
Objetivos
En este instructivo, se muestra cómo hacer lo siguiente:
- Crea un clúster de Managed Service para Apache Spark y, luego, instala Apache HBase y Apache ZooKeeper en el clúster.
- Crea una tabla de HBase con la shell de HBase que se ejecuta en el nodo principal del clúster de Managed Service para Apache Spark.
- Usa Cloud Shell para enviar un trabajo de Java o PySpark Spark al servicio de Managed Service para Apache Spark que escribe datos en la tabla de HBase y, luego, los lee.
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto,
usa la calculadora de precios.
Antes de comenzar
Si aún no lo has hecho, crea un proyecto de Google Cloud Platform.
- Accede a tu Google Cloud cuenta de. Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataproc and Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
Crea un clúster de Managed Service para Apache Spark
Ejecuta el siguiente comando en una terminal de sesión de Cloud Shell para hacer lo siguiente:
- Instalar los componentes de HBase y ZooKeeper
- Aprovisionar tres nodos trabajadores (se recomiendan entre tres y cinco trabajadores para ejecutar el código en este instructivo)
- Habilitar la puerta de enlace de componentes
- Usar la versión de imagen 2.0
- Usar la marca
--propertiespara agregar la configuración de HBase y la biblioteca de HBase a las rutas de clase del controlador y el ejecutor de Spark
gcloud dataproc clusters create cluster-name \ --region=region \ --optional-components=HBASE,ZOOKEEPER \ --num-workers=3 \ --enable-component-gateway \ --image-version=2.0 \ --properties='spark:spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark:spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Verifica la instalación del conector
Desde la Google Cloud consola o una terminal de sesión de Cloud Shell,establece una conexión SSH a la instancia principal del clúster de Managed Service para Apache Spark.
Verifica la instalación del conector de Apache HBase Spark en el nodo principal:
ls -l /usr/lib/spark/jars | grep hbase-spark
-rw-r--r-- 1 root root size date time hbase-spark-connector.version.jar
Mantén abierta la terminal de sesión SSH para hacer lo siguiente:
- Crear una tabla de HBase
- (Usuarios de Java): Ejecutar comandos en el nodo principal del clúster para determinar las versiones de los componentes instalados en el clúster
- Analizar tu tabla de HBase después de ejecutar el código
Crea una tabla de HBase
Ejecuta los comandos que se enumeran en esta sección en la terminal de sesión SSH del nodo principal que abriste en el paso anterior.
Abre la shell de HBase:
hbase shell
Crea una tabla de HBase “my-table” con una familia de columnas “cf”:
create 'my_table','cf'
- Para confirmar la creación de la tabla, en la Google Cloud consola, haz clic en HBase
en los Google Cloud vínculos de la puerta de enlace de componentes de la consola
para abrir la IU de Apache HBase.
my-tableaparece en la sección Tablas de la página Principal.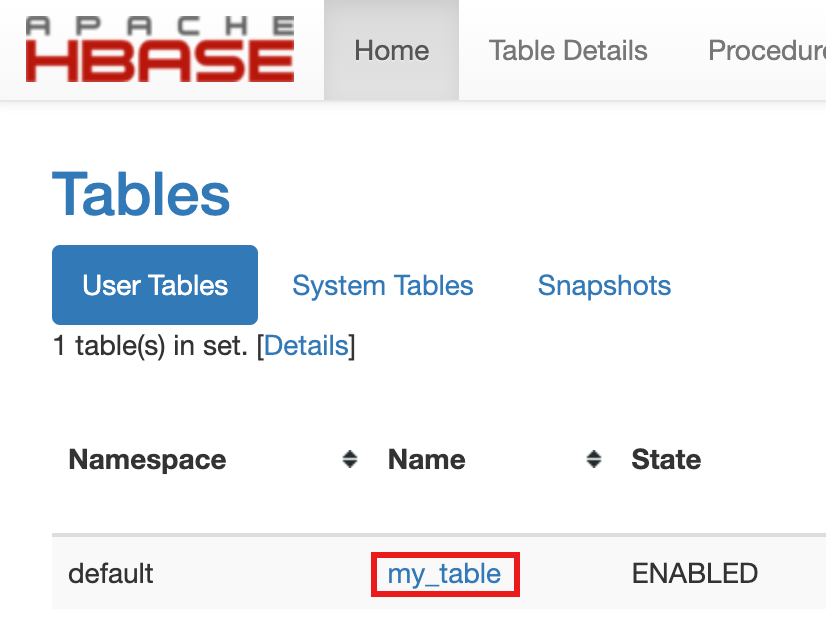
- Para confirmar la creación de la tabla, en la Google Cloud consola, haz clic en HBase
en los Google Cloud vínculos de la puerta de enlace de componentes de la consola
para abrir la IU de Apache HBase.
Consulta el código de Spark
Java
Python
Ejecuta el código
Abre una terminal de sesión de Cloud Shell.
Clona el repositorio de GitHub GoogleCloudDataproc/cloud-dataproc en la terminal de sesión de Cloud Shell:
git clone https://github.com/GoogleCloudDataproc/cloud-dataproc.git
Cambia al directorio
cloud-dataproc/spark-hbase:cd cloud-dataproc/spark-hbase
user-name@cloudshell:~/cloud-dataproc/spark-hbase (project-id)$
Envía el trabajo de Managed Service para Apache Spark.
Java
- Establece las versiones de los componentes en el archivo
pom.xml.- En la página de versiones de Managed Service para Apache Spark
2.0.x, se enumeran las versiones de los componentes de Scala, Spark y HBase instalados
con las cuatro versiones secundarias más recientes y las cuatro anteriores de la imagen 2.0.
- Para encontrar la versión secundaria de tu clúster de versión de imagen 2.0, haz clic en el nombre del clúster en la página Clústeres de laGoogle Cloud consola para abrir la página Detalles del clúster, en la que se muestra la versión de la imagen del clúster.
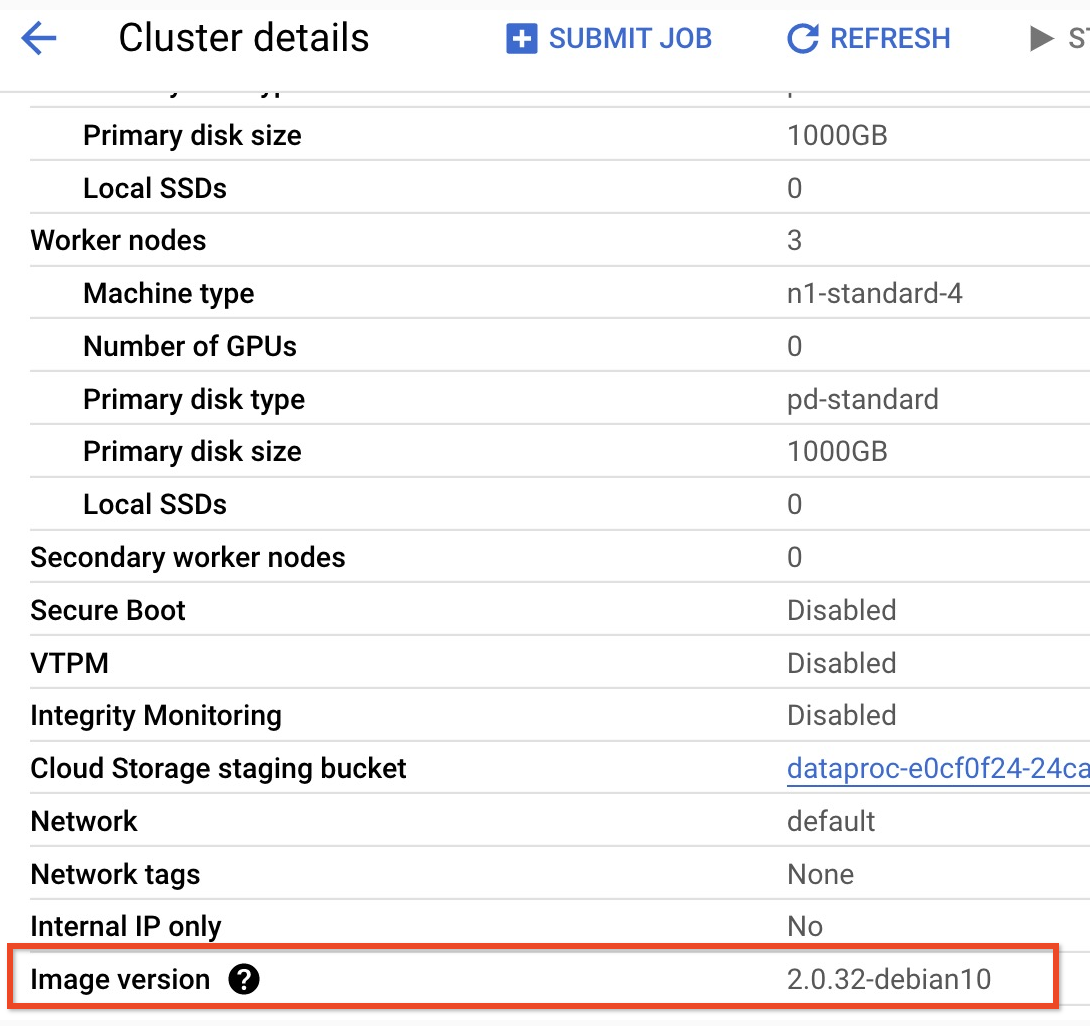
- Para encontrar la versión secundaria de tu clúster de versión de imagen 2.0, haz clic en el nombre del clúster en la página Clústeres de laGoogle Cloud consola para abrir la página Detalles del clúster, en la que se muestra la versión de la imagen del clúster.
- Como alternativa, puedes ejecutar los siguientes comandos en una
terminal de sesión SSH
desde el nodo principal de tu clúster para determinar las versiones de los componentes:
- Verifica la versión de Scala:
scala -version
- Verifica la versión de Spark (control-D para salir):
spark-shell
- Verifica la versión de HBase:
hbase version
- Identifica las dependencias de las versiones de Spark, Scala y HBase
en el Maven
pom.xml:<properties> <scala.version>scala full version (for example, 2.12.14)</scala.version> <scala.main.version>scala main version (for example, 2.12)</scala.main.version> <spark.version>spark version (for example, 3.1.2)</spark.version> <hbase.client.version>hbase version (for example, 2.2.7)</hbase.client.version> <hbase-spark.version>1.0.0(the current Apache HBase Spark Connector version)> </properties>
hbase-spark.versiones la versión actual del conector de Spark HBase; deja este número de versión sin cambios.
- Verifica la versión de Scala:
- Edita el archivo
pom.xmlen el editor de Cloud Shell para insertar los números de versión correctos de Scala, Spark y HBase. Haz clic en Abrir terminal cuando termines de editar para volver a la línea de comandos de la terminal de Cloud Shell.cloudshell edit .
- Cambia a Java 8 en Cloud Shell. Se necesita esta versión de JDK para compilar el código (puedes ignorar los mensajes de advertencia de complementos):
sudo update-java-alternatives -s java-1.8.0-openjdk-amd64 && export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
- Verifica la instalación de Java 8:
java -version
openjdk version "1.8..."
- En la página de versiones de Managed Service para Apache Spark
2.0.x, se enumeran las versiones de los componentes de Scala, Spark y HBase instalados
con las cuatro versiones secundarias más recientes y las cuatro anteriores de la imagen 2.0.
- Compila el archivo
jar:mvn clean package
.jarse coloca en el subdirectorio/target(por ejemplo,target/spark-hbase-1.0-SNAPSHOT.jar. Envía el trabajo.
gcloud dataproc jobs submit spark \ --class=hbase.SparkHBaseMain \ --jars=target/filename.jar \ --region=cluster-region \ --cluster=cluster-name
--jars: Inserta el nombre de tu archivo.jardespués de “target/” y antes de “.jar”.- Si no estableciste las rutas de clase de HBase del controlador y el ejecutor de Spark cuando
creaste el clúster,
debes establecerlas con cada envío de trabajo. Para ello, incluye la
siguiente
‑‑propertiesmarca en el comando de envío de trabajo:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
Visualiza el resultado de la tabla de HBase en el resultado de la terminal de sesión de Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Python
Envía el trabajo.
gcloud dataproc jobs submit pyspark scripts/pyspark-hbase.py \ --region=cluster-region \ --cluster=cluster-name
- Si no estableciste las rutas de clase de HBase del controlador y el ejecutor de Spark cuando
creaste el clúster,
debes establecerlas con cada envío de trabajo. Para ello, incluye la
siguiente
‑‑propertiesmarca en el comando de envío de trabajo:--properties='spark.driver.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*,spark.executor.extraClassPath=/etc/hbase/conf:/usr/lib/hbase/*'
- Si no estableciste las rutas de clase de HBase del controlador y el ejecutor de Spark cuando
creaste el clúster,
debes establecerlas con cada envío de trabajo. Para ello, incluye la
siguiente
Visualiza el resultado de la tabla de HBase en el resultado de la terminal de sesión de Cloud Shell:
Waiting for job output... ... +----+----+ | key|name| +----+----+ |key1| foo| |key2| bar| +----+----+
Analiza la tabla de HBase
Para analizar el contenido de tu tabla de HBase, ejecuta los siguientes comandos en la terminal de sesión SSH del nodo principal que abriste en Verifica la instalación del conector:
- Abre la shell de HBase:
hbase shell
- Analiza “my-table”:
scan 'my_table'
ROW COLUMN+CELL key1 column=cf:name, timestamp=1647364013561, value=foo key2 column=cf:name, timestamp=1647364012817, value=bar 2 row(s) Took 0.5009 seconds
Limpia
Una vez que completes el instructivo, puedes limpiar los recursos que creaste para que dejen de usar la cuota y generar cargos. En las siguientes secciones, se describe cómo borrar o desactivar estos recursos.
Borra el proyecto
La manera más fácil de eliminar la facturación es borrar el proyecto que creaste para el instructivo.
Para borrar el proyecto, sigue estos pasos:
- En la Google Cloud consola, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que tú quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borra el clúster
- Para borrar tu clúster, realiza los siguientes pasos:
gcloud dataproc clusters delete cluster-name \ --region=${REGION}