
Puoi attivare componenti aggiuntivi come Flink quando crei un cluster Managed Service for Apache Spark utilizzando la funzionalità Componenti facoltativi. Questa pagina mostra come creare un cluster Managed Service for Apache Spark con il componente facoltativo Apache Flink attivato (un cluster Flink), quindi eseguire i job Flink sul cluster.
Puoi utilizzare il tuo cluster Flink per:
Esegui job Flink utilizzando la risorsa
Jobsdalla console Google Cloud , da Google Cloud CLI o dall'API Dataproc.Esegui job Flink utilizzando la CLI
flinkin esecuzione sul nodo master del cluster Flink.
Crea un cluster Flink
Puoi utilizzare la console Google Cloud , Google Cloud CLI o l'API Dataproc per creare un cluster con il componente Flink attivato.
Consiglio:utilizza un cluster di VM standard con un master con il componente Flink. I cluster in modalità ad alta disponibilità di Managed Service for Apache Spark (con 3 VM master) non supportano la modalità ad alta disponibilità di Flink.
Console
Per creare un cluster Managed Service for Apache Spark Flink utilizzando la console Google Cloud , segui questi passaggi:
- Apri la pagina Crea cluster.
- Nella sezione Definisci il cluster, conferma o modifica la versione dell'immagine:
- La versione dell'immagine deve essere
1.5o successiva per attivare il componente Flink sul cluster. Consulta Versioni di Managed Service for Apache Spark supportate per visualizzare gli elenchi delle versioni dei componenti incluse in ogni release dell'immagine. - Consulta Esegui job Managed Service for Apache Spark Flink per i requisiti della versione dell'immagine per eseguire i job Flink utilizzando la risorsa Jobs.
- La versione dell'immagine deve essere
- Fai clic su Configurazione aggiuntiva per espandere la sezione.
- Modifica Componenti facoltativi.
- Nel riquadro che si apre, seleziona la casella di controllo Flink, quindi fai clic su Salva.
- Modifica Personalizzazione e altro.
- Nel riquadro che si apre:
- Nella sezione Proprietà del cluster, fai clic su + Aggiungi proprietà
per configurare le proprietà di Flink (prefisso:
flink, chiave: FLINK_KEY, valore: VALUE) in/etc/flink/conf/flink-conf.yamlche fungeranno da valori predefiniti per le applicazioni Flink che esegui sul cluster.Esempi:
- Imposta
flink:historyserver.archive.fs.dirper specificare la posizione Cloud Storage in cui scrivere i file della cronologia dei job Flink (questa posizione verrà utilizzata dal server di cronologia Flink in esecuzione sul cluster Flink). - Imposta gli slot di attività Flink con
flink:taskmanager.numberOfTaskSlots=n.
- Imposta
- Nella sezione Metadati personalizzati del cluster, fai clic su
+ Aggiungi proprietà e imposta la chiave su
flink-start-yarn-sessione il valore sutrueper eseguire il daemon Flink YARN,/usr/bin/flink-yarn-daemon, in background sul nodo del driver del cluster per avviare una sessione Flink YARN (vedi Esegui job Flink utilizzando la CLI Flink - Modalità sessione).
- Nella sezione Proprietà del cluster, fai clic su + Aggiungi proprietà
per configurare le proprietà di Flink (prefisso:
- Fai clic su Salva.
- Se utilizzi la versione dell'immagine Managed Service for Apache Spark
2.0o precedente, fai clic su Sicurezza. - Nel riquadro che si apre, in Accesso al progetto, seleziona
la casella di controllo Attiva l'ambito cloud-platform per questo cluster,
poi fai clic su Salva
(l'ambito
cloud-platformè attivato per impostazione predefinita quando crei un cluster che utilizza la versione dell'immagine Managed Service for Apache Spark2.1o successive). - Fai clic su Crea cluster per creare il cluster.
gcloud
Per creare un cluster Managed Service for Apache Spark Flink utilizzando gcloud CLI, esegui questo comando gcloud dataproc clusters create localmente in una finestra del terminale o in Cloud Shell:
gcloud dataproc clusters create CLUSTER_NAME \ --region=REGION \ --image-version=DATAPROC_IMAGE_VERSION \ --optional-components=FLINK \ --enable-component-gateway \ --properties=PROPERTIES ... other flags
Note:
- CLUSTER_NAME: specifica il nome del cluster.
- REGION: specifica una regione Compute Engine in cui si troverà il cluster.
DATAPROC_IMAGE_VERSION: specifica facoltativamente la versione dell'immagine da utilizzare nel cluster. La versione dell'immagine del cluster determina la versione del componente Flink installato sul cluster.
- La versione dell'immagine deve essere
1.5o successiva per attivare il componente Flink sul cluster. Consulta Versioni delle immagini di Managed Service for Apache Spark supportate per visualizzare gli elenchi delle versioni dei componenti incluse in ogni release dell'immagine. - Consulta Esegui job Flink di Managed Service for Apache Spark per i requisiti della versione dell'immagine per eseguire job Flink tramite l'API Dataproc Jobs.
- La versione dell'immagine deve essere
--optional-components: devi specificare il componenteFLINKper eseguire i job Flink e il servizio web Flink HistoryServer sul cluster.--enable-component-gateway: devi attivare il gateway dei componenti per attivare il link del gateway dei componenti all'interfaccia utente di Flink History Server. L'attivazione del gateway dei componenti consente anche l'accesso all'interfaccia web di Flink Job Manager in esecuzione sul cluster Flink.PROPERTIES. (Facoltativo) Specifica una o più proprietà del cluster.
Quando crei cluster Managed Service for Apache Spark con versioni immagine
2.0.67+ e2.1.15+, puoi utilizzare il flag--propertiesper configurare le proprietà Flink in/etc/flink/conf/flink-conf.yamlche fungeranno da valori predefiniti per le applicazioni Flink che esegui sul cluster.Puoi impostare
flink:historyserver.archive.fs.dirper specificare la posizione Cloud Storage in cui scrivere i file della cronologia dei job Flink (questa posizione verrà utilizzata da Flink History Server in esecuzione sul cluster Flink).Esempio di più proprietà:
--properties=flink:historyserver.archive.fs.dir=gs://my-bucket/my-flink-cluster/completed-jobs,flink:taskmanager.numberOfTaskSlots=2Altri flag:
- Puoi aggiungere il flag facoltativo
--metadata flink-start-yarn-session=trueper eseguire il daemon Flink YARN,/usr/bin/flink-yarn-daemon, in background sul nodo master del cluster per avviare una sessione Flink YARN (vedi Eseguire job Flink utilizzando la CLI di Flink - Modalità sessione).
- Puoi aggiungere il flag facoltativo
Quando utilizzi versioni di immagini 2.0 o precedenti, aggiungi il flag
--scopes=https://www.googleapis.com/auth/cloud-platformper abilitare l'accesso alle API Google Cloud da parte del cluster (vedi Best practice per gli ambiti). L'ambitocloud-platformè abilitato per impostazione predefinita quando crei un cluster che utilizza la versione immagine 2.1 o successive di Managed Service for Apache Spark.
API
Per creare un cluster Managed Service for Apache Spark Flink utilizzando l'API Dataproc, invia una richiesta clusters.create, come segue:
Note:
Imposta SoftwareConfig.Component su
FLINK.Puoi impostare facoltativamente
SoftwareConfig.imageVersionper specificare la versione dell'immagine da utilizzare sul cluster. La versione dell'immagine del cluster determina la versione del componente Flink installato sul cluster.La versione dell'immagine deve essere
1.5o successive per attivare il componente Flink sul cluster (consulta Versioni di Managed Service for Apache Spark supportate per visualizzare gli elenchi delle versioni dei componenti incluse in ogni release dell'immagine Managed Service for Apache Spark).Consulta Esegui job Flink di Managed Service for Apache Spark per i requisiti della versione dell'immagine per eseguire job Flink tramite l'API Dataproc Jobs.
Imposta EndpointConfig.enableHttpPortAccess su
trueper abilitare il link Component Gateway all'interfaccia utente di Flink History Server. L'attivazione del gateway dei componenti consente anche l'accesso all'interfaccia web di Flink Job Manager in esecuzione sul cluster Flink.Puoi impostare facoltativamente
SoftwareConfig.propertiesper specificare una o più proprietà del cluster.- Puoi specificare le proprietà di Flink che fungeranno da
valori predefiniti per le applicazioni Flink che esegui sul cluster. Ad esempio,
puoi impostare
flink:historyserver.archive.fs.dirper specificare la posizione Cloud Storage in cui scrivere i file della cronologia dei job Flink (questa posizione verrà utilizzata dal server di cronologia Flink in esecuzione sul cluster Flink).
- Puoi specificare le proprietà di Flink che fungeranno da
valori predefiniti per le applicazioni Flink che esegui sul cluster. Ad esempio,
puoi impostare
In via facoltativa, puoi impostare:
GceClusterConfig.metadata. Ad esempio, per specificareflink-start-yarn-sessiontrueper eseguire il daemon Flink YARN,/usr/bin/flink-yarn-daemon, in background sul nodo master del cluster per avviare una sessione Flink YARN (vedi Modalità sessione Flink).- GceClusterConfig.serviceAccountScopes
a
https://www.googleapis.com/auth/cloud-platform(ambitocloud-platform) quando utilizzi versioni dell'immagine 2.0 o precedenti per consentire l'accesso alle API Google Cloud da parte del cluster (vedi Best practice per gli ambiti). L'ambitocloud-platformè abilitato per impostazione predefinita quando crei un cluster che utilizza la versione immagine 2.1 o successive di Managed Service for Apache Spark.
Dopo aver creato un cluster Flink
- Utilizza il link
Flink History Serverin Component Gateway per visualizzare Flink History Server in esecuzione sul cluster Flink. - Utilizza
YARN ResourceManager linkin Component Gateway per visualizzare l'interfaccia web di Flink Job Manager in esecuzione sul cluster Flink . - Crea un server di cronologia permanente Managed Service for Apache Spark per visualizzare i file della cronologia dei job Flink scritti dai cluster Flink esistenti ed eliminati.
Esegui job Flink utilizzando la risorsa Jobs
Puoi eseguire job Flink utilizzando la risorsa Managed Service for Apache Spark Jobs dalla
consoleGoogle Cloud , da Google Cloud CLI o dall'API Dataproc.
Console
Per inviare un job di conteggio delle parole Flink di esempio dalla console:
Apri la pagina Invia un job di Managed Service for Apache Spark nella consoleGoogle Cloud nel browser.
Compila i campi nella pagina Invia un job:
- Seleziona il nome del cluster dall'elenco dei cluster.
- Imposta Tipo di prestazione su
Flink. - Imposta Classe principale o jar su
org.apache.flink.examples.java.wordcount.WordCount. - Imposta File jar su
file:///usr/lib/flink/examples/batch/WordCount.jar.file:///indica un file che si trova sul cluster. Managed Service for Apache Spark ha installatoWordCount.jardurante la creazione del cluster Flink.- Questo campo accetta anche un percorso Cloud Storage
(
gs://BUCKET/JARFILE) o un percorso Hadoop Distributed File System (HDFS) (hdfs://PATH_TO_JAR).
Fai clic su Invia.
- L'output del driver del job viene visualizzato nella pagina Dettagli job.
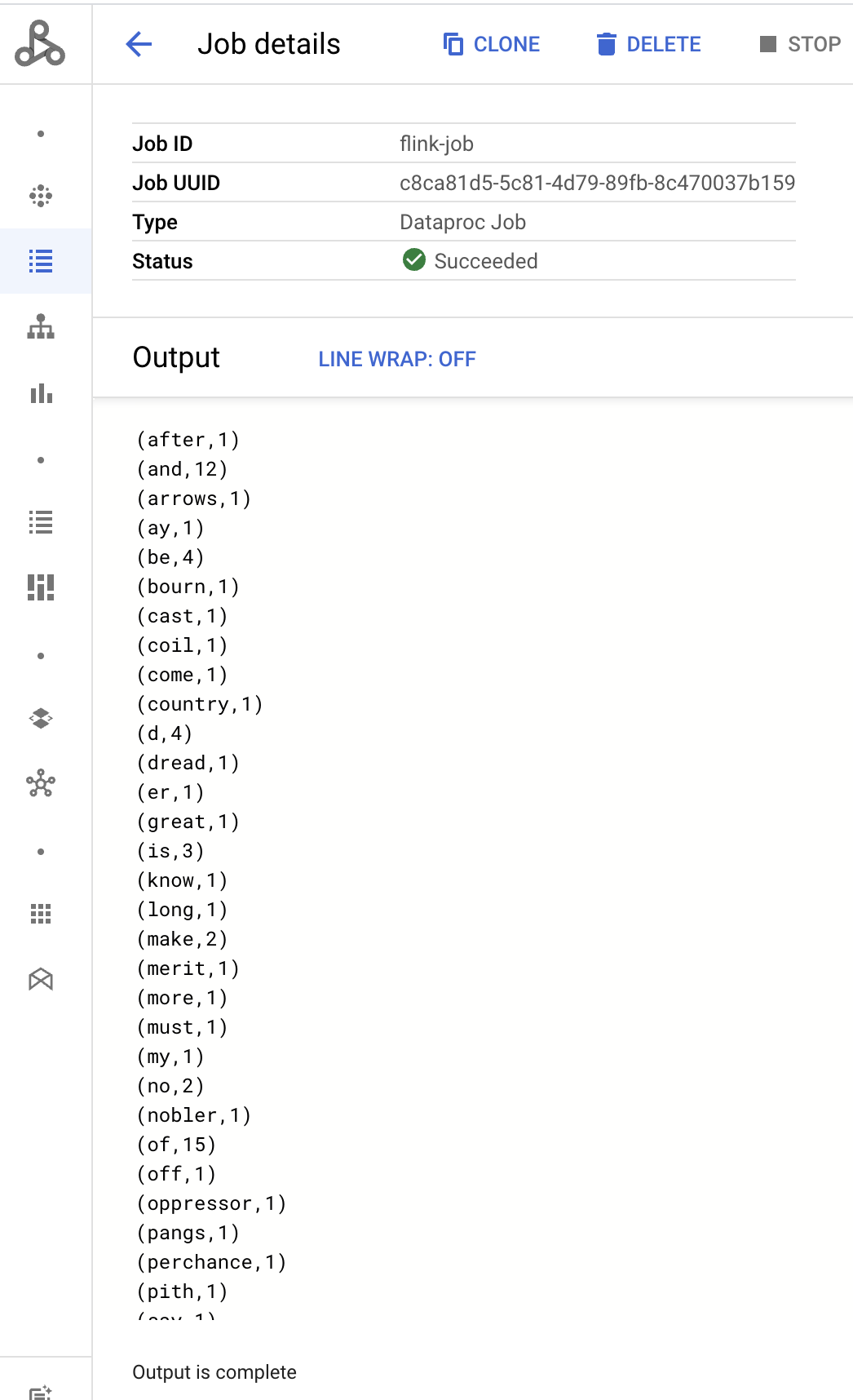
- I job Flink sono elencati nella pagina Job di Managed Service for Apache Spark nella console Google Cloud .
- Fai clic su Interrompi o Elimina dalla pagina Job o Dettagli job per interrompere o eliminare un job.
gcloud
Per inviare un job Flink a un cluster Managed Service for Apache Spark Flink, esegui il comando gcloud CLI gcloud dataproc jobs submit localmente in una finestra del terminale o in Cloud Shell.
gcloud dataproc jobs submit flink \ --cluster=CLUSTER_NAME \ --region=REGION \ --class=MAIN_CLASS \ --jar=JAR_FILE \ -- JOB_ARGS
Note:
- CLUSTER_NAME: specifica il nome del cluster Managed Service for Apache Spark Flink a cui inviare il job.
- REGION: specifica una regione di Compute Engine in cui si trova il cluster.
- MAIN_CLASS: specifica la classe
maindella tua applicazione Flink, ad esempio:org.apache.flink.examples.java.wordcount.WordCount
- JAR_FILE: specifica il file JAR dell'applicazione Flink. Puoi specificare:
- Un file jar installato sul cluster, utilizzando il prefisso
file:///` :file:///usr/lib/flink/examples/streaming/TopSpeedWindowing.jarfile:///usr/lib/flink/examples/batch/WordCount.jar
- Un file JAR in Cloud Storage:
gs://BUCKET/JARFILE - Un file jar in HDFS:
hdfs://PATH_TO_JAR
- Un file jar installato sul cluster, utilizzando il prefisso
JOB_ARGS: (facoltativo) aggiungi gli argomenti del job dopo il doppio trattino (
--).Dopo aver inviato il job, l'output del driver del job viene visualizzato nel terminale locale o di Cloud Shell.
Program execution finished Job with JobID 829d48df4ebef2817f4000dfba126e0f has finished. Job Runtime: 13610 ms ... (after,1) (and,12) (arrows,1) (ay,1) (be,4) (bourn,1) (cast,1) (coil,1) (come,1)
REST
Questa sezione mostra come inviare un job Flink a un cluster Managed Service for Apache Spark Flink utilizzando l'API Managed Service for Apache Spark jobs.submit.
Prima di utilizzare i dati della richiesta, apporta le sostituzioni seguenti:
- PROJECT_ID: Google Cloud ID progetto
- REGION: regione del cluster
- CLUSTER_NAME: specifica il nome del cluster Managed Service for Apache Spark Flink a cui inviare il job
Metodo HTTP e URL:
POST https://dataproc.googleapis.com/v1/projects/PROJECT_ID/regions/REGION/jobs:submit
Corpo JSON della richiesta:
{
"job": {
"placement": {
"clusterName": "CLUSTER_NAME"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
}
}
}
Per inviare la richiesta, espandi una di queste opzioni:
Dovresti ricevere una risposta JSON simile alla seguente:
{
"reference": {
"projectId": "PROJECT_ID",
"jobId": "JOB_ID"
},
"placement": {
"clusterName": "CLUSTER_NAME",
"clusterUuid": "CLUSTER_UUID"
},
"flinkJob": {
"mainClass": "org.apache.flink.examples.java.wordcount.WordCount",
"args": [
"1000"
],
"jarFileUris": [
"file:///usr/lib/flink/examples/batch/WordCount.jar"
]
},
"status": {
"state": "PENDING",
"stateStartTime": "2020-10-07T20:16:21.759Z"
},
"jobUuid": "JOB_UUID"
}
- I job Flink sono elencati nella pagina Job di Managed Service for Apache Spark nella console Google Cloud .
- Puoi fare clic su Interrompi o Elimina dalla pagina Job o Dettagli job nella Google Cloud console per interrompere o eliminare un job.
Esegui job Flink utilizzando l'interfaccia a riga di comando flink
Anziché
eseguire job Flink utilizzando la risorsa Managed Service for Apache Spark Jobs,
puoi eseguire job Flink sul nodo driver del cluster Flink utilizzando la CLI flink.
Le seguenti sezioni descrivono diversi modi per eseguire un job CLI flink sul
cluster Managed Service for Apache Spark Flink.
Accedi tramite SSH al nodo master:utilizza l'utilità SSH per aprire una finestra del terminale sulla VM master del cluster.
Imposta il classpath:inizializza il classpath di Hadoop dalla finestra del terminale SSH sulla VM master del cluster Flink:
export HADOOP_CLASSPATH=$(hadoop classpath)Esegui job Flink:puoi eseguire job Flink in diverse modalità di deployment su YARN: modalità applicazione, per job e sessione.
Modalità applicazione:la modalità applicazione Flink è supportata da Managed Service for Apache Spark versione immagine 2.0 e successive. Questa modalità esegue il metodo
main()del job su YARN Job Manager. Il cluster si arresta al termine del job.Esempio di invio del job:
flink run-application \ -t yarn-application \ -Djobmanager.memory.process.size=1024m \ -Dtaskmanager.memory.process.size=2048m \ -Djobmanager.heap.mb=820 \ -Dtaskmanager.heap.mb=1640 \ -Dtaskmanager.numberOfTaskSlots=2 \ -Dparallelism.default=4 \ /usr/lib/flink/examples/batch/WordCount.jarElenca i job in esecuzione:
./bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YYAnnulla un job in esecuzione:
./bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>Modalità per job:questa modalità Flink esegue il metodo
main()del job sul lato client.Esempio di invio del job:
flink run \ -m yarn-cluster \ -p 4 \ -ys 2 \ -yjm 1024m \ -ytm 2048m \ /usr/lib/flink/examples/batch/WordCount.jarModalità sessione: avvia una sessione Flink YARN a lunga esecuzione, quindi invia uno o più job alla sessione.
Avvia una sessione:puoi avviare una sessione Flink in uno dei seguenti modi:
Crea un cluster Flink aggiungendo il flag
--metadata flink-start-yarn-session=trueal comandogcloud dataproc clusters create(vedi Creare un cluster Dataproc Flink). Se questo flag è abilitato, dopo la creazione del cluster, Managed Service for Apache Spark esegue/usr/bin/flink-yarn-daemonper avviare una sessione Flink sul cluster.L'ID applicazione YARN della sessione viene salvato in
/tmp/.yarn-properties-${USER}. Puoi elencare l'ID con il comandoyarn application -list.Esegui lo script Flink
yarn-session.sh, preinstallato nella VM master del cluster, con impostazioni personalizzate:Esempio con impostazioni personalizzate:
/usr/lib/flink/bin/yarn-session.sh \ -s 1 \ -jm 1024m \ -tm 2048m \ -nm flink-dataproc \ --detachedEsegui lo script wrapper
/usr/bin/flink-yarn-daemondi Flink con le impostazioni predefinite:. /usr/bin/flink-yarn-daemon
Invia un job a una sessione: esegui questo comando per inviare un job Flink alla sessione.
flink run -m <var>FLINK_MASTER_URL</var>/usr/lib/flink/examples/batch/WordCount.jar- FLINK_MASTER_URL: l'URL, inclusi host e porta, della VM master Flink in cui vengono eseguiti i job.
Rimuovi
http:// prefixdall'URL. Questo URL è elencato nell'output del comando quando avvii una sessione di Flink. Puoi eseguire questo comando per elencare questo URL nel campoTracking-URL:
yarn application -list -appId=<yarn-app-id> | sed 's#http://##' ```- FLINK_MASTER_URL: l'URL, inclusi host e porta, della VM master Flink in cui vengono eseguiti i job.
Rimuovi
Elenca i job in una sessione:per elencare i job Flink in una sessione, esegui una delle seguenti operazioni:
Esegui
flink listsenza argomenti. Il comando cerca l'ID applicazione YARN della sessione in/tmp/.yarn-properties-${USER}.Ottieni l'ID applicazione YARN della sessione da
/tmp/.yarn-properties-${USER}o dall'output diyarn application -list, quindi esegui<code>flink list -yid YARN_APPLICATION_ID.Esegui
flink list -m FLINK_MASTER_URL.
Arresta una sessione: per arrestare la sessione, ottieni l'ID applicazione YARN della sessione da
/tmp/.yarn-properties-${USER}o dall'output diyarn application -list, quindi esegui uno dei seguenti comandi:echo "stop" | /usr/lib/flink/bin/yarn-session.sh -id YARN_APPLICATION_IDyarn application -kill YARN_APPLICATION_ID
Esegui job Apache Beam su Flink
Puoi eseguire job Apache Beam su
Managed Service for Apache Spark utilizzando
FlinkRunner.
Puoi eseguire i job Beam su Flink nei seguenti modi:
- Job Java Beam
- Job Portable Beam
Job Java Beam
Pacchettizza i job Beam in un file JAR. Fornisci il file JAR in bundle con le dipendenze necessarie per eseguire il job.
L'esempio seguente esegue un job Java Beam dal nodo master del cluster Managed Service for Apache Spark.
Crea un cluster Managed Service for Apache Spark con il componente Flink abilitato.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platform--optional-components: Flink.--image-version: la versione dell'immagine del cluster, che determina la versione di Flink installata sul cluster (ad esempio, vedi le versioni dei componenti Apache Flink elencate per le ultime quattro versioni di rilascio dell'immagine 2.0.x).--region: una regione Managed Service for Apache Spark supportata.--enable-component-gateway: attiva l'accesso all'interfaccia utente di Flink Job Manager.--scopes: abilita l'accesso alle API da parte del cluster (vedi Best practice per gli ambiti). Google Cloud L'ambitocloud-platformè abilitato per impostazione predefinita (non è necessario includere questa impostazione del flag) quando crei un cluster che utilizza la versione immagine 2.1 o successive di Managed Service for Apache Spark.
Utilizza l'utilità SSH per aprire una finestra del terminale sul nodo master del cluster Flink.
Avvia una sessione Flink YARN sul nodo master del cluster Managed Service for Apache Spark.
. /usr/bin/flink-yarn-daemonPrendi nota della versione di Flink sul cluster Managed Service for Apache Spark.
flink --versionSulla tua macchina locale, genera l'esempio canonico di conteggio delle parole di Beam in Java.
Scegli una versione di Beam compatibile con la versione di Flink sul cluster Managed Service for Apache Spark. Consulta la tabella Compatibilità delle versioni di Flink che elenca la compatibilità delle versioni di Beam-Flink.
Apri il file POM generato. Controlla la versione del runner Beam Flink specificata dal tag
<flink.artifact.name>. Se la versione del runner Beam Flink nel nome dell'artefatto Flink non corrisponde alla versione di Flink sul cluster, aggiorna il numero di versione in modo che corrisponda.mvn archetype:generate \ -DarchetypeGroupId=org.apache.beam \ -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples \ -DarchetypeVersion=BEAM_VERSION \ -DgroupId=org.example \ -DartifactId=word-count-beam \ -Dversion="0.1" \ -Dpackage=org.apache.beam.examples \ -DinteractiveMode=falsePacchettizza l'esempio di conteggio delle parole.
mvn package -Pflink-runnerCarica il file JAR uber compresso,
word-count-beam-bundled-0.1.jar(~135 MB), nel nodo master del cluster Managed Service for Apache Spark. Puoi utilizzaregcloud storage cpper trasferire più rapidamente i file al cluster Managed Service for Apache Spark da Cloud Storage.Nel terminale locale, crea un bucket Cloud Storage e carica l'uber JAR.
gcloud storage buckets create BUCKET_NAMEgcloud storage cp target/word-count-beam-bundled-0.1.jar gs://BUCKET_NAME/Sul nodo master di Managed Service for Apache Spark, scarica il file JAR uber.
gcloud storage cp gs://BUCKET_NAME/word-count-beam-bundled-0.1.jar .
Esegui il job Java Beam sul nodo driver del cluster Managed Service for Apache Spark.
flink run -c org.apache.beam.examples.WordCount word-count-beam-bundled-0.1.jar \ --runner=FlinkRunner \ --output=gs://BUCKET_NAME/java-wordcount-outVerifica che i risultati siano stati scritti nel bucket Cloud Storage.
gcloud storage cat gs://BUCKET_NAME/java-wordcount-out-SHARD_IDInterrompi la sessione Flink YARN.
yarn application -listyarn application -kill YARN_APPLICATION_ID
Job Portable Beam
Per eseguire job Beam scritti in Python, Go e altri linguaggi supportati, puoi utilizzare FlinkRunner e PortableRunner come descritto nella pagina Flink Runner di Beam (vedi anche Roadmap del framework di portabilità).
L'esempio seguente esegue un job Beam portatile in Python dal nodo master del cluster Managed Service for Apache Spark.
Crea un cluster Managed Service for Apache Spark con i componenti Flink e Docker abilitati.
gcloud dataproc clusters create CLUSTER_NAME \ --optional-components=FLINK,DOCKER \ --image-version=DATAPROC_IMAGE_VERSION \ --region=REGION \ --enable-component-gateway \ --scopes=https://www.googleapis.com/auth/cloud-platformNote:
--optional-components: Flink e Docker.--image-version: la versione dell'immagine del cluster, che determina la versione di Flink installata sul cluster (ad esempio, vedi le versioni dei componenti Apache Flink elencate per le quattro versioni di rilascio dell'immagine 2.0.x più recenti e precedenti).--region: una regione di Managed Service for Apache Spark disponibile.--enable-component-gateway: attiva l'accesso all'interfaccia utente di Flink Job Manager.--scopes: attiva l'accesso alle API da parte del cluster (vedi Best practice per gli ambiti). Google Cloud L'ambitocloud-platformè abilitato per impostazione predefinita (non è necessario includere questa impostazione del flag) quando crei un cluster che utilizza la versione immagine 2.1 o successive di Managed Service for Apache Spark.
Utilizza gcloud CLI localmente o in Cloud Shell per creare un bucket Cloud Storage. Specificherai BUCKET_NAME quando esegui un programma di conteggio delle parole di esempio.
gcloud storage buckets create BUCKET_NAMEIn una finestra del terminale sulla VM del cluster, avvia una sessione Flink YARN. Prendi nota dell'URL master di Flink, l'indirizzo del master di Flink in cui vengono eseguiti i job. Specificherai il FLINK_MASTER_URL quando esegui un programma di conteggio delle parole di esempio.
. /usr/bin/flink-yarn-daemonVisualizza e annotati la versione di Flink in esecuzione nel cluster Managed Service for Apache Spark. Specificherai il FLINK_VERSION quando esegui un programma di conteggio delle parole di esempio.
flink --versionInstalla le librerie Python necessarie per il job sul nodo master del cluster.
Installa una versione di Beam compatibile con la versione di Flink sul cluster.
python -m pip install apache-beam[gcp]==BEAM_VERSIONEsegui l'esempio di conteggio delle parole sul nodo master del cluster.
python -m apache_beam.examples.wordcount \ --runner=FlinkRunner \ --flink_version=FLINK_VERSION \ --flink_master=FLINK_MASTER_URL --flink_submit_uber_jar \ --output=gs://BUCKET_NAME/python-wordcount-outNote:
--runner:FlinkRunner.--flink_version: FLINK_VERSION, come indicato in precedenza.--flink_master: FLINK_MASTER_URL, come indicato in precedenza.--flink_submit_uber_jar: utilizza l'uber JAR per eseguire il job Beam.--output: BUCKET_NAME, creato in precedenza.
Verifica che i risultati siano stati scritti nel bucket.
gcloud storage cat gs://BUCKET_NAME/python-wordcount-out-SHARD_IDInterrompi la sessione Flink YARN.
- Recupera l'ID applicazione.
yarn application -list1. Insert the <var>YARN_APPLICATION_ID</var>, then stop the session.yarn application -kill
Esegui Flink su un cluster Kerberizzato
Il componente Managed Service for Apache Spark Flink supporta i cluster Kerberizzati. Per inviare e rendere persistente un job Flink o per avviare un cluster Flink è necessario un ticket Kerberos valido. Per impostazione predefinita, un ticket Kerberos rimane valido per sette giorni.
Accedere all'interfaccia utente di Flink Job Manager
L'interfaccia web di Flink Job Manager è disponibile durante l'esecuzione di un job Flink o di un cluster di sessione Flink. Per utilizzare l'interfaccia web:
- Crea un cluster Managed Service for Apache Spark Flink.
- Dopo la creazione del cluster, fai clic sul link YARN ResourceManager di Component Gateway nella scheda Interfaccia web della pagina Dettagli cluster nella console Google Cloud .
- Nell'interfaccia utente di YARN Resource Manager, identifica la voce dell'applicazione del cluster Flink. A seconda dello stato di completamento di un job, verrà visualizzato un link ApplicationMaster
o History.
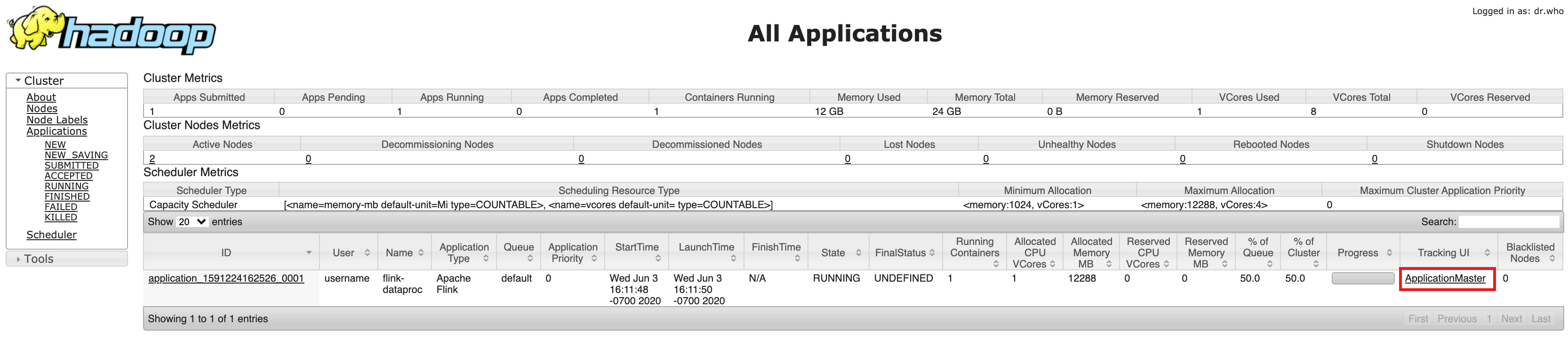
- Per un job di streaming a esecuzione prolungata, fai clic sul link ApplicationManager per aprire la dashboard di Flink. Per un job completato, fai clic sul link Cronologia per visualizzare i dettagli del job.
