
Puedes aplicar etiquetas de usuario a los clústeres y trabajos de Managed Service para Apache Spark para agrupar estos recursos y filtrarlos y enumerarlos más adelante. Debes asociar las etiquetas con los recursos cuando se crea el recurso, o el clúster o en cuando se envían los trabajos. Una vez que un recurso se asocia con una etiqueta, la etiqueta se propaga a las operaciones realizadas en el recurso (creación, actualización, actualización para parches o eliminación de clústeres; envío, actualización, cancelación o eliminación de trabajos), lo que te permite filtrar y crear listas de clústeres, trabajos y operaciones por etiqueta.
También puedes agregar etiquetas a los recursos de Compute Engine asociados con los recursos del clúster, como los discos y las instancias de máquina virtual.
¿Qué son las etiquetas de recurso?
Una etiqueta es un par clave-valor que puedes asignar a los clústeres y trabajos de Managed Service para Apache Spark. Te ayudan a organizar estos recursos y administrar los costos a gran escala, con el nivel de detalle que necesitas. Puedes adjuntar una etiqueta a cada recurso y, luego, usarlas para filtrarlos. La información sobre las etiquetas se envía al sistema de facturación que te permite desglosar los cargos facturados por etiqueta. Con los informes de facturación integrados, puedes filtrar y agrupar costos por etiquetas de recurso. También puedes usar etiquetas para consultar las exportaciones de datos de facturación.
Requisitos para las etiquetas
Las etiquetas que se aplican a un recurso deben cumplir los siguientes requisitos:
- Cada clúster o trabajo puede tener hasta 32 etiquetas.
- Cada etiqueta debe ser un par clave-valor.
- La longitud de las claves debe ser de entre 1 y 63 caracteres, y no pueden estar vacías. Los valores pueden estar vacíos y su longitud máxima es de 63 caracteres.
- Las claves y los valores pueden contener solo letras en minúscula, caracteres numéricos, guiones bajos y guiones. Todos los caracteres deben usar la codificación UTF-8, además, se permiten los caracteres internacionales. Las claves deben comenzar con una letra en minúscula o un carácter internacional.
- La porción de clave de una etiqueta debe ser única para un solo recurso. Sin embargo, puedes usar la misma clave en varios recursos.
Estos límites se aplican a la clave y al valor de cada etiqueta, y a los clústeres o trabajos individuales de Managed Service para Apache Spark que tienen etiquetas. No hay límite para la cantidad de etiquetas de clúster que puedes aplicar en todos los recursos de un proyecto.
Usos comunes de las etiquetas
Estos son algunos casos prácticos comunes de las etiquetas:
Etiquetas del equipo o del centro de costos: Agrega etiquetas según el equipo o centro de costos para distinguir los clústeres y los trabajos de Managed Service para Apache Spark que pertenecen a distintos equipos (por ejemplo,
team:researchyteam:analytics). Puedes usar este tipo de etiqueta para la contabilidad de costos o la creación del presupuesto.Etiquetas de componentes: por ejemplo,
component:redis,component:frontend,component:ingestycomponent:dashboard.Etiquetas de entorno o etapa: por ejemplo,
environment:productionyenvironment:test.Etiquetas de estado: por ejemplo,
state:active,state:readytodeleteystate:archive.Etiquetas de propiedad: Se usan para identificar a los equipos responsables de las operaciones, por ejemplo:
team:shopping-cart.
No recomendamos crear grandes cantidades de etiquetas únicas, como marcas de tiempo o valores individuales para cada llamada a la API. El problema con este enfoque es que, cuando los valores cambian con frecuencia o con claves que sobrecargan el catálogo, esto dificulta el filtrado y la generación de informes eficaces para los recursos.
Etiquetas
Las etiquetas se pueden usar como anotaciones que se pueden consultar en los recursos, pero no se pueden usar para establecer condiciones en las políticas. Las etiquetas proporcionan una forma de permitir o rechazar políticas de manera condicional en función de si un recurso tiene una etiqueta específica, ya que proporciona un control detallado sobre las políticas. Para obtener más información, consulta la Descripción general de etiquetas.
Crea y usa etiquetas de Managed Service para Apache Spark
Comando de gcloud
Puedes especificar una o más etiquetas para que se apliquen a un clúster o trabajo de Managed Service for Apache Spark al momento de su creación o envío con Google Cloud CLI.
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Una vez que se crea un trabajo o un clúster de Managed Service para Apache Spark, puedes actualizar las etiquetas asociadas con ese recurso mediante Google Cloud CLI.
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
De manera similar, puedes usar Google Cloud CLI para filtrar los recursos de Managed Service para Apache Spark por etiqueta con una expresión de filtro con el siguiente formato: labels.<key=value>.
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
Consulta la documentación de las API de clusters.list y jobs.list de Dataproc para obtener más información sobre cómo escribir una expresión de filtro.
API de REST
Las etiquetas se pueden adjuntar a los clústeres o trabajos de Managed Service para Apache Spark a través de la API de REST de Managed Service para Apache Spark. Las API de clusters.create y jobs.submit pueden usarse para adjuntar etiquetas a un clúster o trabajo en el momento de la creación o el envío.
Las APIs de clusters.patch y jobs.patch pueden usarse para editar etiquetas después de que se creó un clúster. A continuación, se muestra el cuerpo JSON de una solicitud cluster.create que adjunta la etiqueta key1:value al clúster.
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
Las APIs de clusters.list y jobs.list pueden usarse para crear listas de clústeres o trabajos que coinciden con un filtro especificado, con el siguiente formato: labels.<key=value>.
A continuación, se muestra un ejemplo de una solicitud HTTPS GET a la API de clusters.list de Dataproc que especifica un filtro de etiqueta key=value. El emisor inserta project, region, un filtro label-key y label-value, y api-key.
Ten en cuenta que esta solicitud de ejemplo está dividida en dos líneas para que se pueda leer con mayor facilidad.
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
Consulta la documentación de las API de clusters.list y jobs.list de Dataproc para obtener más información sobre cómo escribir una expresión de filtro.
Console
Puedes especificar un conjunto de etiquetas para agregar a un clúster o trabajo de Managed Service para Apache Spark en el momento de su creación o envío con la consola de Google Cloud .
- Agrega etiquetas a un clúster desde la sección Etiquetas del panel Personalizar clúster de la página Crear un clúster de Managed Service para Apache Spark.
- Agrega etiquetas a un trabajo desde la página Enviar un trabajo de Managed Service para Apache Spark.
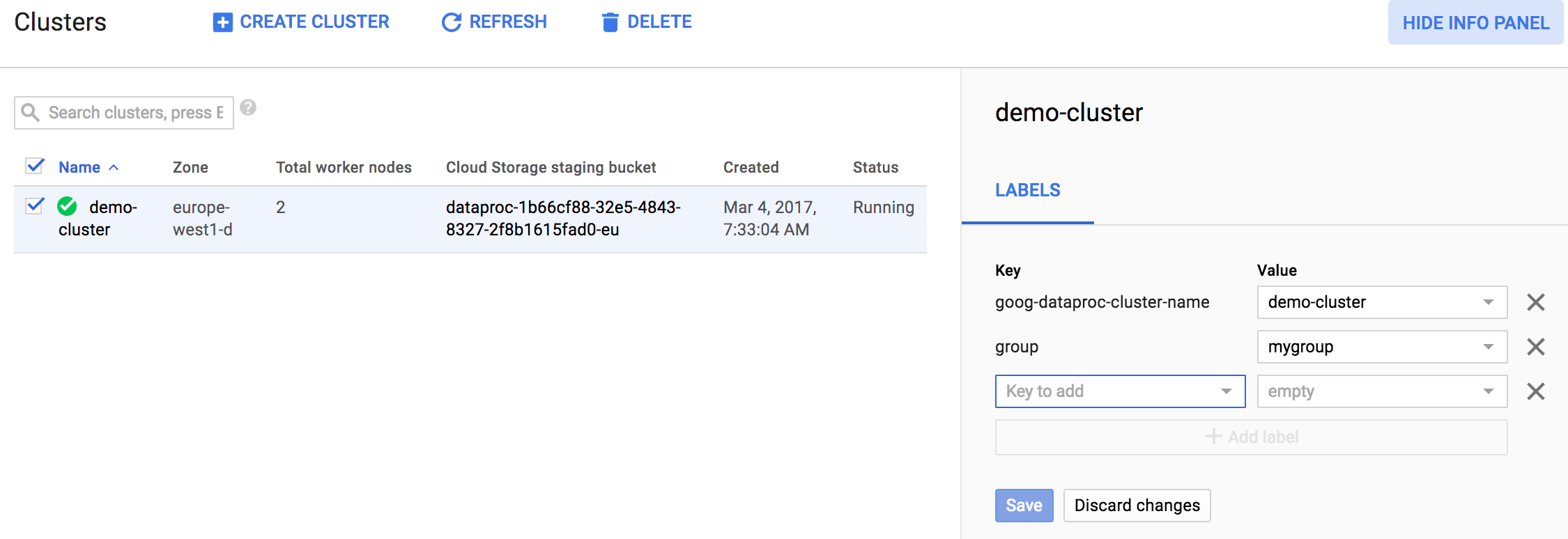
Una vez que se crea o envía un clúster o trabajo de Managed Service para Apache Spark, puedes actualizar las etiquetas asociadas con el clúster o el trabajo. Para actualizar las etiquetas, haz clic en el cuadro de selección de un clúster o trabajo de la lista y, luego, en SHOW INFO PANEL. Este es un ejemplo de la página Managed Service para Apache Spark→List clusters.

Una vez que se muestra el panel de información, puedes actualizar las etiquetas de tu clúster o trabajo de Managed Service para Apache Spark. A continuación, se muestra un ejemplo de la actualización de etiquetas para un clúster de Managed Service para Apache Spark.
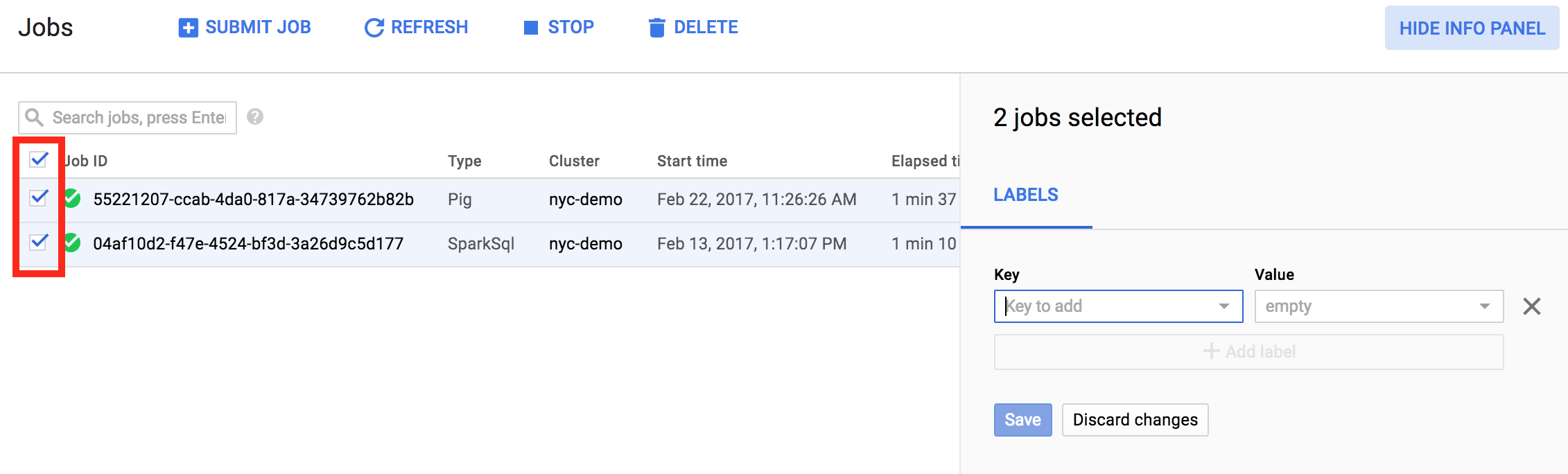
También es posible actualizar etiquetas para múltiples elementos en una operación. En este ejemplo, las etiquetas se actualizan para múltiples trabajos de Managed Service para Apache Spark al mismo tiempo.
Las etiquetas te permiten filtrar los recursos de Managed Service para Apache Spark que se muestran en las páginas [Managed Service para Apache Spark→Lista de clústeres](https://console.cloud.google.com/dataproc/clusters) y [Managed Service para Apache Spark→Lista de trabajos](https://console.cloud.google.com/dataproc/jobs). En la parte superior de la página, puedes usar el patrón de búsqueda `labels.

Etiquetas aplicadas de manera automática
Cuando creas o actualizas un clúster, Managed Service para Apache Spark aplica de forma automática múltiples etiquetas al clúster y a sus recursos. Por ejemplo, Managed Service para Apache Spark aplica etiquetas a las máquinas virtuales, los discos persistentes y los aceleradores cuando se crea un clúster. Las etiquetas aplicadas de forma automática tienen un prefijo goog-dataproc especial.
Las siguientes etiquetas goog-dataproc se aplican automáticamente a los recursos de Managed Service para Apache Spark. Cualquier valor que proporciones para las etiquetas goog-dataproc reservadas durante la creación del clúster anulará los valores proporcionados de forma automática. Por esta razón, no se recomienda que proporciones tus propios valores para estas etiquetas.
| Etiqueta | Descripción |
|---|---|
goog-dataproc-cluster-name |
Nombre del clúster especificado por el usuario. |
goog-dataproc-cluster-uuid |
ID de clúster único. |
goog-dataproc-location |
Extremo regional del clúster de Managed Service para Apache Spark |
Puedes usar estas etiquetas aplicadas de forma automática de las siguientes maneras:
- Busca y filtra recursos de Managed Service para Apache Spark
- Filtrado de datos de facturación para calcular costos de Managed Service para Apache Spark
¿Qué sigue?
Obtén información para crear y actualizar etiquetas para proyectos con Resource Manager.
Obtén más información para organizar los recursos con etiquetas.