
I cluster Managed Service for Apache Spark sono basati su istanze Compute Engine. I tipi di macchina definiscono le risorse hardware virtualizzate disponibili per un'istanza. Compute Engine offre sia tipi di macchine predefinite sia tipi di macchine personalizzate. I cluster Managed Service for Apache Spark possono utilizzare tipi predefiniti e personalizzati per i nodi master e worker.
I cluster Managed Service for Apache Spark supportano i seguenti tipi di macchine predefiniti di Compute Engine (la disponibilità dei tipo di macchina varia in base alla regione):
- Tipi di macchine per uso generico,
che includono i tipi di macchine N1, N2, N2D, E2, C3, C4, N4 e N4D (Managed Service for Apache Spark
supporta anche i tipi di macchine personalizzate N1, N2, N2D, E2, N4 e N4D).
Limitazioni:
- Il tipo di macchina n1-standard-1 non è supportato per le immagini 2.0+ (il tipo di macchina n1-standard-1 non è consigliato per le immagini precedenti alla versione 2.0. Utilizza invece un tipo di macchina con più memoria).
- I tipi di macchine con core condivisi non sono supportati, inclusi i seguenti tipi di macchine non supportati:
- E2: tipi di macchine con core condivisi e2-micro, e2-small ed e2-medium e
- N1: tipi di macchine con core condivisi f1-micro e g1-small.
- Managed Service for Apache Spark seleziona
hyperdisk-balancedcome tipo di disco di avvio se il tipo di macchina è C4, N4 o N4D.
- Tipi di macchine ottimizzate per il calcolo, che includono i tipi di macchine C2 e C2D.
- Tipi di macchine ottimizzati per la memoria, che includono i tipi di macchine M1 e M2.
- Tipi di macchine Arm, che includono i tipi di macchine C4A.
Tipi di macchine personalizzate
Managed Service for Apache Spark supporta i tipi di macchine personalizzate delle serie N1, N2, N2D, E2, N4 e N4D.
I tipi di macchine personalizzate sono ideali per i seguenti carichi di lavoro:
- Workload non adatti ai tipi di macchina predefiniti.
- Workload che richiedono più potenza di elaborazione o più memoria, ma non tutti gli upgrade forniti dal tipo di macchina di livello superiore.
Ad esempio, se hai un workload che richiede più potenza di elaborazione di quella fornita da un'istanza n1-standard-4, ma il passaggio successivo, un'istanza n1-standard-8, fornisce una capacità eccessiva. Con i tipi di macchine personalizzate, puoi creare cluster Managed Service for Apache Spark con nodi master e/o worker nella gamma media, con 6 CPU virtuali e 25 GB di memoria.
Specifica un tipo di macchina personalizzata
I tipi di macchine personalizzate utilizzano una specifica machine type speciale e sono soggetti a limitazioni. Ad esempio,
la specifica del tipo di macchina personalizzata per una VM personalizzata con 6 CPU virtuali e
22,5 GB di memoria è custom-6-23040.
I numeri nella specifica del tipo di macchina corrispondono al numero di CPU virtuali
(vCPU) nella macchina (6) e alla quantità di memoria (23040).
La quantità di memoria viene calcolata moltiplicando la quantità di memoria in
gigabyte per 1024 (vedi
Esprimere la memoria in GB o MB). In questo esempio, 22,5 (GB) viene moltiplicato per 1024: 22.5 * 1024 = 23040.
Specifichi il tipo di macchina personalizzata quando crei un cluster. Puoi impostare il tipo di macchina per i nodi master o worker o entrambi quando crei un cluster. Se imposti entrambi, il nodo master può utilizzare un tipo di macchina personalizzata diverso da quello utilizzato dai worker. Il tipo di macchina utilizzato dai worker secondari segue le impostazioni dei worker principali e non può essere impostato separatamente (vedi Worker secondari: VM prerilasciabili e non prerilasciabili).
Prezzi dei tipi di macchine personalizzate
I tipo di macchina personalizzate si basano sulle risorse utilizzate in una macchina personalizzata. I prezzi di Managed Service for Apache Spark vengono aggiunti al costo delle risorse di calcolo e si basano sul numero totale di CPU virtuali (vCPU) utilizzate in un cluster.
Crea un cluster Managed Service for Apache Spark con un tipo di macchina specificato
Console
Nel riquadro Configura nodi della pagina Crea un cluster di Managed Service for Apache Spark nella console Google Cloud , seleziona la famiglia di macchine, la serie e il tipo per i nodi master e worker del cluster.
Comando g-cloud
Esegui il comando
gcloud dataproc clusters create
con i seguenti flag per creare un cluster Managed Service for Apache Spark con tipi di macchine master
e/o worker:
- Il flag
--master-machine-type machine-typeti consente di impostare il tipo di macchina predefinita o personalizzata utilizzata dall'istanza VM master nel cluster (o dalle istanze master se crei un cluster HA). - Il flag
--worker-machine-type custom-machine-typeti consente di impostare il tipo di macchina predefinita o personalizzata utilizzato dalle istanze VM worker nel cluster
Esempio:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / other args
... properties: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
API
Per creare un cluster con tipi di macchine personalizzate, imposta machineTypeUri in masterConfig e/o workerConfig
InstanceGroupConfig
nella
richiesta API
cluster.create.
Esempio:
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "test-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
}
}
}
Crea un cluster Managed Service for Apache Spark con tipo di macchina personalizzata con memoria estesa
Managed Service for Apache Spark supporta tipi di macchine personalizzate con memoria estesa oltre il limite di 6,5 GB per vCPU (vedi Prezzi della memoria estesa).
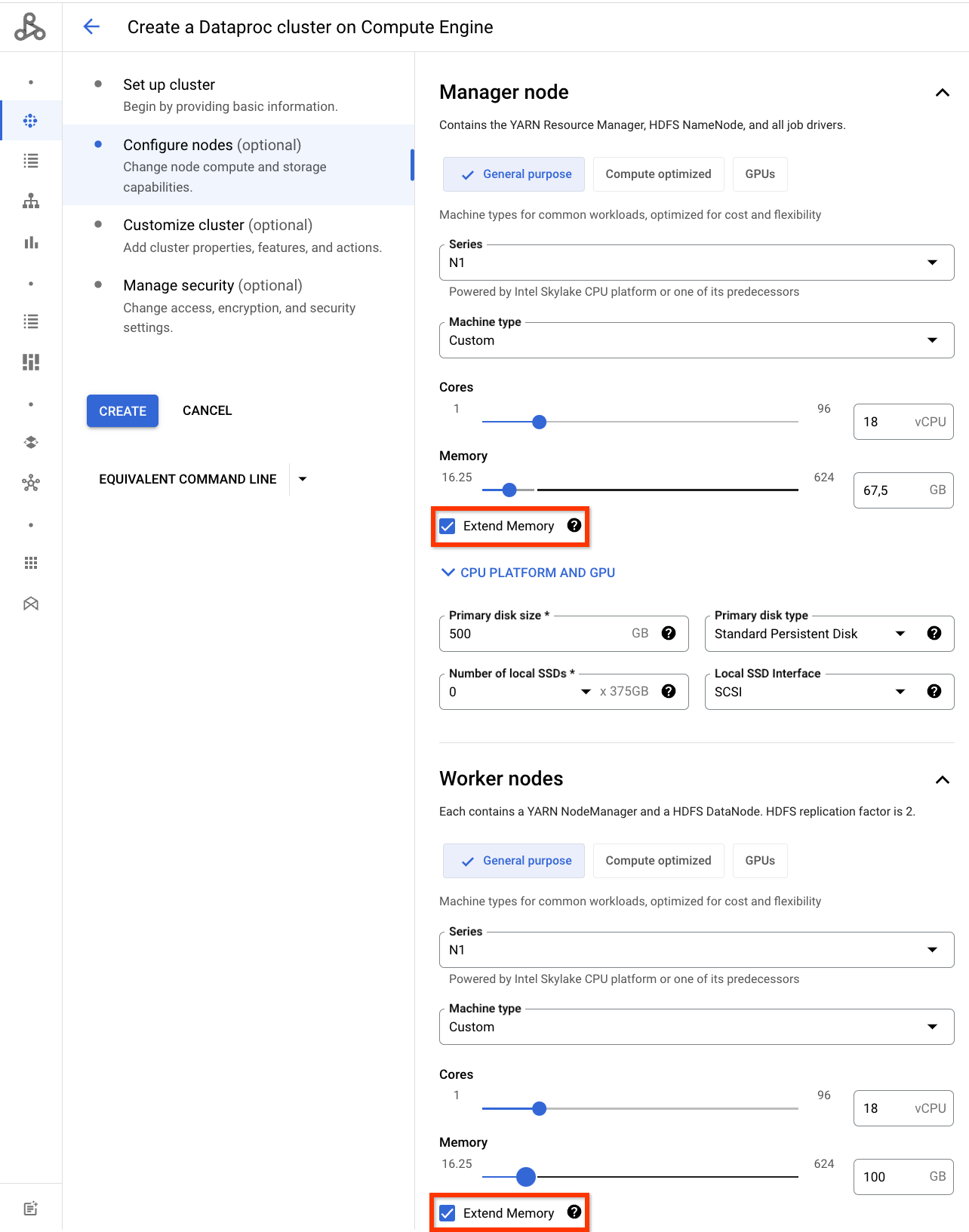
Console
Fai clic su Estendi memoria quando personalizzi la memoria del tipo di macchina nella sezione Nodo master e/o Nodi worker del riquadro Configura nodi nella pagina Crea un cluster di Managed Service for Apache Spark nella Google Cloud console.
Comando gcloud
Per creare un cluster dalla riga di comando gcloud con
CPU personalizzate con memoria estesa, aggiungi un suffisso -ext ai flag
‑‑master-machine-type e/o
‑‑worker-machine-type.
Esempio
Il seguente esempio di riga di comando gcloud crea un cluster Managed Service for Apache Spark con 1 CPU e 50 GB di memoria (50 * 1024 = 51200) in ogni nodo:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / other args
API
Il seguente snippet JSON di esempio <code.instancegroupconfig< code="" dir="ltr" translate="no"></code.instancegroupconfig<> di una richiesta dell'API REST Managed Service for Apache Spark clusters.create specifica 1 CPU e 50 GB di memoria (50 * 1024 = 51200) in ogni nodo:
...
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
Tipi di macchine per le braccia
Managed Service for Apache Spark supporta la creazione di un cluster con nodi che utilizzano tipi di macchine Arm, come il tipo di macchina C4A.
Requisiti e limitazioni:
- L'immagine di Managed Service for Apache Spark deve essere compatibile con il chipset Arm.
Le immagini di Managed Service for Apache Spark
2.1-ubuntu20-arm,2.2-ubuntu22-arm, e2.3-ubuntu22-arm(e il suffisso-armsuccessivo) sono compatibili con il chipset Arm. Le immagini compatibili con Arm non supportano molti componenti facoltativi e di azioni di inizializzazione, come indicato nelle pagine delle versioni di rilascio delle immagini. - Poiché per un cluster deve essere specificata un'immagine, i nodi master, worker e secondari devono utilizzare un tipo di macchina Arm compatibile con l'immagine Arm di Managed Service for Apache Spark selezionata.
- Le funzionalità di Managed Service for Apache Spark che non sono compatibili con i tipi di macchine Arm non sono disponibili (ad esempio, le SSD locali non sono supportate dai tipi di macchine C4A).
- Le immagini ARM supportano solo i componenti preinstallati e un set limitato di componenti opzionali. Gli altri componenti facoltativi e tutte le azioni di inizializzazione non sono supportati.
Crea un cluster Managed Service for Apache Spark con un tipo di macchina Arm
Console
Per creare un cluster Managed Service for Apache Spark che utilizza un tipo di macchina Arm, segui questi passaggi:
Nella console Google Cloud , vai alla pagina Managed Service for Apache Spark Crea un cluster Dataproc su Compute Engine.
Nella sezione Controllo delle versioni, fai clic su Modifica per selezionare un'immagine del chipset Arm.
Seleziona il riquadro Configura nodi.
Seleziona la serie Arm (ad esempio
C4A) e il tipo di macchina Arm per ogni nodo del cluster.Conferma o specifica altri dettagli del cluster, poi fai clic su Crea.
gcloud
Per creare un cluster Managed Service for Apache Spark che utilizza un tipo di macchina Arm, esegui il seguente comando gcloud localmente in una finestra del terminale o in Cloud Shell. Questo esempio specifica l'immagine
2.1-ubuntu20-arm e il tipo di macchina Arm c4a-standard-4.
gcloud dataproc clusters create cluster-name \ --region=REGION \ --image-version=2.1-ubuntu20-arm \ --master-machine-type=c4a-standard-4 \ --worker-machine-type=c4a-standard-4
Note:
REGION: la regione in cui si troverà il cluster.
Consulta la documentazione di riferimento di gcloud dataproc clusters create per informazioni su altri flag della riga di comando che puoi utilizzare per personalizzare il cluster.
API
La seguente richiesta di esempio dell'API REST Managed Service for Apache Spark
clusters.create
crea un cluster che utilizza il tipo di macchina Arm c4a-standard-4.
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "sample-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"softwareConfig": {
"imageVersion": "2.1-ubuntu20-arm"
}
}
}
Passaggi successivi
- Scopri di più sulle VM Arm su Compute.
- Scopri come creare una VM con un tipo di macchina personalizzata.
- Scopri come creare e avviare un'istanza Compute Engine.