
Auf dieser Seite erfahren Sie, wie Sie einen Managed Service for Apache Spark-Cluster erstellen, der den Spark Spanner-Connector verwendet, um mit Apache SparkDaten aus Spanner zu lesen und in Spanner zu schreiben.
Der Spanner-Connector verwendet die Spanner Java-Bibliothek, um mit Spark Daten aus der Spanner-Datenbank zu lesen und in die Spanner-Datenbank zu schreiben. Der Spanner-Connector unterstützt das Lesen von Spanner Tabellen und Diagrammen in Spark DataFrames und GraphFrames, sowie das Schreiben von DataFrame-Daten in Spanner-Tabellen.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
- Managed Service for Apache Spark
- Spanner
- Cloud Storage
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Verwenden Sie den Preisrechner.
Hinweis
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistung unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Spanner, Managed Service for Apache Spark, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Weisen Sie die erforderlichen Rollen zu.
- Richten Sie einen Managed Service for Apache Spark-Cluster ein.
- Richten Sie eine Spanner-Instanz mit einer Datenbanktabelle „Singers“ ein.
Erforderliche Rollen zuweisen
Bestimmte IAM-Rollen sind erforderlich, um die Beispiele auf dieser Seite auszuführen. Abhängig von den Organisationsrichtlinien wurden diese Rollen möglicherweise bereits gewährt. Informationen zum Prüfen von Rollenzuweisungen finden Sie unter Müssen Sie Rollen zuweisen?.
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Bitten Sie Ihren Administrator, dem Compute Engine-Standarddienstkonto die folgenden IAM-Rollen für das Projekt zuzuweisen, damit das Compute Engine-Standarddienstkonto die erforderlichen Berechtigungen zum Erstellen eines Managed Service for Apache Spark-Clusters hat:
-
Dataproc-Worker (
roles/dataproc.worker) -
Cloud Spanner-Datenbanknutzer (
roles/spanner.databaseUser) -
Cloud Spanner-Datenbankleser mit Data Boost (
roles/spanner.databaseReaderWithDataBoost)
Managed Service for Apache Spark-Cluster einrichten
Erstellen Sie einen Managed Service for Apache Spark-Cluster
oder verwenden Sie einen vorhandenen Managed Service for Apache Spark-Cluster, der mit dem
2.1 oder höher Managed Service for Apache Spark-Image erstellt wurde. Wenn der
Cluster mit dem 2.0 oder früher Image erstellt wurde, muss er mit
der scope Eigenschaft auf
cloud-platform festgelegt worden sein.
Spanner-Instanz mit einer Datenbanktabelle „Singers“ einrichten
Erstellen Sie eine Spanner-Instanz
mit einer Datenbank, die eine Tabelle Singers enthält. Notieren Sie sich die Spanner-Instanz-ID und die Datenbank-ID.
Spanner-Connector mit Spark verwenden
Der Spanner-Connector ist für Spark-Versionen 3.1+ verfügbar. Sie
geben die
Connector-Version
als Teil der JAR-Datei-Spezifikation des Cloud Storage-Connectors an, wenn Sie
einen Job senden an einen
Managed Service for Apache Spark-Cluster.
Beispiel:gcloud CLI-Spark-Jobübermittlung mit dem Spanner-Connector.
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar \ ... [other job submission flags]
Ersetzen Sie Folgendes:
CONNECTOR_VERSION: Spanner-Connector-Version.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub
GoogleCloudDataproc/spark-spanner-connector Repository aus.
Spanner-Tabellen lesen
Mit Python oder Scala können Sie Spanner-Tabellendaten über die Spark-Datenquellen-API in ein Spark-DataFrame lesen.
PySpark
Sie können den PySpark-Beispielcode in diesem Abschnitt in Ihrem Cluster ausführen, indem Sie den Job an den Managed Service for Apache Spark-Dienst senden oder den Job über die spark-submit-REPL auf dem Clustermaster ausführen.
Managed Service for Apache Spark-Job
- Erstellen Sie eine
singers.py-Datei in einem lokalen Texteditor oder in Cloud Shell mit dem vorinstallierten Texteditorvi,vimodernano. - Nachdem Sie die Platzhaltervariablen ausgefüllt haben, fügen Sie den folgenden Code
in die
singers.pyDatei ein. Beachten Sie, dass die Spanner Data Boost Funktion aktiviert ist, die sich kaum auf die Haupt-Spanner-Instanz auswirkt.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Google Cloud Projekt-ID. Projekt-IDs werden im Bereich Projektinformationen im Console- Google Cloud Dashboard aufgeführt.
- INSTANCE_ID, DATABASE_ID, und TABLE_NAME : Informationen finden Sie unter
Spanner-Instanz mit
SingersDatenbanktabelle einrichten.
- Speichern Sie die Datei
singers.py. - Senden Sie den Job
über die Google Cloud Console, die gcloud CLI oder die
REST API an Managed Service for Apache Spark.
Beispiel:gcloud CLI-Jobübermittlung mit dem Spanner-Connector.
gcloud dataproc jobs submit pyspark singers.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jarErsetzen Sie Folgendes:
- CLUSTER_NAME: Der Name des neuen Clusters.
- REGION: Eine verfügbare Compute Engine Region zum Ausführen der Arbeitslast.
- CONNECTOR_VERSION: Spanner-Connector-Version.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub
GoogleCloudDataproc/spark-spanner-connectorRepository aus.
`spark-submit`-Job
- Stellen Sie über SSH eine Verbindung zum Clustermaster des Managed Service for Apache Spark-Clusters her.
- Rufen Sie in der Console die Seite Cluster von Managed Service for Apache Spark auf und klicken Sie dann auf den Namen Ihres Clusters. Google Cloud
- Wählen Sie auf der Seite Clusterdetails den Tab VM-Instanzen aus. Klicken Sie dann rechts neben dem Namen des Clustermasters auf
SSH.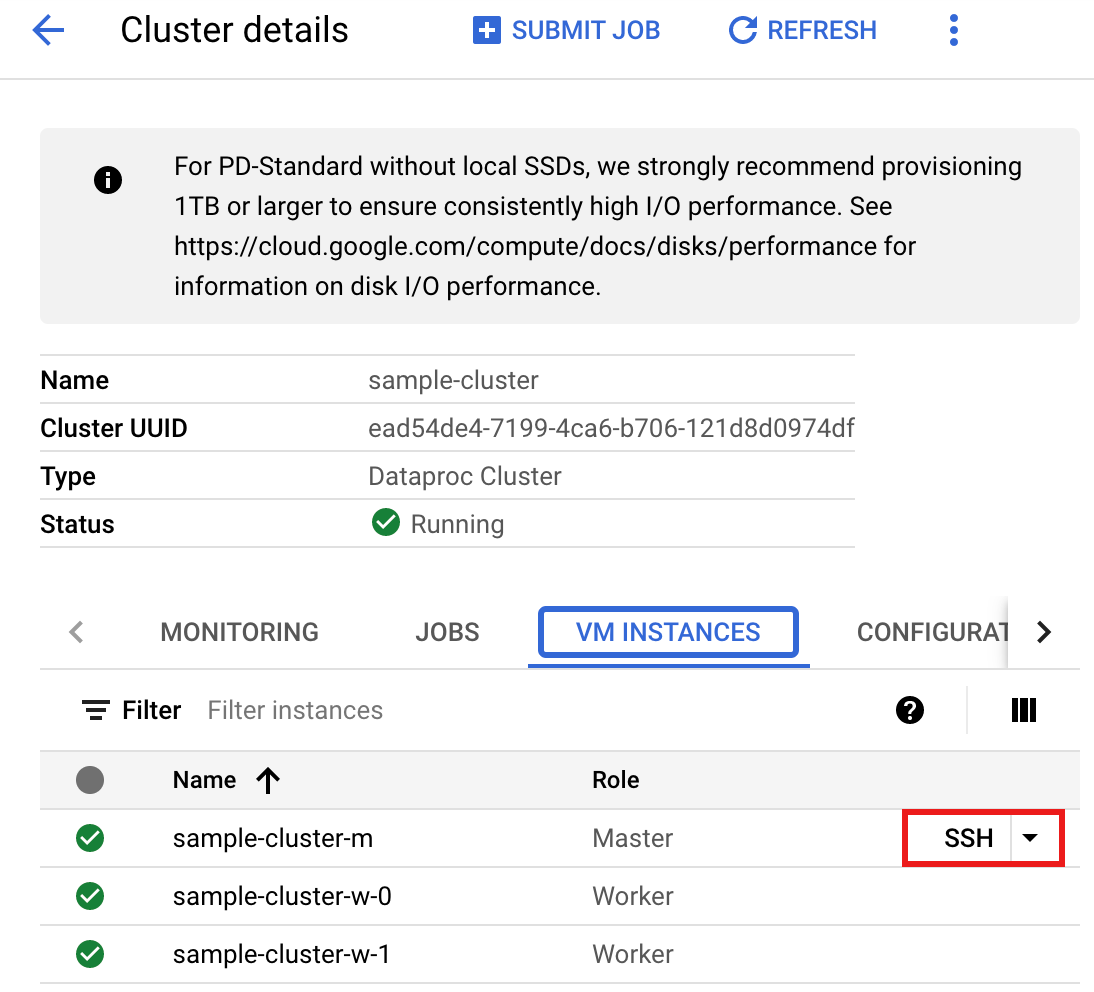
Im Stammverzeichnis des Masterknotens wird ein Browserfenster geöffnet.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Erstellen Sie mit dem vorinstallierten Texteditor
vi,vimodernanoeinesingers.py-Datei auf dem Masterknoten.- Fügen Sie den folgenden Code in die Datei
singers.pyein, nachdem Sie die Platzhaltervariablen in die Dateisingers.pyeingefügt haben. Beachten Sie, dass die Spanner Data Boost Funktion aktiviert ist, die sich kaum auf die Haupt-Spanner-Instanz auswirkt.#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") \ .option("instanceId", "INSTANCE_ID") \ .option("databaseId", "DATABASE_ID") \ .option("table", "TABLE_NAME") \ .option("enableDataBoost", "true") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Google Cloud Projekt-ID. Projekt-IDs werden im Bereich Projektinformationen im Console- Google Cloud Dashboard aufgeführt.
- INSTANCE_ID, DATABASE_ID, und TABLE_NAME : Informationen finden Sie unter
Spanner-Instanz mit
SingersDatenbanktabelle einrichten.
- Speichern Sie die Datei
singers.py.
- Fügen Sie den folgenden Code in die Datei
- Führen Sie
singers.pymitspark-submitaus, um die SpannerSingersTabelle zu erstellen.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
Ersetzen Sie Folgendes:
- CONNECTOR_VERSION: Spanner-Connector-Version.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub
GoogleCloudDataproc/spark-spanner-connectorRepository aus.
Die Ausgabe sieht so aus:
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- CONNECTOR_VERSION: Spanner-Connector-Version.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub
Scala
Führen Sie die folgenden Schritte aus, um den Scala-Beispielcode in Ihrem Cluster auszuführen:
- Stellen Sie über SSH eine Verbindung zum Clustermaster des Managed Service for Apache Spark-Clusters her.
- Rufen Sie in der Console die Seite Cluster von Managed Service for Apache Spark auf und klicken Sie dann auf den Namen Ihres Clusters. Google Cloud
- Wählen Sie auf der Seite Clusterdetails den Tab VM-Instanzen aus. Klicken Sie dann rechts neben dem Namen des Clustermasters auf
SSH.
Im Stammverzeichnis des Masterknotens wird ein Browserfenster geöffnet.
Connected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Erstellen Sie mit dem vorinstallierten Texteditor
vi,vimodernanoeinesingers.scala-Datei auf dem Masterknoten.- Fügen Sie den folgenden Code in die Datei
singers.scalaein. Beachten Sie, dass die Spanner Data Boost Funktion aktiviert ist, die sich kaum auf die Haupt-Spanner-Instanz auswirkt.object singers { def main(): Unit = { /* * Uncomment (use the following code) if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .option("enableDataBoost", true) .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
Ersetzen Sie Folgendes:
- PROJECT_ID: Ihre Google Cloud Projekt-ID. Projekt-IDs werden im Bereich Projektinformationen im Console- Google Cloud Dashboard aufgeführt.
- INSTANCE_ID, DATABASE_ID, und TABLE_NAME : Informationen finden Sie unter
Spanner-Instanz mit
SingersDatenbanktabelle einrichten.
- Speichern Sie die Datei
singers.scala.
- Fügen Sie den folgenden Code in die Datei
- Starten Sie die
spark-shell-REPL.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Ersetzen Sie Folgendes:
CONNECTOR_VERSION: Spanner-Connector-Version. Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub
GoogleCloudDataproc/spark-spanner-connectorRepository aus. - Führen Sie
singers.scalamit dem Befehl:load singers.scalaaus , um die Spanner-TabelleSingerszu erstellen. Die Ausgabeliste enthält Beispiele aus der Ausgabe von „Singers“.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
Spanner-Diagramme lesen
Der Spanner-Connector unterstützt das Exportieren des Diagramms in separate
Knoten- und Edge-
DataFrames
sowie das direkte Exportieren in
GraphFrames
direkt.
Im folgenden Beispiel wird ein Spanner in einen GraphFrame exportiert. Dazu wird die Python-SpannerGraphConnectorKlasse verwendet, die in der
JAR-Datei des
Spanner-Connectors enthalten ist, um das
Spanner-Diagramm zu lesen.
from pyspark.sql import SparkSession connector_jar = "gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar" spark = (SparkSession.builder.appName("spanner-graphframe-graphx-example") .config("spark.jars.packages", "graphframes:graphframes:0.8.4-spark3.5-s_2.12") .config("spark.jars", connector_jar) .getOrCreate()) spark.sparkContext.addPyFile(connector_jar) from spannergraph import SpannerGraphConnector connector = (SpannerGraphConnector() .spark(spark) .project("PROJECT_ID") .instance("INSTANCE_ID") .database("DATABASE_ID") .graph("GRAPH_ID")) g = connector.load_graph() g.vertices.show() g.edges.show()
Ersetzen Sie Folgendes:
- CONNECTOR_VERSION: Spanner-Connector-Version.
Wählen Sie die Spanner-Connector-Version aus der Versionsliste im GitHub
GoogleCloudDataproc/spark-spanner-connector-Repository aus. - PROJECT_ID: Ihre Google Cloud Projekt-ID. Projekt-IDs werden im Bereich Projektinformationen im Console- Google Cloud Dashboard aufgeführt.
- INSTANCE_ID, DATABASE_ID und TABLE_NAME: Fügen Sie die Instanz-, Datenbank- und Diagramm-IDs ein.
Wenn Sie Knoten- und Edge-DataFrames anstelle von GraphFrames exportieren möchten, verwenden Sie stattdessen load_dfs:
df_vertices, df_edges, df_id_map = connector.load_dfs()
Spanner-Tabellen schreiben
Der Spanner-Connector unterstützt das Schreiben eines Spark-DataFrames in eine Spanner-Tabelle über die Spark-Datenquellen-API.
Beispiel für das Schreiben eines DataFrames in eine Spanner-Tabelle
Füllen Sie die Variablen aus, bevor Sie den Code speichern und ausführen.
"""Spanner PySpark write example.""" from pyspark.sql import SparkSession spark = SparkSession.builder.appName('Spanner Write App').getOrCreate() columns = ['id', 'name', 'email'] data = [(1, 'John Doe', 'john.doe@example.com'), (2, 'Jane Doe', 'jane.doe@example.com')] df = spark.createDataFrame(data, columns) df.write.format('cloud-spanner') \ .option("projectId", "PROJECT_ID") .option("instanceId", "INSTANCE_ID") .option("databaseId", "DATABASE_ID") .option("table", "TABLE_NAME") .mode("append") \ .save()
Ersetzen Sie Folgendes:
- PROJECT_ID: Die Google Cloud Projekt-ID. Projekt-IDs werden im Bereich Projektinformationen im Console- Google Cloud Dashboard aufgeführt.
- INSTANCE_ID, DATABASE_ID, und TABLE_NAME: Fügen Sie die Instanz-, Datenbank- und Tabellen-IDs ein.
Bereinigen
Damit Ihrem Google Cloud Konto keine laufenden Kosten entstehen, können Sie Ihren Managed Service for Apache Spark-Cluster beenden oder löschen und Ihre Spanner-Instanz löschen.
Nächste Schritte
- Informationen finden Sie in den
pyspark.sql.DataFrameBeispielen. - Informationen zur Sprachunterstützung für Spark-DataFrames finden Sie unter:
- Informationen finden Sie im Spark Spanner-Connector Repository auf GitHub.
- Informationen finden Sie unter Tipps zur Feinabstimmung von Spark-Jobs.