
Objetivos
Neste tutorial, mostramos como fazer as seguintes tarefas:
- Criar um cluster do Serviço Gerenciado para Apache Spark, instalando o Apache HBase e o Apache ZooKeeper no cluster
- Criar uma tabela do HBase usando o shell do HBase em execução no nó mestre do cluster do Serviço Gerenciado para Apache Spark
- Usar o Cloud Shell para enviar um job do Spark Java ou PySpark ao Serviço Gerenciado para Apache Spark que grava dados na tabela do HBase e, em seguida, lê dados dela
Custos
Neste documento, você vai usar os seguintes componentes faturáveis do Google Cloud:
Para gerar uma estimativa de custo baseada na projeção de uso,
use a calculadora de preços.
Antes de começar
Se ainda não tiver feito, crie um projeto do Google Cloud Platform.
- Faça login na sua Google Cloud conta do. Se você começou a usar o Google Cloud, crie uma conta para avaliar o desempenho dos nossos produtos em situações reais. Clientes novos também recebem US $300 em créditos para executar, testar e implantar cargas de trabalho.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Criar um cluster do Serviço Gerenciado para Apache Spark
Execute o comando a seguir em um terminal de sessão do Cloud Shell para:
- Instalar os componentes do HBase e do ZooKeeper
- Provisionar três nós de trabalho (três a cinco workers são recomendados para executar o código neste tutorial)
- Ativar o Gateway de componentes
- Usar a versão de imagem 2.0
- Usar a flag
--propertiespara adicionar a configuração e a biblioteca do HBase aos caminhos de classe do driver e do executor do Spark.
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Verificar a instalação do conector
No Google Cloud console ou em um terminal de sessão do Cloud Shell, use SSH no nó mestre do cluster do Serviço Gerenciado para Apache Spark.
Verifique a instalação do conector do Apache HBase Spark no nó mestre:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Mantenha o terminal de sessão SSH aberto para:
- Criar uma tabela do HBase
- (Usuários Java): execute comandos no nó mestre do cluster para determinar as versões dos componentes instalados no cluster
- Verificar a tabela do HBase depois de você executar o código
Criar uma tabela do HBase
Execute os comandos listados nesta seção no terminal de sessão SSH do nó mestre que você abriu na etapa anterior.
Abra o shell do HBase:
hbase shell
Crie uma tabela do HBase "my-table" com um grupo de colunas "cf":
create 'my_table','cf'
- Para confirmar a criação da tabela, no Google Cloud console, clique em HBase
nos Google Cloud links do Gateway de componentes do console
para abrir a interface do Apache HBase.
my-tableestá listada na seção Tabelas da página Início.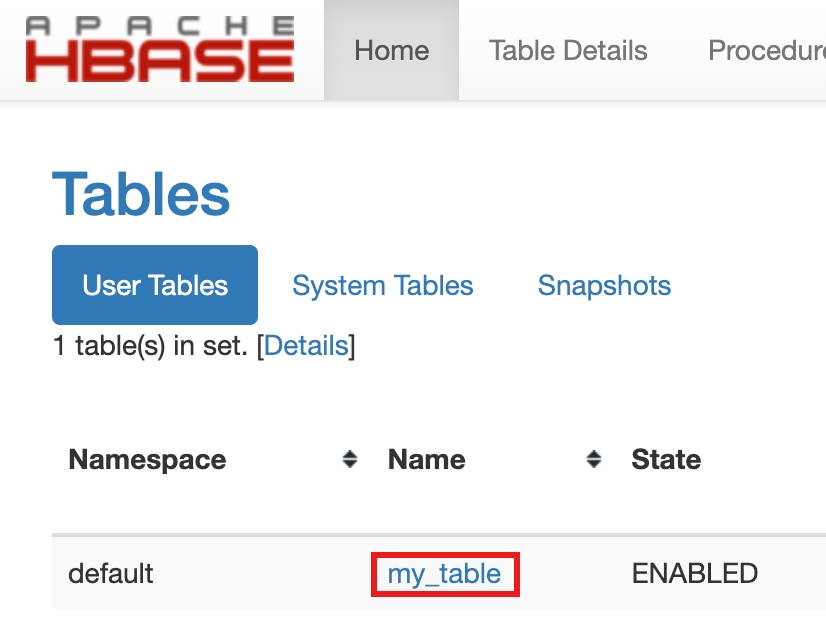
- Para confirmar a criação da tabela, no Google Cloud console, clique em HBase
nos Google Cloud links do Gateway de componentes do console
para abrir a interface do Apache HBase.
Conferir o código do Spark
Java
Python
Executar o código
Abra um terminal de sessão do Cloud Shell.
Clone o repositório GitHub GoogleCloudDataproc/cloud-dataproc no terminal de sessão do Cloud Shell:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Mude para o diretório
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Envie o job do Serviço Gerenciado para Apache Spark.
Java
- Defina as versões dos componentes no arquivo
pom.xml.- A página de versões do Serviço Gerenciado para Apache Spark
2.0.x
lista as versões dos componentes Scala, Spark e HBase instalados
com as quatro versões secundárias mais recentes e anteriores da imagem 2.0.
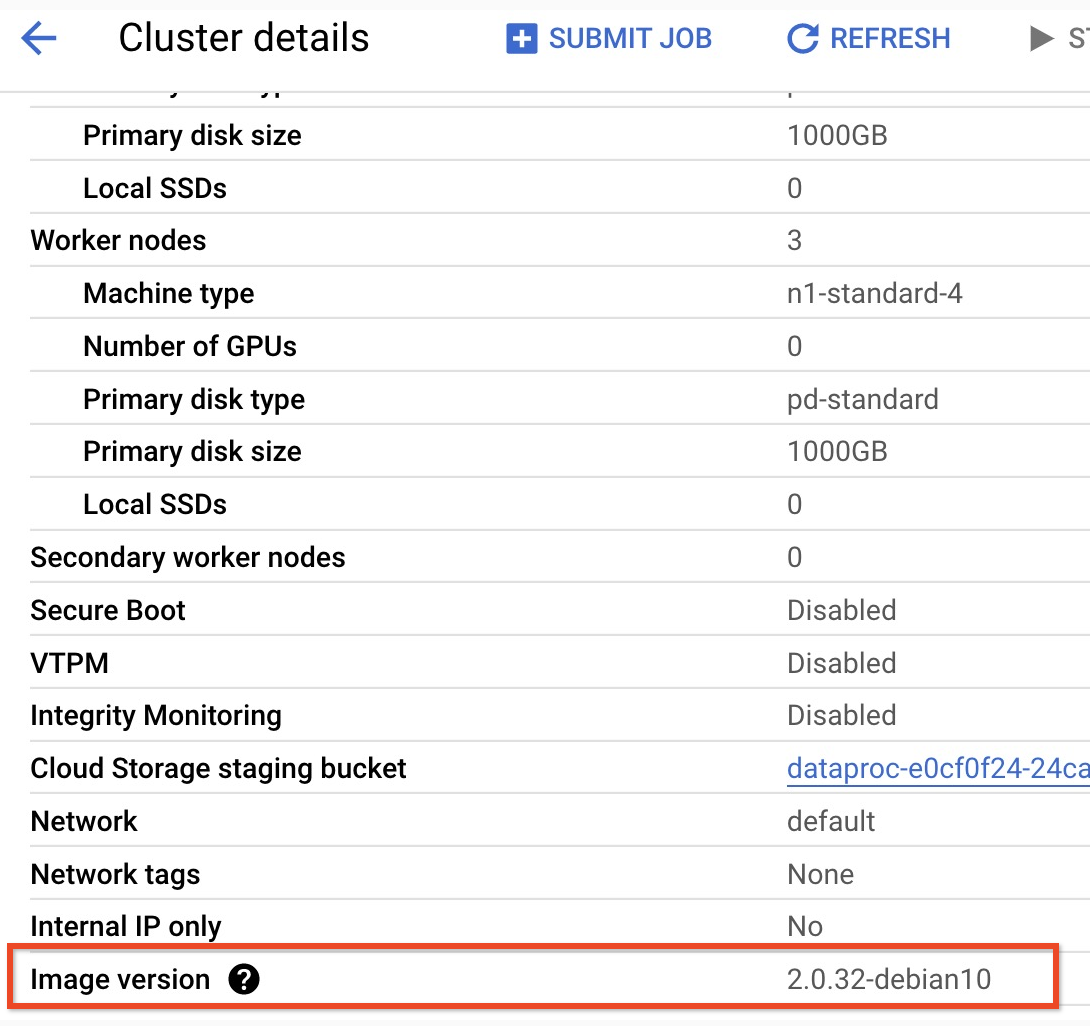
- Para encontrar a versão secundária do cluster da versão de imagem 2.0,
clique no nome do cluster na página
Clusters no
Google Cloud console para abrir a página Detalhes do cluster, em que a
versão da imagem do cluster está listada.
- Para encontrar a versão secundária do cluster da versão de imagem 2.0,
clique no nome do cluster na página
Clusters no
Google Cloud console para abrir a página Detalhes do cluster, em que a
versão da imagem do cluster está listada.
- Como alternativa, você pode executar os comandos a seguir em um
terminal de sessão SSH
do nó mestre do cluster para determinar as versões dos componentes:
- Verifique a versão do Scala:
scala -version
- Verifique a versão do Spark (control-D para sair):
spark-shell
- Verifique a versão do HBase:
hbase version
- Identifique as dependências de versão do Spark, Scala e HBase
no Maven
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versioné a versão atual do conector do Spark HBase. Deixe esse número de versão inalterado.
- Verifique a versão do Scala:
- Edite o arquivo
pom.xmlno editor do Cloud Shell para inserir os números de versão corretos do Scala, Spark e HBase. Clique em Abrir terminal quando terminar de editar para retornar à linha de comando do terminal do Cloud Shell.cloudshell edit .
- Mude para o Java 8 no Cloud Shell. Essa versão do JDK é necessária para criar o código. Ignore todas as mensagens de aviso do plug-in:
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Verifique a instalação do Java 8:
java -version
openjdk version "1.8..."
- A página de versões do Serviço Gerenciado para Apache Spark
2.0.x
lista as versões dos componentes Scala, Spark e HBase instalados
com as quatro versões secundárias mais recentes e anteriores da imagem 2.0.
- Crie o arquivo
jar:mvn clean package
.jaré colocado no subdiretório/target, por exemplo,target/spark-hbase-1.0-SNAPSHOT.jar. Envie o job.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: insira o nome do arquivo.jarapós "target/" e antes de ".jar".- Se você não definiu os caminhos de classe do HBase do driver e do executor do Spark ao
criar o cluster,
é necessário defini-los com cada envio de job, incluindo a
seguinte flag
‑‑propertiesno comando de envio do job:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Confira a saída da tabela do HBase na saída do terminal de sessão do Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
Envie o job.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Se você não definiu os caminhos de classe do HBase do driver e do executor do Spark ao
criar o cluster,
é necessário defini-los com cada envio de job, incluindo a
seguinte flag
‑‑propertiesno comando de envio do job:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Se você não definiu os caminhos de classe do HBase do driver e do executor do Spark ao
criar o cluster,
é necessário defini-los com cada envio de job, incluindo a
seguinte flag
Confira a saída da tabela do HBase na saída do terminal de sessão do Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Verificar a tabela do HBase
É possível verificar o conteúdo da tabela do HBase executando os comandos a seguir no terminal de sessão SSH do nó mestre que você abriu em Verificar a instalação do conector:
- Abra o shell do HBase:
hbase shell
- Verifique "my-table":
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Limpar
Depois de concluir o tutorial, você pode limpar os recursos que criou para que eles parem de usar a cota e gerar cobranças. Nas seções a seguir, você aprenderá a excluir e desativar esses recursos.
Exclua o projeto
O jeito mais fácil de evitar cobranças é excluindo o projeto que você criou para o tutorial.
Para excluir o projeto:
- No Google Cloud console, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Desligar para excluir o projeto.
excluir o cluster
- Para excluir o cluster:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}