
Dokumen ini menunjukkan cara mengaktifkan Lightning Engine untuk mempercepat workload batch dan sesi interaktif Managed Service untuk Apache Spark.
Ringkasan
Lightning Engine adalah akselerator kueri berperforma tinggi yang didukung oleh mesin pengoptimalan multi-layer yang melakukan teknik pengoptimalan biasa, seperti pengoptimalan kueri dan eksekusi, serta pengoptimalan yang dikurasi di lapisan sistem file dan konektor akses data.
Seperti yang ditunjukkan dalam ilustrasi berikut, Lightning Engine mempercepat performa eksekusi kueri Spark pada workload yang mirip dengan TPC-H
(ukuran set data 10 TB).
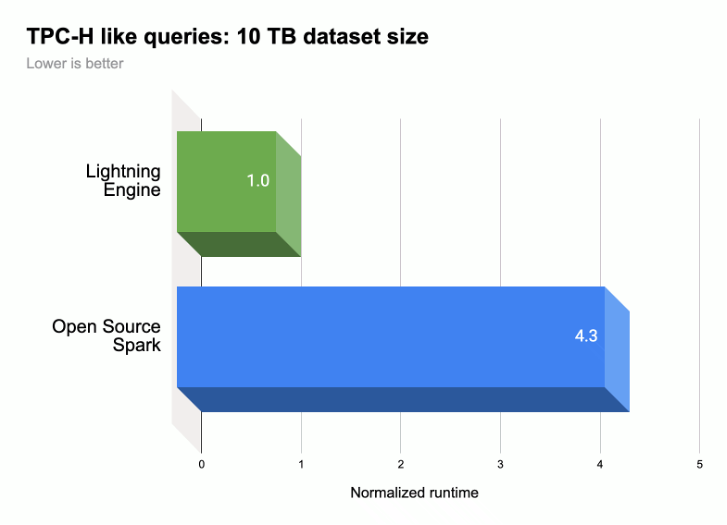
Untuk mengetahui informasi selengkapnya: lihat Memperkenalkan Lightning Engine — performa Apache Spark generasi berikutnya.
Ketersediaan Lightning Engine
- Lightning Engine tersedia untuk digunakan dengan Managed Service untuk Apache Spark runtime 2.3.
- Lightning Engine hanya tersedia dengan paket harga premium Managed Service untuk Apache Spark.
- Workload batch: Lightning Engine diaktifkan secara otomatis untuk workload batch di tingkat premium. Anda tidak perlu melakukan tindakan apa pun.
- Sesi interaktif: Lightning Engine tidak diaktifkan secara default untuk sesi interaktif. Untuk mengaktifkannya, lihat Mengaktifkan Lightning Engine.
- Template sesi: Lightning Engine tidak diaktifkan secara default untuk template sesi. Untuk mengaktifkannya, lihat Mengaktifkan Lightning Engine.
Aktifkan Lightning Engine
Bagian berikut menunjukkan cara mengaktifkan Lightning Engine pada Managed Service for Apache Spark untuk workload batch, template sesi, dan sesi interaktif.
Workload batch
Mengaktifkan Lightning Engine pada workload batch
Anda dapat menggunakan konsol Google Cloud , Google Cloud CLI, atau Dataproc API untuk mengaktifkan Lightning Engine pada beban kerja batch.
Konsol
Gunakan konsol Google Cloud untuk mengaktifkan Lightning Engine pada workload batch.
Di konsol Google Cloud :
- Buka Batch Managed Service untuk Apache Spark.
- Klik Buat untuk membuka halaman Buat batch.
Pilih dan isi kolom berikut:
- Container:
- Versi runtime: Pilih
2.3.
- Versi runtime: Pilih
Konfigurasi Tingkat:
- Pilih
Premium. Opsi ini akan otomatis mengaktifkan dan mencentang "Aktifkan LIGHTNING ENGINE untuk mempercepat performa Spark".
Saat Anda memilih tingkat premium, Driver Compute Tier dan Executor Compute Tier akan disetel ke
Premium. Setelan komputasi tingkat premium yang ditetapkan secara otomatis ini tidak dapat diganti untuk batch menggunakan runtime sebelum3.0.Anda dapat mengonfigurasi Driver Disk Tier dan Executor Disk Tier ke
Premiumatau membiarkannya pada nilai tingkatStandarddefault. Jika memilih tingkat disk premium, Anda harus memilih ukuran disk. Untuk mengetahui informasi selengkapnya, lihat properti alokasi resource.- Pilih
Properti: Opsional: Masukkan pasangan
Key(nama properti) danValueberikut jika Anda ingin memilih runtime Native Query Execution:Kunci Nilai spark.dataproc.lightningEngine.runtimenative
- Container:
Isi, pilih, atau konfirmasi setelan workload batch lainnya. Lihat Mengirimkan workload batch Spark.
Klik Submit untuk menjalankan beban kerja batch Spark.
gcloud
Tetapkan flag perintah gcloud CLI
gcloud dataproc batches submit spark
berikut untuk mengaktifkan Lightning Engine pada beban kerja batch.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Catatan:
- PROJECT_ID: Project ID Google Cloud Anda. Project ID tercantum di bagian Project info di Dasbor konsol Google Cloud .
- REGION: Region Compute Engine yang tersedia untuk menjalankan beban kerja.
--properties=dataproc.tier=premium. Menetapkan tingkat premium secara otomatis akan menetapkan properti berikut pada batch workload:spark.dataproc.engine=lightningEnginememilih Lightning Engine untuk workload batch.spark.dataproc.driver.compute.tierdanspark.dataproc.executor.compute.tierdisetel kepremium(lihat properti alokasi resource). Setelan komputasi tingkat premium yang ditetapkan secara otomatis ini tidak dapat diganti untuk batch menggunakan runtime sebelum3.0.
Properti lainnya
Native Query Engine:
spark.dataproc.lightningEngine.runtime=nativeTambahkan properti ini jika Anda ingin memilih runtime Native Query Execution.Tingkatan dan ukuran disk: Secara default, ukuran disk driver dan eksekutor ditetapkan ke tingkatan dan ukuran
standard. Anda dapat menambahkan properti untuk memilih tingkat dan ukuran diskpremium(dalam kelipatan375 GiB).
Untuk mengetahui informasi selengkapnya, lihat properti alokasi resource.
OTHER_FLAGS_AS_NEEDED: Lihat Mengirimkan workload batch Spark.
API
Untuk mengaktifkan Lightning Engine pada workload batch, sebagai bagian dari permintaan
batches.create Anda:
- Tetapkan RuntimeConfig.version
ke
2.3. Tambahkan "dataproc.tier":"premium" ke RuntimeConfig.properties Menetapkan tingkat premium akan otomatis menetapkan properti berikut pada batch workload:
spark.dataproc.engine=lightningEnginememilih Lightning Engine untuk workload batch.spark.dataproc.driver.compute.tierdanspark.dataproc.executor.compute.tierdisetel kepremium(lihat properti alokasi resource). Setelan komputasi tingkat premium yang ditetapkan secara otomatis ini tidak dapat diganti untuk batch yang menggunakan runtime sebelum3.0.
Lainnya RuntimeConfig.properties:
Mesin Kueri Native:
spark.dataproc.lightningEngine.runtime:native. Tambahkan properti ini jika Anda ingin memilih runtime Native Query Execution.Tingkatan dan ukuran disk: Secara default, ukuran disk driver dan eksekutor ditetapkan ke tingkatan dan ukuran
standard. Anda dapat menambahkan properti untuk memilih tingkat dan ukuranpremium(dalam kelipatan375 GiB).
Untuk mengetahui informasi selengkapnya, lihat properti alokasi resource.
Lihat Mengirimkan workload batch Spark untuk menetapkan kolom API workload batch lainnya.
Template sesi
Mengaktifkan Lightning Engine pada template sesi
Anda dapat menggunakan konsol Google Cloud , Google Cloud CLI, atau Dataproc API untuk mengaktifkan Lightning Engine pada template sesi untuk sesi Jupyter atau Spark Connect.
Konsol
Gunakan konsol Google Cloud untuk mengaktifkan Lightning Engine pada workload batch.
Di konsol Google Cloud :
- Buka Template Sesi Managed Service untuk Apache Spark.
- Klik Buat untuk membuka halaman Buat template sesi.
Pilih dan isi kolom berikut:
- Info template sesi:
- Pilih "Aktifkan Lightning Engine untuk mempercepat performa Spark".
- Konfigurasi Eksekusi:
- Versi runtime: Pilih
2.3.
- Versi runtime: Pilih
Properties: Masukkan pasangan
Key(nama properti) danValueberikut untuk memilih tingkatan Premium:Kunci Nilai dataproc.tierpremium spark.dataproc.enginelightningEngine Opsional: Masukkan pasangan
Key(nama properti) danValueberikut untuk memilih runtime Native Query Execution:Kunci Nilai spark.dataproc.lightningEngine.runtimenative
- Info template sesi:
Isi, pilih, atau konfirmasi setelan template sesi lainnya. Lihat Membuat template sesi.
Klik Submit untuk membuat template sesi.
gcloud
Anda tidak dapat membuat template sesi Managed Service untuk Apache Spark secara langsung menggunakan
gcloud CLI. Sebagai gantinya, Anda dapat menggunakan perintah
gcloud beta dataproc session-templates import untuk mengimpor template sesi yang ada, mengedit template yang diimpor untuk mengaktifkan Lightning Engine dan secara opsional runtime Kueri Native, lalu mengekspor
template yang diedit menggunakan perintah gcloud beta dataproc session-templates export.
API
Untuk mengaktifkan Lightning Engine pada template sesi, sebagai bagian dari permintaan
sessionTemplates.create Anda:
- Tetapkan RuntimeConfig.version
ke
2.3. - Tambahkan "dataproc.tier":"premium" dan "spark.dataproc.engine":"lightningEngine" ke RuntimeConfig.properties.
Lainnya RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Tambahkan properti ini ke RuntimeConfig.properties untuk memilih runtime Native Query Execution.
Lihat artikel Membuat template sesi untuk menetapkan kolom API template sesi lainnya.
Sesi interaktif
Mengaktifkan Lightning Engine pada sesi interaktif
Anda dapat menggunakan Google Cloud CLI atau Dataproc API untuk mengaktifkan Lightning Engine pada sesi interaktif Managed Service for Apache Spark. Anda juga dapat mengaktifkan Lightning Engine dalam sesi interaktif di notebook BigQuery Studio.
gcloud
Tetapkan flag perintah gcloud CLI
gcloud beta dataproc sessions create spark
berikut untuk mengaktifkan Lightning Engine pada sesi interaktif.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Catatan:
- PROJECT_ID: Project ID Google Cloud Anda. Project ID tercantum di bagian Project info di Dasbor konsol Google Cloud .
- REGION: Region Compute Engine yang tersedia untuk menjalankan beban kerja.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. Properti ini mengaktifkan Lightning Engine pada sesi.Properti lainnya:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime=native: Tambahkan properti ini untuk memilih runtime Native Query Execution.
- Native Query Engine:
OTHER_FLAGS_AS_NEEDED: Lihat Membuat sesi interaktif.
API
Untuk mengaktifkan Lightning Engine pada sesi, sebagai bagian dari permintaan
sessions.create Anda:
- Tetapkan RuntimeConfig.version
ke
2.3. - Tambahkan "dataproc.tier":"premium" dan "spark.dataproc.engine":"lightningEngine" ke RuntimeConfig.properties.
Lainnya RuntimeConfig.properties:
- Native Query Engine:
spark.dataproc.lightningEngine.runtime:native: Tambahkan properti ini ke RuntimeConfig.properties jika Anda ingin memilih runtime Native Query Execution.
Lihat Membuat sesi interaktif untuk menyetel kolom API template sesi lainnya.
Notebook BigQuery
Anda dapat mengaktifkan Lightning Engine saat membuat sesi di notebook PySpark BigQuery Studio.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Memverifikasi setelan Lightning Engine
Anda dapat menggunakan konsol Google Cloud , Google Cloud CLI, atau Dataproc API untuk memverifikasi setelan Lightning Engine pada workload batch, template sesi, atau sesi interaktif.
Workload batch
Untuk memverifikasi bahwa tingkatan batch disetel ke
premiumdan mesin disetel keLightning Engine:- KonsolGoogle Cloud : Di halaman Batch, lihat kolom Tingkatan dan Mesin untuk batch. Anda dapat mengklik ID Batch untuk melihat setelan ini di halaman detail batch.
- gcloud CLI: Jalankan perintah
gcloud dataproc batches describe. - API: Mengirim permintaan
batches.get.
Template sesi
Untuk memverifikasi bahwa engine disetel ke
Lightning Engineuntuk template sesi:- konsolGoogle Cloud : Di halaman Session Templates, lihat kolom Engine untuk template Anda. Anda dapat mengklik Nama template sesi untuk melihat setelan ini di halaman detail template sesi.
- gcloud CLI: Jalankan perintah
gcloud beta dataproc session-templates describe. - API: Mengirim permintaan
sessionTemplates.get.
Sesi interaktif
To the engine ditetapkan ke
Lightning Engineuntuk sesi interaktif:- Google Cloud konsol: Di halaman Sesi Interaktif, lihat kolom Mesin untuk template. Anda dapat mengklik ID Sesi Interaktif untuk melihat setelan ini di halaman detail template sesi.
- gcloud CLI: Jalankan perintah
gcloud beta dataproc sessions describe. - API: Mengirim permintaan
sessions.get.
Eksekusi Kueri Native
Eksekusi Kueri Native (NQE) adalah fitur opsional Lightning Engine yang meningkatkan performa melalui implementasi native berdasarkan Apache Gluten dan Velox yang didesain untuk hardware Google.
Runtime Eksekusi Kueri Native mencakup pengelolaan memori terpadu untuk peralihan dinamis antara memori off-heap dan on-heap tanpa memerlukan perubahan pada konfigurasi Spark yang ada. NQE mencakup dukungan yang diperluas untuk operator, fungsi, dan jenis data Spark, serta kecerdasan untuk mengidentifikasi peluang secara otomatis guna menggunakan mesin native untuk operasi pushdown yang optimal.
Mengidentifikasi workload eksekusi kueri Native
Gunakan Eksekusi Kueri Native dalam skenario berikut:
API DataFrame Spark, API Dataset Spark, dan kueri Spark SQL yang membaca data dari file Parquet dan ORC. Format file output tidak memengaruhi performa Eksekusi Kueri Native.
Beban kerja yang direkomendasikan oleh alat kualifikasi Eksekusi Kueri Native.
Eksekusi kueri native tidak direkomendasikan untuk beban kerja dengan input jenis data berikut:
- Byte: ORC dan Parquet
- Stempel waktu: ORC
- Struct, Array, Map: Parquet
Batasan Eksekusi Kueri Native
Mengaktifkan Eksekusi Kueri Native dalam skenario berikut dapat menyebabkan pengecualian, ketidakcocokan Spark, atau penggantian beban kerja ke mesin Spark default.
Pengganti
Eksekusi Kueri Native dalam eksekusi berikut dapat menyebabkan penggantian workload ke mesin eksekusi Spark, sehingga menyebabkan regresi atau kegagalan.
ANSI: Jika mode ANSI diaktifkan, eksekusi akan beralih kembali ke Spark.
Mode peka huruf besar/kecil: Eksekusi Kueri Native hanya mendukung mode default Spark yang tidak peka huruf besar/kecil. Jika mode peka huruf besar/kecil diaktifkan, hasil yang salah dapat terjadi.
Pemindaian tabel berpartisi: Eksekusi Kueri Native mendukung pemindaian tabel berpartisi hanya jika jalur berisi informasi partisi. Jika tidak, beban kerja akan kembali ke mesin eksekusi Spark.
Perilaku yang tidak kompatibel
Perilaku yang tidak kompatibel atau hasil yang salah dapat terjadi saat menggunakan eksekusi kueri Native dalam kasus berikut:
Fungsi JSON: Eksekusi Kueri Native mendukung string yang diapit tanda kutip ganda, bukan tanda kutip tunggal. Hasil yang salah terjadi dengan tanda petik tunggal. Menggunakan "*" di jalur dengan fungsi
get_json_objectakan menampilkanNULL.Konfigurasi baca Parquet:
- Eksekusi Kueri Native memperlakukan
spark.files.ignoreCorruptFilessebagai ditetapkan ke nilaifalsedefault, meskipun ditetapkan ketrue. - Eksekusi Kueri Native mengabaikan
spark.sql.parquet.datetimeRebaseModeInRead, dan hanya menampilkan konten file Parquet. Perbedaan antara kalender hibrida lama (Julian Gregorian) dan kalender Gregorian Proleptik tidak dipertimbangkan. Hasil Spark dapat berbeda.
- Eksekusi Kueri Native memperlakukan
NaN: Tidak didukung. Hasil yang tidak terduga dapat terjadi, misalnya, saat menggunakanNaNdalam perbandingan numerik.Pembacaan kolom Spark: Error fatal dapat terjadi karena vektor kolom Spark tidak kompatibel dengan Eksekusi Kueri Native.
Tumpahan: Jika partisi shuffle disetel ke angka yang besar, fitur tumpahan ke disk dapat memicu
OutOfMemoryException. Jika hal ini terjadi, mengurangi jumlah partisi dapat menghilangkan pengecualian ini.