
Vous pouvez appliquer des libellés utilisateur aux clusters et aux jobs Managed Service pour Apache Spark afin de regrouper ces ressources en vue de les filtrer et de les répertorier ultérieurement. Vous associez des libellés aux ressources lors de la création de la ressource, lorsque vous créez un cluster ou envoyez une tâche. Une fois qu'une ressource est associée à un libellé, celui-ci est propagé aux opérations effectuées sur la ressource (création, mise à jour, correction ou suppression de cluster ; envoi, mise à jour, annulation ou suppression de tâches), ce qui vous permet de filtrer et de répertorier les clusters, les tâches et les opérations par libellé.
Vous pouvez également ajouter des libellés aux ressources Compute Engine associées aux ressources de cluster, telles que les instances de machines virtuelles et les disques.
Qu'est-ce qu'un libellé ?
Un libellé est une paire clé-valeur que vous pouvez attribuer aux clusters et aux jobs Managed Service pour Apache Spark. Elle vous aide à organiser ces ressources et à gérer vos coûts à grande échelle avec la précision dont vous avez besoin. Vous pouvez associer une étiquette à chaque ressource, puis filtrer les ressources par étiquette. Les informations sur les étiquettes sont transmises au système de facturation. Ainsi, vous pouvez trier vos frais facturés par étiquette. Grâce aux rapports de facturation intégrés, vous pouvez filtrer et regrouper les coûts par étiquette de ressource. Vous pouvez également utiliser des étiquettes pour interroger les exportations de données de facturation.
Exigences relatives aux libellés
Les libellés appliqués à une ressource doivent répondre aux exigences suivantes :
- Chaque cluster ou job peut comporter jusqu'à 32 libellés.
- Chaque étiquette doit correspondre à une paire clé/valeur.
- Les clés doivent comporter un (1) caractère au minimum et 63 au maximum, et ne peuvent pas être vides. Les valeurs peuvent être vides et comporter 63 caractères au maximum.
- Les clés et les valeurs ne peuvent contenir que des lettres minuscules, des chiffres, des traits de soulignement et des tirets. Tous les caractères doivent être au format d'encodage UTF-8. Les caractères internationaux sont autorisés. Les clés doivent commencer par une lettre minuscule ou un caractère international.
- La partie clé d'un libellé doit être unique au sein d'une ressource spécifique. Cependant, vous pouvez utiliser la même clé avec plusieurs ressources.
Ces limites s'appliquent à la clé et à la valeur de chaque libellé, ainsi qu'au cluster ou au job Managed Service pour Apache Spark individuel associé à des libellés. Vous pouvez appliquer autant de libellés que vous le souhaitez à toutes les ressources d'un projet.
Cas d'utilisation courants des libellés
Voici quelques cas d'utilisation courants des étiquettes :
Libellés d'équipe ou de centre de coût : ajoutez des libellés en fonction de l'équipe ou du centre de coûts pour distinguer les clusters et les jobs Managed Service pour Apache Spark appartenant à différentes équipes (par exemple,
team:researchetteam:analytics). Vous pouvez utiliser ce type de libellé pour la comptabilité analytique ou la budgétisation.Étiquettes de composant : par exemple,
component:redis,component:frontend,component:ingestetcomponent:dashboard.Libellés d'environnement ou d'étape : par exemple,
environment:productionetenvironment:test.Libellés d'état : par exemple,
state:active,state:readytodeleteetstate:archive.Étiquettes de propriété : permettent d'identifier les équipes responsables des opérations (par exemple,
team:shopping-cart).
Nous vous déconseillons de créer de grands nombres d'étiquettes uniques (par exemple, pour les horodatages ou les valeurs individuelles pour chaque appel d'API). Le problème avec cette approche est que lorsque les valeurs changent fréquemment ou que des clés encombrent le catalogue, il est difficile de filtrer efficacement les ressources et de créer des rapports associés.
Libellés et tags
Pour les ressources, les libellés peuvent être utilisés comme des annotations qu'il est possible d'interroger. Cependant, ils ne peuvent pas être utilisés pour définir des conditions dans le cadre de vos stratégies. Les tags permettent d'autoriser ou de refuser des règles de manière conditionnelle selon qu'une ressource possède un tag spécifique ou non, grâce à un contrôle ultraprécis sur les règles. Pour en savoir plus, consultez la présentation des tags.
Créer et utiliser des libellés Managed Service pour Apache Spark
Commande gcloud
À l'aide de Google Cloud CLI, lorsque vous créez un cluster ou envoyez une tâche Managed Service for Apache Spark, vous pouvez spécifier un ou plusieurs libellés à leur appliquer.
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Une fois le cluster ou le job Managed Service pour Apache Spark créés, vous pouvez mettre à jour les libellés associés à cette ressource à l'aide de Google Cloud CLI.
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
De même, vous pouvez utiliser la Google Cloud CLI pour filtrer les ressources Managed Service pour Apache Spark par libellé à l'aide d'une expression de filtre au format suivant : labels.<key=value>.
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
Pour plus d'informations sur l'écriture d'expressions de filtre, consultez les sections clusters.list et jobs.list dans la documentation de l'API Dataproc.
API REST
Les libellés peuvent être associés aux clusters ou aux jobs Managed Service pour Apache Spark via l'API REST Managed Service pour Apache Spark. Les API clusters.create et jobs.submit peuvent être utilisées pour associer des libellés à un cluster ou à une tâche lors de la création ou de l'envoi.
Les API clusters.patch et jobs.patch peuvent être utilisées pour modifier les libellés après la création d'un cluster. Voici un exemple de corps JSON de requête "cluster.create" qui inclut le libellé key1:value associé au cluster.
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
Les API clusters.list et jobs.list peuvent être utilisées pour répertorier les clusters ou les jobs correspondant à un filtre spécifié, au format suivant : labels.<key=value>.
Voici un exemple de requête HTTPS GET clusters.list à l'API Dataproc qui spécifie un filtre de libellé key=value. L'appelant insère project, region, un filtre label-key et label-value, et un élément api-key.
Notez que cet exemple de demande est divisé en deux lignes pour faciliter la lecture.
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
Pour plus d'informations sur l'écriture d'expressions de filtre, consultez les sections clusters.list et jobs.list dans la documentation de l'API Dataproc.
Console
Vous pouvez spécifier un ensemble de libellés à ajouter à un cluster ou à un job Managed Service pour Apache Spark au moment de sa création ou de son envoi à l'aide de la console Google Cloud .
- Ajoutez des libellés à un cluster à partir de la section "Libellés" du panneau "Personnaliser le cluster" de la page Managed Service pour Apache Spark Créer un cluster.
- Ajoutez des libellés à un job à partir de la page Managed Service pour Apache Spark Envoyer un job.
Une fois un cluster ou un job Managed Service pour Apache Spark créé ou envoyé, vous pouvez mettre à jour les libellés associés au cluster ou au job. Pour mettre à jour les libellés, cliquez sur la zone de sélection d'un cluster ou d'un job listé, puis sur SHOW INFO PANEL. Voici un exemple tiré de la page Managed Service pour Apache Spark→Répertorier les clusters.

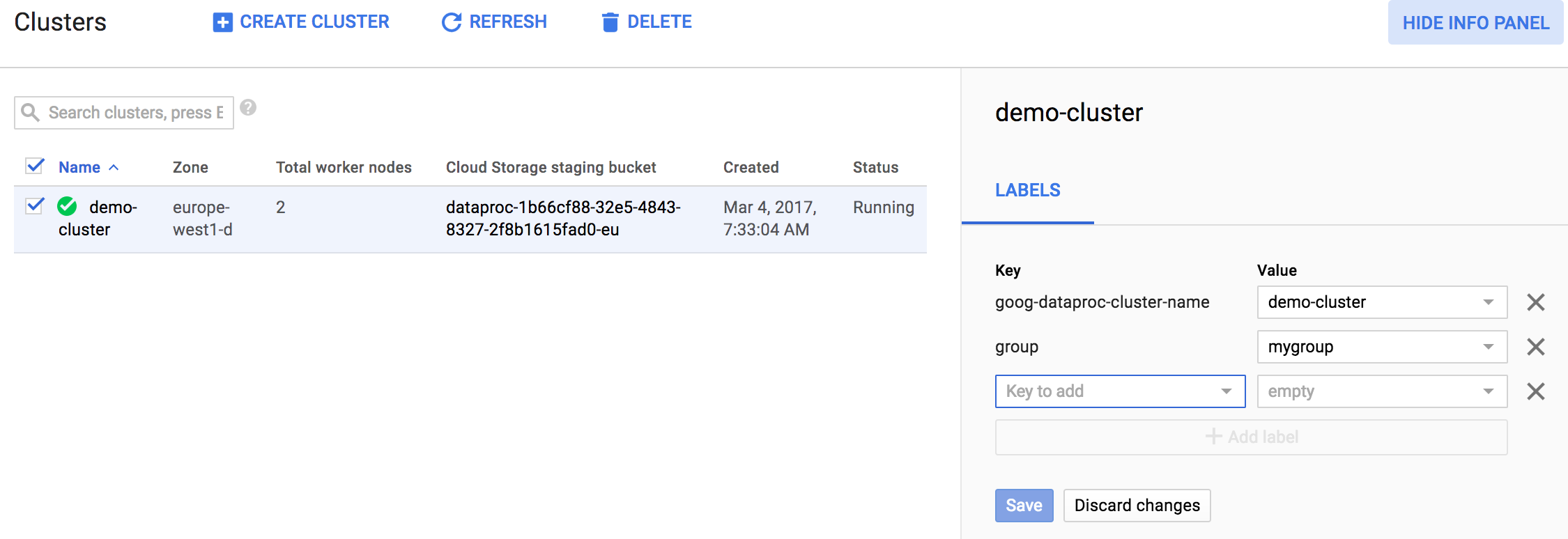
Une fois le panneau d'informations affiché, vous pouvez mettre à jour les libellés de votre cluster ou job Managed Service pour Apache Spark. Vous trouverez ci-dessous un exemple de mise à jour des libellés d'un cluster Managed Service pour Apache Spark.
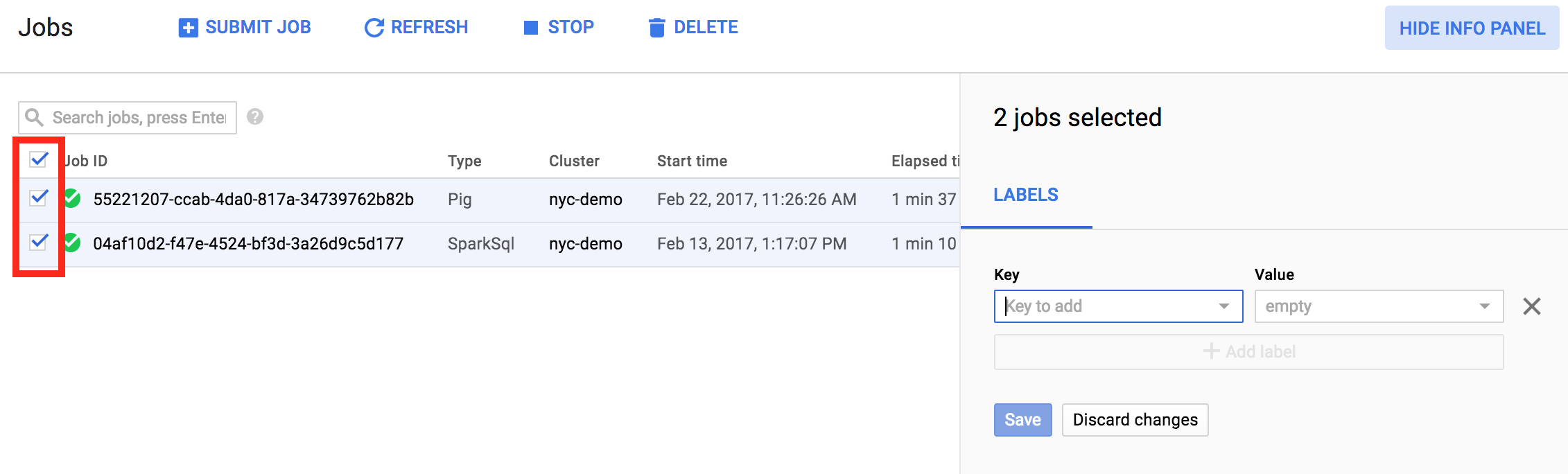
Il est également possible de mettre à jour des libellés pour plusieurs éléments au cours d'une seule et même opération. Dans l'exemple ci-dessous, les étiquettes de plusieurs tâches Managed Service pour Apache Spark sont mises à jour en même temps.
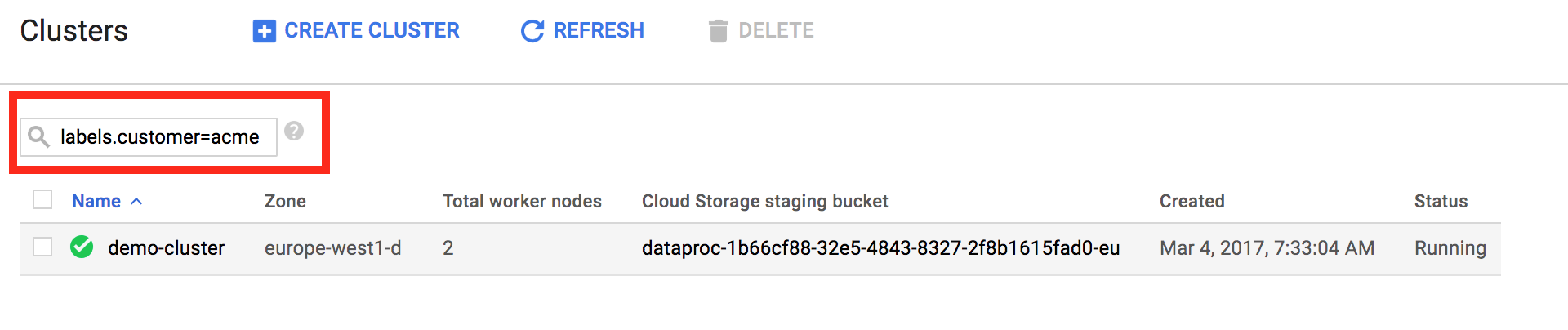
Les libellés vous permettent de filtrer les ressources Managed Service pour Apache Spark affichées sur les pages [Managed Service pour Apache Spark → Répertorier les clusters](https://console.cloud.google.com/dataproc/clusters) et [Managed Service pour Apache Spark → Répertorier les jobs](https://console.cloud.google.com/dataproc/jobs). En haut de la page, vous pouvez utiliser le modèle de recherche `labels.
Étiquettes appliquées automatiquement
Lors de la création ou de la mise à jour d'un cluster, Managed Service pour Apache Spark applique automatiquement plusieurs libellés au cluster et à ses ressources. Par exemple, Managed Service pour Apache Spark applique des libellés aux machines virtuelles, aux disques persistants et aux accélérateurs lors de la création d'un cluster. Les libellés appliqués automatiquement comportent un préfixe goog-dataproc spécial.
Les libellés goog-dataproc suivants sont automatiquement appliqués aux ressources Managed Service pour Apache Spark. Toutes les valeurs que vous fournissez pour les libellés goog-dataproc réservés lors de la création du cluster remplacent les valeurs fournies automatiquement. Pour cette raison, il n'est pas recommandé de fournir vos propres valeurs pour ces libellés.
| Libellé | Description |
|---|---|
goog-dataproc-cluster-name |
Nom du cluster spécifié par l'utilisateur |
goog-dataproc-cluster-uuid |
ID de cluster unique |
goog-dataproc-location |
Point de terminaison régional Managed Service pour Apache Spark |
Vous pouvez utiliser ces libellés appliqués automatiquement de différentes manières, par exemple :
- Rechercher et filtrer des ressources Managed Service pour Apache Spark
- Filtrer les données de facturation pour calculer les coûts Managed Service pour Apache Spark
Étapes suivantes
Découvrez comment créer et mettre à jour des libellés pour les projets à l'aide de Resource Manager.
Découvrez comment organiser des ressources à l'aide d'étiquettes.