
Apache Spark 專用的 BigQuery 連接器,能夠讓資料科學家將可靈活擴充的 SQL 引擎所具備的強大力量,與 Apache Spark 的機器學習功能相結合。在本教學課程中,我們將示範如何在資料集上使用 Managed Service for Apache Spark、BigQuery 和 Apache Spark ML 來執行機器學習。
目標
使用線性迴歸建構出生重量模型來做為五項因素的函式:- 懷孕週數
- 母親年齡
- 父親年齡
- 孕婦在懷孕期間增加的重量
- 阿普伽新生兒評分法
使用下列工具:
- BigQuery,用於準備寫入 Google Cloud 專案的線性迴歸輸入資料表
- Python,用於查詢及管理 BigQuery 中的資料
- Apache Spark,用於存取產生的線性迴歸資料表
- Spark ML,用於建構及評估模型
- Managed Service for Apache Spark PySpark 工作,用於叫用 Spark ML 函式
費用
在本文件中,您會使用下列 Google Cloud的計費元件:
- Compute Engine
- Managed Service for Apache Spark
- BigQuery
如要根據預測用量估算費用,請使用 Pricing Calculator。
事前準備
Managed Service for Apache Spark 叢集已安裝 Spark ML 等 Spark 元件。 如要設定 Managed Service for Apache Spark 叢集並執行本範例中的程式碼,您需要 (或已) 完成下列步驟:
- 登入 Google Cloud 帳戶。如果您是 Google Cloud新手,歡迎 建立帳戶,親自評估產品在實際工作環境中的成效。新客戶還能獲得價值 $300 美元的免費抵免額,可用於執行、測試及部署工作負載。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
安裝 Google Cloud CLI。
-
若您採用的是外部識別資訊提供者 (IdP),請先使用聯合身分登入 gcloud CLI。
-
執行下列指令,初始化 gcloud CLI:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
Enable the Dataproc, BigQuery, Compute Engine APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
安裝 Google Cloud CLI。
-
若您採用的是外部識別資訊提供者 (IdP),請先使用聯合身分登入 gcloud CLI。
-
執行下列指令,初始化 gcloud CLI:
gcloud init - 在專案中建立 Managed Service for Apache Spark 叢集。您的叢集必須使用 Spark 2.0 以上版本 (包括機器學習程式庫),才能執行 Managed Service for Apache Spark 版本。
建立 BigQuery natality 資料的子集
在本節中,您將會在專案中建立資料集,然後在資料集中建立資料表,再將出生率資料子集從開放大眾使用的出生率 BigQuery 資料集複製到該資料表中。稍後在本教學課程中,您將在這個資料表中使用子集資料,透過使用母親年齡、父親年齡與懷孕週數的函式來預測出生重量。
您可以使用 Google Cloud 控制台建立資料子集,或在本機電腦上執行 Python 指令碼。
控制台
在專案中建立資料集。
- 前往 BigQuery 網頁版 UI。
- 在左側的導覽面板中,按一下專案名稱,然後按一下「建立資料集」。
- 在「建立資料集」對話方塊中:
- 針對「Dataset ID」,輸入「natality_regression」。
- 針對「Data location」(資料位置),您可以選擇該資料集的位置。預設值位置為
US multi-region。請注意,資料集建立後即無法變更位置。 - 針對「Default table expiration」(預設資料表到期時間),選擇下列其中一個選項:
- 永不過期 (預設):您必須手動刪除資料表。
- 天數:資料表會在建立時間之後於指定天數內刪除。
- 在「加密」部分,選擇下列其中一個選項:
- Google-owned and Google-managed encryption key (預設)。
- 客戶自行管理的金鑰:請參閱「使用 Cloud KMS 金鑰保護資料」。
- 按一下「建立資料集」。
針對公開出生率資料集執行查詢,然後將查詢結果儲存在資料集的新資料表中。
- 複製下列查詢並貼到查詢編輯器,然後按一下「執行」。
CREATE OR REPLACE TABLE natality_regression.regression_input as SELECT weight_pounds, mother_age, father_age, gestation_weeks, weight_gain_pounds, apgar_5min FROM `bigquery-public-data.samples.natality` WHERE weight_pounds IS NOT NULL AND mother_age IS NOT NULL AND father_age IS NOT NULL AND gestation_weeks IS NOT NULL AND weight_gain_pounds IS NOT NULL AND apgar_5min IS NOT NULL
- 查詢完成後 (大約一分鐘後),結果會儲存在專案的
natality_regression資料集中,並命名為「regression_input」BigQuery 資料表。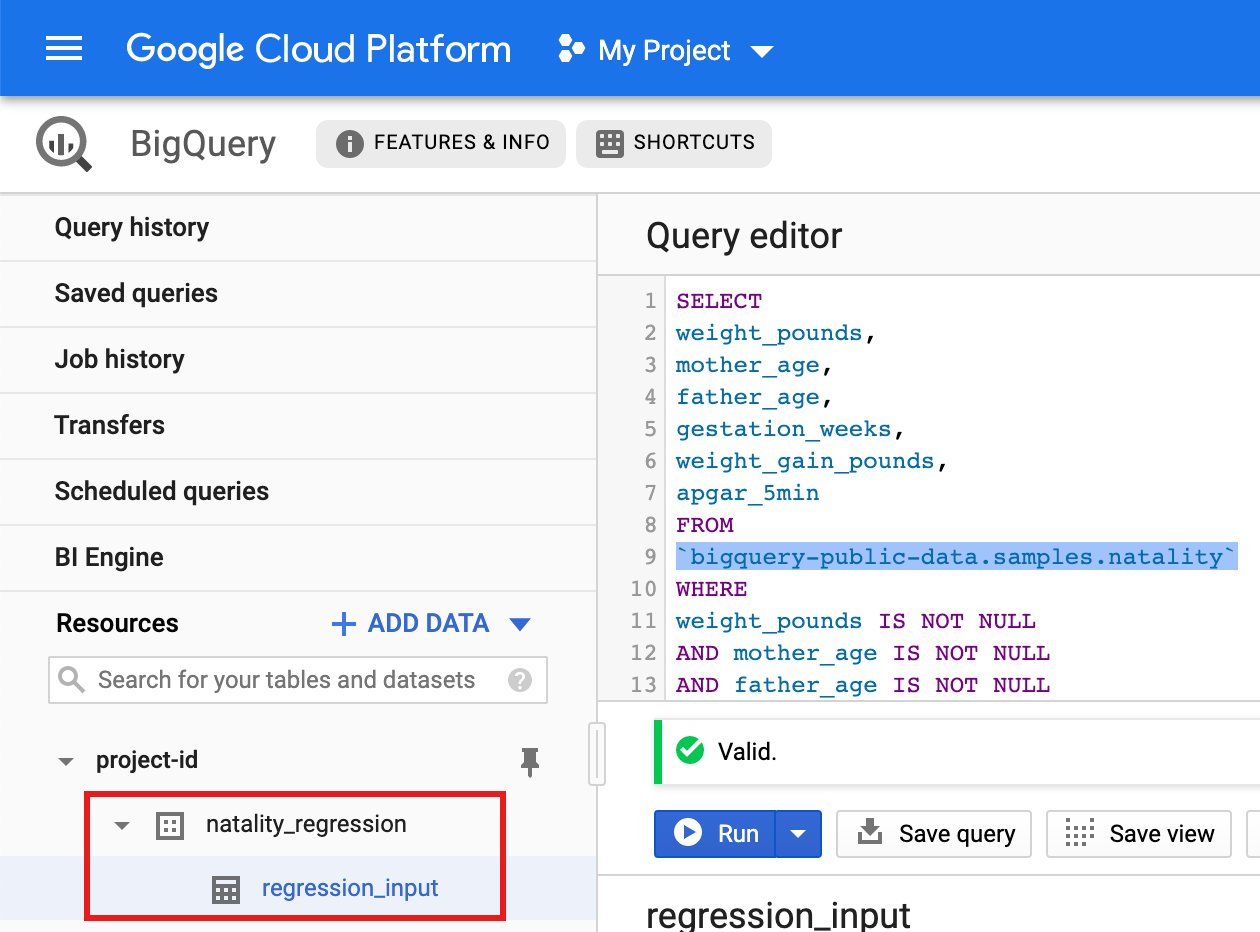
- 複製下列查詢並貼到查詢編輯器,然後按一下「執行」。
Python
在試用這個範例之前,請先按照「使用用戶端程式庫的 Managed Service for Apache Spark 快速入門導覽課程」中的 Python 設定說明操作。詳情請參閱 Managed Service for Apache Spark Python API 參考文件。
如要向 Managed Service for Apache Spark 進行驗證,請設定應用程式預設憑證。詳情請參閱「為本機開發環境設定驗證機制」。
如需安裝 Python 和 Python 專用的 Google Cloud 用戶端程式庫 (需執行程式碼) 的操作說明,請參閱設定 Python 開發環境一文。建議您安裝及使用 Python
virtualenv。請複製以下
natality_tutorial.py程式碼並貼到本機電腦上的python殼層。按一下殼層中的<return>鍵執行程式碼,以透過公開natality資料子集填入的「regression_input」資料表,在預設Google Cloud 專案中建立「natality_regression」 BigQuery 資料集。確認已建立
natality_regression資料集和regression_input資料表。
執行線性迴歸
在本節中,您將使用 Google Cloud 控制台將工作提交至 Managed Service for Apache Spark,或從本機終端機執行 gcloud 指令,藉此執行 PySpark 線性迴歸。
控制台
複製下列程式碼,然後貼到本機電腦上的新
natality_sparkml.py檔案中。"""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
將本機的
natality_sparkml.py檔案複製到專案的 Cloud Storage bucket。gcloud storage cp natality_sparkml.py gs://bucket-name
從 Managed Service for Apache Spark 的「Submit a job」(提交工作) 頁面執行迴歸。
在「Main python file」(主要 Python 檔案) 欄位中,插入
natality_sparkml.py檔案副本所在 Cloud Storage 值區的gs://URI。選取
PySpark做為「Job type」(工作類型)。在「Jar files」(JAR 檔案) 欄位中插入
gs://spark-lib/bigquery/spark-bigquery-latest_2.12.jar。這樣一來,PySpark 應用程式在執行階段就能使用 spark-bigquery-connector,將 BigQuery 資料讀取至 Spark DataFrame。填寫「Job ID」(工作 ID)、「Region」(區域) 和「Cluster」(叢集) 欄位。
按一下「提交」,在叢集上執行工作。
工作完成後,線性迴歸輸出模型摘要會顯示在 Managed Service for Apache Spark 工作詳細資料視窗中。
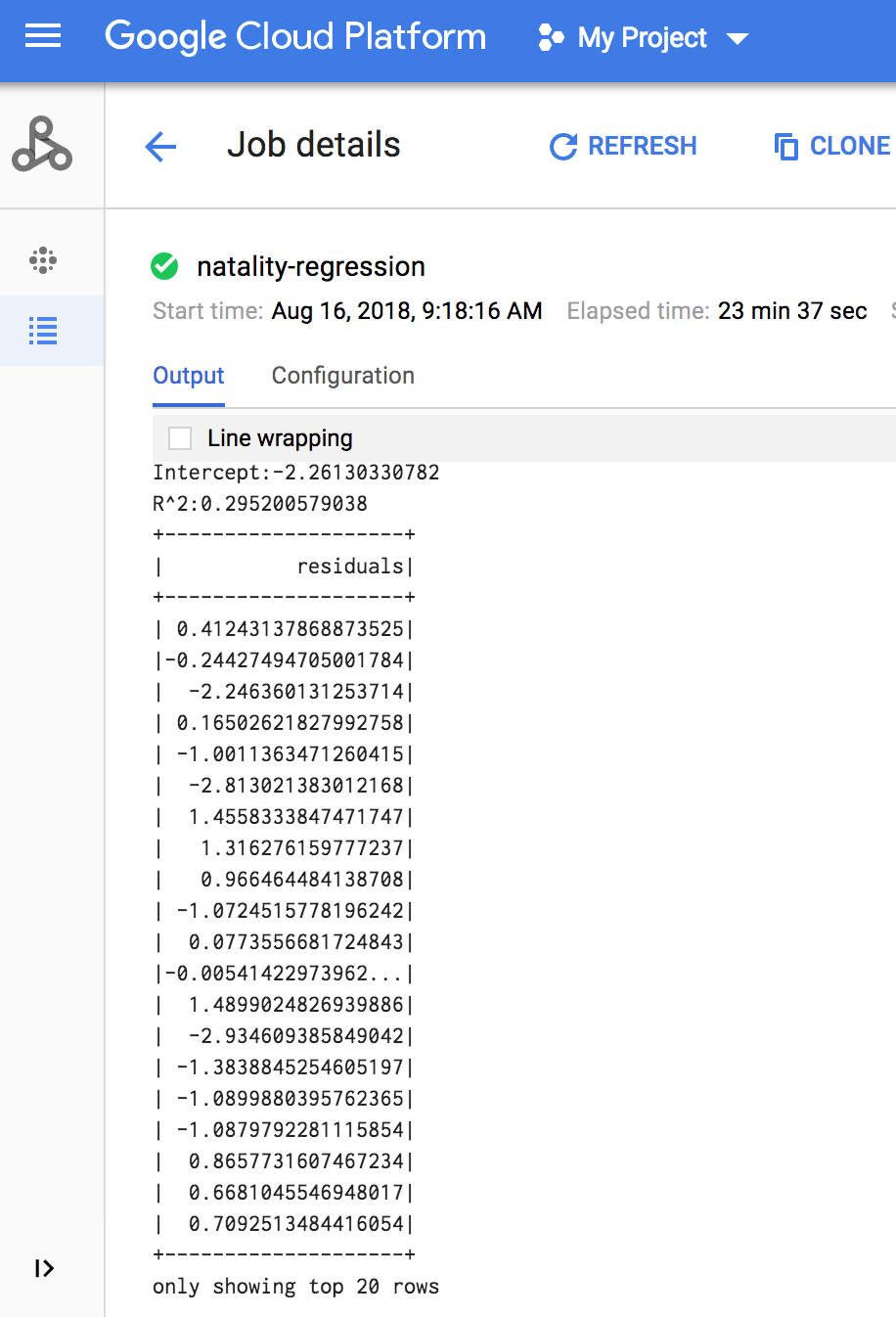
gcloud
複製下列程式碼,然後貼到本機電腦上的新
natality_sparkml.py檔案中。"""Run a linear regression using Apache Spark ML. In the following PySpark (Spark Python API) code, we take the following actions: * Load a previously created linear regression (BigQuery) input table into our Cloud Dataproc Spark cluster as an RDD (Resilient Distributed Dataset) * Transform the RDD into a Spark Dataframe * Vectorize the features on which the model will be trained * Compute a linear regression using Spark ML """ from pyspark.context import SparkContext from pyspark.ml.linalg import Vectors from pyspark.ml.regression import LinearRegression from pyspark.sql.session import SparkSession # The imports, above, allow us to access SparkML features specific to linear # regression as well as the Vectors types. # Define a function that collects the features of interest # (mother_age, father_age, and gestation_weeks) into a vector. # Package the vector in a tuple containing the label (`weight_pounds`) for that # row. def vector_from_inputs(r): return (r["weight_pounds"], Vectors.dense(float(r["mother_age"]), float(r["father_age"]), float(r["gestation_weeks"]), float(r["weight_gain_pounds"]), float(r["apgar_5min"]))) sc = SparkContext() spark = SparkSession(sc) # Read the data from BigQuery as a Spark Dataframe. natality_data = spark.read.format("bigquery").option( "table", "natality_regression.regression_input").load() # Create a view so that Spark SQL queries can be run against the data. natality_data.createOrReplaceTempView("natality") # As a precaution, run a query in Spark SQL to ensure no NULL values exist. sql_query = """ SELECT * from natality where weight_pounds is not null and mother_age is not null and father_age is not null and gestation_weeks is not null """ clean_data = spark.sql(sql_query) # Create an input DataFrame for Spark ML using the above function. training_data = clean_data.rdd.map(vector_from_inputs).toDF(["label", "features"]) training_data.cache() # Construct a new LinearRegression object and fit the training data. lr = LinearRegression(maxIter=5, regParam=0.2, solver="normal") model = lr.fit(training_data) # Print the model summary. print("Coefficients:" + str(model.coefficients)) print("Intercept:" + str(model.intercept)) print("R^2:" + str(model.summary.r2)) model.summary.residuals.show()
將本機的
natality_sparkml.py檔案複製到專案的 Cloud Storage bucket。gcloud storage cp natality_sparkml.py gs://bucket-name
在本機的終端機視窗中執行下方所示的
gcloud指令,將 Pyspark 工作提交至 Managed Service for Apache Spark。- --jars 旗標值會在執行階段提供 spark-bigquery-connector 給 PySpark 工作,讓工作能將 BigQuery 資料讀取至 Spark DataFrame。
gcloud dataproc jobs submit pyspark \ gs://your-bucket/natality_sparkml.py \ --cluster=cluster-name \ --region=region \ --jars=gs://spark-lib/bigquery/spark-bigquery-with-dependencies_SCALA_VERSION-CONNECTOR_VERSION.jar
- --jars 旗標值會在執行階段提供 spark-bigquery-connector 給 PySpark 工作,讓工作能將 BigQuery 資料讀取至 Spark DataFrame。
工作完成之後,線性迴歸輸出 (模型摘要) 會出現在終端機視窗中。
<<< # Print the model summary. ... print "Coefficients:" + str(model.coefficients) Coefficients:[0.0166657454602,-0.00296751984046,0.235714392936,0.00213002070133,-0.00048577251587] <<< print "Intercept:" + str(model.intercept) Intercept:-2.26130330748 <<< print "R^2:" + str(model.summary.r2) R^2:0.295200579035 <<< model.summary.residuals.show() +--------------------+ | residuals| +--------------------+ | -0.7234737533344147| | -0.985466980630501| | -0.6669710598385468| | 1.4162434829714794| |-0.09373154375186754| |-0.15461747949235072| | 0.32659061654192545| | 1.5053877697929803| | -0.640142797263989| | 1.229530260294963| |-0.03776160295256...| | -0.5160734239126814| | -1.5165972740062887| | 1.3269085258245008| | 1.7604670124710626| | 1.2348130901905972| | 2.318660276655887| | 1.0936947030883175| | 1.0169768511417363| | -1.7744915698181583| +--------------------+ only showing top 20 rows.
清除所用資源
完成教學課程後,您可以清除所建立的資源,這樣資源就不會繼續使用配額,也不會產生費用。下列各節將說明如何刪除或關閉這些資源。
刪除專案
如要避免付費,最簡單的方法就是刪除您為了本教學課程所建立的專案。
刪除專案的方法如下:
- 前往 Google Cloud 控制台的「Manage resources」(管理資源) 頁面。
- 在專案清單中選取要刪除的專案,然後點選「Delete」(刪除)。
- 在對話方塊中輸入專案 ID,然後按一下 [Shut down] (關閉) 以刪除專案。
刪除 Managed Service for Apache Spark 叢集
請參閱刪除叢集說明。
後續步驟
- 請參閱 Spark 工作調整提示