
이 문서에서는 Lightning Engine을 사용 설정하여 Managed Service for Apache Spark 일괄 워크로드 및 대화형 세션을 가속화하는 방법을 보여줍니다.
개요
Lightning Engine은 쿼리 및 실행 최적화와 같은 일반적인 최적화 기법과 파일 시스템 레이어 및 데이터 액세스 커넥터의 선별된 최적화를 실행하는 다중 레이어 최적화 엔진으로 구동되는 고성능 쿼리 가속기입니다.
다음 그림과 같이 Lightning Engine은 TPC-H 유사 워크로드(10 TB 데이터 세트 크기)에서 Spark 쿼리 실행 성능을 가속화합니다.
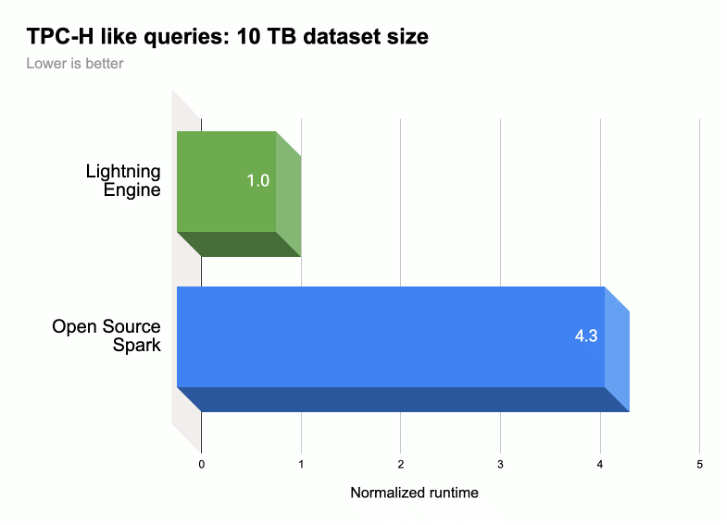
자세한 내용은 Lightning Engine 소개: 차세대 Apache Spark 성능을 참고하세요.
Lightning Engine 사용 가능 여부
- Lightning Engine은 Managed Service for Apache Spark 런타임 2.3과 함께 사용할 수 있습니다.
- Lightning Engine은 Managed Service for Apache Spark 프리미엄 가격 책정 등급에서만 사용할 수 있습니다.
- 일괄 워크로드: Lightning Engine은 프리미엄 등급의 일괄 워크로드에 대해 자동으로 사용 설정됩니다. 별도의 조치가 필요하지 않습니다.
- 대화형 세션: 대화형 세션의 경우 Lightning 엔진이 기본적으로 사용 설정되어 있지 않습니다. 사용 설정하려면 Lightning Engine 사용 설정을 참고하세요.
- 세션 템플릿: 세션 템플릿의 경우 Lightning Engine이 기본적으로 사용 설정되지 않습니다. 이를 사용 설정하려면 Lightning Engine 사용 설정을 참고하세요.
Lightning Engine 사용 설정
다음 섹션에서는 Managed Service for Apache Spark 일괄 워크로드, 세션 템플릿, 대화형 세션에서 Lightning 엔진을 사용 설정하는 방법을 보여줍니다.
일괄 워크로드
일괄 워크로드에서 Lightning Engine 사용 설정
Google Cloud 콘솔, Google Cloud CLI 또는 Dataproc API를 사용하여 일괄 워크로드에서 Lightning Engine을 사용 설정할 수 있습니다.
콘솔
Google Cloud 콘솔을 사용하여 일괄 워크로드에서 Lightning Engine을 사용 설정합니다.
Google Cloud 콘솔에서 다음을 수행합니다.
- Managed Service for Apache Spark 배치로 이동합니다.
- 만들기를 클릭하여 배치 만들기 페이지를 엽니다.
다음 필드를 선택하고 작성합니다.
- 컨테이너:
- 런타임 버전:
2.3을 선택합니다.
- 런타임 버전:
등급 구성:
Premium을 선택합니다. 이렇게 하면 'Lightning Engine을 사용 설정하여 Spark 성능 가속화'가 자동으로 사용 설정되고 확인됩니다.
프리미엄 등급을 선택하면 드라이버 컴퓨팅 등급과 실행자 컴퓨팅 등급이
Premium로 설정됩니다.3.0이전의 런타임을 사용하는 배치에 대해 이러한 프리미엄 등급 컴퓨팅 설정은 자동으로 설정되며 재정의할 수 없습니다.드라이버 디스크 등급 및 실행자 디스크 등급을
Premium로 구성하거나 기본Standard등급 값으로 그대로 둘 수 있습니다. 프리미엄 디스크 등급을 선택하는 경우 디스크 크기를 선택해야 합니다. 자세한 내용은 리소스 할당 속성을 참고하세요.속성: 선택사항: 네이티브 쿼리 실행 런타임을 선택하려면 다음
Key(속성 이름) 및Value쌍을 입력합니다.키 값 spark.dataproc.lightningEngine.runtime원주민/토착민
- 컨테이너:
다른 일괄 워크로드 설정을 입력하거나 선택하거나 확인합니다. Spark 일괄 워크로드 제출을 참고하세요.
제출을 클릭하여 Spark 배치 워크로드를 실행합니다.
gcloud
다음 gcloud CLI gcloud dataproc batches submit spark 명령어 플래그를 설정하여 일괄 워크로드에서 Lightning Engine을 사용 설정합니다.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
참고:
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- REGION: 워크로드를 실행하는 데 사용할 수 있는 Compute Engine 리전입니다.
--properties=dataproc.tier=premium. 프리미엄 등급을 설정하면 일괄 워크로드에 다음 속성이 자동으로 설정됩니다.spark.dataproc.engine=lightningEngine는 일괄 워크로드에 Lightning Engine을 선택합니다.spark.dataproc.driver.compute.tier및spark.dataproc.executor.compute.tier은premium로 설정됩니다 (리소스 할당 속성 참고).3.0이전의 런타임을 사용하는 배치에 대해서는 이러한 프리미엄 등급 컴퓨팅 설정이 자동으로 설정되며 재정의할 수 없습니다.
기타 속성
네이티브 쿼리 엔진:
spark.dataproc.lightningEngine.runtime=native네이티브 쿼리 실행 런타임을 선택하려면 이 속성을 추가합니다.디스크 등급 및 크기: 기본적으로 드라이버 및 실행자 디스크 크기는
standard등급 및 크기로 설정됩니다. 속성을 추가하여premium디스크 등급과 크기 (375 GiB의 배수)를 선택할 수 있습니다.
자세한 내용은 리소스 할당 속성을 참고하세요.
OTHER_FLAGS_AS_NEEDED: Spark 배치 워크로드 제출을 참고하세요.
API
일괄 워크로드에서 Lightning Engine을 사용 설정하려면 batches.create 요청의 일부로 다음을 실행하세요.
- RuntimeConfig.version을
2.3로 설정합니다. RuntimeConfig.properties에 'dataproc.tier':'premium'을 추가합니다. 프리미엄 등급을 설정하면 배치 워크로드에 다음 속성이 자동으로 설정됩니다.
spark.dataproc.engine=lightningEngine는 일괄 워크로드에 Lightning Engine을 선택합니다.spark.dataproc.driver.compute.tier및spark.dataproc.executor.compute.tier은premium로 설정됩니다 (리소스 할당 속성 참고).3.0이전의 런타임을 사용하는 배치에서는 이러한 프리미엄 등급 컴퓨팅 설정이 자동으로 설정되므로 재정의할 수 없습니다.
기타 RuntimeConfig.properties:
네이티브 쿼리 엔진:
spark.dataproc.lightningEngine.runtime:native. 네이티브 쿼리 실행 런타임을 선택하려면 이 속성을 추가하세요.디스크 등급 및 크기: 기본적으로 드라이버 및 실행자 디스크 크기는
standard등급 및 크기로 설정됩니다.premium등급과 크기 (375 GiB의 배수)를 선택하는 속성을 추가할 수 있습니다.
자세한 내용은 리소스 할당 속성을 참고하세요.
다른 일괄 워크로드 API 필드를 설정하려면 Spark 일괄 워크로드 제출을 참고하세요.
세션 템플릿
세션 템플릿에서 Lightning Engine 사용 설정
Google Cloud 콘솔, Google Cloud CLI 또는 Dataproc API를 사용하여 Jupyter 또는 Spark Connect 세션의 세션 템플릿에서 Lightning Engine을 사용 설정할 수 있습니다.
콘솔
Google Cloud 콘솔을 사용하여 일괄 워크로드에서 Lightning Engine을 사용 설정합니다.
Google Cloud 콘솔에서 다음을 수행합니다.
- Managed Service for Apache Spark 세션 템플릿으로 이동
- 만들기를 클릭하여 세션 템플릿 만들기 페이지를 엽니다.
다음 필드를 선택하고 작성합니다.
- 세션 템플릿 정보:
- 'Lightning Engine을 사용 설정하여 Spark 성능 가속화'를 선택합니다.
- 실행 구성:
- 런타임 버전:
2.3을 선택합니다.
- 런타임 버전:
속성: 다음
Key(속성 이름) 및Value쌍을 입력하여 프리미엄 등급을 선택합니다.키 값 dataproc.tier프리미엄 spark.dataproc.enginelightningEngine 선택사항: 다음
Key(속성 이름) 및Value쌍을 입력하여 네이티브 쿼리 실행 런타임을 선택합니다.키 값 spark.dataproc.lightningEngine.runtimenative
- 세션 템플릿 정보:
다른 세션 템플릿 설정을 입력하거나 선택하거나 확인합니다. 세션 템플릿 만들기를 참고하세요.
제출을 클릭하여 세션 템플릿을 만듭니다.
gcloud
gcloud CLI를 사용하여 Managed Service for Apache Spark 세션 템플릿을 직접 만들 수는 없습니다. 대신 gcloud beta dataproc session-templates import 명령어를 사용하여 기존 세션 템플릿을 가져오고, 가져온 템플릿을 수정하여 Lightning Engine과 선택적으로 Native Query 런타임을 사용 설정한 다음 gcloud beta dataproc session-templates export 명령어를 사용하여 수정된 템플릿을 내보낼 수 있습니다.
API
세션 템플릿에서 Lightning Engine을 사용 설정하려면 sessionTemplates.create 요청의 일부로 다음을 수행하세요.
- RuntimeConfig.version을
2.3로 설정합니다. - RuntimeConfig.properties에 'dataproc.tier':'premium' 및 'spark.dataproc.engine':'lightningEngine'을 추가합니다.
기타 RuntimeConfig.properties:
- 네이티브 쿼리 엔진:
spark.dataproc.lightningEngine.runtime:native: RuntimeConfig.properties에 이 속성을 추가하여 네이티브 쿼리 실행 런타임을 선택합니다.
다른 세션 템플릿 API 필드를 설정하려면 세션 템플릿 만들기를 참고하세요.
대화형 세션
대화형 세션에서 Lightning Engine 사용 설정
Google Cloud CLI 또는 Dataproc API를 사용하여 Apache Spark용 관리 서비스의 대화형 세션에서 Lightning Engine을 사용 설정할 수 있습니다. BigQuery Studio 노트북의 대화형 세션에서 Lightning Engine을 사용 설정할 수도 있습니다.
gcloud
대화형 세션에서 Lightning Engine을 사용 설정하려면 다음 gcloud CLI gcloud beta dataproc sessions create spark 명령어 플래그를 설정합니다.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
참고:
- PROJECT_ID: Google Cloud 프로젝트 ID입니다. 프로젝트 ID는 Google Cloud 콘솔 대시보드의 프로젝트 정보 섹션에 나열됩니다.
- REGION: 워크로드를 실행하는 데 사용할 수 있는 Compute Engine 리전입니다.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. 이러한 속성은 세션에서 Lightning Engine을 사용 설정합니다.기타 속성:
- 네이티브 쿼리 엔진:
spark.dataproc.lightningEngine.runtime=native: 네이티브 쿼리 실행 런타임을 선택하려면 이 속성을 추가합니다.
- 네이티브 쿼리 엔진:
OTHER_FLAGS_AS_NEEDED: 대화형 세션 만들기를 참고하세요.
API
세션에서 Lightning Engine을 사용 설정하려면 sessions.create 요청의 일부로 다음을 실행하세요.
- RuntimeConfig.version을
2.3로 설정합니다. - RuntimeConfig.properties에 'dataproc.tier':'premium' 및 'spark.dataproc.engine':'lightningEngine'을 추가합니다.
기타 RuntimeConfig.properties:
- 네이티브 쿼리 엔진:
spark.dataproc.lightningEngine.runtime:native: 네이티브 쿼리 실행 런타임을 선택하려면 RuntimeConfig.properties에 이 속성을 추가합니다.
다른 세션 템플릿 API 필드를 설정하려면 대화형 세션 만들기를 참고하세요.
BigQuery 노트북
BigQuery Studio PySpark 노트북에서 세션을 만들 때 Lightning Engine을 사용 설정할 수 있습니다.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Lightning Engine 설정 확인
Google Cloud 콘솔, Google Cloud CLI 또는 Dataproc API를 사용하여 일괄 워크로드, 세션 템플릿 또는 대화형 세션의 Lightning Engine 설정을 확인할 수 있습니다.
일괄 워크로드
일괄 계층이
premium로 설정되고 엔진이Lightning Engine로 설정되었는지 확인하려면 다음 단계를 따르세요.- Google Cloud 콘솔: 배치 페이지에서 배치에 대한 계층 및 엔진 열을 확인합니다. 일괄 ID를 클릭하여 일괄 세부정보 페이지에서 이러한 설정을 확인할 수도 있습니다.
- gcloud CLI:
gcloud dataproc batches describe명령어를 실행합니다. - API:
batches.get요청을 실행합니다.
세션 템플릿
세션 템플릿에 대해 engine이
Lightning Engine로 설정되어 있는지 확인하려면 다음 단계를 따르세요.- Google Cloud 콘솔: 세션 템플릿 페이지에서 템플릿의 엔진 열을 확인합니다. 세션 템플릿 이름을 클릭하여 세션 템플릿 세부정보 페이지에서 이 설정을 확인할 수도 있습니다.
- gcloud CLI:
gcloud beta dataproc session-templates describe명령어를 실행합니다. - API:
sessionTemplates.get요청을 실행합니다.
대화형 세션
엔진이 대화형 세션에 대해
Lightning Engine로 설정됩니다.- Google Cloud 콘솔: 대화형 세션 페이지에서 템플릿의 엔진 열을 확인합니다. 대화형 세션 ID를 클릭하여 세션 템플릿 세부정보 페이지에서 이 설정을 확인할 수도 있습니다.
- gcloud CLI:
gcloud beta dataproc sessions describe명령어를 실행합니다. - API:
sessions.get요청을 실행합니다.
네이티브 쿼리 실행
네이티브 쿼리 실행 (NQE)은 Google 하드웨어용으로 설계된 Apache Gluten 및 Velox를 기반으로 하는 네이티브 구현을 통해 성능을 향상하는 선택적 Lightning Engine 기능입니다.
네이티브 쿼리 실행 런타임에는 기존 Spark 구성을 변경하지 않고도 오프힙 메모리와 온힙 메모리 간에 동적으로 전환할 수 있는 통합 메모리 관리가 포함되어 있습니다. NQE에는 연산자, 함수, Spark 데이터 유형에 대한 확장된 지원과 최적의 푸시다운 작업을 위해 네이티브 엔진을 사용할 기회를 자동으로 식별하는 인텔리전스가 포함되어 있습니다.
네이티브 쿼리 실행 워크로드 식별
다음 시나리오에서 네이티브 쿼리 실행을 사용하세요.
Parquet 및 ORC 파일에서 데이터를 읽는 Spark Dataframe API, Spark Dataset API, Spark SQL 쿼리 출력 파일 형식은 네이티브 쿼리 실행 성능에 영향을 미치지 않습니다.
네이티브 쿼리 실행 검증 도구에서 추천하는 워크로드
다음 데이터 유형의 입력이 있는 워크로드에는 네이티브 쿼리 실행이 권장되지 않습니다.
- 바이트: ORC 및 Parquet
- 타임스탬프: ORC
- 구조체, 배열, 맵: Parquet
네이티브 쿼리 실행 제한사항
다음 시나리오에서 네이티브 쿼리 실행을 사용 설정하면 예외, Spark 비호환성 또는 워크로드가 기본 Spark 엔진으로 대체될 수 있습니다.
대체
다음 실행에서 네이티브 쿼리 실행을 사용하면 워크로드가 Spark 실행 엔진으로 대체되어 회귀 또는 실패가 발생할 수 있습니다.
ANSI: ANSI 모드가 사용 설정된 경우 실행이 Spark로 대체됩니다.
대소문자 구분 모드: 네이티브 쿼리 실행은 Spark 기본 대소문자 구분 모드만 지원합니다. 대소문자 구분 모드가 사용 설정된 경우 잘못된 결과가 발생할 수 있습니다.
파티션을 나눈 테이블 스캔: 네이티브 쿼리 실행은 경로에 파티션 정보가 포함된 경우에만 파티션을 나눈 테이블 스캔을 지원하며, 그렇지 않으면 워크로드가 Spark 실행 엔진으로 대체됩니다.
호환되지 않는 동작
다음과 같은 경우 네이티브 쿼리 실행을 사용하면 호환되지 않는 동작이나 잘못된 결과가 발생할 수 있습니다.
JSON 함수: 네이티브 쿼리 실행은 작은따옴표가 아닌 큰따옴표로 묶인 문자열을 지원합니다. 작은따옴표를 사용하면 결과가 잘못됩니다.
get_json_object함수와 함께 경로에 '*'를 사용하면NULL이 반환됩니다.Parquet 읽기 구성:
- 네이티브 쿼리 실행은
true로 설정된 경우에도spark.files.ignoreCorruptFiles을 기본false값으로 설정된 것으로 취급합니다. - 네이티브 쿼리 실행은
spark.sql.parquet.datetimeRebaseModeInRead를 무시하고 Parquet 파일 콘텐츠만 반환합니다. 기존 하이브리드 (율리우스 그레고리) 달력과 소급 그레고리 달력 간의 차이는 고려되지 않습니다. Spark 결과는 다를 수 있습니다.
- 네이티브 쿼리 실행은
NaN: 지원되지 않습니다. 예를 들어 숫자 비교에서NaN을 사용하면 예기치 않은 결과가 발생할 수 있습니다.Spark 열 형식 읽기: Spark 열 형식 벡터가 네이티브 쿼리 실행과 호환되지 않으므로 치명적인 오류가 발생할 수 있습니다.
스필: 셔플 파티션이 큰 수로 설정되면 디스크로 스필 기능이
OutOfMemoryException를 트리거할 수 있습니다. 이 경우 파티션 수를 줄이면 이 예외를 없앨 수 있습니다.