
É possível aplicar rótulos de usuário aos clusters e jobs do serviço gerenciado para Apache Spark para agrupar esses recursos para filtragem e listagem posteriores. Você associa rótulos aos recursos quando o recurso é criado, na criação do cluster ou no envio do job. Depois que um recurso é associado a um rótulo, ele é propagado para operações realizadas no recurso (criação, atualização, correção ou exclusão de cluster, exclusão, envio, atualização ou cancelamento de job), permitindo filtrar e listar clusters, jobs e operações por rótulo.
Também é possível adicionar rótulos aos recursos do Compute Engine associados aos recursos do cluster, como instâncias de máquina virtual e discos.
O que são rótulos?
Um rótulo é um par de chave-valor que pode ser atribuído a clusters e jobs do serviço gerenciado para Apache Spark. Eles ajudam a organizar esses recursos e gerenciar seus custos em escala, com a granularidade necessária. É possível anexar um rótulo a cada recurso e filtrar os recursos com base nesses rótulos. As informações sobre rótulos são encaminhadas ao sistema de faturamento, que permite detalhar as cobranças faturadas por rótulo. Com os relatórios de faturamento integrados, é possível filtrar e agrupar custos por rótulos de recursos. Também é possível usar rótulos para consultar as exportações de dados de faturamento.
Requisitos para rótulos
Os rótulos aplicados a um recurso precisam atender aos seguintes requisitos:
- Cada cluster ou job pode ter até 32 rótulos.
- Cada rótulo precisa ser um par de chave-valor.
- As chaves têm comprimento mínimo de 1 e máximo de 63 caracteres. Além disso, elas não podem estar vazias. Os valores podem estar vazios e ter um comprimento máximo de 63 caracteres.
- As chaves e os valores contêm apenas letras minúsculas, caracteres numéricos, sublinhados e traços. Todos os caracteres precisam usar a codificação UTF-8, e os caracteres internacionais são permitidos. As chaves precisam começar com uma letra minúscula ou um caractere internacional.
- A parte principal de um rótulo de cluster precisa ser exclusiva em um único recurso. No entanto, é possível usar a mesma chave com vários recursos.
Esses limites se aplicam à chave e ao valor de cada rótulo e ao cluster ou job individual do Managed Service para Apache Spark que tem rótulos. Não há limite para a quantidade de rótulos que podem ser aplicados a todos os recursos em um projeto.
Usos comuns dos rótulos
Veja alguns casos de uso comum para rótulos:
Rótulos de centro de custo ou de equipe: adicione rótulos com base na equipe ou no centro de custo para distinguir clusters e jobs do Managed Service para Apache Spark pertencentes a equipes diferentes (por exemplo,
team:researcheteam:analytics). É possível usar esse tipo de rótulo para contabilidade de custos ou orçamento.Rótulos de componentes: por exemplo,
component:redis,component:frontend,component:ingestecomponent:dashboard.Rótulos de ambientes ou de estágios: por exemplo,
environment:productioneenvironment:test.Rótulos de estado: por exemplo,
state:active,state:readytodeleteestate:archive.Rótulos de propriedade: usados para identificar as equipes responsáveis pelas operações, por exemplo:
team:shopping-cart.
Não recomendamos a criação de um grande número de rótulos exclusivos, como os relacionados a carimbos de data/hora ou valores individuais, para todas as chamadas de API. O problema com essa abordagem é que, quando os valores mudam com frequência ou com chaves que desordenam o catálogo, isso dificulta a filtragem e a geração de relatórios sobre os recursos.
Rótulos e tags
Os rótulos podem ser usados como anotações de consulta para recursos, mas não podem ser usados para definir condições em políticas. Com as tags, é possível permitir ou negar políticas condicionalmente com base em um recurso ter ou não uma tag específica, fornecendo controle refinado sobre as políticas. Para mais informações, consulte a Visão geral das tags.
Criar e usar rótulos do Managed Service for Apache Spark
Comando gcloud
É possível especificar um ou mais rótulos a serem aplicados a um cluster ou job do Managed Service para Apache Spark no momento da criação ou do envio usando a Google Cloud CLI.
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Depois de criar um cluster ou job do Managed Service para Apache Spark, é possível atualizar os rótulos associados a esse recurso usando a Google Cloud CLI.
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
Da mesma forma, é possível usar a Google Cloud CLI para filtrar recursos do Managed Service para Apache Spark por rótulo usando
uma expressão de filtro no seguinte formato: labels.<key=value>.
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
Consulte a documentação da API Dataproc clusters.list e jobs.list para mais informações sobre como gravar uma expressão de filtro.
API REST
Os rótulos podem ser anexados a clusters ou jobs do Managed Service for Apache Spark pela
API REST do Managed Service for Apache Spark. As APIs clusters.create
e jobs.submit
podem ser usadas para anexar rótulos a um cluster ou job no momento da criação ou do envio.
As APIs clusters.patch
e jobs.patch
podem ser usadas para editar rótulos depois da criação de um cluster. Este é o corpo JSON de uma solicitação cluster.create que inclui um
rótulo key1:value ao cluster.
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
As APIs clusters.list e jobs.list
podem ser usadas para listar clusters ou jobs que correspondem a um filtro especificado, usando
o seguinte formato: labels.<key=value>.
Veja um exemplo de solicitação HTTPS GET
clusters.list
da API Dataproc que especifica um filtro de rótulo key=value. O autor da chamada insere
project, region, um filtro label-key e label-value e um api-key.
Essa solicitação de exemplo é dividida em duas linhas para facilitar a leitura.
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
Consulte a documentação da API Dataproc clusters.list e jobs.list para mais informações sobre como gravar uma expressão de filtro.
Console
É possível especificar um conjunto de rótulos para adicionar a um cluster ou job do Managed Service para Apache Spark no momento da criação ou do envio usando o console Google Cloud .
- Adicione rótulos a um cluster na seção "Rótulos" do painel "Personalizar cluster" da página Criar um cluster do serviço gerenciado para Apache Spark.
- Adicione rótulos a um job na página Enviar um job do Managed Service for Apache Spark.
Depois que um cluster ou job do Managed Service for Apache Spark é criado ou enviado,
é possível atualizar os rótulos associados a ele. Para atualizar rótulos,
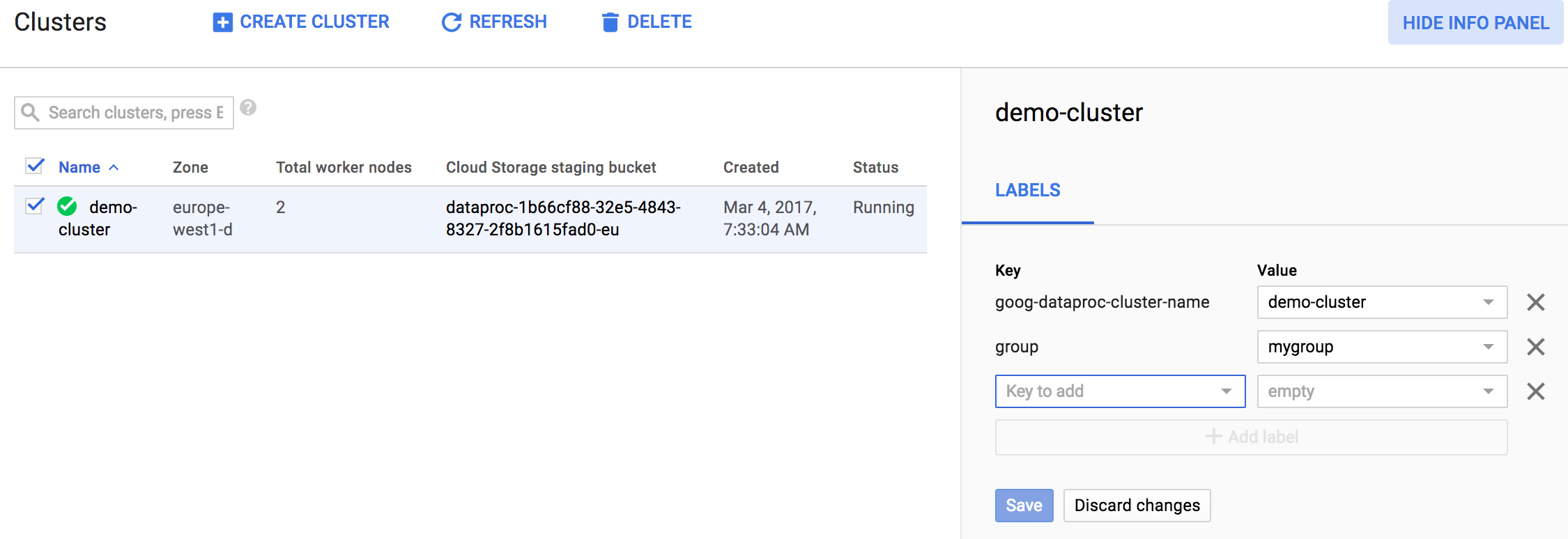
clique na caixa de seleção de um cluster ou job listado e clique em SHOW INFO PANEL. Este é um exemplo da página Managed Service for Apache Spark→Listar clusters.

Depois que o painel de informações for exibido, você poderá atualizar os rótulos do cluster ou job do Managed Service para Apache Spark. Confira abaixo um exemplo de como atualizar rótulos de um cluster do Managed Service for Apache Spark.
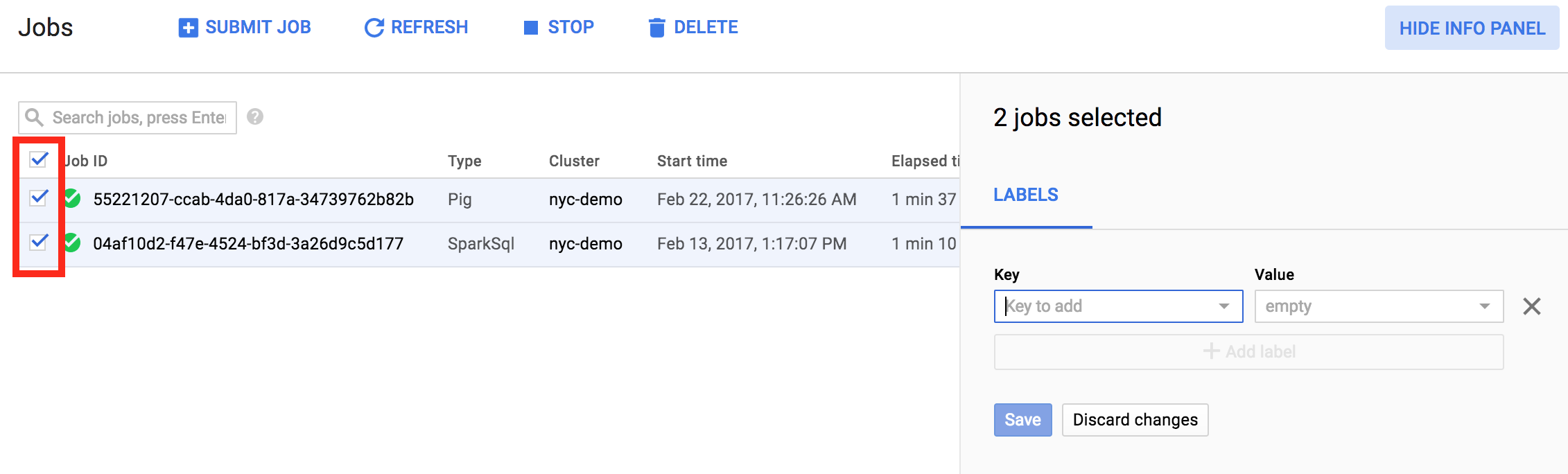
Também é possível atualizar os rótulos de vários itens em uma única operação. Neste exemplo, os rótulos de vários jobs do Managed Service for Apache Spark estão sendo atualizados ao mesmo tempo.
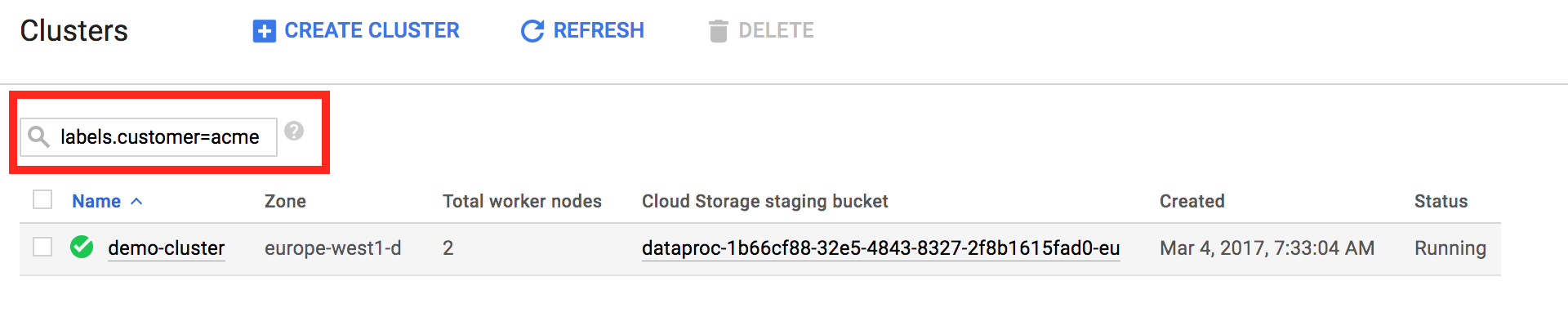
Os rótulos permitem filtrar os recursos do serviço gerenciado para Apache Spark mostrados nas páginas [Serviço gerenciado para Apache Spark → Listar clusters](https://console.cloud.google.com/dataproc/clusters) e [Serviço gerenciado para Apache Spark → Listar jobs](https://console.cloud.google.com/dataproc/jobs). Na parte de cima da página, use o padrão das pesquisas `labels.
Rótulos aplicados automaticamente
Ao criar ou atualizar um cluster, o serviço gerenciado para Apache Spark aplica automaticamente
vários rótulos ao cluster e aos recursos do cluster. Por exemplo,
o serviço gerenciado para Apache Spark aplica rótulos a máquinas virtuais, discos permanentes
e aceleradores quando um cluster é criado. Os rótulos aplicados automaticamente têm um
prefixo goog-dataproc especial.
Os rótulos goog-dataproc a seguir são aplicados automaticamente aos
recursos do Managed Service for Apache Spark. Todos os valores fornecidos para os rótulos
goog-dataproc reservados na criação do cluster modificarão
os valores fornecidos automaticamente. Por esse motivo, não é recomendável fornecer os próprios valores para esses rótulos.
| Rótulo | Descrição |
|---|---|
goog-dataproc-cluster-name |
Nome do cluster especificado pelo usuário. |
goog-dataproc-cluster-uuid |
ID do cluster exclusivo. |
goog-dataproc-location |
Endpoint regional do cluster do Managed Service for Apache Spark |
Você pode usar esses rótulos aplicados automaticamente de várias maneiras, incluindo:
- Como pesquisar e filtrar recursos do Managed Service for Apache Spark
- Como filtrar dados de faturamento para calcular os custos do Managed Service for Apache Spark
A seguir
Saiba como criar e atualizar rótulos para projetos usando o Resource Manager.
Saiba como organizar recursos usando rótulos.