
אשכולות Dataproc מבוססים על מכונות ב-Compute Engine. סוגי מכונות מגדירים את משאבי החומרה הווירטואליים שזמינים למופע. ב-Compute Engine יש סוגי מכונות מוגדרים מראש וסוגי מכונות בהתאמה אישית. באשכולות Dataproc אפשר להשתמש בסוגים שהוגדרו מראש ובסוגים מותאמים אישית גם עבור צמתי מאסטר וגם עבור צמתי עובד.
אשכולות Dataproc תומכים בסוגי המכונות הבאים עם קונפיגורציה מוגדרת (predefined) של Compute Engine (הזמינות של סוגי המכונות משתנה בהתאם לאזור):
- סוגי מכונות לשימוש כללי, שכוללים את סוגי המכונות N1, N2, N2D, E2, C3, C4, N4 ו-N4D (ב-Dataproc יש גם תמיכה בסוגי מכונות בהתאמה אישית N1, N2, N2D, E2, N4 ו-N4D).
מגבלות:
- סוג המכונה n1-standard-1 לא נתמך בתמונות מגרסה 2.0 ומעלה (סוג המכונה n1-standard-1 לא מומלץ לתמונות מגרסה 2.0 ומטה – במקום זאת, צריך להשתמש בסוג מכונה עם זיכרון גבוה יותר).
- אין תמיכה בסוגי מכונות עם ליבות משותפות, כולל סוגי המכונות הבאים שלא נתמכים:
- E2: סוגי מכונות עם ליבות משותפות e2-micro, e2-small ו-e2-medium, וגם
- N1: סוגי מכונות עם ליבות משותפות f1-micro ו-g1-small.
- Dataproc בוחר באפשרות
hyperdisk-balancedכסוג של דיסק האתחול אם סוג המכונה הוא C4, N4 או N4D.
- מכונות וירטואליות מותאמות לצריכת מעבד גבוהה (compute-optimized), כולל מכונות וירטואליות מסוג C2 ו-C2D.
- סוגי מכונות וירטואליות שעברו אופטימיזציה לזיכרון, כולל סוגי מכונות וירטואליות M1 ו-M2.
- סוגי מכונות Arm, כולל סוגי מכונות C4A.
סוגי מכונות בהתאמה אישית
Dataproc תומך בסדרות N1, N2, N2D, E2, N4 ו-N4D של מכונות מותאמות אישית.
סוגי מכונות בהתאמה אישית מתאימים במיוחד לעומסי העבודה הבאים:
- עומסי עבודה שלא מתאימים לסוגי מכונות עם קונפיגורציה מוגדרת (predefined).
- עומסי עבודה שדורשים יותר כוח עיבוד או יותר זיכרון, אבל לא צריכים את כל השדרוגים שזמינים ברמה הבאה של סוג המכונה.
לדוגמה, אם יש לכם עומס עבודה שדורש יותר כוח עיבוד ממה שמספקת מכונת n1-standard-4, אבל המכונה הבאה ברמה גבוהה יותר, מכונת n1-standard-8, מספקת יותר מדי קיבולת. בעזרת מכונות מותאמות אישית, אתם יכולים ליצור אשכולות Dataproc עם צמתי מאסטר ו/או צמתי עובד בטווח הביניים, עם 6 מעבדים וירטואליים ו-25GB של זיכרון.
ציון סוג מכונה בהתאמה אישית
סוגי מכונות בהתאמה אישית משתמשים במפרט מיוחד machine type וכפופים להגבלות. לדוגמה, המפרט של סוג מכונה בהתאמה אישית למכונה וירטואלית בהתאמה אישית עם 6 מעבדים וירטואליים ו-22.5GB של זיכרון הוא custom-6-23040.
המספרים במפרט סוג המכונה תואמים למספר יחידות ה-vCPU במכונה (6) ולנפח הזיכרון (23040). נפח הזיכרון מחושב על ידי הכפלת נפח הזיכרון בגיגה-בייט ב-1024 (ראו הצגת נפח הזיכרון ב-GB או ב-MB). בדוגמה הזו, מכפילים את 22.5 (GB) ב-1024: 22.5 * 1024 = 23040.
מציינים את סוג המכונה בהתאמה אישית כשיוצרים אשכול. כשיוצרים אשכול, אפשר להגדיר את סוג המכונה לצומתי הניהול או לצומתי העובדים, או לשניהם. אם מגדירים את שניהם, צומת הראשי יכול להשתמש בסוג מכונה בהתאמה אישית ששונה מסוג המכונה בהתאמה אישית שמשמשת את העובדים. סוג המכונה שבו משתמשים בכל העובדים המשניים נקבע לפי ההגדרות של העובדים הראשיים, ואי אפשר להגדיר אותו בנפרד (ראו עובדים משניים – מכונות וירטואליות שניתן להפסיק ומכונות וירטואליות שלא ניתן להפסיק).
תמחור של סוגי מכונות בהתאמה אישית
התמחור של סוגי מכונות בהתאמה אישית מבוסס על המשאבים שנעשה בהם שימוש במכונה מותאמת אישית. התמחור של Dataproc מתווסף לעלות של משאבי מחשוב, והוא מבוסס על המספר הכולל של מעבדים וירטואליים (vCPU) שנעשה בהם שימוש באשכול.
יצירת אשכול Dataproc עם סוג מכונה מוגדר
המסוף
בחלונית Configure nodes (הגדרת הצמתים) בדף Create a cluster (יצירת אשכול) של Dataproc במסוף Google Cloud , בוחרים את סדרת המכונות, משפחת המכונות וסוג המכונות לצמתים הראשיים ולצמתים של העובדים באשכול.
פקודת gcloud
מריצים את הפקודה gcloud dataproc clusters create עם הדגלים הבאים כדי ליצור אשכול Dataproc עם סוגי מכונות ראשיות ו/או עובדות:
- הדגל
--master-machine-type machine-typeמאפשר להגדיר את סוג המכונה המוגדר מראש או סוג המכונה בהתאמה אישית שבו נעשה שימוש במופע הראשי של המכונה הווירטואלית באשכול (או במופעים ראשיים אם יוצרים אשכול זמינות גבוהה) - הדגל
--worker-machine-type custom-machine-typeמאפשר להגדיר את סוג המכונה המוגדר מראש או סוג מכונה בהתאמה אישית שבו משתמשות המכונות הווירטואליות של העובדים באשכול.
דוגמה:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-6-23040 / --worker-machine-type custom-6-23040 / other args
... properties: distcp:mapreduce.map.java.opts: -Xmx1638m distcp:mapreduce.map.memory.mb: '2048' distcp:mapreduce.reduce.java.opts: -Xmx4915m distcp:mapreduce.reduce.memory.mb: '6144' mapred:mapreduce.map.cpu.vcores: '1' mapred:mapreduce.map.java.opts: -Xmx1638m ...
API
כדי ליצור אשכול עם סוגי מכונות בהתאמה אישית, מגדירים את machineTypeUri ב-masterConfig או ב-workerConfig
InstanceGroupConfig בבקשת ה-API cluster.create.
דוגמה:
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "test-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "n1-highmem-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
}
}
}
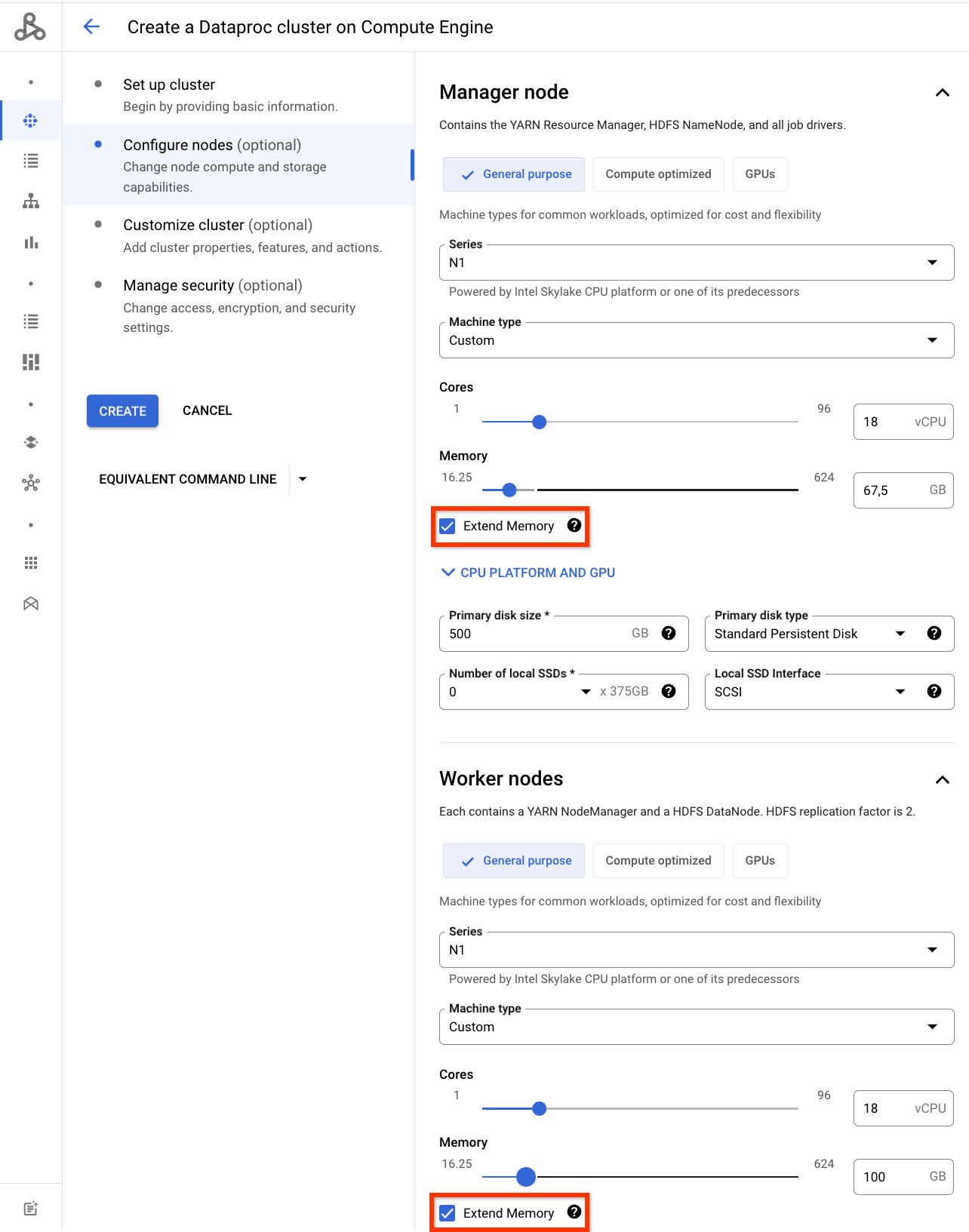
יצירת אשכול Dataproc עם סוג מכונה בהתאמה אישית עם זיכרון מורחב
Dataproc תומך בסוגי מכונות בהתאמה אישית עם זיכרון מורחב מעבר למגבלה של 6.5GB לכל vCPU (ראו תמחור של זיכרון מורחב).
המסוף
לוחצים על Extend memory (הגדלת הזיכרון) כשמבצעים התאמה אישית של הזיכרון של סוג המכונה בקטע Master node (צומת ראשי) או Worker nodes (צומתי עבודה) בחלונית Configure nodes (הגדרת צמתים) בדף Create a cluster (יצירת אשכול) ב-Dataproc ב- Google Cloud console.
פקודת gcloud
כדי ליצור אשכול משורת הפקודה של gcloud עם מעבדים מותאמים אישית עם זיכרון מורחב, מוסיפים את הסיומת -ext לדגלים ‑‑master-machine-type או ‑‑worker-machine-type.
דוגמה
הדוגמה הבאה לשורת פקודה ב-gcloud יוצרת אשכול Dataproc עם מעבד אחד וזיכרון של 50GB (50 * 1,024 = 51,200) בכל צומת:
gcloud dataproc clusters create test-cluster / --master-machine-type custom-1-51200-ext / --worker-machine-type custom-1-51200-ext / other args
API
בקטע ה-JSON הבא לדוגמה מתוך בקשת clusters.create של Dataproc API בארכיטקטורת REST <code.instancegroupconfig< code="" dir="ltr" translate="no"></code.instancegroupconfig<> מוגדרים מעבד אחד וזיכרון בנפח 50GB (50 * 1024 = 51200) בכל צומת:
...
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "custom-1-51200-ext",
...
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "custom-1-51200-ext",
...
...
סוגי מכונות Arm
Dataproc תומך ביצירת אשכול עם צמתים שמשתמשים בסוגי מכונות של Arm, כמו סוג המכונה C4A.
דרישות ומגבלות:
- תמונת Dataproc צריכה להיות תואמת לערכת שבבים של Arm.
תמונות Dataproc
2.1-ubuntu20-arm,2.2-ubuntu22-arm, ו-2.3-ubuntu22-arm(ומאוחרות יותר עם הסיומת-arm) תואמות לערכת השבבים של Arm. תמונות שמתאימות ל-Arm לא תומכות בהרבה רכיבים אופציונליים ורכיבי פעולות אתחול, כמו שצוין בדפי גרסאות ההפצה של התמונות. - מכיוון שצריך לציין תמונה אחת לאשכול, הצמתים הראשיים, הצמתים של העובדים והצמתים של העובדים המשניים צריכים להשתמש בסוג מכונת Arm שתואם לתמונת ה-Arm של Dataproc שנבחרה.
- תכונות של Dataproc שלא תואמות לסוגי מכונות של Arm לא זמינות (לדוגמה, כונני SSD מקומיים לא נתמכים בסוגי מכונות C4A).
- תמונות Arm תומכות רק ברכיבים שמותקנים מראש ובקבוצה מוגבלת של רכיבים אופציונליים. אין תמיכה ברכיבים אופציונליים אחרים ובכל פעולות האתחול.
יצירת אשכול Dataproc עם סוג מכונה של Arm
המסוף
כדי ליצור אשכול Dataproc שמשתמש בסוג מכונה של Arm:
במסוף Google Cloud , נכנסים לדף Create a Dataproc cluster on Compute Engine (יצירת אשכול Dataproc ב-Compute Engine).
בקטע Versioning, לוחצים על Change כדי לבחור תמונה של ערכת שבבים מסוג Arm.
בוחרים בחלונית Configure nodes.
בוחרים את סדרת ה-Arm (למשל
C4A) ואת סוג מכונת ה-Arm לכל צומת באשכול.מאשרים או מציינים פרטים אחרים של האשכול, ואז לוחצים על יצירה.
gcloud
כדי ליצור אשכול Dataproc שמשתמש בסוג מכונה של Arm, מריצים את הפקודה gcloud באופן מקומי בחלון טרמינל או ב-Cloud Shell. בדוגמה הזו מצוין סוג המכונה c4a-standard-4 Arm והתמונה 2.1-ubuntu20-arm.
gcloud dataproc clusters create cluster-name \ --region=REGION \ --image-version=2.1-ubuntu20-arm \ --master-machine-type=c4a-standard-4 \ --worker-machine-type=c4a-standard-4
הערות:
REGION: האזור שבו האשכול ימוקם.
במסמכי העזר בנושא gcloud dataproc clusters create אפשר למצוא מידע על דגלים נוספים של שורת הפקודה שאפשר להשתמש בהם כדי להתאים אישית את האשכול.
API
בדוגמה הבאה של בקשת clusters.create של Dataproc API בארכיטקטורת REST נוצר אשכול שמשתמש בסוג המכונה c4a-standard-4 Arm.
POST /v1/projects/my-project-id/regions/is-central1/clusters/
{
"projectId": "my-project-id",
"clusterName": "sample-cluster",
"config": {
"configBucket": "",
"gceClusterConfig": {
"subnetworkUri": "default",
"zoneUri": "us-central1-a"
},
"masterConfig": {
"numInstances": 1,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
}
},
"workerConfig": {
"numInstances": 2,
"machineTypeUri": "c4a-standard-4",
"diskConfig": {
"bootDiskSizeGb": 500,
"numLocalSsds": 0
}
},
"softwareConfig": {
"imageVersion": "2.1-ubuntu20-arm"
}
}
}
המאמרים הבאים
- מידע נוסף על מכונות וירטואליות של Arm ב-Compute
- איך יוצרים מכונה וירטואלית עם סוג מכונה בהתאמה אישית
- איך יוצרים מכונה של Compute Engine ומפעילים אותה