
目標
使用 Dataproc Hub 建立單一使用者 JupyterLab 筆記本環境,在 Managed Service for Apache Spark 叢集上執行。
建立筆記本,並在 Managed Service for Apache Spark 叢集上執行 Spark 工作。
刪除叢集,並將筆記本保留在 Cloud Storage 中。
事前準備
- 管理員必須授予您
notebooks.instances.use權限 (請參閱「設定 Identity and Access Management (IAM) 角色」)。
從 Dataproc Hub 建立 Dataproc JupyterLab 叢集
在 Google Cloud 控制台依序前往「Dataproc」→「Workbench」頁面,然後選取「使用者管理的筆記本」分頁標籤。
在列出管理員建立的 Dataproc Hub 執行個體資料列中,按一下「Open JupyterLab」(開啟 JupyterLab)。
- 如果您無法存取 Google Cloud 控制台,請在網頁瀏覽器中輸入管理員與您共用的 Dataproc Hub 執行個體網址。
在「Jupyterhub→Dataproc Options」(Jupyterhub→Dataproc 選項) 頁面中,選取叢集設定和區域。如果啟用,請指定任何自訂項目,然後按一下「建立」。
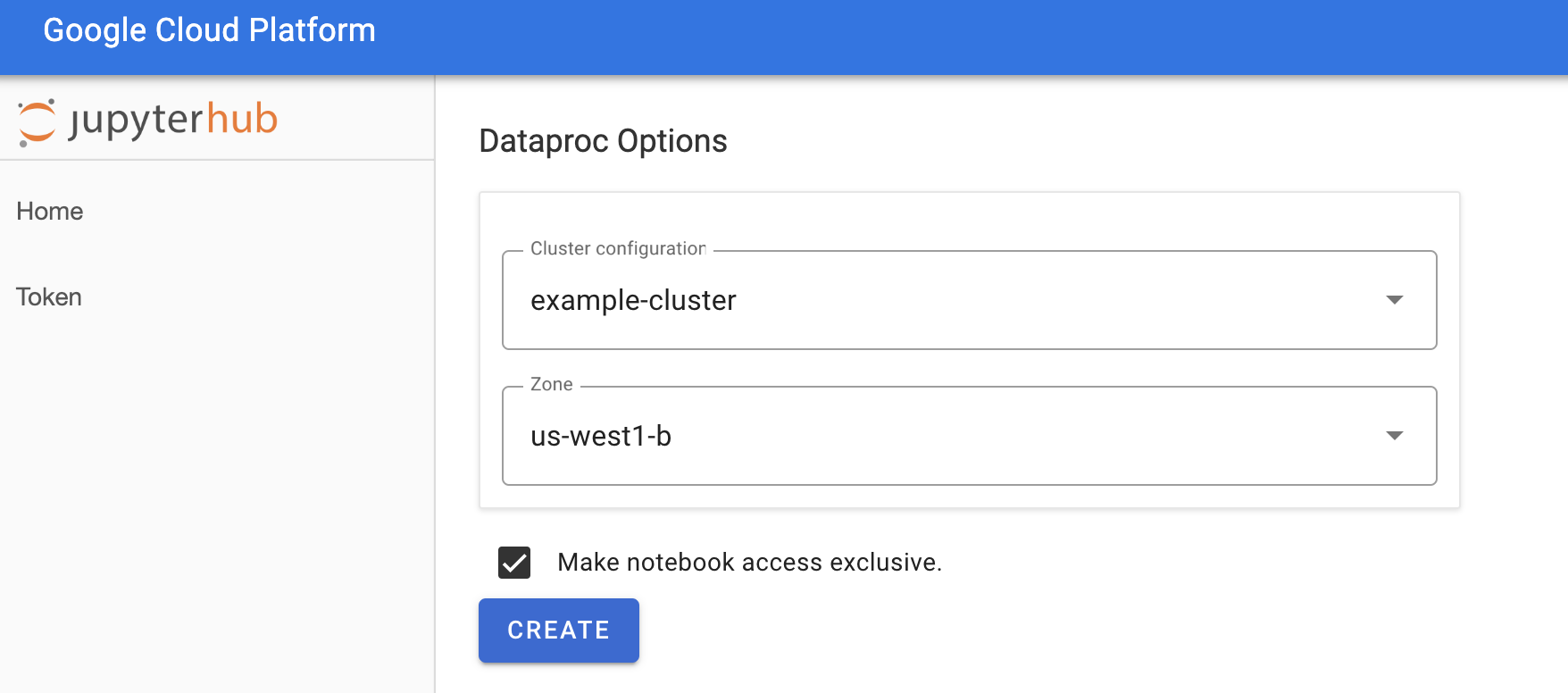
建立 Managed Service for Apache Spark 叢集後,系統會將您重新導向至叢集上執行的 JupyterLab 介面。
建立筆記本並執行 Spark 工作
在 JupyterLab 介面的左側面板中,按一下
GCS(Cloud Storage)。從 JupyterLab 啟動器建立 PySpark 筆記本。
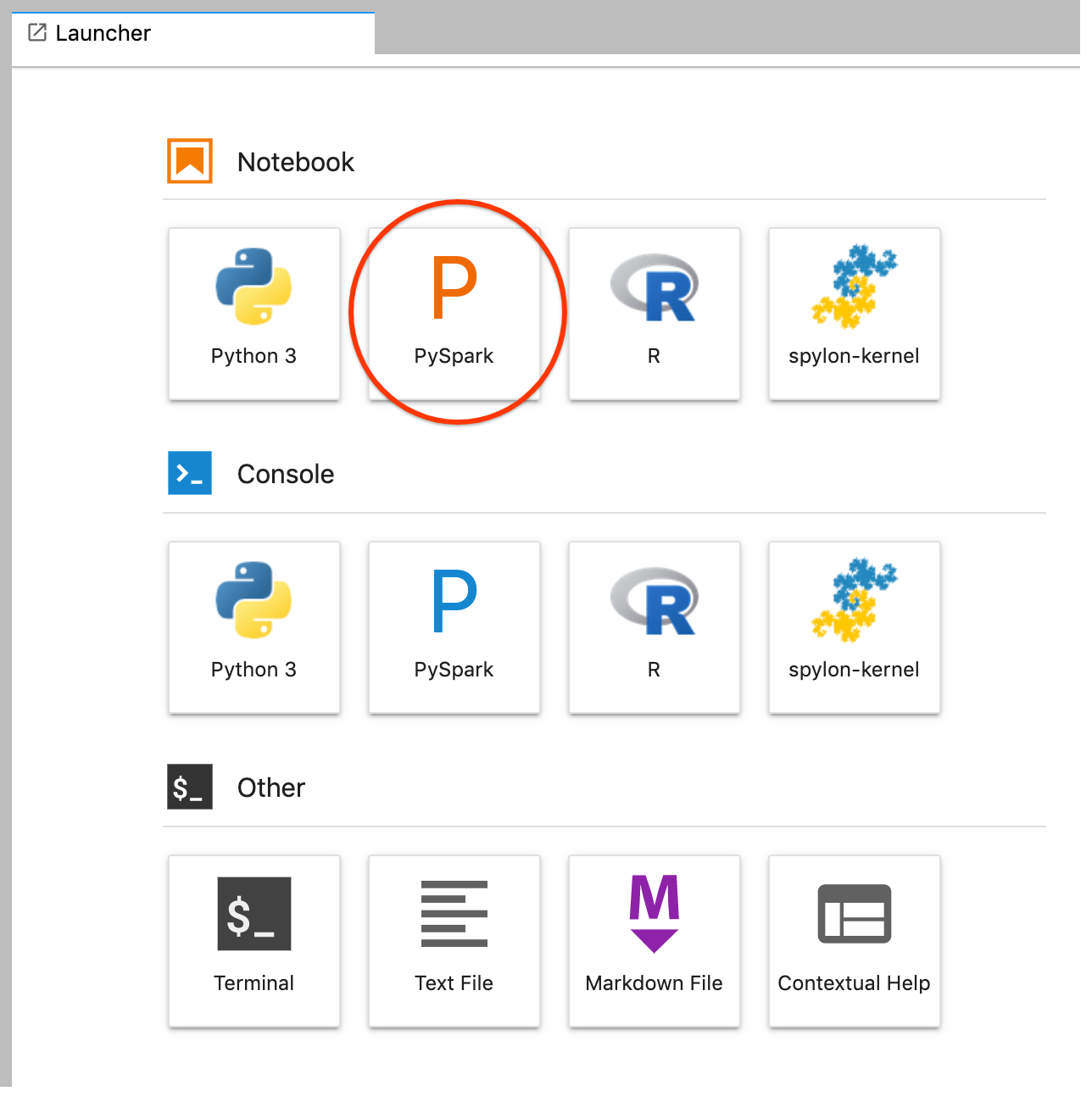
PySpark 核心會初始化 SparkContext (使用
sc變數)。您可以檢查 SparkContext,並從筆記本執行 Spark 工作。rdd = (sc.parallelize(['lorem', 'ipsum', 'dolor', 'sit', 'amet', 'lorem']) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a + b)) print(rdd.collect())
為筆記本命名並儲存。刪除 Managed Service for Apache Spark 叢集後,筆記本會儲存並保留在 Cloud Storage 中。
關閉 Dataproc 叢集
在 JupyterLab 介面中,選取「File」→「Hub Control Panel」,開啟 Jupyterhub 頁面。
按一下「停止我的叢集」即可關閉 (刪除) JupyterLab 伺服器,這會刪除 Managed Service for Apache Spark 叢集。
後續步驟
- 在 GitHub 上探索 Dataproc 的 Spark 和 Jupyter 筆記本。