
Ce document répertorie les messages d'erreur courants des tâches, et fournit des informations sur la surveillance et le débogage des tâches pour vous aider à résoudre les problèmes liés aux tâches Dataproc.
Messages d'erreur courants des tâches
La tâche n'a pas été acquise
Cela indique que l'agent Dataproc sur le nœud maître n'a pas pu acquérir la tâche à partir du plan de contrôle. Cela se produit souvent en raison de problèmes de mémoire saturée ou de réseau. Si la tâche a bien été exécutée précédemment et que vous n'avez pas modifié les paramètres de configuration du réseau, les problèmes de mémoire saturée sont la cause la plus probable, souvent le résultat de l'envoi de nombreuses tâches en cours d'exécution simultanées ou de tâches dont les pilotes consomment une mémoire importante (par exemple, les tâches qui chargent de grands ensembles de données en mémoire).
Aucun agent actif trouvé sur le ou les nœuds maîtres
Cela indique que l'agent Dataproc sur le nœud maître n'est pas actif et ne peut pas accepter de nouvelles tâches. Cela se produit souvent en raison de problèmes de mémoire saturée (OOM) ou de réseau, ou si la VM du nœud maître est défectueuse. Si la tâche a bien été exécutée précédemment et que vous n'avez pas modifié les paramètres de configuration du réseau, les problèmes de mémoire saturée sont la cause la plus probable, souvent le résultat de l'envoi de nombreuses tâches en cours d'exécution simultanées ou de tâches dont les pilotes consomment une mémoire importante (par exemple, les tâches qui chargent de grands ensembles de données en mémoire).
Pour résoudre le problème, essayez les actions suivantes :
- Redémarrez la tâche.
- Connectez-vous au nœud maître du cluster à l'aide de SSH, puis déterminez quelle tâche ou autre ressource utilise le plus de mémoire.
Si vous ne parvenez pas à vous connecter au nœud maître, consultez les journaux du port série (console).

Générez un bundle de diagnostic, contenant le syslog et d'autres données.
Tâche introuvable
Cette erreur indique que le cluster a été supprimé pendant l'exécution d'une tâche. Vous pouvez effectuer les actions suivantes pour identifier le principal qui a effectué la suppression et confirmer que la suppression du cluster s'est produite pendant l'exécution d'une tâche :
Affichez les journaux d'audit Dataproc pour identifier le principal qui a effectué l'opération de suppression.
Utilisez Logging ou la CLI gcloud pour vérifier que le dernier état connu de l'application YARN était RUNNING :
- Utilisez le filtre suivant dans Logging :
resource.type="cloud_dataproc_cluster" resource.labels.cluster_name="CLUSTER_NAME" resource.labels.cluster_uuid="CLUSTER_UUID" "YARN_APPLICATION_ID State change from"
- Exécutez
gcloud dataproc jobs describe job-id --region=REGION, puis vérifiezyarnApplications: > STATEdans la sortie.
Si le principal qui a supprimé le cluster est le compte de service de l'agent de service Dataproc, vérifiez si le cluster a été configuré avec une durée de suppression automatique inférieure à la durée de la tâche.
Pour éviter les erreurs Task not found, utilisez l'automatisation pour vous assurer que les clusters ne sont pas supprimés
avant la fin de toutes les tâches en cours d'exécution.
Aucun espace restant sur le dispositif
Dataproc écrit les données HDFS et les données temporaires sur le disque. Ce message d'erreur indique que le cluster a été créé avec un espace disque insuffisant. Pour analyser et éviter cette erreur :
Vérifiez la taille du disque principal du cluster indiquée dans l'onglet Configuration de la page Détails du cluster de la Google Cloud console. La taille minimale recommandée du disque est de
1000 GBpour les clusters utilisant len1-standard-4type de machine et de2 TBpour les clusters utilisant len1-standard-32type de machine.Si la taille du disque du cluster est inférieure à la taille recommandée, recréez le cluster avec au moins la taille de disque recommandée.
Si la taille du disque est égale ou supérieure à la taille recommandée, utilisez SSH pour vous connecter à la VM maître du cluster, puis exécutez
df -hsur la VM maître pour vérifier l'utilisation du disque et déterminer si un espace disque supplémentaire est nécessaire.
Surveillance et débogage des tâches
Utilisez la CLI gcloud, l'API REST Dataproc et la Google Cloud console pour analyser et déboguer les tâches Dataproc.
CLI gcloud
Pour examiner le statut d'une tâche en cours d'exécution, procédez comme suit :
gcloud dataproc jobs describe job-id \ --region=region
Pour afficher les résultats du pilote de la tâche, consultez la section Afficher les résultats de la tâche.
API REST
Appelez jobs.get pour examiner les champs JobStatus.State, JobStatus.Substate, JobStatus.details et YarnApplication d'une tâche.
Console
Pour afficher les résultats du pilote de la tâche, consultez la section Afficher les résultats de la tâche.
Pour afficher le journal de l'agent dataproc dans Logging, sélectionnez Dataproc Cluster→Cluster Name→Cluster UUID dans le sélecteur de cluster de l'explorateur de journaux.
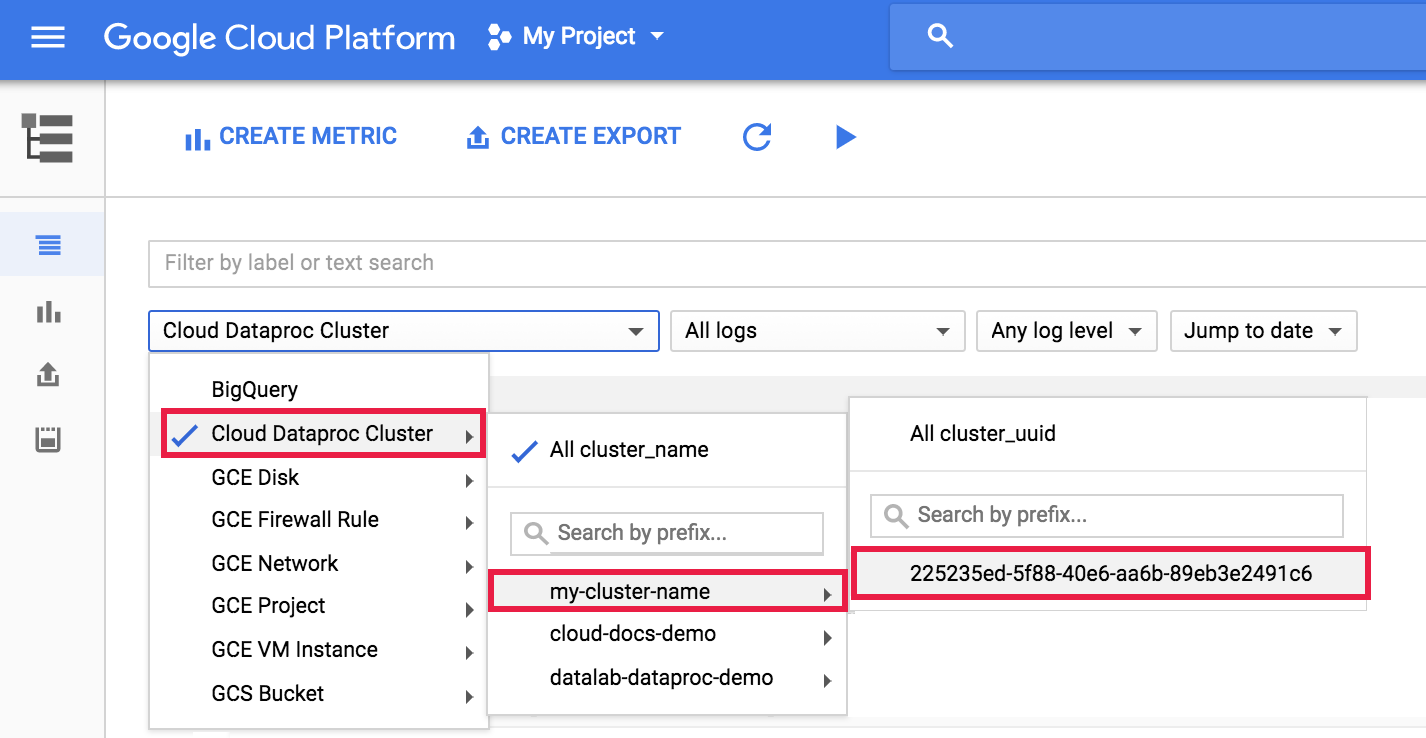
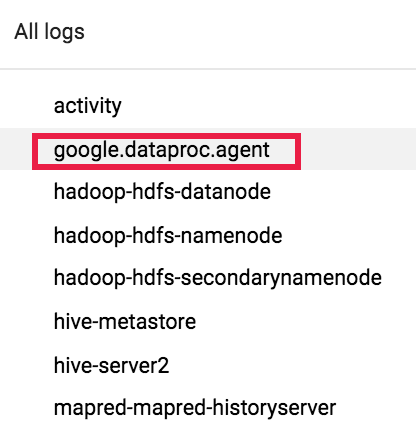
Utilisez ensuite le sélecteur de journaux pour sélectionner les journaux google.dataproc.agent.
Afficher les journaux de tâches dans Logging
Si une tâche échoue, vous pouvez accéder aux journaux des tâches dans Logging.
Déterminer l'émetteur d'une tâche
La recherche des détails d'une tâche affichera l'émetteur de la tâche dans le champ submittedBy. Par exemple, le résultat de la tâche suivant montre que user@domain a envoyé l'exemple de tâche à un cluster.
... placement: clusterName: cluster-name clusterUuid: cluster-uuid reference: jobId: job-uuid projectId: project status: state: DONE stateStartTime: '2018-11-01T00:53:37.599Z' statusHistory: - state: PENDING stateStartTime: '2018-11-01T00:33:41.387Z' - state: SETUP_DONE stateStartTime: '2018-11-01T00:33:41.765Z' - details: Agent reported job success state: RUNNING stateStartTime: '2018-11-01T00:33:42.146Z' submittedBy: user@domain