do seu bucket. Para ir à próxima
etapa, clique em Continuar.
-
Na seção Começar, faça o seguinte:
- Insira um nome globalmente exclusivo que atenda aos requisitos de nomeação de bucket.
- Para adicionar um
rótulo de bucket,
abra a seção Rótulos (),
clique em add_box
Adicionar rótulo e especifique um
keye umvaluepara o rótulo.
-
Na seção Escolha onde armazenar seus dados, faça o seguinte:
- Selecione um tipo de local.
- Escolha um local onde os dados do bucket são armazenados permanentemente no menu suspenso Tipo de local.
- Se você selecionar o tipo de local birregional, também poderá ativar a replicação turbo usando a caixa de seleção relevante.
- Para configurar a replicação entre buckets, selecione
Adicionar replicação entre buckets usando o Serviço de transferência do Cloud Storage e
siga estas etapas:
Configurar a replicação entre buckets
- No menu Bucket, selecione um bucket.
Na seção Configurações de replicação, clique em Configurar para definir as configurações do job de replicação.
O painel Configurar a replicação entre buckets aparece.
- Para filtrar objetos a serem replicados por prefixo de nome de objeto, insira um prefixo com que você quer incluir ou excluir objetos e clique em Adicionar um prefixo.
- Para definir uma classe de armazenamento para os objetos replicados, selecione uma classe de armazenamento no menu Classe de armazenamento. Se você pular esta etapa, os objetos replicados vão usar a classe de armazenamento do bucket de destino por padrão.
- Clique em Concluído.
-
Na seção Escolha como armazenar seus dados, faça o seguinte:
- Selecione uma classe de armazenamento padrão para o bucket ou Classe automática para gerenciamento automático da classe de armazenamento dos dados do bucket.
- Para ativar o namespace hierárquico, na seção Otimizar o armazenamento para cargas de trabalho com uso intensivo de dados, selecione Ativar namespace hierárquico neste bucket.
- Na seção Escolha como controlar o acesso a objetos, selecione se o bucket aplica ou não a prevenção de acesso público e selecione um método de controle de acesso para os objetos do bucket.
-
Na seção Escolha como proteger os dados do objeto, faça o
seguinte:
- Selecione qualquer uma das opções em Proteção de dados que
você quer definir para o bucket.
- Para ativar a exclusão reversível, clique na caixa de seleção Política de exclusão reversível (para recuperação de dados) e especifique o número de dias que você quer reter os objetos após a exclusão.
- Para definir o controle de versões de objetos, clique na caixa de seleção Controle de versões de objetos (para controle de versões) e especifique o número máximo de versões por objeto e o número de dias após os quais as versões não atuais expiram.
- Para ativar a política de retenção em objetos e buckets, clique na caixa de seleção Retenção (para compliance) e faça o seguinte:
- Para ativar o bloqueio de retenção de objetos, clique na caixa de seleção Ativar retenção de objetos.
- Para ativar o Bloqueio de buckets, clique na caixa de seleção Definir política de retenção de buckets e escolha uma unidade e um período de armazenamento para a retenção.
- Para escolher como os dados do objeto serão criptografados, expanda a seção Criptografia de dados () e selecione um método de Criptografia de dados.
- Selecione qualquer uma das opções em Proteção de dados que
você quer definir para o bucket.
-
Na seção Começar, faça o seguinte:
- Clique em Criar.
Criar um cluster do Managed Service for Apache Spark
Crie um cluster do Managed Service para Apache Spark usando a flag optional-components (disponível na versão de imagem 2.1 e mais recentes) para instalar o componente opcional Trino no cluster e a flag enable-component-gateway para ativar o Component Gateway e permitir que você acesse a interface da Web do Trino no console Google Cloud .
- Defina variáveis de ambiente.
- PROJECT: ID do projeto
- BUCKET_NAME: o nome do bucket do Cloud Storage que você criou em Antes de começar
- REGION: região onde o cluster usado neste tutorial será criado, por exemplo, "us-west1"
- WORKERS: 3 a 5 workers são recomendados para este tutorial
export PROJECT=project-id export WORKERS=number export REGION=region export BUCKET_NAME=bucket-name
- Execute a Google Cloud CLI na sua máquina local para
criar o cluster.
gcloud beta dataproc clusters create trino-cluster \ --project=${PROJECT} \ --region=${REGION} \ --num-workers=${WORKERS} \ --scopes=cloud-platform \ --optional-components=TRINO \ --image-version=2.1 \ --enable-component-gateway
Preparar dados
Exporte o conjunto de dados bigquery-public-data chicago_taxi_trips para o Cloud Storage como arquivos CSV e crie uma tabela externa Hive para fazer referência aos dados.
- Na máquina local, execute o seguinte comando para importar os dados de táxi do BigQuery como arquivos CSV sem cabeçalhos para o bucket do Cloud Storage criado em Antes de começar.
bq --location=us extract --destination_format=CSV \ --field_delimiter=',' --print_header=false \ "bigquery-public-data:chicago_taxi_trips.taxi_trips" \ gs://${BUCKET_NAME}/chicago_taxi_trips/csv/shard-*.csv - Crie tabelas externas do Hive com backup dos arquivos CSV e Parquet em seu bucket do Cloud Storage.
- Crie a tabela externa Hive
chicago_taxi_trips_csv.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_csv( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE location 'gs://${BUCKET_NAME}/chicago_taxi_trips/csv/';" - Verifique a criação da tabela externa Hive.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_csv;" - Crie outra tabela Hive externa
chicago_taxi_trips_parquetcom as mesmas colunas, mas com dados armazenados no formato Parquet para melhorar o desempenho da consulta.gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " CREATE EXTERNAL TABLE chicago_taxi_trips_parquet( unique_key STRING, taxi_id STRING, trip_start_timestamp TIMESTAMP, trip_end_timestamp TIMESTAMP, trip_seconds INT, trip_miles FLOAT, pickup_census_tract INT, dropoff_census_tract INT, pickup_community_area INT, dropoff_community_area INT, fare FLOAT, tips FLOAT, tolls FLOAT, extras FLOAT, trip_total FLOAT, payment_type STRING, company STRING, pickup_latitude FLOAT, pickup_longitude FLOAT, pickup_location STRING, dropoff_latitude FLOAT, dropoff_longitude FLOAT, dropoff_location STRING) STORED AS PARQUET location 'gs://${BUCKET_NAME}/chicago_taxi_trips/parquet/';" - Carregue os dados da tabela Hive CSV na tabela Hive Parquet.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute " INSERT OVERWRITE TABLE chicago_taxi_trips_parquet SELECT * FROM chicago_taxi_trips_csv;" - Verifique se os dados foram carregados corretamente.
gcloud dataproc jobs submit hive \ --cluster trino-cluster \ --region=${REGION} \ --execute "SELECT COUNT(*) FROM chicago_taxi_trips_parquet;"
- Crie a tabela externa Hive
Execute consultas
Você pode executar consultas localmente na CLI do Trino ou em um aplicativo.
Consultas da CLI do Trino
Esta seção demonstra como consultar o conjunto de dados de táxi Hive Parquet usando a CLI do Trino.
- Execute o seguinte comando na máquina local para SSH no nó mestre do cluster. O terminal local deixará de responder durante a execução do comando.
gcloud compute ssh trino-cluster-m
- Na janela do terminal SSH no nó mestre do cluster, execute a CLI Trino, que se conecta ao servidor Trino em execução no nó mestre.
trino --catalog hive --schema default
- No prompt
trino:default, verifique se o Trino pode encontrar as tabelas do Hive.show tables;
Table ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ chicago_taxi_trips_csv chicago_taxi_trips_parquet (2 rows)
- Execute consultas a partir do prompt
trino:defaulte compare o desempenho da consulta de dados Parquet x CSV.- Consulta de dados Parquet
select count(*) from chicago_taxi_trips_parquet where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171735_00006_2sz8c, FINISHED, 3 nodes Splits: 308 total, 308 done (100.00%) 0:16 [113M rows, 297MB] [6.91M rows/s, 18.2MB/s] - Consulta de dados CSV
select count(*) from chicago_taxi_trips_csv where trip_miles > 50;
_col0 ‐‐‐‐‐‐‐‐ 117957 (1 row)
Query 20180928_171936_00009_2sz8c, FINISHED, 3 nodes Splits: 881 total, 881 done (100.00%) 0:47 [113M rows, 41.5GB] [2.42M rows/s, 911MB/s]
- Consulta de dados Parquet
Consultas de aplicativos Java
Para executar consultas de um aplicativo Java usando o driver JDBC do Java para Trino:
1. Faça o download do driver JDBC do Java para Trino.
1. Adicione uma dependência trino-jdbc no pom.xml do Maven.
<dependency> <groupId>io.trino</groupId> <artifactId>trino-jdbc</artifactId> <version>376</version> </dependency>
package dataproc.codelab.trino;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
public class TrinoQuery {
private static final String URL = "jdbc:trino://trino-cluster-m:8080/hive/default";
private static final String SOCKS_PROXY = "localhost:1080";
private static final String USER = "user";
private static final String QUERY =
"select count(*) as count from chicago_taxi_trips_parquet where trip_miles > 50";
public static void main(String[] args) {
try {
Properties properties = new Properties();
properties.setProperty("user", USER);
properties.setProperty("socksProxy", SOCKS_PROXY);
Connection connection = DriverManager.getConnection(URL, properties);
try (Statement stmt = connection.createStatement()) {
ResultSet rs = stmt.executeQuery(QUERY);
while (rs.next()) {
int count = rs.getInt("count");
System.out.println("The number of long trips: " + count);
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}Geração de registros e monitoramento
Logging
Os registros do Trino estão localizados em /var/log/trino/ nos nós mestre e de trabalho do cluster.
IU da Web
Consulte Como visualizar e acessar URLs do Gateway de componentes para abrir a interface da Web do Trino em execução no nó mestre do cluster no navegador local.
Monitoramento
O Trino expõe informações de ambiente de execução do cluster por meio de tabelas de ambiente de execução.
No prompt (do trino:default) de uma sessão do Trino, execute a seguinte consulta para visualizar os dados da tabela de ambiente de execução:
select * FROM system.runtime.nodes;
Limpar
Depois de concluir o tutorial, você pode limpar os recursos que criou para que eles parem de usar a cota e gerar cobranças. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Exclua o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- No console Google Cloud , acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir .
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
excluir o cluster
- Para excluir o cluster:
gcloud dataproc clusters delete --project=${PROJECT} trino-cluster \ --region=${REGION}
Excluir o bucket
- Para excluir o bucket do Cloud Storage criado em Antes de começar, incluindo os arquivos de dados armazenados no bucket:
gcloud storage rm gs://${BUCKET_NAME} --recursive