
目标
本教程将介绍如何执行以下操作:
- 创建 Managed Service for Apache Spark 集群,并在该集群上安装 Apache HBase 和 Apache ZooKeeper
- 使用在 Managed Service for Apache Spark 集群的主节点上运行的 HBase shell 创建 HBase 表
- 使用 Cloud Shell 将 Java 或 PySpark Spark 作业提交到 Managed Service for Apache Spark 服务,以将数据写入 HBase 表,然后从 HBase 表读取数据。
费用
在本文档中,您将使用 Google Cloud的以下收费组件:
如需根据您的预计使用情况来估算费用,请使用价格计算器。
准备工作
如果您尚未创建 Google Cloud Platform 项目,请首先创建该项目。
- 登录您的 Google Cloud 账号。如果您是 Google Cloud新手,请 创建一个账号来评估我们的产品在实际场景中的表现。新客户还可获享 $300 赠金,用于运行、测试和部署工作负载。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
创建 Managed Service for Apache Spark 集群
在 Cloud Shell 会话终端中运行以下命令,以执行以下操作:
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
验证连接器安装
在 Google Cloud 控制台或 Cloud Shell 会话终端中,通过 SSH 连接到 Managed Service for Apache Spark 集群主服务器。
验证主节点上是否已安装 Apache HBase Spark 连接器:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
保持 SSH 会话终端打开状态,以执行以下操作:
- 创建 HBase 表
- (Java 用户):在集群的主节点上运行命令,以确定集群上安装的组件的版本
- 运行代码后扫描 Hbase 表
创建 HBase 表
在您上一步中打开的主节点 SSH 会话终端中运行本部分中列出的命令。
打开 HBase shell:
hbase shell
创建包含“cf”列族的 HBase“my-table”:
create 'my_table','cf'
- 如需确认创建表,请在 Google Cloud 控制台中点击Google Cloud 控制台组件网关链接中的 HBase,以打开 Apache HBase 界面。
my-table列在首页页面的表部分中。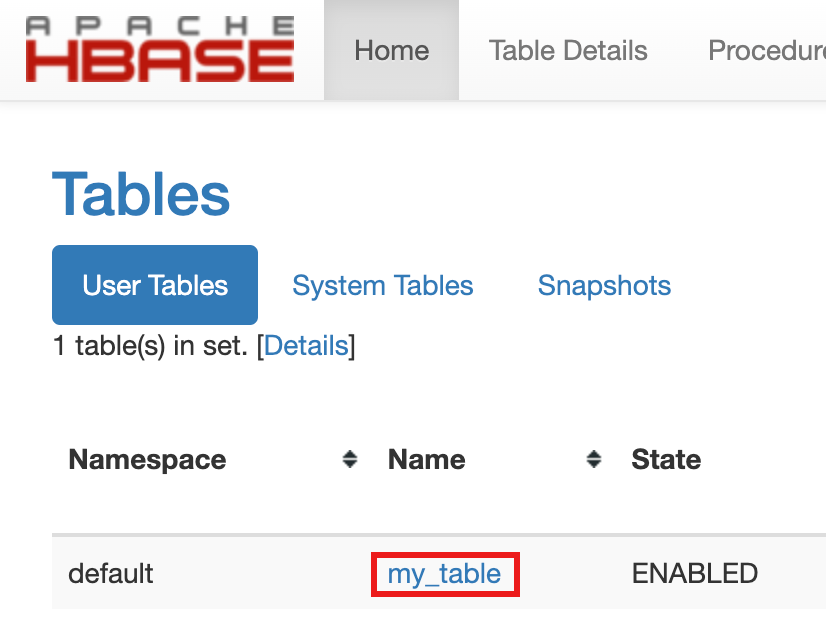
- 如需确认创建表,请在 Google Cloud 控制台中点击Google Cloud 控制台组件网关链接中的 HBase,以打开 Apache HBase 界面。
查看 Spark 代码
Java
Python
运行代码
打开 Cloud Shell 会话终端。
将 GitHub GoogleCloudDataproc/cloud-dataproc 代码库克隆到 Cloud Shell 会话终端中:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
切换到
cloud-dataproc/spark-hbase目录:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
提交 Managed Service for Apache Spark 作业。
Java
- 在
pom.xml文件中设置组件版本。- Managed Service for Apache Spark 2.0.x 发布版本页面列出了与最新和过去四个 2.0 次要版本映像一起安装的 Scala、Spark 和 HBase 组件版本。
- 如需查找 2.0 映像版本集群的次要版本,请点击Google Cloud 控制台的集群页面上的集群名称,以打开集群详情页面,其中列出了集群映像版本。
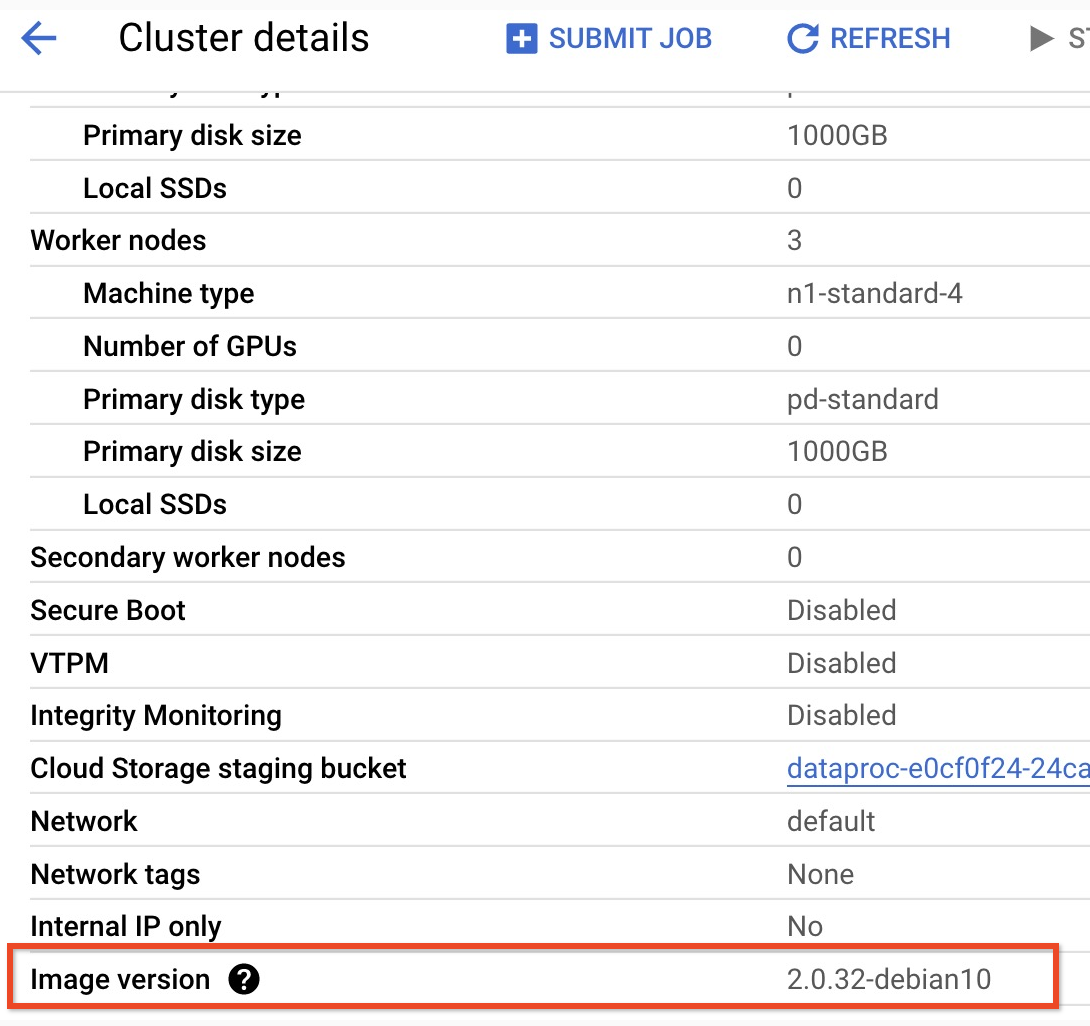
- 如需查找 2.0 映像版本集群的次要版本,请点击Google Cloud 控制台的集群页面上的集群名称,以打开集群详情页面,其中列出了集群映像版本。
- 或者,您也可以在集群的主节点的 SSH 会话终端中运行以下命令,以确定组件版本:
- 检查 Scala 版本:
scala -version
- 检查 Spark 版本(按 Control-D 退出):
spark-shell
- 检查 HBase 版本:
hbase version
- 在 Maven
pom.xml中识别 Spark、Scala 和 HBase 版本依赖项:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.version是当前的 Spark HBase 连接器版本;请保持此版本号不变。
- 检查 Scala 版本:
- 在 Cloud Shell 编辑器中修改
pom.xml文件,以插入正确的 Scala、Spark 和 HBase 版本号。 完成修改后,点击打开终端以返回 Cloud Shell 终端命令行。cloudshell edit .
- 在 Cloud Shell 中切换到 Java 8。您需要使用此 JDK 版本来构建代码(可以忽略任何插件警告消息):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- 验证 Java 8 安装:
java -version
openjdk version "1.8..."
- Managed Service for Apache Spark 2.0.x 发布版本页面列出了与最新和过去四个 2.0 次要版本映像一起安装的 Scala、Spark 和 HBase 组件版本。
- 构建
jar文件:mvn clean package
.jar文件放在/target子目录中(例如,target/spark-hbase-1.0-SNAPSHOT.jar)。 提交作业。
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars:将.jar文件的名称插入“target/”之后、“jar”之前。- 如果您在创建集群时未设置 Spark 驱动程序和执行器 HBase 类路径,则必须在提交每个作业时通过在作业提交命令中添加以下
‑‑properties标志来进行设置:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
在 Cloud Shell 会话终端输出中查看 HBase 表输出:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
提交作业。
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- 如果您在创建集群时未设置 Spark 驱动程序和执行器 HBase 类路径,则必须在提交每个作业时通过在作业提交命令中添加以下
‑‑properties标志来进行设置:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- 如果您在创建集群时未设置 Spark 驱动程序和执行器 HBase 类路径,则必须在提交每个作业时通过在作业提交命令中添加以下
在 Cloud Shell 会话终端输出中查看 HBase 表输出:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
扫描 HBase 表
您可以在验证连接器安装中打开的主节点 SSH 会话终端中运行以下命令,以扫描 HBase 表的内容:
- 打开 HBase shell:
hbase shell
- 扫描“my-table”:
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
清理
完成本教程后,您可以清理您创建的资源,让它们停止使用配额,以免产生费用。以下部分介绍如何删除或关闭这些资源。
删除项目
为了避免产生费用,最简单的方法是删除您为本教程创建的项目。
要删除项目,请执行以下操作:
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关闭以删除项目。
删除集群
- 如需删除您的集群,请输入以下命令:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}