
Il plug-in Managed Service for Apache Spark Ranger Cloud Storage, disponibile con le versioni 1.5 e 2.0 dell'immagine Managed Service for Apache Spark, attiva un servizio di autorizzazione su ogni VM del cluster Managed Service for Apache Spark. Il servizio di autorizzazione valuta le richieste del connettore Cloud Storage in base alle policy Ranger e, se la richiesta è consentita, restituisce un token di accesso per il service account VM del cluster.
Il plug-in Ranger Cloud Storage si basa su Kerberos per l'autenticazione e si integra con il supporto del connettore Cloud Storage per i token di delega. I token di delega vengono archiviati in un database MySQL sul nodo master del cluster. La password di root per il database viene specificata tramite le proprietà del cluster quando crei il cluster Managed Service for Apache Spark.
Prima di iniziare
Concedi il ruolo Creatore token account di servizio e il ruolo Amministratore ruoli IAM nell'account di servizio VM Managed Service for Apache Spark nel tuo progetto.
Installa il plug-in Ranger Cloud Storage
Esegui i seguenti comandi in una finestra del terminale locale o in Cloud Shell per installare il plug-in Ranger Cloud Storage quando crei un cluster Managed Service for Apache Spark.
Imposta le variabili di ambiente
export CLUSTER_NAME=new-cluster-name \ export REGION=region \ export KERBEROS_KMS_KEY_URI=Kerberos-KMS-key-URI \ export KERBEROS_PASSWORD_URI=Kerberos-password-URI \ export RANGER_ADMIN_PASSWORD_KMS_KEY_URI=Ranger-admin-password-KMS-key-URI \ export RANGER_ADMIN_PASSWORD_GCS_URI=Ranger-admin-password-GCS-URI \ export RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI=MySQL-root-password-KMS-key-URI \ export RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI=MySQL-root-password-GCS-URI
Note:
- CLUSTER_NAME: il nome del nuovo cluster.
- REGIONE: la regione in cui verrà creato il cluster, ad esempio
us-west1. - KERBEROS_KMS_KEY_URI e KERBEROS_PASSWORD_URI: vedi Configurare la password dell'entità principale root Kerberos.
- RANGER_ADMIN_PASSWORD_KMS_KEY_URI e RANGER_ADMIN_PASSWORD_GCS_URI: vedi Configurare la password di amministratore di Ranger.
- RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI e RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI: configura una password MySQL seguendo la stessa procedura che hai utilizzato per configurare una password di amministrazione di Ranger.
Crea un cluster Managed Service for Apache Spark
Esegui questo comando per creare un cluster Managed Service for Apache Spark e installare il plug-in Ranger Cloud Storage sul cluster.
gcloud dataproc clusters create ${CLUSTER_NAME} \
--region=${REGION} \
--scopes cloud-platform \
--enable-component-gateway \
--optional-components=SOLR,RANGER \
--kerberos-kms-key=${KERBEROS_KMS_KEY_URI} \
--kerberos-root-principal-password-uri=${KERBEROS_PASSWORD_URI} \
--properties="dataproc:ranger.gcs.plugin.enable=true, \
dataproc:ranger.kms.key.uri=${RANGER_ADMIN_PASSWORD_KMS_KEY_URI}, \
dataproc:ranger.admin.password.uri=${RANGER_ADMIN_PASSWORD_GCS_URI}, \
dataproc:ranger.gcs.plugin.mysql.kms.key.uri=${RANGER_GCS_PLUGIN_MYSQL_KMS_KEY_URI}, \
dataproc:ranger.gcs.plugin.mysql.password.uri=${RANGER_GCS_PLUGIN_MYSQL_PASSWORD_URI}"
Note:
- Versione immagine 1.5:se stai creando un cluster con la versione immagine 1.5 (vedi
Selezione delle versioni),
aggiungi il flag
--metadata=GCS_CONNECTOR_VERSION="2.2.6" or higherper installare la versione del connettore richiesta.
Verifica l'installazione del plug-in Ranger Cloud Storage
Al termine della creazione del cluster, nell'interfaccia web di amministrazione di Ranger viene visualizzato un tipo di servizio GCS denominato gcs-dataproc.

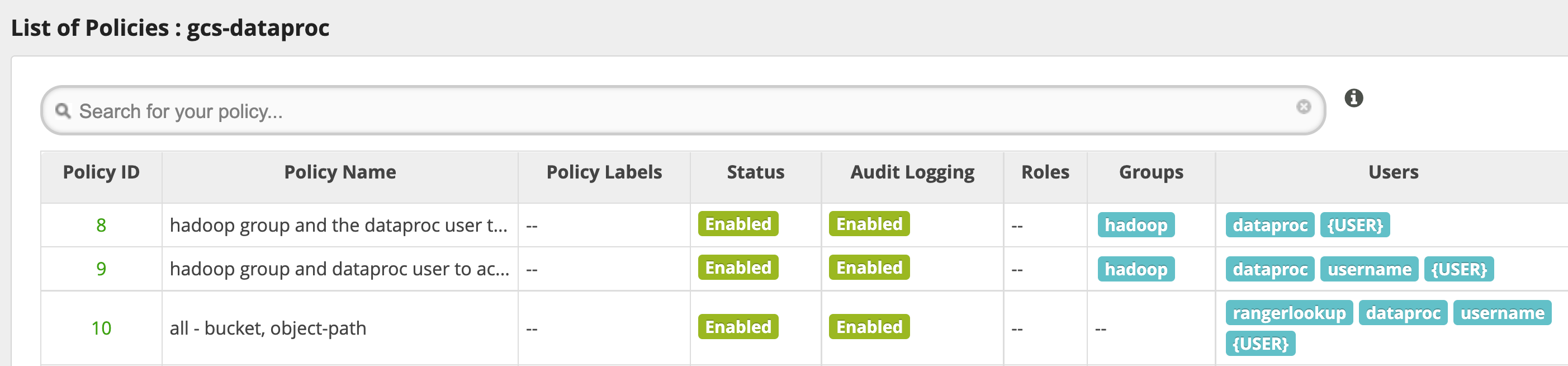
Norme predefinite del plug-in Ranger Cloud Storage
Il servizio gcs-dataproc predefinito ha i seguenti criteri:
Policy per leggere e scrivere nei bucket temporanei e di gestione temporanea del cluster Managed Service for Apache Spark
Un criterio
all - bucket, object-path, che consente a tutti gli utenti di accedere ai metadati di tutti gli oggetti. Questo accesso è necessario per consentire al connettore Cloud Storage di eseguire operazioni HCFS (Hadoop Compatible Filesystem).
Consigli per l'utilizzo
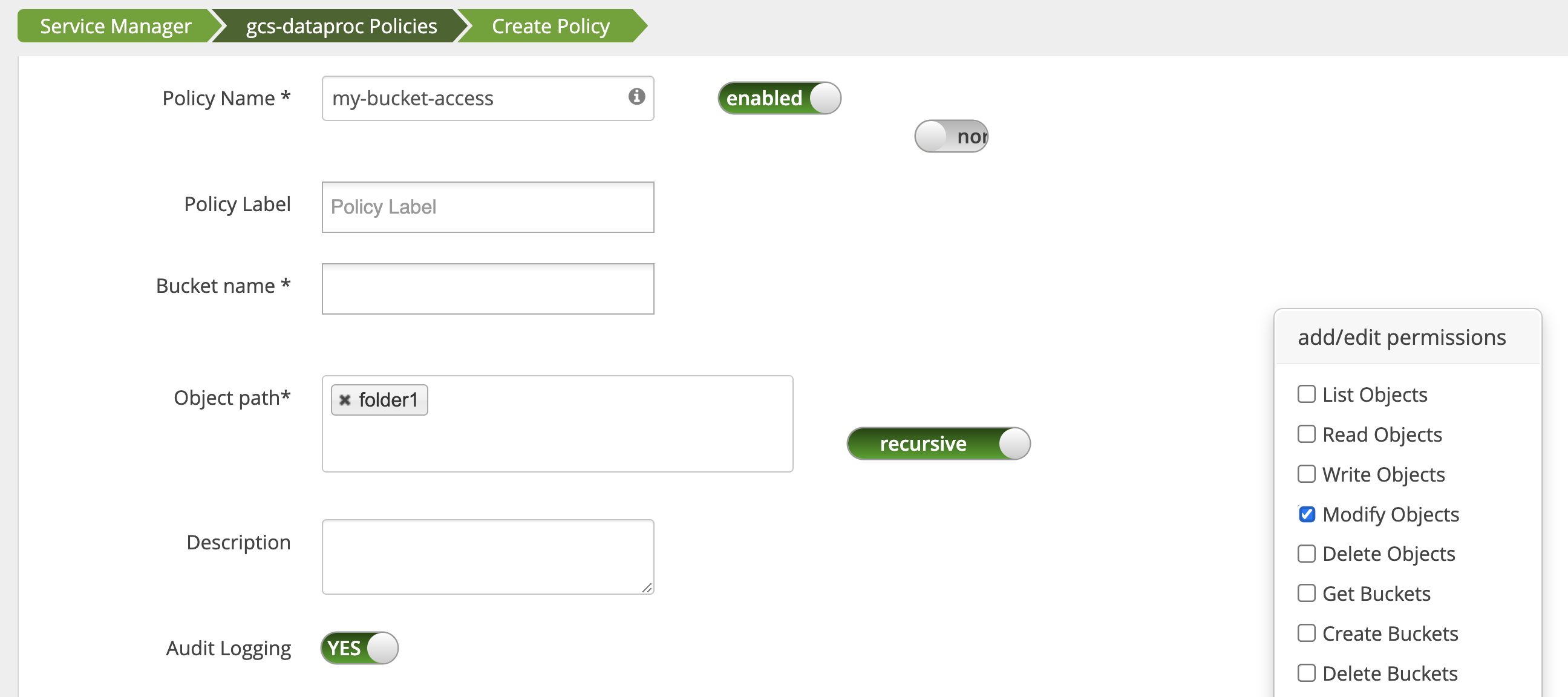
Accesso delle app alle cartelle dei bucket
Per ospitare app che creano file intermedi nel bucket Cloud Storage,
puoi concedere le autorizzazioni Modify Objects, List Objects e Delete Objects
sul percorso del bucket Cloud Storage, quindi selezionare
la modalità recursive per estendere le autorizzazioni ai sottopercorsi del percorso specificato.
Misure protettive
Per evitare la circonvenzione del plug-in:
Concedi all'account di servizio VM l'accesso alle risorse nei tuoi bucket Cloud Storage per consentirgli di concedere l'accesso a queste risorse con token di accesso con ambito ridotto (consulta Autorizzazioni IAM per Cloud Storage). Inoltre, rimuovi l'accesso degli utenti alle risorse bucket per evitare l'accesso diretto degli utenti al bucket.
Disabilita
sudoe altri mezzi di accesso root sulle VM del cluster, incluso l'aggiornamento del filesudoer, per impedire la rappresentazione o le modifiche alle impostazioni di autenticazione e autorizzazione. Per ulteriori informazioni, consulta le istruzioni per Linux per l'aggiunta/rimozione dei privilegi utentesudo.Utilizza
iptableper bloccare le richieste di accesso diretto a Cloud Storage dalle VM del cluster. Ad esempio, puoi bloccare l'accesso al server dei metadati della VM per impedire l'accesso alle credenziali del account di servizio della VM o al token di accesso utilizzato per autenticare e autorizzare l'accesso a Cloud Storage (vediblock_vm_metadata_server.sh, uno script di inizializzazione che utilizza le regoleiptableper bloccare l'accesso al server dei metadati della VM).
Job Spark, Hive-on-MapReduce e Hive-on-Tez
Per proteggere i dettagli di autenticazione utente sensibili e ridurre il carico sul Key Distribution Center (KDC), il driver Spark non distribuisce le credenziali Kerberos agli executor. Il driver Spark ottiene invece un token di delega dal plug-in Ranger Cloud Storage e lo distribuisce agli executor. Gli executor utilizzano il token di delega per autenticarsi al plug-in Ranger Cloud Storage, scambiandolo con un token di accesso Google che consente l'accesso a Cloud Storage.
Anche i job Hive-on-MapReduce e Hive-on-Tez utilizzano token per accedere a Cloud Storage. Utilizza le seguenti proprietà per ottenere token per accedere ai bucket Cloud Storage specificati quando invii i seguenti tipi di job:
Job Spark:
--conf spark.yarn.access.hadoopFileSystems=gs://bucket-name,gs://bucket-name,...
Job Hive-on-MapReduce:
--hiveconf "mapreduce.job.hdfs-servers=gs://bucket-name,gs://bucket-name,..."
Job Hive-on-Tez:
--hiveconf "tez.job.fs-servers=gs://bucket-name,gs://bucket-name,..."
Scenario del job Spark
Un job Spark wordcount non viene eseguito quando viene eseguito da una finestra del terminale su una VM del cluster Managed Service for Apache Spark in cui è installato il plug-in Ranger Cloud Storage.
spark-submit \
--conf spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET} \
--class org.apache.spark.examples.JavaWordCount \
/usr/lib/spark/examples/jars/spark-examples.jar \
gs://bucket-name/wordcount.txt
Note:
- FILE_BUCKET: bucket Cloud Storage per l'accesso a Spark.
Output degli errori:
Caused by: com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: '<USER>', Bucket: '<dataproc_temp_bucket>', Object Path: 'a97127cf-f543-40c3-9851-32f172acc53b/spark-job-history/', Action: 'LIST_OBJECTS'
Note:
spark.yarn.access.hadoopFileSystems=gs://${FILE_BUCKET}è obbligatorio in un ambiente abilitato a Kerberos.
Output degli errori:
Caused by: java.lang.RuntimeException: Failed creating a SPNEGO token. Make sure that you have run `kinit` and that your Kerberos configuration is correct. See the full Kerberos error message: No valid credentials provided (Mechanism level: No valid credentials provided)
Un criterio viene modificato utilizzando Access Manager nell'interfaccia web di amministrazione di Ranger
per aggiungere username all'elenco degli utenti che dispongono di List Objects e di altre autorizzazioni per i bucket temp.
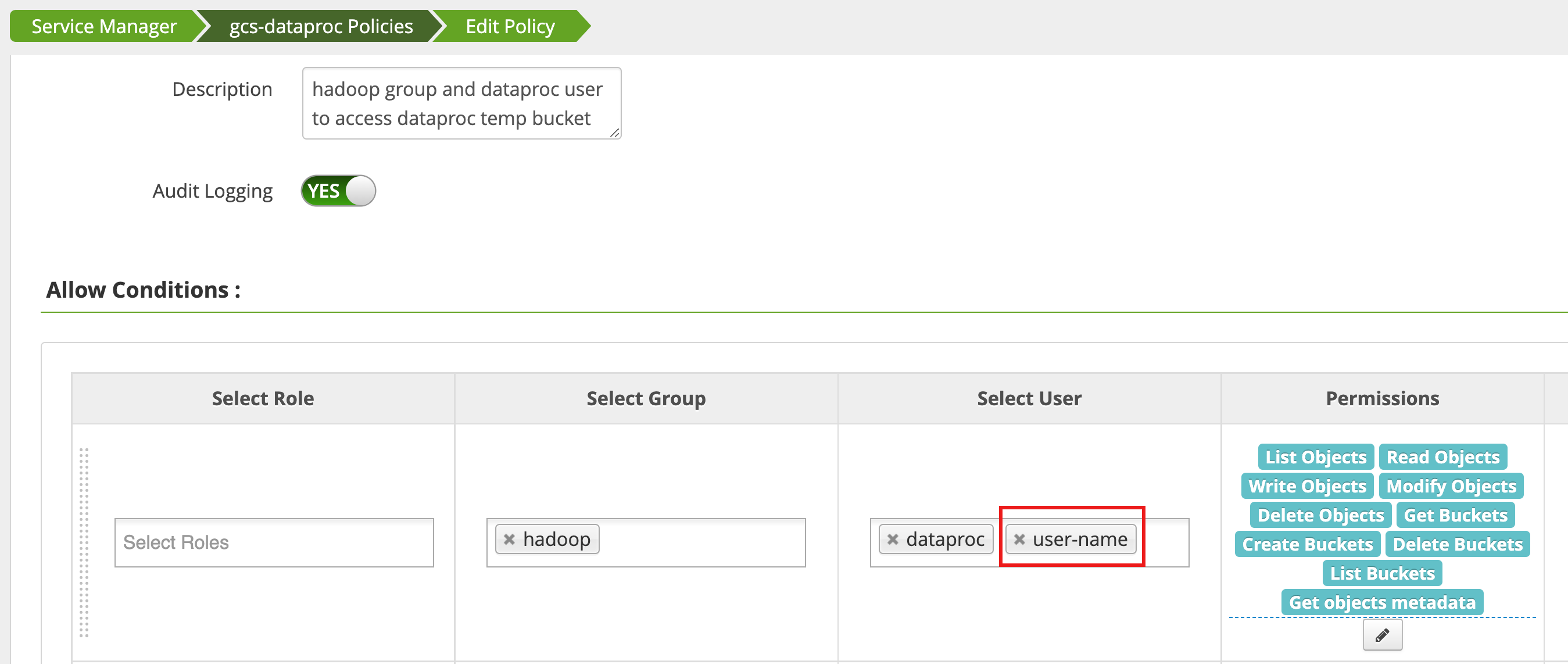
L'esecuzione del job genera un nuovo errore.
Output degli errori:
com.google.gcs.ranger.client.shaded.io.grpc.StatusRuntimeException: PERMISSION_DENIED: Access denied by Ranger policy: User: <USER>, Bucket: '<file-bucket>', Object Path: 'wordcount.txt', Action: 'READ_OBJECTS'
Viene aggiunta una policy per concedere all'utente l'accesso in lettura al percorso Cloud Storage wordcount.text.
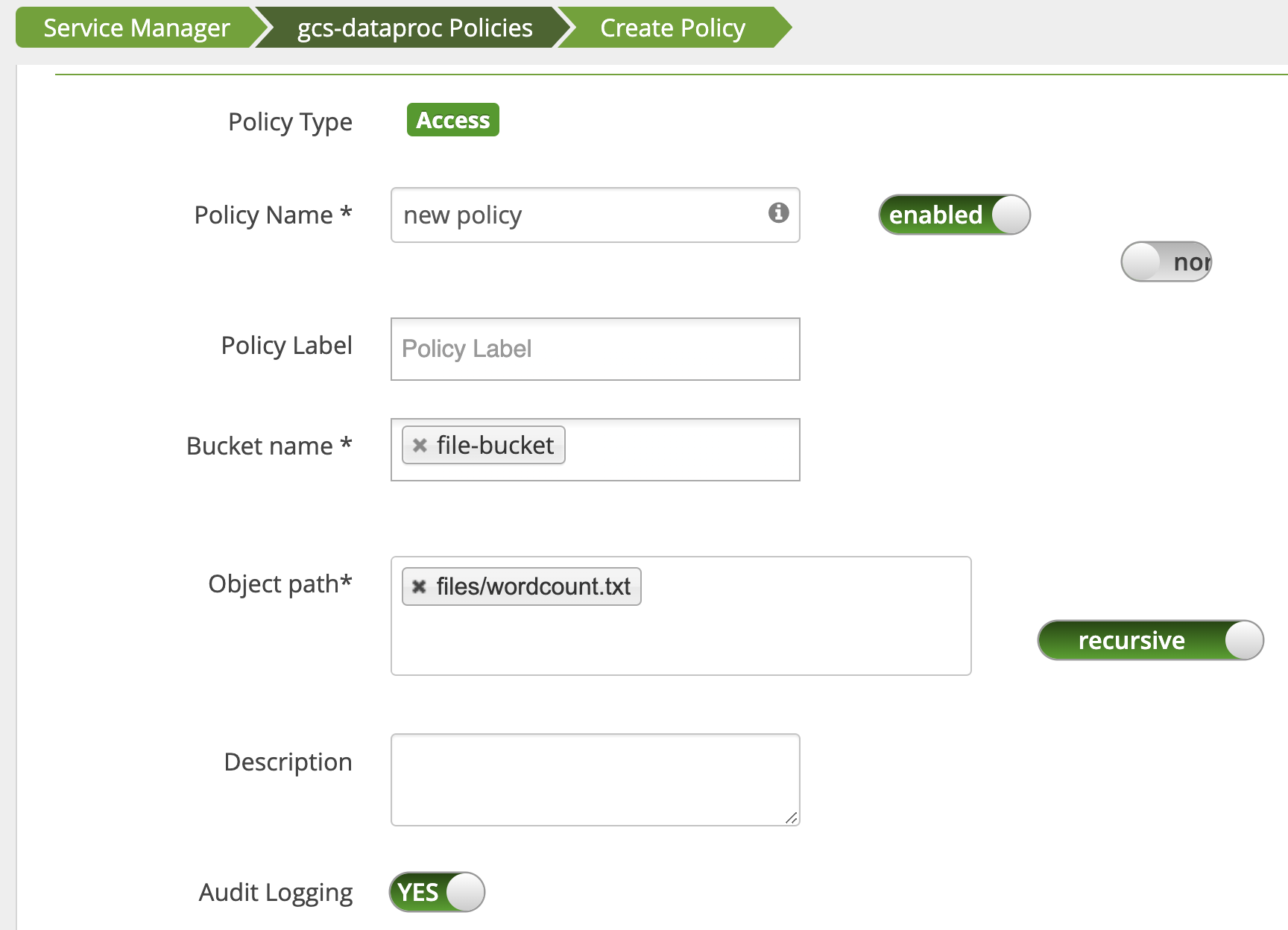
Il job viene eseguito e completato correttamente.
INFO com.google.cloud.hadoop.fs.gcs.auth.GcsDelegationTokens: Using delegation token RangerGCSAuthorizationServerSessionToken owner=<USER>, renewer=yarn, realUser=, issueDate=1654116824281, maxDate=0, sequenceNumber=0, masterKeyId=0 this: 1 is: 1 a: 1 text: 1 file: 1 22/06/01 20:54:13 INFO org.sparkproject.jetty.server.AbstractConnector: Stopped