
Wenn Sie einen Managed Service for Apache Spark-Job senden, erfasst Managed Service for Apache Spark automatisch die Jobausgabe und stellt sie Ihnen zur Verfügung. Sie können die Jobausgabe also schnell überprüfen, ohne eine Verbindung zum Cluster beibehalten zu müssen, wenn Jobs ausgeführt oder komplizierte Log-Dateien analysiert werden.
Spark-Logs
Es gibt zwei Arten von Spark-Logs: Spark-Treiberlogs und Spark-Ausführerlogs.
Spark-Treiberlogs enthalten die Jobausgabe. Spark-Ausführerlogs enthalten die ausführbare Datei oder die Launcher-Ausgabe des Jobs, z. B. die Meldung spark-submit "Submitted application xxx". Sie können hilfreich sein, um Fehler bei Jobs zu beheben.
Der Managed Service for Apache Spark-Jobtreiber, der sich vom Spark-Treiber unterscheidet, ist ein Launcher für viele Jobtypen. Beim Starten von Spark-Jobs wird er als Wrapper für die zugrunde liegende ausführbare Datei spark-submit ausgeführt, die den Spark-Treiber startet. Der Spark-Treiber führt den Job im Spark
client oder cluster Modus im Managed Service for Apache Spark-Cluster aus:
client-Modus: Der Spark-Treiber führt den Job imspark-submit-Prozess aus und Spark-Logs werden an den Managed Service for Apache Spark-Jobtreiber gesendet.cluster-Modus: Der Spark-Treiber führt den Job in einem YARN-Container aus. Spark-Treiberlogs sind für den Managed Service for Apache Spark-Jobtreiber nicht verfügbar.
Übersicht über Managed Service for Apache Spark- und Spark-Jobattribute
| Attribut | Wert | Default | Beschreibung |
|---|---|---|---|
dataproc:dataproc.logging.stackdriver.job.driver.enable |
"true" oder "false" | falsch | Muss beim Erstellen des Clusters festgelegt werden. Wenn true,
befindet sich die Jobtreiberausgabe in Logging,
und ist der Jobressource zugeordnet. Wenn false, befindet sich die Jobtreiber
ausgabe nicht in Logging.Hinweis: Die folgenden Einstellungen für Clusterattribute sind ebenfalls erforderlich, um Jobtreiberlogs in Logging zu aktivieren, und werden beim Erstellen eines Clusters standardmäßig festgelegt: dataproc:dataproc.logging.stackdriver.enable=true und dataproc:jobs.file-backed-output.enable=true
|
dataproc:dataproc.logging.stackdriver.job.yarn.container.enable |
"true" oder "false" | falsch | Muss beim Erstellen des Clusters festgelegt werden.
Wenn true, sind die YARN-Containerlogs des Jobs der Jobressource zugeordnet. Wenn false, sind die YARN-Containerlogs des Jobs der Clusterressource zugeordnet. |
spark:spark.submit.deployMode |
Client oder Cluster | Client | Steuert den client- oder cluster-Modus von Spark. |
Spark-Jobs, die mit der Managed Service for Apache Spark-API jobs gesendet wurden
In den Tabellen in diesem Abschnitt wird die Auswirkung verschiedener Attributseinstellungen auf das
Ziel der Managed Service for Apache Spark-Jobtreiberausgabe aufgeführt, wenn Jobs
über die Managed Service for Apache Spark jobs API gesendet werden. Dazu gehört das Senden von Jobs über die
Google Cloud Console, die gcloud CLI und die Cloud-Clientbibliotheken.
Die aufgeführten Managed Service for Apache Spark- und Spark-Attribute
können beim Erstellen eines Clusters mit dem --properties Flag festgelegt werden und gelten
für alle Spark-Jobs, die im Cluster ausgeführt werden. Spark-Attribute können auch mit dem
--properties Flag (ohne das Präfix „spark:“) festgelegt werden, wenn ein Job an die Managed Service for Apache Spark jobs API gesendet wird. Sie gelten dann nur für den Job.
Managed Service for Apache Spark-Jobtreiberausgabe
In den folgenden Tabellen wird die Auswirkung verschiedener Attributseinstellungen auf das Ziel der Managed Service for Apache Spark-Jobtreiberausgabe aufgeführt.
dataproc: |
Ausgabe |
|---|---|
| falsch (Standardeinstellung) |
|
| wahr |
|
Spark-Treiberlogs
In den folgenden Tabellen wird die Auswirkung verschiedener Attributseinstellungen auf das Ziel von Spark-Treiberlogs aufgeführt.
spark: |
dataproc: |
dataproc: |
Treiberausgabe |
|---|---|---|---|
| Client | falsch (Standardeinstellung) | "true" oder "false" |
|
| Client | wahr | "true" oder "false" |
|
| Cluster | falsch (Standardeinstellung) | falsch |
|
| Cluster | wahr | wahr |
|
Spark-Ausführerlogs
In den folgenden Tabellen wird die Auswirkung verschiedener Attributseinstellungen auf das Ziel von Spark-Ausführerlogs aufgeführt.
dataproc: |
Ausführerlog |
|---|---|
| falsch (Standardeinstellung) | In Logging: yarn-userlogs unter der Clusterressource |
| wahr | In Logging: dataproc.job.yarn.container unter der Jobressource |
Spark-Jobs, die nicht mit der Managed Service for Apache Spark-API jobs gesendet wurden
In diesem Abschnitt wird die Auswirkung verschiedener Attributseinstellungen auf das Ziel von Spark-Joblogs aufgeführt, wenn Jobs nicht mit der Managed Service for Apache Spark-API jobs gesendet werden, z. B. wenn ein Job direkt auf einem Clusterknoten mit spark-submit gesendet wird oder wenn ein Jupyter- oder Zeppelin-Notebook verwendet wird. Diese Jobs haben keine Managed Service for Apache Spark-Job-IDs oder -Treiber.
Spark-Treiberlogs
In den folgenden Tabellen wird die Auswirkung verschiedener Attributseinstellungen auf das Ziel von Spark-Treiberlogs für Jobs aufgeführt, die nicht über die Managed Service for Apache Spark-API jobs gesendet wurden.
spark: |
Treiberausgabe |
|---|---|
| Client |
|
| Cluster |
|
Spark-Ausführerlogs
Wenn Spark-Jobs nicht über die Managed Service for Apache Spark-API jobs gesendet werden, befinden sich die Ausführerlogs in Logging unter yarn-userlogs unter der Clusterressource.
Jobausgabe ansehen
Sie können auf die Managed Service for Apache Spark-Jobausgabe in der Google Cloud Console, der gcloud CLI, Cloud Storage oder Logging zugreifen.
Console
Zum Aufrufen der Jobausgabe rufen Sie den Managed Service for Apache Spark Jobs -Abschnitt für Ihr Projekt auf und klicken auf die Job-ID.
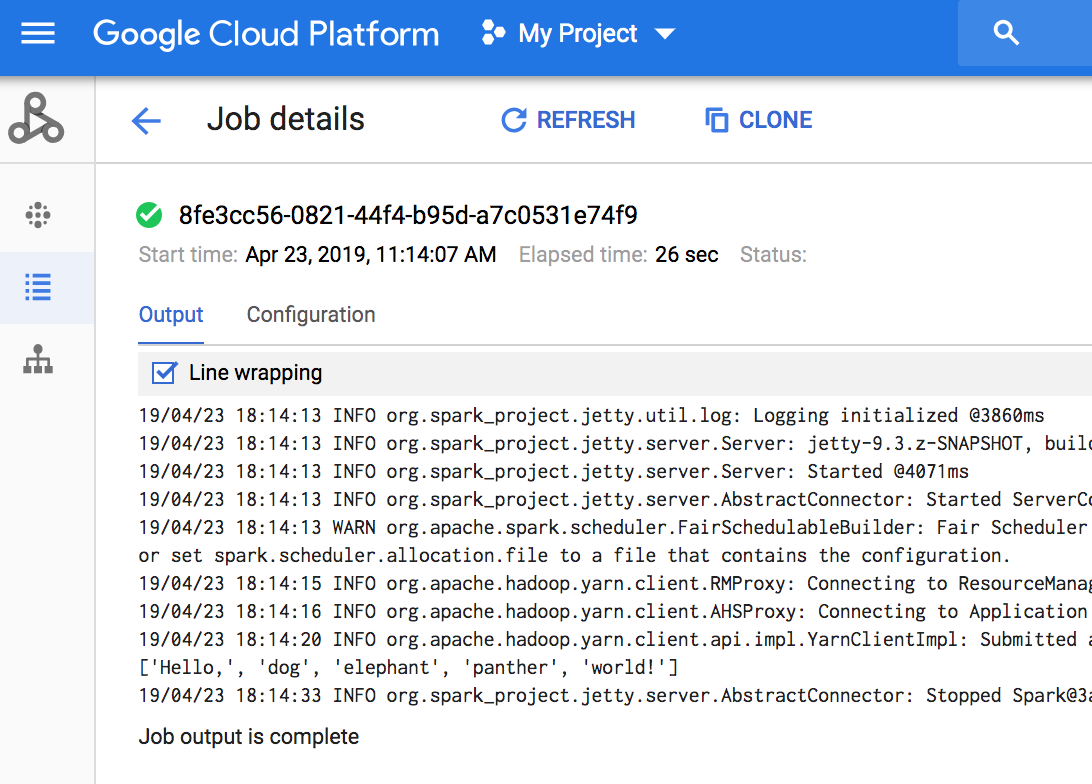
Bei der Ausführung des Jobs wird die Jobausgabe regelmäßig mit neuen Inhalten aktualisiert.
gcloud-Befehl
Wenn Sie einen Job mit dem
gcloud dataproc jobs submit
Befehl senden, wird die Jobausgabe in der Konsole angezeigt. Sie können die Ausgabe später, auf einem anderen Computer oder in einem neuen Fenster wieder aufrufen, indem Sie die ID Ihres Jobs an den gcloud dataproc jobs wait Befehl übergeben. Die Job-ID ist eine
GUID,
wie z. B. 5c1754a5-34f7-4553-b667-8a1199cb9cab. Hier ein Beispiel:
gcloud dataproc jobs wait 5c1754a5-34f7-4553-b667-8a1199cb9cab \ --project my-project-id --region my-cluster-region
Waiting for job output... ... INFO gcs.GoogleHadoopFileSystemBase: GHFS version: 1.4.2-hadoop2 ... 16:47:45 INFO client.RMProxy: Connecting to ResourceManager at my-test-cluster-m/ ...
Cloud Storage
Die Jobausgabe wird in Cloud Storage in entweder im Staging-Bucket oder in dem Bucket gespeichert, den Sie beim Erstellen des Clusters angegeben haben. Ein Link zur Jobausgabe in Cloud Storage wird im Feld Job.driverOutputResourceUri bereitgestellt. Dieses erhalten Sie über:
- Eine jobs.get API-Anfrage.
- Den Befehl gcloud dataproc jobs describe job-id
command.
$ gcloud dataproc jobs describe spark-pi ... driverOutputResourceUri: gs://dataproc-nnn/jobs/spark-pi/driveroutput ...