
나중에 필터링 및 나열할 리소스를 그룹화하기 위해 Managed Service for Apache Spark 클러스터 및 작업에 사용자 라벨을 적용할 수 있습니다. 리소스를 만들 때, 클러스터 생성 또는 작업 제출 시 라벨을 리소스와 연결합니다. 리소스가 라벨과 연결되면 리소스에서 수행되는 작업(클러스터 만들기/업데이트/패치 적용/삭제, 작업 제출/업데이트/취소/삭제)에 라벨이 전파되어 클러스터, 작업, 운영을 라벨별로 필터링하고 나열할 수 있습니다.
가상 머신 인스턴스 및 디스크와 같은 클러스터 리소스와 연결된 Compute Engine 리소스에 라벨을 추가할 수도 있습니다.
라벨이란 무엇인가요?
라벨은 Managed Service for Apache Spark 클러스터 및 작업에 할당할 수 있는 키-값 쌍입니다. 이러한 리소스를 구성하고 필요한 세부사항으로 규모에 맞게 비용을 관리하는 데 도움이 됩니다. 각 리소스에 라벨을 연결한 후 이 라벨을 기준으로 리소스를 필터링할 수 있습니다. 라벨에 대한 정보는 청구 요금을 라벨별로 분류할 수 있는 결제 시스템으로 전달됩니다. 기본 제공되는 결제 보고서를 통해 리소스 라벨별로 비용을 필터링하고 그룹화할 수 있습니다. 라벨을 사용하여 결제 데이터 내보내기를 쿼리할 수도 있습니다.
라벨 요구사항
리소스에 적용된 라벨은 다음 요구사항을 충족해야 합니다.
- 각 클러스터 또는 작업에는 최대 32개의 라벨이 있을 수 있습니다.
- 각 라벨은 키-값 쌍이어야 합니다.
- 키는 비워 둘 수 없으며 최소 길이는 1자(영문 기준)이고 최대 길이는 63자(영문 기준)입니다. 값은 비워 둘 수 있으며 최대 길이는 63자(영문 기준)입니다.
- 키와 값에는 소문자, 숫자, 밑줄, 대시만 사용할 수 있습니다. 모든 문자는 UTF-8 인코딩을 사용해야 하며 국제 문자가 허용됩니다. 키는 소문자나 국제 문자로 시작해야 합니다.
- 라벨의 키 부분은 단일 리소스에서 고유해야 합니다. 그러나 여러 리소스에 같은 키를 사용할 수 있습니다.
이러한 한도는 각 라벨의 키와 값 및 라벨이 있는 개별 Managed Service for Apache Spark 클러스터 또는 작업에 적용됩니다. 한 프로젝트의 모든 리소스에 적용할 수 있는 라벨 수에는 제한이 없습니다.
라벨의 일반적인 사용 사례
다음은 라벨의 몇 가지 일반적인 사용 사례입니다.
팀 또는 비용 센터 라벨: 팀 또는 비용 센터를 기준으로 라벨을 추가하여 서로 다른 팀 (예:
team:research및team:analytics)에서 소유하는 Managed Service for Apache Spark 클러스터와 작업을 구분할 수 있습니다. 비용 계산이나 예산 책정에 이 유형의 라벨을 사용할 수 있습니다.구성요소 라벨:
component:redis,component:frontend,component:ingest,component:dashboard를 예로 들 수 있습니다.환경 또는 단계 라벨:
environment:production과environment:test를 예로 들 수 있습니다.상태 라벨:
state:active,state:readytodelete,state:archive를 예시로 들 수 있습니다.소유권 라벨: 작업을 담당하는 팀을 식별하는 데 사용됩니다(예:
team:shopping-cart).
모든 API 호출의 타임스탬프 또는 개별 값과 같은 다수의 고유 라벨을 만들지 않는 것이 좋습니다. 이 접근 방식의 문제는 값이 자주 변경되거나 카탈로그를 복잡하게 하는 키로 인해 리소스를 효과적으로 필터링하고 보고하기 어렵다는 것입니다.
라벨 및 태그
라벨은 리소스에 대해 쿼리 가능한 주석으로 사용될 수 있지만 정책에 조건을 설정하는 데는 사용할 수 없습니다. 태그를 사용하면 정책을 세밀하게 제어하여 리소스에 특정 태그가 있는지 여부에 따라 정책을 조건부로 허용하거나 거부할 수 있습니다. 자세한 내용은 태그 개요를 참조하세요.
Managed Service for Apache Spark 라벨 만들기 및 사용
gcloud 명령어
Google Cloud CLI를 사용하여 만들거나 제출할 때 Managed Service for Apache Spark 클러스터나 작업에 적용할 라벨을 한 개 이상 지정할 수 있습니다.
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Managed Service for Apache Spark 클러스터 또는 작업이 생성되면 Google Cloud CLI를 사용하여 리소스와 연결된 라벨을 업데이트할 수 있습니다.
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
마찬가지로 Google Cloud CLI를 사용하여 labels.<key=value> 형식의 필터 표현식을 사용하여 라벨을 기준으로 Managed Service for Apache Spark 리소스를 필터링할 수 있습니다.
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
필터 표현식 작성에 대한 자세한 내용은 clusters.list 및 jobs.list Dataproc API 참고 리소스를 참조하세요.
REST API
라벨은 Managed Service for Apache Spark REST API를 통해 Managed Service for Apache Spark 클러스터 또는 작업에 연결할 수 있습니다. clusters.create, jobs.submit API를 사용하여 만들거나 제출할 때 클러스터나 작업에 라벨을 연결할 수 있습니다.
clusters.patch, jobs.patch API를 사용하면 클러스터를 만든 후에 라벨을 수정할 수 있습니다. 다음은 key1:value 라벨을 클러스터에 연결하는 것을 포함한 cluster.create 요청의 JSON 본문입니다.
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
clusters.list 및 jobs.list API를 사용하면 labels.<key=value> 형식을 사용하는 지정된 필터와 일치하는 클러스터 또는 작업을 나열할 수 있습니다.
다음은 key=value 라벨 필터를 지정하는 Dataproc API clusters.list HTTPS GET 요청의 샘플입니다. 호출자는 project, region, 필터 label-key 및 label-value, api-key를 삽입합니다.
이 샘플 요청은 가독성을 위해 두 개의 줄로 나누어져 있습니다.
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
필터 표현식 작성에 대한 자세한 내용은 clusters.list 및 jobs.list Dataproc API 참고 리소스를 참조하세요.
콘솔
Google Cloud 콘솔을 사용하여 만들거나 제출할 때 Managed Service for Apache Spark 클러스터나 작업에 추가할 라벨 집합을 지정할 수 있습니다.
- Managed Service for Apache Spark 클러스터 만들기 페이지의 클러스터 맞춤설정 패널의 라벨 섹션에서 클러스터에 라벨을 추가합니다.
- Managed Service for Apache Spark 작업 제출 페이지에서 작업에 라벨을 추가합니다.
Managed Service for Apache Spark 클러스터 또는 작업이 생성되거나 제출되면 이 클러스터 또는 작업과 연결된 라벨을 업데이트할 수 있습니다. 라벨을 업데이트하려면 나열된 클러스터 또는 작업의 선택 상자를 클릭한 다음 SHOW INFO PANEL을 클릭합니다. 다음은 Managed Service for Apache Spark→클러스터 나열 페이지의 예시입니다.

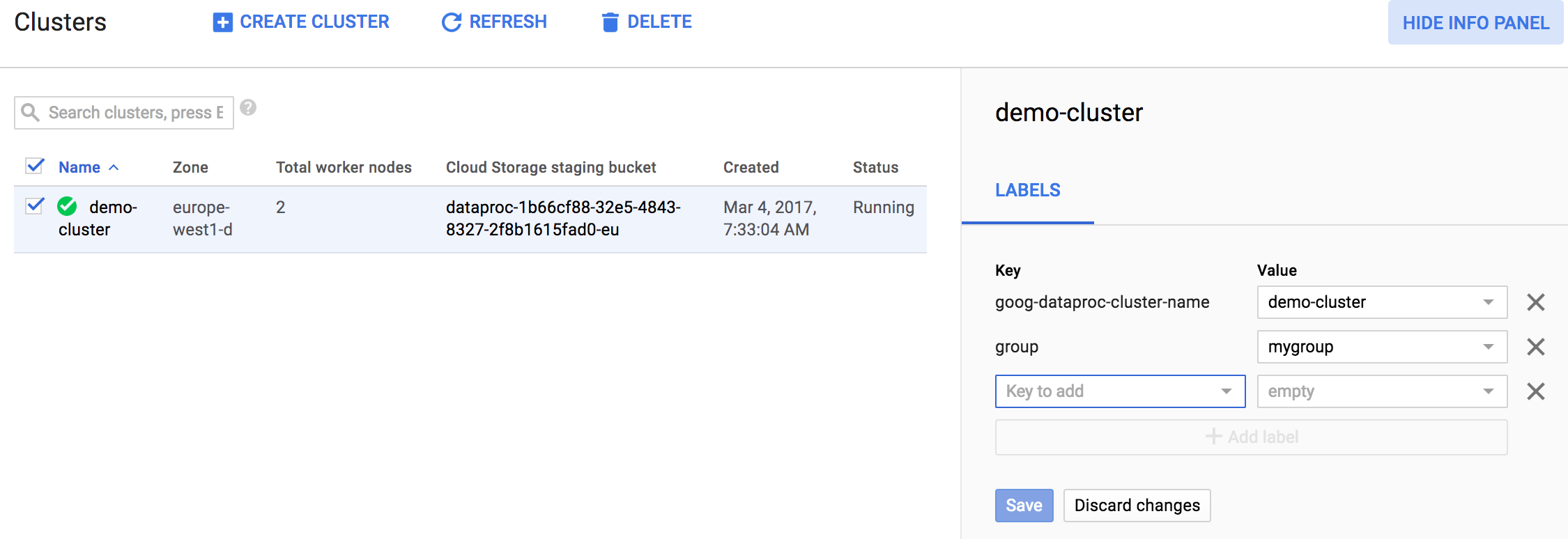
정보 패널이 표시되면 Managed Service for Apache Spark 클러스터 또는 작업의 라벨을 업데이트할 수 있습니다. 다음은 Managed Service for Apache Spark 클러스터의 라벨을 업데이트하는 예시입니다.
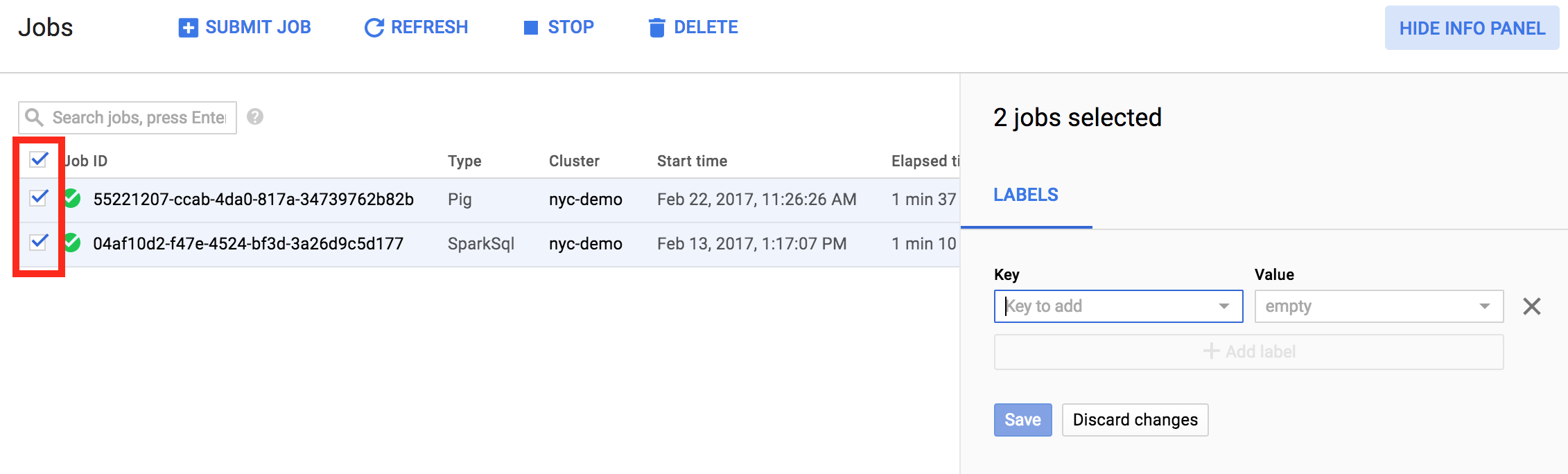
또한 한 작업에서 여러 항목의 라벨을 업데이트할 수도 있습니다. 이 예에서는 여러 Managed Service for Apache Spark 작업의 라벨을 한번에 업데이트합니다.
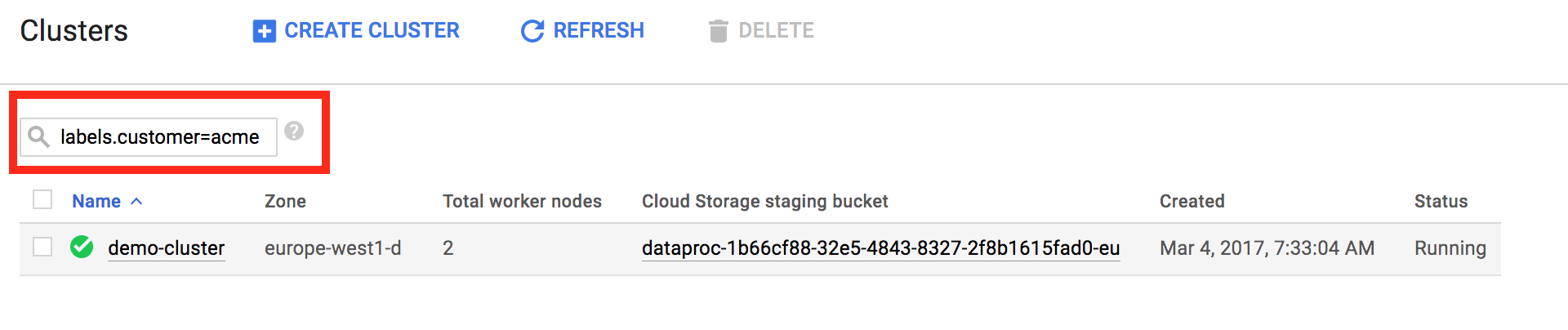
라벨을 사용하면 [Managed Service for Apache Spark→클러스터 나열](https://console.cloud.google.com/dataproc/clusters) 및 [Managed Service for Apache Spark→작업 나열](https://console.cloud.google.com/dataproc/jobs) 페이지에 표시된 Managed Service for Apache Spark 리소스를 필터링할 수 있습니다. 페이지 상단에서 검색 패턴 `labels.
라벨 자동 적용
클러스터를 만들거나 업데이트할 때 Managed Service for Apache Spark는 자동으로 클러스터와 클러스터 리소스에 라벨을 여러 개 적용합니다. 예를 들어 Managed Service for Apache Spark는 클러스터가 생성될 때 가상 머신, 영구 디스크, 가속기에 라벨을 적용합니다. 자동으로 적용되는 라벨에는 특별한 goog-dataproc 프리픽스가 있습니다.
다음 goog-dataproc 라벨은 Managed Service for Apache Spark 리소스에 자동으로 적용됩니다. 클러스터를 만들 때 지정되는 goog-dataproc 라벨에 다른 값을 입력하면 자동 적용된 값이 재정의됩니다. 따라서 자체 값을 입력하는 것은 권장되지 않습니다.
| 라벨 | 설명 |
|---|---|
goog-dataproc-cluster-name |
사용자가 지정한 클러스터 이름입니다. |
goog-dataproc-cluster-uuid |
고유한 클러스터 ID입니다. |
goog-dataproc-location |
Managed Service for Apache Spark 리전 클러스터 엔드포인트 |
다음과 같은 다양한 방법으로 자동 적용되는 라벨을 사용할 수 있습니다.
- Managed Service for Apache Spark 리소스 검색 및 필터링
- 결제 데이터 필터링을 통해 Managed Service for Apache Spark 비용 계산
다음 단계
Resource Manager를 사용하여 프로젝트용 라벨 만들기 및 업데이트 방법 알아보기
라벨을 사용한 리소스 정리 방법 알아보기