
במסמך הזה מוסבר איך להפעיל את Lightning Engine כדי להאיץ עומסי עבודה של אצווה וסשנים אינטראקטיביים של Serverless for Apache Spark.
סקירה כללית
Lightning Engine הוא מאיץ שאילתות בעל ביצועים גבוהים שמבוסס על מנוע אופטימיזציה רב-שכבתי שמבצע שיטות אופטימיזציה מקובלות, כמו אופטימיזציה של שאילתות והרצה, וגם אופטימיזציות שנבחרו בקפידה בשכבת מערכת הקבצים ובמחברים של גישה לנתונים.
כפי שמוצג באיור הבא, Lightning Engine מאיץ את ביצוע השאילתות של Spark בעומס עבודה שדומה ל-TPC-H (גודל מערך הנתונים הוא 10 TB).
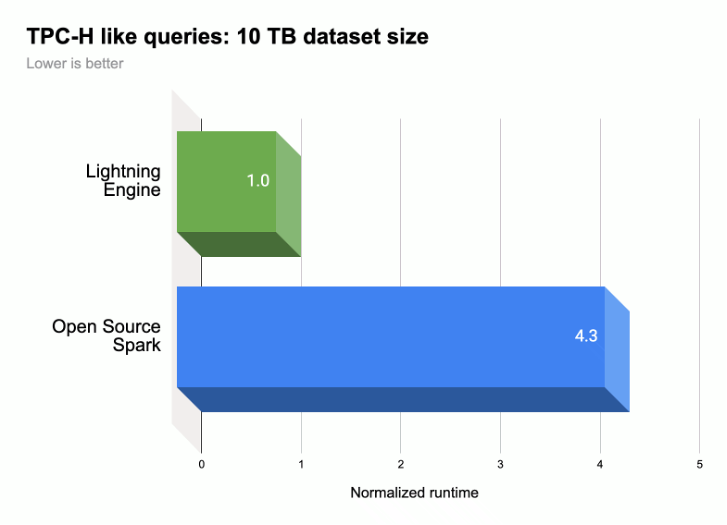
מידע נוסף זמין במאמר הדור הבא של ביצועי Apache Spark – הכירו את Lightning Engine.
זמינות של Lightning Engine
- אפשר להשתמש ב-Lightning Engine עם זמן הריצה Serverless for Apache Spark 2.3.
- Lightning Engine זמין רק עם מסלול הפרימיום של Serverless for Apache Spark.
- עומסי עבודה של אצווה: Lightning Engine מופעל באופן אוטומטי לעומסי עבודה של אצווה ברמת הפרימיום. לא נדרשת שום פעולה.
- סשנים אינטראקטיביים: מנוע Lightning לא מופעל כברירת מחדל בסשנים אינטראקטיביים. במאמר הפעלת Lightning Engine מוסבר איך להפעיל את התכונה.
- תבניות של סשנים: Lightning Engine לא מופעל כברירת מחדל בתבניות של סשנים. במאמר הפעלת Lightning Engine מוסבר איך להפעיל את התכונה.
הפעלת Lightning Engine
בקטעים הבאים מוסבר איך להפעיל את מנוע Lightning בעומס עבודה של אצווה ב-Serverless for Apache Spark, בתבנית סשן ובסשן אינטראקטיבי.
עומס עבודה באצווה
הפעלת Lightning Engine בעומס עבודה של אצווה
אתם יכולים להשתמש במסוף Google Cloud , ב-Google Cloud CLI או ב-Dataproc API כדי להפעיל את Lightning Engine בעומס עבודה של אצווה.
המסוף
משתמשים במסוף Google Cloud כדי להפעיל את Lightning Engine בעומס עבודה של אצווה.
במסוף Google Cloud :
- עוברים אל Dataproc Batches.
- לוחצים על יצירה כדי לפתוח את הדף יצירת קבוצה.
בוחרים את השדות הבאים וממלאים אותם:
- מאגר:
- גרסת זמן ריצה: בוחרים באפשרות
2.3.
- גרסת זמן ריצה: בוחרים באפשרות
הגדרת רמת מסלול:
- בוחרים באפשרות
Premium. האפשרות 'הפעלת LIGHTNING ENGINE להאצת הביצועים של Spark' מופעלת ומסומנת באופן אוטומטי.
כשבוחרים במסלול הפרימיום, הערכים של Driver Compute Tier ושל Executor Compute Tier מוגדרים ל-
Premium. אי אפשר לשנות את הגדרות החישוב של מסלול הפרימיום שמוגדרות אוטומטית עבור Batch באמצעות סביבות זמן ריצה שקדמו ל-3.0.אפשר להגדיר את רמת הדיסק של מנהל התקן ואת רמת הדיסק של Executor ל-
Premiumאו להשאיר אותם ברמת ברירת המחדלStandard. אם בוחרים רמת פרימיום של דיסק, צריך לבחור את גודל הדיסק. מידע נוסף זמין במאמר בנושא מאפייני הקצאת משאבים.- בוחרים באפשרות
מאפיינים: אופציונלי: מזינים את הצמד
Key(שם המאפיין) ו-Valueאם רוצים לבחור את זמן הריצה של Native Query Execution:מפתח ערך spark.dataproc.lightningEngine.runtimeמותאמת
- מאגר:
ממלאים, בוחרים או מאשרים הגדרות אחרות של עומסי עבודה באצווה. איך שולחים עומס עבודה של Spark batch
לוחצים על שליחה כדי להריץ את עומס העבודה של Spark batch.
gcloud
מגדירים את דגלי הפקודה הבאים של gcloud dataproc batches submit spark ב-CLI של gcloud כדי להפעיל את Lightning Engine בעומס עבודה של אצווה.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
הערות:
- PROJECT_ID: מזהה הפרויקט ב- Google Cloud . מזהי הפרויקטים מופיעים בקטע Project info בלוח הבקרה של מסוף Google Cloud .
- REGION: אזור זמין ב-Compute Engine להרצת עומס העבודה.
--properties=dataproc.tier=premium. הגדרת רמת פרימיום מגדירה אוטומטית את המאפיינים הבאים בעומס העבודה של האצווה:-
spark.dataproc.engine=lightningEngineבוחר ב-Lightning Engine עבור עומס העבודה של האצווה. - המאפיינים
spark.dataproc.driver.compute.tierו-spark.dataproc.executor.compute.tierמוגדרים ל-premium(ראו מאפייני הקצאת משאבים). אי אפשר לשנות את הגדרות החישוב האלה של מסלול הפרימיום שמוגדרות אוטומטית עבור Batch באמצעות סביבות זמן ריצה שקדמו ל-3.0.
-
נכסים אחרים
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeמוסיפים את המאפיין הזה אם רוצים לבחור את זמן הריצה של Native Query Execution.רמות וגדלים של דיסקים: כברירת מחדל, הגדלים של הדיסקים של מנהל התקן ושל תהליך ההרצה מוגדרים לרמות ולגדלים
standard. אפשר להוסיף מאפיינים כדי לבחורpremiumרמות וגדלים של דיסקים (בכפולות של375 GiB).
מידע נוסף זמין במאמר בנושא מאפייני הקצאת משאבים.
OTHER_FLAGS_AS_NEEDED: אפשר לעיין במאמר בנושא שליחת עומס עבודה של אצווה ב-Spark.
API
כדי להפעיל את Lightning Engine בעומס עבודה באצווה, כחלק מבקשת batches.create:
- מגדירים את RuntimeConfig.version לערך
2.3. מוסיפים את המאפיין dataproc.tier:'premium' אל RuntimeConfig.properties. הגדרת רמת הפרימיום מגדירה באופן אוטומטי את המאפיינים הבאים בעומס העבודה של האצווה:
-
spark.dataproc.engine=lightningEngineבוחר ב-Lightning Engine עבור עומס העבודה של האצווה. - המאפיינים
spark.dataproc.driver.compute.tierו-spark.dataproc.executor.compute.tierמוגדרים ל-premium(ראו מאפייני הקצאת משאבים). אי אפשר לשנות את הגדרות החישוב האלה של מסלול הפרימיום שמוגדרות אוטומטית עבור Batch שמשתמשות בסביבות ריצה מגרסה קודמת ל-3.0.
-
אחר RuntimeConfig.properties:
Native Query Engine:
spark.dataproc.lightningEngine.runtime:native. מוסיפים את המאפיין הזה אם רוצים לבחור את זמן הריצה של Native Query Execution.רמות וגדלים של דיסקים: כברירת מחדל, הגדלים של הדיסקים של מנהל התקן ושל תהליך ההרצה מוגדרים לרמות ולגדלים
standard. אפשר להוסיף נכסים כדי לבחורpremiumרמות וגדלים (בכפולות של375 GiB).
מידע נוסף זמין במאמר בנושא מאפייני הקצאת משאבים.
במאמר שליחת עומס עבודה של אצווה ב-Spark מוסבר איך מגדירים שדות אחרים ב-API של עומס עבודה של אצווה.
תבנית סשן
הפעלת Lightning Engine בתבנית סשן
אפשר להשתמש ב Google Cloud מסוף, ב-Google Cloud CLI או ב-Dataproc API כדי להפעיל את Lightning Engine בתבנית של סשן ב-Jupyter או ב-Spark Connect.
המסוף
משתמשים במסוף Google Cloud כדי להפעיל את Lightning Engine בעומס עבודה של אצווה.
במסוף Google Cloud :
- עוברים אל Dataproc Session Templates.
- לוחצים על יצירה כדי לפתוח את הדף יצירת תבנית סשן.
בוחרים את השדות הבאים וממלאים אותם:
- פרטי תבנית הסשן:
- בוחרים באפשרות 'הפעלת Lightning Engine להאצת הביצועים של Spark'.
- הגדרת הביצוע:
- גרסת זמן ריצה: בוחרים באפשרות
2.3.
- גרסת זמן ריצה: בוחרים באפשרות
מאפיינים: מזינים את זוגות הערכים הבאים
Key(שם המאפיין) ו-Valueכדי לבחור את רמת הפרימיום:מפתח ערך dataproc.tierפרימיום spark.dataproc.enginelightningEngine אופציונלי: מזינים את הצמד
Key(שם הנכס) ו-Valueכדי לבחור את זמן הריצה של Native Query Execution (הרצת שאילתות מקוריות):מפתח ערך spark.dataproc.lightningEngine.runtimenative
- פרטי תבנית הסשן:
ממלאים, בוחרים או מאשרים הגדרות אחרות של תבנית הביקור. איך יוצרים תבנית של סשן
לוחצים על שליחה כדי ליצור את תבנית הסשן.
gcloud
אי אפשר ליצור ישירות תבנית של סשן Serverless for Apache Spark באמצעות ה-CLI של gcloud. במקום זאת, אפשר להשתמש בפקודה gcloud beta dataproc session-templates import כדי לייבא תבנית קיימת של סשן, לערוך את התבנית המיובאת כדי להפעיל את Lightning Engine ואופציונלית את זמן הריצה של Native Query, ואז לייצא את התבנית הערוכה באמצעות הפקודה gcloud beta dataproc session-templates export.
API
כדי להפעיל את Lightning Engine בתבנית של סשן, כחלק מהבקשה שלכם ל-sessionTemplates.create:
- מגדירים את RuntimeConfig.version לערך
2.3. - מוסיפים את dataproc.tier:premium ו-spark.dataproc.engine:lightningEngine אל RuntimeConfig.properties.
אחר RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: מוסיפים את המאפיין הזה ל-RuntimeConfig.properties כדי לבחור את זמן הריצה של Native Query Execution.
במאמר יצירת תבנית של סשן מוסבר איך להגדיר שדות אחרים של API של תבנית סשן.
סשן אינטראקטיבי
הפעלת Lightning Engine בסשן אינטראקטיבי
אתם יכולים להשתמש ב-Google Cloud CLI או ב-Dataproc API כדי להפעיל את Lightning Engine בסשן אינטראקטיבי של Serverless ל-Apache Spark. אפשר גם להפעיל את Lightning Engine בסשן אינטראקטיבי במחברת של BigQuery Studio.
gcloud
מגדירים את הפקודות הבאות של ה-CLI של gcloud gcloud beta dataproc sessions create spark כדי להפעיל את Lightning Engine בסשן אינטראקטיבי.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
הערות:
- PROJECT_ID: מזהה הפרויקט ב- Google Cloud . מזהי הפרויקטים מופיעים בקטע Project info בלוח הבקרה של מסוף Google Cloud .
- REGION: אזור זמין ב-Compute Engine להרצת עומס העבודה.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. המאפיינים האלה מפעילים את Lightning Engine בסשן.מאפיינים אחרים:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: מוסיפים את המאפיין הזה כדי לבחור את זמן הריצה של Native Query Execution.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: ראו יצירת סשן אינטראקטיבי.
API
כדי להפעיל את Lightning Engine בסשן, כחלק מהבקשה sessions.create:
- מגדירים את RuntimeConfig.version לערך
2.3. - מוסיפים את dataproc.tier:premium ו-spark.dataproc.engine:lightningEngine אל RuntimeConfig.properties.
אחר RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: מוסיפים את המאפיין הזה ל-RuntimeConfig.properties אם רוצים לבחור את זמן הריצה Native Query Execution.
במאמר יצירת סשן אינטראקטיבי מוסבר איך מגדירים שדות אחרים של API של תבנית סשן.
מחברת BigQuery
אפשר להפעיל את Lightning Engine כשיוצרים סשן במחברת PySpark ב-BigQuery Studio.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
אימות ההגדרות של Lightning Engine
אתם יכולים להשתמש במסוף Google Cloud , ב-Google Cloud CLI או ב-Dataproc API כדי לאמת את ההגדרות של Lightning Engine בעומס עבודה של אצווה, בתבנית סשן או בסשן אינטראקטיבי.
עומס עבודה באצווה
כדי לוודא שtier מוגדר ל-
premiumו-engine מוגדר ל-Lightning Engine:- מסוףGoogle Cloud : בדף Batches, אפשר לראות את העמודות Tier ו-Engine של האצווה. אפשר גם ללחוץ על מזהה האצווה כדי לראות את ההגדרות האלה בדף פרטי האצווה.
- ה-CLI של gcloud: מריצים את הפקודה
gcloud dataproc batches describe. - API: שליחת בקשת
batches.get.
תבנית סשן
כדי לוודא שהמנוע מוגדר ל-
Lightning Engineבתבנית של סשן:- מסוףGoogle Cloud : בדף Session Templates, בודקים את העמודה Engine של התבנית. אפשר ללחוץ על השם של תבנית הסשן כדי לראות את ההגדרה הזו גם בדף הפרטים של תבנית הסשן.
- gcloud CLI: מריצים את הפקודה
gcloud beta dataproc session-templates describe. - API: שליחת בקשת
sessionTemplates.get.
סשן אינטראקטיבי
ההגדרה של המנוע היא
Lightning Engineבסשן אינטראקטיבי:- מסוףGoogle Cloud : בדף Interactive Sessions, אפשר לראות את התבנית בעמודה Engine. אפשר ללחוץ על מזהה סשן אינטראקטיבי כדי לראות את ההגדרה הזו גם בדף הפרטים של תבנית הסשן.
- gcloud CLI: מריצים את הפקודה
gcloud beta dataproc sessions describe. - API: שליחת בקשת
sessions.get.
הרצת שאילתה מקורית
התכונה Native Query Execution (NQE) היא תכונה אופציונלית של Lightning Engine שמשפרת את הביצועים באמצעות הטמעה מקורית שמבוססת על Apache Gluten ועל Velox, ומיועדת למכשירי Google.
זמן הריצה של Native Query Execution כולל ניהול זיכרון מאוחד למעבר דינמי בין זיכרון מחוץ ל-heap לבין זיכרון ב-heap, בלי שנדרשים שינויים בהגדרות הקיימות של Spark. ה-NQE כולל תמיכה מורחבת באופרטורים, בפונקציות ובסוגי נתונים של Spark, וגם יכולות חכמות לזיהוי אוטומטי של הזדמנויות לשימוש במנוע המקורי כדי לבצע פעולות אופטימליות של pushdown.
זיהוי עומסי עבודה של ביצוע שאילתות מקוריות
כדאי להשתמש בביצוע שאילתות מקוריות בתרחישים הבאים:
ממשקי API של Spark Dataframe, ממשקי API של Spark Dataset ושאילתות Spark SQL שקוראות נתונים מקובצי Parquet ו-ORC. פורמט קובץ הפלט לא משפיע על הביצועים של Native Query Execution.
עומסי עבודה שמומלצים על ידי הכלי לאישור ביצוע שאילתות מקוריות.
לא מומלץ להשתמש בהרצת שאילתות מקוריות בעומסי עבודה עם קלט מסוגי הנתונים הבאים:
- Byte: ORC ו-Parquet
- חותמת זמן: ORC
- Struct, Array, Map: Parquet
מגבלות על ביצוע שאילתות מקוריות
הפעלה של Native Query Execution בתרחישים הבאים עלולה לגרום לחריגים, לחוסר תאימות ל-Spark או להעברה של עומס העבודה למנוע Spark שמוגדר כברירת מחדל.
חלופות
ביצוע שאילתות מקוריות במהלך הביצוע עלול לגרום לנסיגה בעומס העבודה למנוע הביצוע של Spark, וכתוצאה מכך לרגרסיה או לכשל.
ANSI: אם מצב ANSI מופעל, הביצוע חוזר ל-Spark.
מצב תלוי-אותיות רישיות: התכונה 'הרצת שאילתות מקוריות' תומכת רק במצב ברירת המחדל של Spark, שהוא מצב לא תלוי-אותיות רישיות. אם מפעילים את המצב שבו יש הבחנה בין אותיות רישיות לאותיות קטנות, יכולות להיות תוצאות שגויות.
סריקת טבלה מחולקת למחיצות: הפעלת שאילתות מקוריות תומכת בסריקת טבלה מחולקת למחיצות רק אם הנתיב מכיל את פרטי המחיצה. אחרת, עומס העבודה עובר למנוע ההפעלה של Spark.
התנהגות לא תואמת
התנהגות לא תואמת או תוצאות שגויות יכולות להתרחש כשמשתמשים בהרצת שאילתות מקוריות במקרים הבאים:
פונקציות JSON: בביצוע שאילתות מקוריות יש תמיכה במחרוזות שמוקפות במירכאות כפולות, ולא במירכאות בודדות. התוצאות לא נכונות כשמשתמשים במירכאות בודדות. שימוש ב-'*' בנתיב עם הפונקציה
get_json_objectמחזירNULL.הגדרת קריאה של Parquet:
- הפעלת שאילתות מקוריות מתייחסת ל-
spark.files.ignoreCorruptFilesכאילו הערךfalseמוגדר כברירת מחדל, גם אם הערךtrueמוגדר. - הפעלת שאילתות מקוריות מתעלמת מ-
spark.sql.parquet.datetimeRebaseModeInReadומחזירה רק את התוכן של קובץ Parquet. לא נלקחים בחשבון ההבדלים בין לוח השנה ההיברידי מדור קודם (יוליאני-גריגוריאני) לבין לוח השנה הגרגוריאני הפרוֹלֶפטי. התוצאות ב-Spark יכולות להיות שונות.
- הפעלת שאילתות מקוריות מתייחסת ל-
NaN: לא נתמך. לדוגמה, יכולות להתקבל תוצאות לא צפויות כשמשתמשים ב-NaNבהשוואה מספרית.קריאת עמודות ב-Spark: יכולה להתרחש שגיאה קריטית כי וקטור העמודות ב-Spark לא תואם להרצת שאילתות מקוריות.
גלישה: אם מספר המחיצות של ערבוב הנתונים מוגדר כמספר גדול, התכונה 'גלישה לדיסק' יכולה להפעיל
OutOfMemoryException. אם זה קורה, אפשר לבטל את החריגה הזו על ידי הקטנת מספר המחיצות.