
目標
本教學課程將示範如何:
- 建立 Managed Service for Apache Spark 叢集,並在叢集上安裝 Apache HBase 和 Apache ZooKeeper
- 使用在 Managed Service for Apache Spark 叢集主要節點執行的 HBase Shell 建立 HBase 資料表
- 使用 Cloud Shell 將 Java 或 PySpark Spark 工作提交至 Managed Service for Apache Spark 服務,由該服務將資料寫入 HBase 資料表,然後從該資料表讀取資料
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
如果您尚未建立 Google Cloud Platform 專案,請先建立專案。
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
建立 Managed Service for Apache Spark 叢集
在 Cloud Shell 工作階段終端機中執行下列指令,以完成下列步驟:
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
驗證連接器安裝作業
從 Google Cloud 控制台或 Cloud Shell 工作階段終端機,透過 SSH 連線至 Managed Service for Apache Spark 叢集主要執行個體。
驗證 Apache HBase Spark 連接器在主要節點的安裝作業:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
請將 SSH 工作階段終端機保持為開啟狀態,以便:
- 建立 HBase 資料表
- (Java 使用者):在叢集的主要節點上執行指令,判斷叢集上安裝的元件版本
- 在執行程式碼之後掃描 Hbase 資料表
建立 HBase 資料表
在上一步開啟的主要節點 SSH 工作階段終端機中,執行本節列出的指令。
開啟 HBase Shell:
hbase shell
建立名為「my-table」的 HBase 資料表,其中包含「cf」資料欄系列:
create 'my_table','cf'
- 如要確認資料表建立作業,請在 Google Cloud 控制台按一下Google Cloud 控制台「Component Gateway」(元件閘道) 連結中的「HBase」,以開啟 Apache HBase 使用者介面。
my-table會列於「Home」(首頁) 頁面的「Tables」(資料表) 區段中。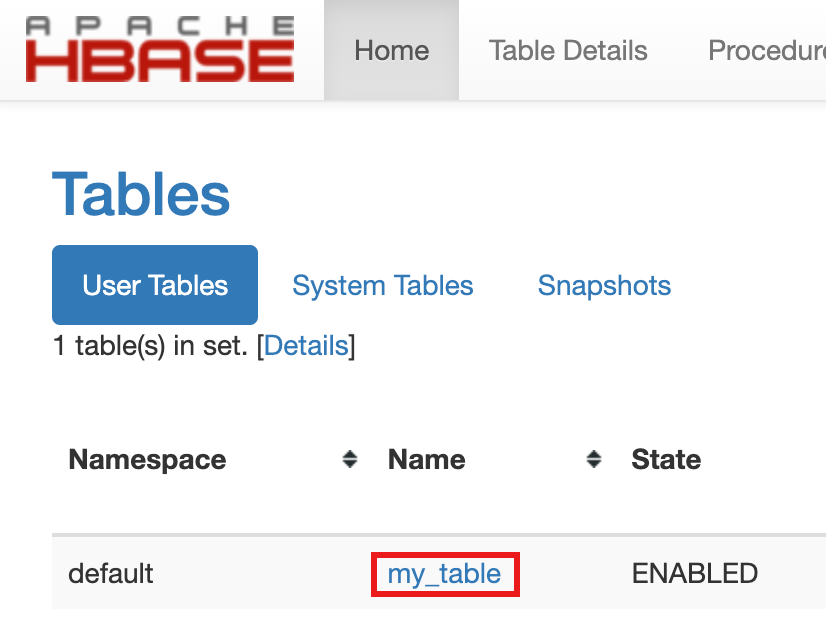
- 如要確認資料表建立作業,請在 Google Cloud 控制台按一下Google Cloud 控制台「Component Gateway」(元件閘道) 連結中的「HBase」,以開啟 Apache HBase 使用者介面。
查看 Spark 程式碼
Java
Python
執行程式碼
開啟 Cloud Shell 工作階段終端機。
將 GitHub GoogleCloudDataproc/cloud-dataproc 存放區複製到 Cloud Shell 工作階段終端機:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
切換至
cloud-dataproc/spark-hbase目錄。cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
提交 Managed Service for Apache Spark 工作。
Java
- 在
pom.xml檔案中設定元件版本。- Managed Service for Apache Spark 2.0.x 發布版本頁面列出隨最新及最近四個 2.0 修正版本映像檔一併安裝的 Scala、Spark 和 HBase 元件版本。
- 或者,也可以在叢集主要節點的 SSH 工作階段終端機中執行下列指令以判斷元件版本:
- 檢查 Scala 版本:
scala -version
- 檢查 Spark 版本 (按 Ctrl+D 鍵即可退出):
spark-shell
- 檢查 HBase 版本:
hbase version
- 在 Maven
pom.xml中找出 Spark、Scala 和 HBase 版本依附元件:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.version是目前的 Spark HBase 連接器版本,請勿變更此版本號碼。
- 檢查 Scala 版本:
- 在 Cloud Shell 編輯器中編輯
pom.xml檔案,插入正確的 Scala、Spark 和 HBase 版本號碼。編輯完成後,按一下「Open Terminal」(開啟終端機),返回 Cloud Shell 終端機指令列。cloudshell edit .
- 在 Cloud Shell 中切換至 Java 8。建構程式碼時需使用此 JDK 版本 (可忽略任何外掛程式警告訊息):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- 驗證 Java 8 安裝狀態:
java -version
openjdk version "1.8..."
- 建構
jar檔案:mvn clean package
.jar檔案會放置於/target子目錄中 (例如target/spark-hbase-1.0-SNAPSHOT.jar)。 提交工作:
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars:在「target/」之後和「.jar」之前插入.jar檔案的名稱。- 如果在建立叢集時未設定 Spark 驅動程式和執行器 HBase 類別路徑,則每次提交工作時都必須加以設定,方法是在工作提交指令中加入下列
‑‑properties旗標:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
在 Cloud Shell 工作階段終端機輸出內容中查看 HBase 資料表輸出內容:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
提交工作:
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- 如果在建立叢集時未設定 Spark 驅動程式和執行器 HBase 類別路徑,則每次提交工作時都必須加以設定,方法是在工作提交指令中加入下列
‑‑properties旗標:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- 如果在建立叢集時未設定 Spark 驅動程式和執行器 HBase 類別路徑,則每次提交工作時都必須加以設定,方法是在工作提交指令中加入下列
在 Cloud Shell 工作階段終端機輸出內容中查看 HBase 資料表輸出內容:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
掃描 HBase 資料表
您可以在「Verify connector installation」(驗證連接器安裝作業) 中開啟的主要節點 SSH 工作階段終端機,執行下列指令以掃描 HBase 資料表內容:
- 開啟 HBase Shell:
hbase shell
- 掃描「my-table」:
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
清除所用資源
完成教學課程後,您可以清除所建立的資源,這樣資源就不會繼續使用配額,也不會產生費用。下列各節將說明如何刪除或關閉這些資源。
刪除專案
如要避免付費,最簡單的方法就是刪除您為了本教學課程所建立的專案。
刪除專案的方法如下:
- 前往 Google Cloud 控制台的「Manage resources」(管理資源) 頁面。
- 在專案清單中選取要刪除的專案,然後點選「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下 [Shut down] (關閉) 以刪除專案。
刪除叢集
- 刪除叢集的方法如下:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}