
Anda dapat menerapkan label pengguna ke cluster dan tugas Managed Service untuk Apache Spark untuk mengelompokkan resource ini agar dapat difilter dan dicantumkan nanti. Anda mengaitkan label dengan resource saat resource dibuat, saat pembuatan cluster, atau pengiriman tugas. Setelah resource dikaitkan dengan label, label tersebut akan disebarkan ke operasi yang dilakukan pada resource pembuatan, update, patch, atau penghapusan cluster; pengiriman, update, pembatalan, atau penghapusan tugas, sehingga Anda dapat memfilter dan mencantumkan cluster, tugas, dan operasi menurut label.
Anda juga dapat menambahkan label ke resource Compute Engine yang dikaitkan dengan resource cluster, seperti instance dan disk Virtual Machine.
Apa yang dimaksud dengan label?
Label adalah pasangan nilai kunci yang dapat Anda tetapkan ke cluster dan tugas Managed Service untuk Apache Spark. Label membantu Anda mengatur resource ini dan mengelola biaya dalam skala besar, dengan perincian yang Anda butuhkan. Anda dapat menghubungkan label ke tiap resource, lalu memfilter resource menurut labelnya. Informasi tentang label akan diteruskan ke sistem penagihan, sehingga Anda dapat mengelompokkan tagihan biaya berdasarkan label. Dengan laporan penagihan bawaan, Anda dapat memfilter dan mengelompokkan biaya berdasarkan label resource. Anda juga dapat menggunakan label untuk membuat kueri ekspor data penagihan.
Persyaratan untuk label
Label yang diterapkan pada resource harus memenuhi persyaratan berikut:
- Tiap cluster atau tugas dapat memiliki hingga 32 label.
- Tiap label harus berupa pasangan nilai kunci.
- Kunci memiliki panjang minimum 1 karakter dan panjang maksimum 63 karakter, serta tidak boleh kosong. Nilai boleh kosong dan memiliki panjang maksimum 63 karakter.
- Kunci dan nilai hanya boleh berisi huruf kecil, karakter numerik, garis bawah, dan tanda pisah. Semua karakter harus menggunakan encoding UTF-8, dan boleh menggunakan karakter internasional. Kunci harus diawali dengan huruf kecil atau karakter internasional.
- Bagian kunci label harus unik dalam satu resource. Namun, Anda dapat menggunakan kunci yang sama dengan beberapa resource.
Batasan ini berlaku untuk kunci dan nilai tiap label, serta untuk tiap cluster atau tugas Managed Service untuk Apache Spark yang memiliki label. Tidak ada batasan jumlah label yang dapat diterapkan di semua resource dalam satu project.
Penggunaan label secara umum
Berikut adalah beberapa kasus penggunaan umum untuk label:
Label tim atau pusat biaya: Tambahkan label berdasarkan tim atau pusat biaya untuk membedakan cluster dan tugas Managed Service untuk Apache Spark yang dimiliki oleh tim yang berbeda (misalnya,
team:researchdanteam:analytics). Anda dapat menggunakan jenis label ini untuk akuntansi atau penganggaran biaya.Label komponen: Misalnya,
component:redis,component:frontend,component:ingest, dancomponent:dashboard.Label lingkungan atau tahap: Misalnya,
environment:productiondanenvironment:test.Label status: Misalnya,
state:active,state:readytodelete, danstate:archive.Label kepemilikan: Digunakan untuk mengidentifikasi tim yang bertanggung jawab atas operasi, misalnya:
team:shopping-cart.
Sebaiknya Anda tidak membuat label unik dalam jumlah besar, seperti untuk stempel waktu atau nilai individu bagi tiap panggilan API. Masalah dari pendekatan ini adalah ketika nilai sering berubah atau dengan adanya kunci yang mengacaukan katalog, pemfilteran dan pelaporan resource secara efektif akan sulit dilakukan.
Label dan tag
Label dapat digunakan sebagai anotasi yang dapat dikueri untuk resource, tetapi tidak dapat digunakan untuk menetapkan kondisi pada kebijakan. Tag menyediakan cara untuk mengizinkan atau menolak kebijakan secara bersyarat berdasarkan apakah resource memiliki tag tertentu, dengan memberikan kontrol terperinci atas kebijakan. Untuk informasi selengkapnya, lihat Ringkasan tag.
Membuat dan menggunakan label Managed Service untuk Apache Spark
Perintah gcloud
Anda dapat menentukan satu atau beberapa label yang akan diterapkan pada cluster atau tugas Managed Service for Apache Spark pada saat pembuatan atau pengiriman menggunakan Google Cloud CLI.
gcloud dataproc clusters create args --labels environment=production,customer=acmegcloud dataproc jobs submit args --labels environment=production,customer=acme
Setelah cluster atau tugas Managed Service untuk Apache Spark dibuat, Anda dapat mengupdate label yang terkait dengan resource tersebut menggunakan Google Cloud CLI.
gcloud dataproc clusters update args --update-labels environment=production,customer=acmegcloud dataproc jobs update args --update-labels environment=production,customer=acme
Demikian pula, Anda dapat menggunakan Google Cloud CLI untuk memfilter resource Managed Service untuk Apache Spark menurut label menggunakan
ekspresi filter dengan format berikut: labels.<key=value>.
gcloud dataproc clusters list \ --region=region \ --filter="status.state=ACTIVE AND labels.environment=production"gcloud dataproc jobs list \ --region=region \ --filter="status.state=ACTIVE AND labels.customer=acme"
Baca dokumentasi Dataproc API clusters.list dan jobs.list untuk mengetahui informasi selengkapnya tentang cara menulis ekspresi filter.
REST API
Label dapat dilampirkan ke cluster atau tugas Managed Service untuk Apache Spark melalui
Managed Service for Apache Spark REST API. API clusters.create
dan jobs.submit
dapat digunakan untuk menghubungkan label ke cluster atau tugas pada saat pembuatan atau pengiriman.
API clusters.patch dan
jobs.patch
dapat digunakan untuk mengedit label setelah cluster dibuat. Berikut adalah isi JSON permintaan cluster.create yang mencakup tindakan menghubungkan label key1:value ke cluster.
{
"clusterName":"cluster-1",
"projectId":"my-project",
"config":{
"configBucket":"",
"gceClusterConfig":{
"networkUri":".../networks/default",
"zoneUri":".../zones/us-central1-f"
},
"masterConfig":{
"numInstances":1,
"machineTypeUri":"..../machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
},
"workerConfig":{
"numInstances":2,
"machineTypeUri":"...machineTypes/n1-standard-4",
"diskConfig":{
"bootDiskSizeGb":500,
"numLocalSsds":0
}
}
},
"labels":{
"key1":"value1"
}
}
API clusters.list
dan jobs.list
dapat digunakan untuk mencantumkan cluster atau tugas yang cocok dengan filter tertentu, menggunakan
format berikut: labels.<key=value>.
Berikut adalah contoh permintaan GET HTTPS
clusters.list
Dataproc API yang menentukan filter label key=value. Pemanggil menyisipkan
project, region, filter label-key dan label-value, serta api-key.
Perhatikan bahwa contoh permintaan ini dibagi menjadi dua baris agar mudah dibaca.
GET https://dataproc.googleapis.com/v1/projects/project/regions/region/clusters? filter=labels.label-key=label-value&key=api-key
Baca dokumentasi Dataproc API clusters.list dan jobs.list untuk mengetahui informasi selengkapnya tentang cara menulis ekspresi filter.
Konsol
Anda dapat menentukan serangkaian label untuk ditambahkan ke cluster atau tugas Managed Service untuk Apache Spark pada saat pembuatan atau pengiriman menggunakan konsol Google Cloud .
- Tambahkan label ke cluster dari bagian Label di panel Customize cluster pada halaman Create a cluster Managed Service untuk Apache Spark.
- Tambahkan label ke tugas dari halaman Submit a job Managed Service untuk Apache Spark.
Setelah cluster atau tugas Managed Service untuk Apache Spark dibuat atau dikirimkan,
Anda dapat mengupdate label yang terkait dengan cluster atau tugas tersebut. Untuk mengupdate label,
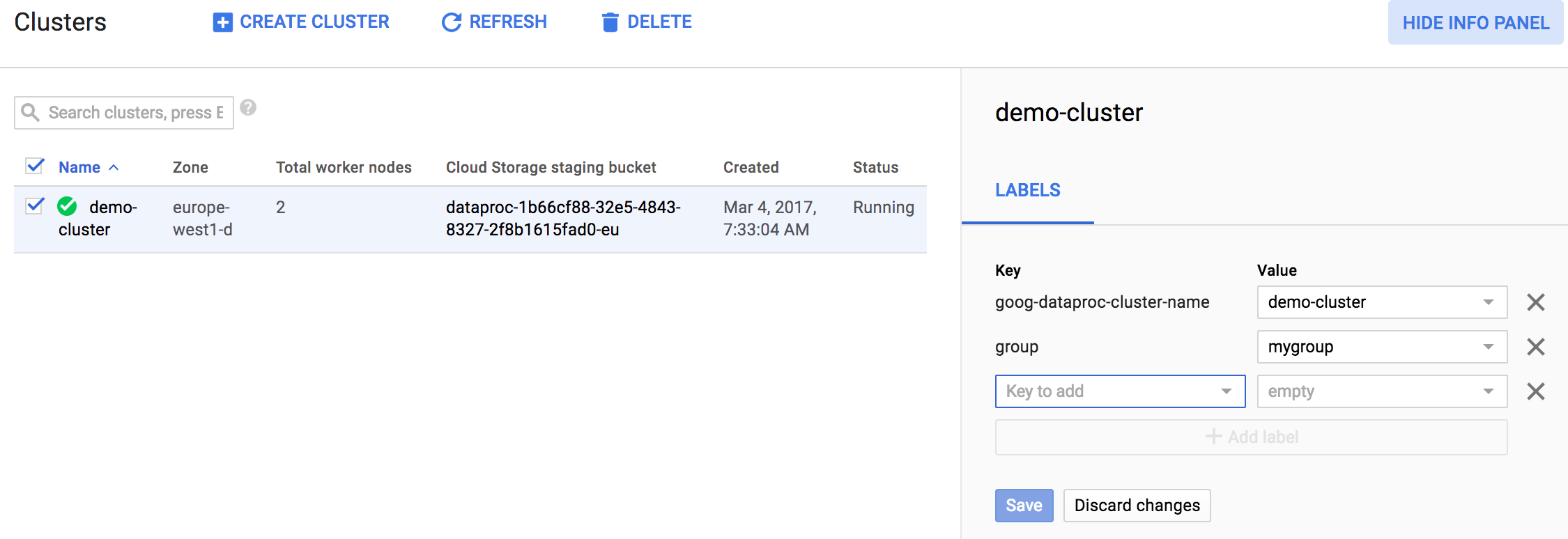
klik kotak pilihan cluster atau tugas yang tercantum, lalu klik SHOW INFO PANEL. Berikut adalah contoh dari halaman Managed Service for Apache Spark→Daftar cluster.

Setelah panel info ditampilkan, Anda dapat mengupdate label untuk cluster atau tugas Managed Service untuk Apache Spark. Berikut adalah contoh cara mengupdate label untuk cluster Managed Service untuk Apache Spark.
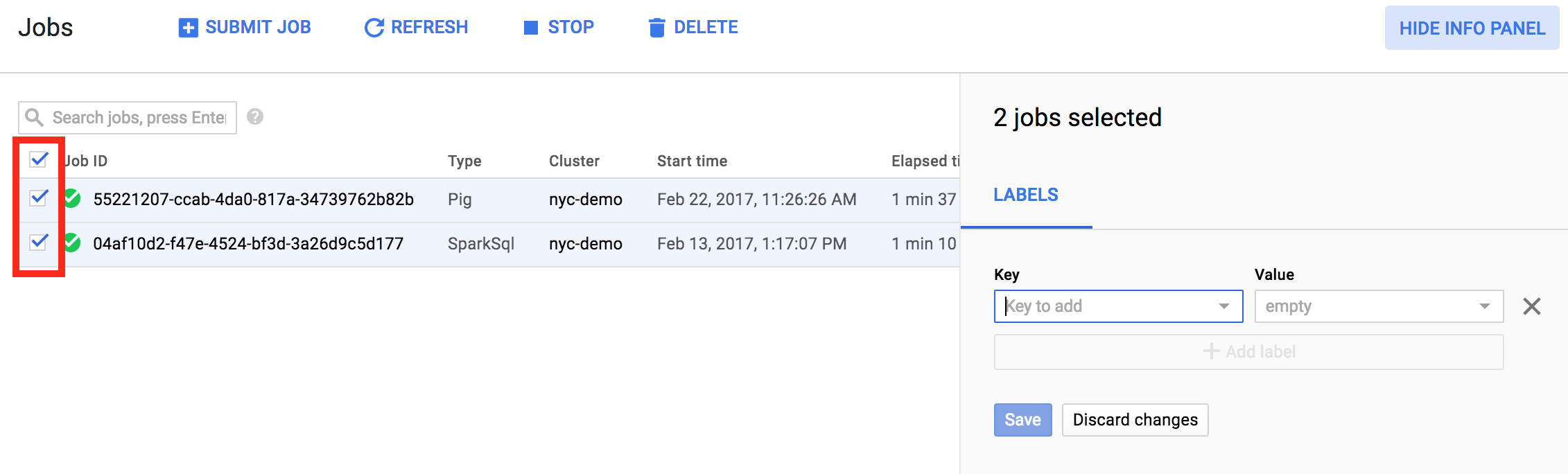
Anda juga dapat mengupdate label pada beberapa item dalam satu operasi. Dalam contoh ini, label diupdate untuk beberapa tugas Managed Service untuk Apache Spark secara bersamaan.
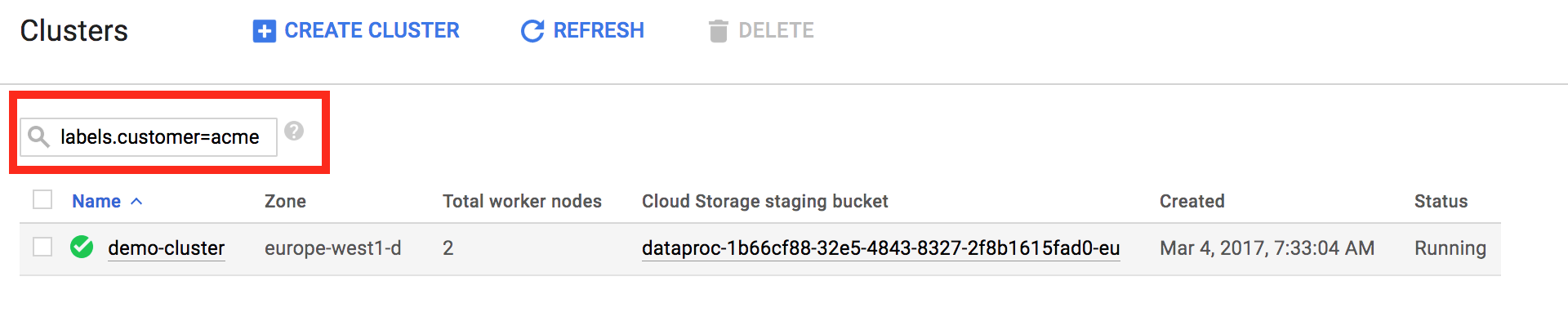
Dengan label, Anda dapat memfilter resource Managed Service untuk Apache Spark yang ditampilkan di halaman [Managed Service for Apache Spark→List clusters](https://console.cloud.google.com/dataproc/clusters) dan [Managed Service for Apache Spark→List jobs](https://console.cloud.google.com/dataproc/jobs). Di bagian atas halaman, Anda dapat menggunakan pola penelusuran `labels.
Label yang diterapkan secara otomatis
Saat membuat atau mengupdate cluster, Managed Service untuk Apache Spark akan otomatis
menerapkan beberapa label ke cluster dan resource cluster. Misalnya,
Managed Service untuk Apache Spark akan menerapkan label ke virtual machine, persistent disk,
dan akselerator saat cluster dibuat. Label yang diterapkan akan otomatis memiliki awalan khusus yaitu goog-dataproc.
Label goog-dataproc berikut akan otomatis diterapkan ke
resource Managed Service untuk Apache Spark. Nilai apa pun yang Anda berikan untuk label
goog-dataproc yang dicadangkan saat pembuatan cluster akan menggantikan
nilai yang diberikan secara otomatis. Oleh sebab itu, sebaiknya jangan memberikan nilai secara manual untuk
label ini.
| Label | Deskripsi |
|---|---|
goog-dataproc-cluster-name |
Nama cluster yang ditentukan pengguna |
goog-dataproc-cluster-uuid |
ID cluster unik |
goog-dataproc-location |
Endpoint cluster regional Managed Service untuk Apache Spark |
Anda dapat menggunakan label yang diterapkan secara otomatis dengan berbagai cara, antara lain:
- Menelusuri dan memfilter resource Managed Service untuk Apache Spark
- Memfilter data penagihan untuk menghitung biaya Managed Service untuk Apache Spark
Langkah berikutnya
Pelajari cara membuat dan mengupdate label untuk project menggunakan Resource Manager.
Pelajari cara mengatur resource menggunakan label.