
Dataproc NodeGroup 資源是一組 Dataproc 叢集節點,用於執行指派的角色。本頁面為驅動程式節點群組的說明。這組節點是獲派 Driver 角色的 Compute Engine VM 群組,用於在 Dataproc 叢集執行工作驅動程式。
使用驅動程式節點群組的時機
- 只有需要在共用叢集執行多項並行工作時,才使用驅動程式節點群組。
- 使用這種群組前請先增加主要節點資源,以避免驅動程式節點群組限制。
驅動程式節點如何協助您執行並行工作
Dataproc 會在 Dataproc 叢集主要節點中,為各工作啟動工作驅動程式程序,而驅動程式程序會以子程序的形式,執行應用程式驅動程式 (例如 spark-submit)。不過,在主要節點執行的並行工作數量,會受到該節點的可用資源所限制,而且 Dataproc 的主要節點無法擴充,所以如果資源不足,工作就有可能失敗或遭節流。
驅動程式節點群組是由 YARN 管理的特殊節點群組,因此工作並行數不受主要節點資源限制。在含有這類群組的叢集中,應用程式驅動程式會在驅動程式節點執行。如有足夠的資源,各驅動程式節點都可以執行多個應用程式驅動程式。
優點
含有驅動程式節點群組的 Dataproc 叢集可以執行下列操作:
- 水平調度工作驅動程式資源,執行更多並行工作。
- 與 worker 資源分開調度驅動程式資源。
- 在 Dataproc 2.0 以上版本的映像檔叢集縮減更快速。在這類叢集,應用程式主要節點會在這種群組的 Spark 驅動程式中執行 (
spark.yarn.unmanagedAM.enabled預設為true)。 - 自訂驅動程式節點啟動程序。您可以在初始化指令碼加入
{ROLE} == 'Driver',讓指令碼在選擇節點時為驅動程式節點群組執行動作。
限制
- Dataproc 工作流程範本不支援節點群組。
- 節點群組叢集無法停止、重新啟動或自動調度資源。
- MapReduce 應用程式主要執行個體在 worker 節點上執行,如果啟用安全停用程序,worker 節點的縮減速度可能會較慢。
- 並行工作數會受到
dataproc:agent.process.threads.job.max叢集屬性影響。舉例來說,如果叢集有三個主要節點,且該屬性為預設值100,則叢集層級的並行工作數上限為300。
比較驅動程式節點群組和 Spark 叢集模式
| 功能 | Spark 叢集模式 | 驅動程式節點群組 |
|---|---|---|
| 縮減 worker 節點 | 長期運作的驅動程式和短期運作的容器都在相同的 worker 節點上執行,因此透過安全停用程序縮減 worker 的速度較慢。 | 驅動程式在節點群組執行,worker 節點縮減較快。 |
| 串流驅動程式輸出內容 | 必須搜尋 YARN 記錄,才能找出排定驅動程式的節點。 | 驅動程式輸出內容會串流至 Cloud Storage,可於工作完成後在 Google Cloud 控制台和 gcloud dataproc jobs wait 指令輸出查看。 |
驅動程式節點群組 IAM 權限
下列 IAM 權限與 Dataproc 節點群組相關動作有關。
| 權限 | 動作 |
|---|---|
dataproc.nodeGroups.create
|
建立 Dataproc 節點群組。如果使用者在專案中具備 dataproc.clusters.create 權限,系統就會授予這項權限。 |
dataproc.nodeGroups.get |
取得 Dataproc 節點群組的詳細資料。 |
dataproc.nodeGroups.update |
調整 Dataproc 節點群組的大小。 |
驅動程式節點群組作業
您可以透過 gcloud CLI 和 Dataproc API,建立、取得、刪除 Dataproc 驅動程式節點群組、調整群組大小,以及將工作提交至該群組。
建立驅動程式節點群組叢集
一個驅動程式節點群組會與一個 Dataproc 叢集相關聯。建立節點群組是建立 Dataproc 叢集的步驟之一。您可以透過 gcloud CLI 或 Dataproc REST API,建立含有驅動程式節點群組的 Dataproc 叢集。
gcloud
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --driver-pool-size=SIZE \ --driver-pool-id=NODE_GROUP_ID
必要旗標:
- CLUSTER_NAME:叢集名稱,在專案內不得重複。名稱開頭須為小寫英文字母,最多包含 51 個小寫英文字母、數字和連字號,而且結尾不得為連字號。可以重複使用已刪除叢集的名稱。
- REGION:叢集所在的區域。
- SIZE:節點群組的驅動程式節點數量。所需數量取決於工作負載和驅動程式集區機型。節點數量「下限」等於工作驅動程式所需的記憶體總量或 vCPU 數量,除以每個驅動程式集區的機器記憶體量或 vCPU 數量。
- NODE_GROUP_ID:這是選用項目,但建議使用。ID 在叢集內不得重複。日後執行作業 (例如調整節點群組大小) 時,可以透過這組 ID 辨別驅動程式群組。如未指定,Dataproc 會自動產生節點群組 ID。
建議旗標:
--enable-component-gateway:新增這個旗標即可啟用 Dataproc 元件閘道,存取 YARN 網頁介面。YARN UI 的「Application」(應用程式) 和「Scheduler」(排程器) 頁面會顯示叢集和工作狀態、應用程式佇列記憶體、核心資源和其他指標。
其他旗標:您可以在 gcloud dataproc clusters create 指令加入下列選用 driver-pool 旗標,自訂節點群組。
| 旗標 | 預設值 |
|---|---|
--driver-pool-id |
如未透過旗標指定,服務會自動產生這組字串 ID。日後執行節點集區作業 (例如調整節點群組大小) 時,可以透過這組 ID 辨別節點群組。 |
--driver-pool-machine-type |
n1-standard-4 |
--driver-pool-accelerator |
沒有預設值。指定加速器時,則必須填入 GPU 類型,GPU 數量則為選填。 |
--num-driver-pool-local-ssds |
無預設 |
--driver-pool-local-ssd-interface |
無預設 |
--driver-pool-boot-disk-type |
pd-standard |
--driver-pool-boot-disk-size |
1000 GB |
--driver-pool-min-cpu-platform |
AUTOMATIC |
REST
完成 Dataproc API cluster.create 要求內的 AuxiliaryNodeGroup。
使用任何要求資料前,請先更改下列內容:
- PROJECT_ID:必填,Google Cloud 專案 ID。
- REGION:必填,Dataproc 叢集區域。
- CLUSTER_NAME:必填,叢集名稱,在專案內不得重複。名稱開頭須為小寫英文字母,最多包含 51 個小寫英文字母、數字和連字號,而且結尾不得為連字號。可以重複使用已刪除叢集的名稱。
- SIZE:必填,節點群組的節點數量。
- NODE_GROUP_ID:這是選用項目,但建議使用。ID 在叢集內不得重複。日後執行作業 (例如調整節點群組大小) 時,可以透過這組 ID 辨別驅動程式群組。如未指定,Dataproc 會自動產生節點群組 ID。
其他選項:請參閱 NodeGroup。
HTTP 方法和網址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters
JSON 要求主體:
{
"clusterName":"CLUSTER_NAME",
"config": {
"softwareConfig": {
"imageVersion":""
},
"endpointConfig": {
"enableHttpPortAccess": true
},
"auxiliaryNodeGroups": [{
"nodeGroup":{
"roles":["DRIVER"],
"nodeGroupConfig": {
"numInstances": SIZE
}
},
"nodeGroupId": "NODE_GROUP_ID"
}]
}
}
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
{
"projectId": "PROJECT_ID",
"clusterName": "CLUSTER_NAME",
"config": {
...
"auxiliaryNodeGroups": [
{
"nodeGroup": {
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": SIZE,
"instanceNames": [
"CLUSTER_NAME-np-q1gp",
"CLUSTER_NAME-np-xfc0"
],
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-2a8224d2-...",
"instanceGroupManagerName": "dataproc-2a8224d2-..."
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
},
"nodeGroupId": "NODE_GROUP_ID"
}
]
},
}
取得驅動程式節點群組叢集中繼資料
您可以執行 gcloud dataproc node-groups describe 指令或透過 Dataproc API,取得驅動程式節點群組中繼資料。
gcloud
gcloud dataproc node-groups describe NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION
必要旗標:
- NODE_GROUP_ID:您可以執行
gcloud dataproc clusters describe CLUSTER_NAME來列出節點群組 ID。 - CLUSTER_NAME:叢集名稱。
- REGION:叢集區域。
REST
使用任何要求資料前,請先更改下列內容:
- PROJECT_ID:必填,Google Cloud 專案 ID。
- REGION:必填,叢集區域。
- CLUSTER_NAME:必填,叢集名稱。
- NODE_GROUP_ID:必填,您可以執行
gcloud dataproc clusters describe CLUSTER_NAME來列出節點群組 ID。
HTTP 方法和網址:
GET https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAMEnodeGroups/Node_GROUP_ID
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
{
"name": "projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/NODE_GROUP_ID",
"roles": [
"DRIVER"
],
"nodeGroupConfig": {
"numInstances": 5,
"imageUri": "https://www.googleapis.com/compute/v1/projects/cloud-dataproc-ci/global/images/dataproc-2-0-deb10-...-rc01",
"machineTypeUri": "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/zones/REGION-a/machineTypes/n1-standard-4",
"diskConfig": {
"bootDiskSizeGb": 1000,
"bootDiskType": "pd-standard"
},
"managedGroupConfig": {
"instanceTemplateName": "dataproc-driver-pool-mcia3j656h2fy",
"instanceGroupManagerName": "dataproc-driver-pool-mcia3j656h2fy"
},
"minCpuPlatform": "AUTOMATIC",
"preemptibility": "NON_PREEMPTIBLE"
}
}
調整驅動程式節點群組的大小
您可以執行 gcloud dataproc node-groups resize 指令或透過 Dataproc API,在叢集驅動程式節點群組新增或移除節點。
gcloud
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=SIZE
必要旗標:
- NODE_GROUP_ID:您可以執行
gcloud dataproc clusters describe CLUSTER_NAME來列出節點群組 ID。 - CLUSTER_NAME:叢集名稱。
- REGION:叢集區域。
- SIZE:為節點群組指定新的驅動程式節點數量。
選用旗標:
--graceful-decommission-timeout=TIMEOUT_DURATION:縮減節點群組時,可以新增這個旗標來指定安全停用的 TIMEOUT_DURATION,以免工作驅動程式立即終止。建議做法:設定逾時的時長時,至少須等於節點群組內執行最久的工作 (系統無法復原失敗的驅動程式)。
範例:gcloud CLI NodeGroup 擴充指令:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=4
範例:gcloud CLI NodeGroup 縮減指令:
gcloud dataproc node-groups resize NODE_GROUP_ID \ --cluster=CLUSTER_NAME \ --region=REGION \ --size=1 \ --graceful-decommission-timeout="100s"
REST
使用任何要求資料前,請先更改下列內容:
- PROJECT_ID:必填,Google Cloud 專案 ID。
- REGION:必填,叢集區域。
- NODE_GROUP_ID:必填,您可以執行
gcloud dataproc clusters describe CLUSTER_NAME來列出節點群組 ID。 - SIZE:必填,節點群組的新節點數量。
- TIMEOUT_DURATION:選填,縮減節點群組時,可以在要求主體新增
gracefulDecommissionTimeout,以免工作驅動程式立即終止。建議做法:設定逾時的時長時,至少須等於節點群組內執行最久的工作 (系統無法復原失敗的驅動程式)。範例:
{ "size": SIZE, "gracefulDecommissionTimeout": "TIMEOUT_DURATION" }
HTTP 方法和網址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/clusters/CLUSTER_NAME/nodeGroups/Node_GROUP_ID:resize
JSON 要求主體:
{
"size": SIZE,
}
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
{
"name": "projects/PROJECT_ID/regions/REGION/operations/OPERATION_ID",
"metadata": {
"@type": "type.googleapis.com/google.cloud.dataproc.v1.NodeGroupOperationMetadata",
"nodeGroupId": "NODE_GROUP_ID",
"clusterUuid": "CLUSTER_UUID",
"status": {
"state": "PENDING",
"innerState": "PENDING",
"stateStartTime": "2022-12-01T23:34:53.064308Z"
},
"operationType": "RESIZE",
"description": "Scale "up or "down" a GCE node pool to SIZE nodes."
}
}
刪除驅動程式節點群組叢集
刪除 Dataproc 叢集時,會一併刪除與該叢集相關聯的節點群組。
提交工作
您可以執行 gcloud dataproc jobs submit 指令或透過 Dataproc API,將工作提交至含有驅動程式節點群組的叢集。
gcloud
gcloud dataproc jobs submit JOB_COMMAND \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=DRIVER_MEMORY \ --driver-required-vcores=DRIVER_VCORES \ DATAPROC_FLAGS \ -- JOB_ARGS
必要旗標:
- JOB_COMMAND:指定工作指令。
- CLUSTER_NAME:叢集名稱。
- DRIVER_MEMORY:執行工作所需的驅動程式記憶體量,以 MB 為單位 (請參閱「YARN 記憶體控制項」)。
- DRIVER_VCORES:執行工作所需的 vCPU 數量。
其他旗標:
- DATAPROC_FLAGS:新增有關工作類型的任何額外 gcloud dataproc jobs submit 旗標。
- JOB_ARGS:在
--後方加上要傳遞至工作的任何引數。
範例:您可以在 Dataproc 驅動程式節點群組叢集中,透過 SSH 終端機工作階段執行下列範例:
估算
pi值的 Spark 工作:gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.SparkPi \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 1000
Spark 字數統計工作:
gcloud dataproc jobs submit spark \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --class=org.apache.spark.examples.JavaWordCount \ --jars=file:///usr/lib/spark/examples/jars/spark-examples.jar \ -- 'gs://apache-beam-samples/shakespeare/macbeth.txt'
估算
pi值的 PySpark 工作:gcloud dataproc jobs submit pyspark \ file:///usr/lib/spark/examples/src/main/python/pi.py \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ -- 1000
Hadoop TeraGen MapReduce 工作:
gcloud dataproc jobs submit hadoop \ --cluster=CLUSTER_NAME \ --region=REGION \ --driver-required-memory-mb=2048 \ --driver-required-vcores=2 \ --jar file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ -- teragen 1000 \ hdfs:///gen1/test
REST
使用任何要求資料前,請先更改下列內容:
- PROJECT_ID:必填,Google Cloud 專案 ID。
- REGION:必填,Dataproc 叢集區域。
- CLUSTER_NAME:必填,叢集名稱,在專案內不得重複。名稱開頭須為小寫英文字母,最多包含 51 個小寫英文字母、數字和連字號,而且結尾不得為連字號。可以重複使用已刪除叢集的名稱。
- DRIVER_MEMORY:必填,執行工作所需的工作驅動程式記憶體量,以 MB 為單位 (請參閱「YARN 記憶體控制項」)。
- DRIVER_VCORES:必填,執行工作所需的 vCPU 數量。
pi 值)。HTTP 方法和網址:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
JSON 要求主體:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME",
},
"driverSchedulingConfig": {
"memoryMb]": DRIVER_MEMORY,
"vcores": DRIVER_VCORES
},
"sparkJob": {
"jarFileUris": "file:///usr/lib/spark/examples/jars/spark-examples.jar",
"args": [
"10000"
],
"mainClass": "org.apache.spark.examples.SparkPi"
}
}
}
請展開以下其中一個選項,以傳送要求:
您應該會收到如下的 JSON 回覆:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "job-id"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "cluster-Uuid"
},
"sparkJob": {
"mainClass": "org.apache.spark.examples.SparkPi",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/spark/examples/jars/spark-examples.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "start-time"
},
"jobUuid": "job-Uuid"
}
Python
- 安裝用戶端程式庫
- 設定應用程式預設憑證
- 執行程式碼
- 估算 pi 值的 Spark 工作:
- 顯示「hello world」的 PySpark 工作:
查看工作記錄檔
如要查看工作狀態及排除相關問題,可以透過 gcloud CLI 或 Google Cloud 控制台查看驅動程式記錄。
gcloud
執行工作時,工作驅動程式記錄會串流至 gcloud CLI 輸出內容或Google Cloud 控制台。記錄會保留於 Cloud Storage 的 Dataproc 叢集暫存 bucket。
執行下列 gcloud CLI 指令,列出 Cloud Storage 中驅動程式記錄的位置:
gcloud dataproc jobs describe JOB_ID \ --region=REGION
驅動程式記錄的 Cloud Storage 位置會以 driverOutputResourceUri 形式列在指令輸出內容中,格式如下:
driverOutputResourceUri: gs://CLUSTER_STAGING_BUCKET/google-cloud-dataproc-metainfo/CLUSTER_UUID/jobs/JOB_ID
控制台
如要查看節點群組叢集記錄,請按照下列步驟操作:
您可以使用下列 Logs Explorer 查詢格式來查找記錄:
resource.type="cloud_dataproc_cluster" resource.labels.project_id="PROJECT_ID" resource.labels.cluster_name="CLUSTER_NAME" log_name="projects/PROJECT_ID/logs/LOG_TYPE>"
- PROJECT_ID: Google Cloud 專案 ID。
- CLUSTER_NAME:叢集名稱。
- LOG_TYPE:
- YARN 使用者記錄:
yarn-userlogs - YARN 資源管理員記錄:
hadoop-yarn-resourcemanager - YARN 節點管理員記錄:
hadoop-yarn-nodemanager
- YARN 使用者記錄:
監控指標
Dataproc 節點群組工作驅動程式會在 dataproc-driverpool 分區內的 dataproc-driverpool-driver-queue 子佇列中執行。
驅動程式節點群組指標
下表列出相關聯的節點群組驅動程式指標 (系統預設會收集這類群組的指標)。
| 驅動程式節點群組指標 | 說明 |
|---|---|
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB |
dataproc-driverpool 分區內,dataproc-driverpool-driver-queue 的可用記憶體量,以 MiB 為單位。 |
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers |
dataproc-driverpool 分區內,dataproc-driverpool-driver-queue 的待處理 (已排入佇列) 容器數量。 |
子佇列指標
下表列出子佇列指標。系統預設會收集驅動程式節點群組的指標,您也可以為任何 Dataproc 叢集啟用指標收集功能。
| 子佇列指標 | 說明 |
|---|---|
yarn:ResourceManager:ChildQueueMetrics:AvailableMB |
預設分區內,這個佇列的可用記憶體量,以 MiB 為單位。 |
yarn:ResourceManager:ChildQueueMetrics:PendingContainers |
預設分區內,這個佇列的待處理 (已排入佇列) 容器數量。 |
yarn:ResourceManager:ChildQueueMetrics:running_0 |
所有分區內,這個佇列中執行時間介於 0 至 60 分鐘的工作數量。 |
yarn:ResourceManager:ChildQueueMetrics:running_60 |
所有分區內,這個佇列中執行時間介於 60 至 300 分鐘的工作數量。 |
yarn:ResourceManager:ChildQueueMetrics:running_300 |
所有分區內,這個佇列中執行時間介於 300 至 1440 分鐘的工作數量。 |
yarn:ResourceManager:ChildQueueMetrics:running_1440 |
所有分區內,這個佇列中執行時間超過 1440 分鐘的工作數量。 |
yarn:ResourceManager:ChildQueueMetrics:AppsSubmitted |
所有分區內,提交至這個佇列的應用程式數量。 |
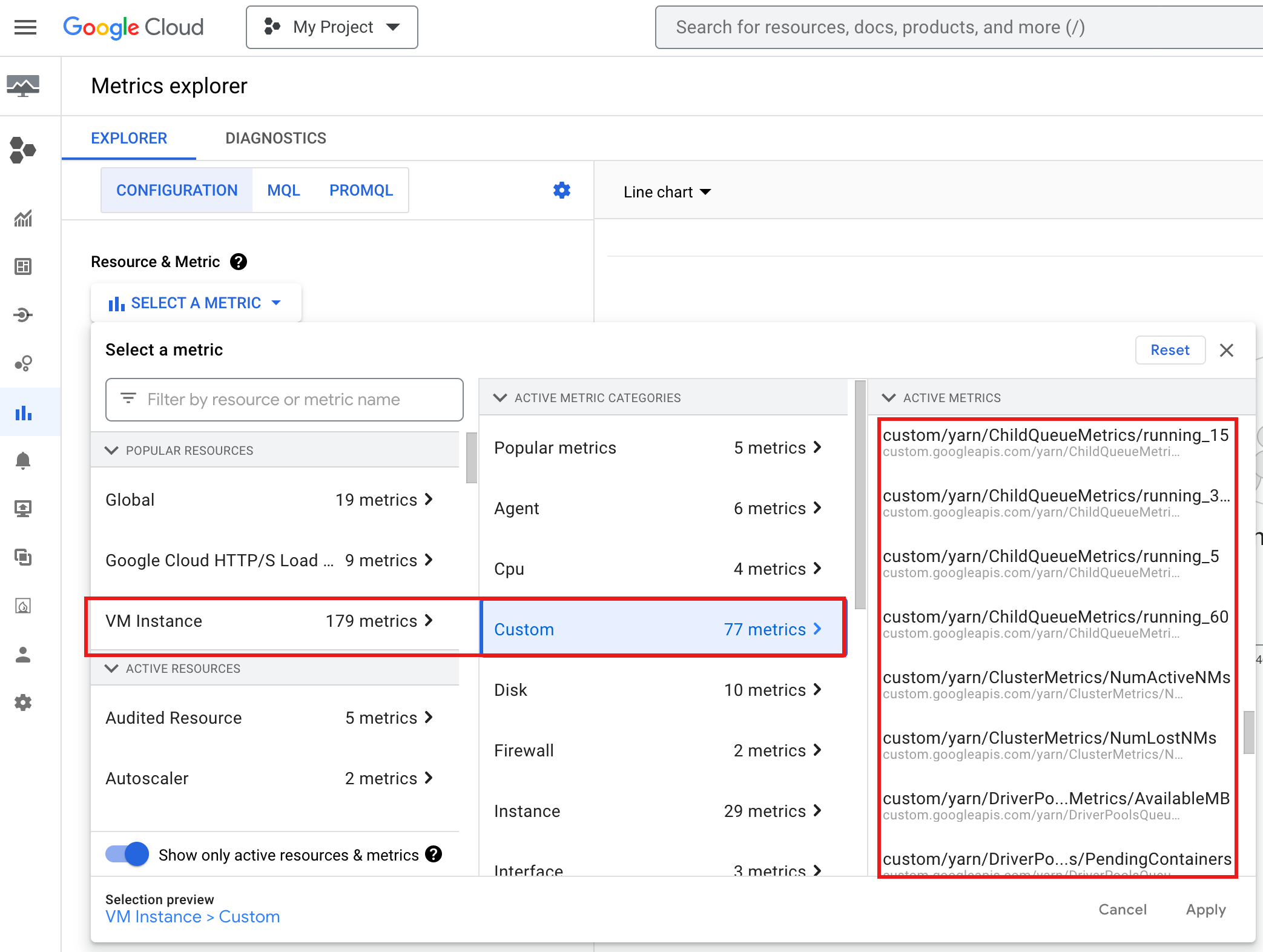
如何在Google Cloud 控制台查看 YARN ChildQueueMetrics 和 DriverPoolsQueueMetrics:
排除節點群組工作驅動程式的錯誤
本節列出驅動程式節點群組的狀態和錯誤,以及相關的建議修正做法。
狀態
狀態:
yarn:ResourceManager:DriverPoolsQueueMetrics:AvailableMB即將達到0,表示叢集驅動程式集區佇列的記憶體即將用盡。建議做法:擴充驅動程式集區大小。
狀態:
yarn:ResourceManager:DriverPoolsQueueMetrics:PendingContainers大於 0,可能表示叢集驅動程式集區佇列的記憶體不足,而 YARN 正在將工作排入佇列。建議做法:擴充驅動程式集區大小。
錯誤
錯誤:
Cluster <var>CLUSTER_NAME</var> requires driver scheduling config to run SPARK job because it contains a node pool with role DRIVER. Positive values are required for all driver scheduling config values.建議做法:將
driver-required-memory-mb和driver-required-vcores設為正數。錯誤:
Container exited with a non-zero exit code 137。建議做法:提升工作記憶體用量的
driver-required-memory-mb。