
Ce document vous explique comment activer Lightning Engine pour accélérer les charges de travail par lot et les sessions interactives Managed Service pour Apache Spark.
Présentation
Lightning Engine est un accélérateur de requêtes hautes performances optimisé par un moteur d'optimisation multicouche qui effectue des techniques d'optimisation habituelles, telles que l'optimisation des requêtes et de l'exécution, ainsi que des optimisations sélectionnées dans la couche du système de fichiers et les connecteurs d'accès aux données.
Comme le montre l'illustration suivante, Lightning Engine accélère les performances d'exécution des requêtes Spark sur une charge de travail de type TPC-H (taille de l'ensemble de données 10 TB).
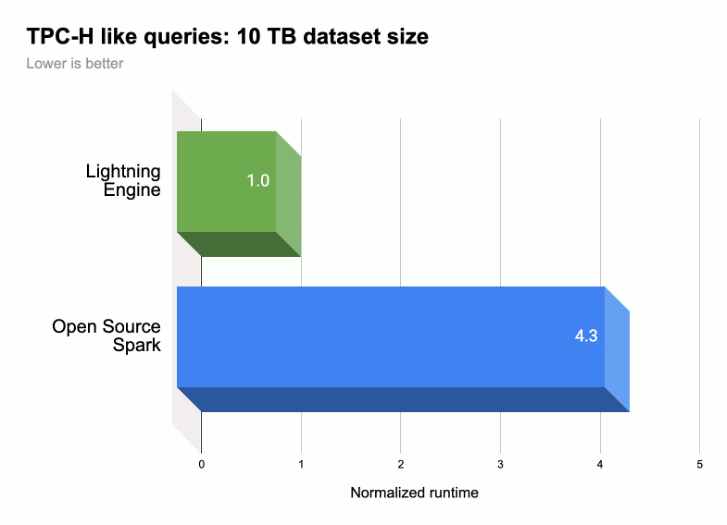
Pour en savoir plus, consultez Présentation de Lightning Engine, la nouvelle génération de performances Apache Spark.
Disponibilité de Lightning Engine
- Lightning Engine est disponible avec Managed Service pour Apache Spark version 2.3.
- Lightning Engine n'est disponible qu'avec le niveau tarifaire Premium de Managed Service pour Apache Spark.
- Charges de travail par lot : Lightning Engine est automatiquement activé pour les charges de travail par lot au niveau Premium. Aucune action n'est requise.
- Sessions interactives : Lightning Engine n'est pas activé par défaut pour les sessions interactives. Pour l'activer, consultez Activer Lightning Engine.
- Modèles de session : Lightning Engine n'est pas activé par défaut pour les modèles de session. Pour l'activer, consultez Activer Lightning Engine.
Activer Lightning Engine
Les sections suivantes vous expliquent comment activer le moteur Lightning sur une charge de travail par lot Managed Service pour Apache Spark, un modèle de session et une session interactive.
Charge de travail par lot
Activer Lightning Engine sur une charge de travail par lot
Vous pouvez utiliser la console Google Cloud , Google Cloud CLI ou l'API Dataproc pour activer Lightning Engine sur une charge de travail par lot.
Console
Utilisez la console Google Cloud pour activer Lightning Engine sur une charge de travail par lot.
Dans la console Google Cloud :
- Accédez à Managed Service pour Apache Spark > Lots.
- Cliquez sur Créer pour ouvrir la page Créer un lot.
Sélectionnez et renseignez les champs suivants :
- Conteneur :
- Version de l'environnement d'exécution : sélectionnez
2.3.
- Version de l'environnement d'exécution : sélectionnez
Configuration des niveaux :
- Sélectionnez
Premium. Cela active et coche automatiquement l'option "Activer LIGHTNING ENGINE pour améliorer les performances Spark".
Lorsque vous sélectionnez le niveau Premium, les niveaux de calcul du pilote et de l'exécuteur sont définis sur
Premium. Ces paramètres de calcul de niveau Premium définis automatiquement ne peuvent pas être remplacés pour les lots utilisant des environnements d'exécution antérieurs à3.0.Vous pouvez configurer les niveaux de disque du pilote et de l'exécuteur sur
Premiumou conserver leur valeur par défaut de niveauStandard. Si vous choisissez un niveau de disque Premium, vous devez sélectionner la taille du disque. Pour en savoir plus, consultez Propriétés d'allocation des ressources.- Sélectionnez
Propriétés : facultatif. Saisissez la paire
Key(nom de propriété) etValuesuivante si vous souhaitez sélectionner le runtime Exécution de requêtes natives :Clé Valeur spark.dataproc.lightningEngine.runtimenative
- Conteneur :
Renseignez, sélectionnez ou confirmez les autres paramètres des charges de travail par lot. Consultez Envoyer une charge de travail par lot Spark.
Cliquez sur Envoyer pour exécuter la charge de travail par lot Spark.
gcloud
Définissez les indicateurs de commande gcloud CLI gcloud dataproc batches submit spark suivants pour activer un moteur Lightning sur une charge de travail par lot.
gcloud dataproc batches submit spark \ --project=PROJECT_ID \ --region=REGION \ --version=2.3 \ --properties=dataproc.tier=premium \ OTHER_FLAGS_AS_NEEDED
Remarques :
- PROJECT_ID : ID de votre projet Google Cloud . Les ID de projet sont listés dans la section Informations sur le projet du tableau de bord de la console Google Cloud .
- REGION : Région Compute Engine disponible pour exécuter la charge de travail.
--properties=dataproc.tier=premium. La définition du niveau Premium définit automatiquement les propriétés suivantes sur la charge de travail par lot :spark.dataproc.engine=lightningEnginesélectionne Lightning Engine pour la charge de travail par lot.spark.dataproc.driver.compute.tieretspark.dataproc.executor.compute.tiersont définis surpremium(voir Propriétés d'allocation des ressources). Ces paramètres de calcul de niveau Premium définis automatiquement ne peuvent pas être remplacés pour les lots utilisant des environnements d'exécution antérieurs à3.0.
Autres propriétés
Moteur de requête natif :
spark.dataproc.lightningEngine.runtime=nativeAjoutez cette propriété si vous souhaitez sélectionner l'environnement d'exécution Exécution de requête native.Niveaux et tailles de disque : par défaut, les tailles de disque du pilote et de l'exécuteur sont définies sur les niveaux et tailles
standard. Vous pouvez ajouter des propriétés pour sélectionner les niveaux et les tailles de disquepremium(par multiples de375 GiB).
Pour en savoir plus, consultez Propriétés d'allocation des ressources.
OTHER_FLAGS_AS_NEEDED : consultez Envoyer une charge de travail par lot Spark.
API
Pour activer Lightning Engine sur une charge de travail par lot, dans votre requête batches.create :
- Définissez RuntimeConfig.version sur
2.3. Ajoutez "dataproc.tier":"premium" à RuntimeConfig.properties. La définition du niveau Premium définit automatiquement les propriétés suivantes sur la charge de travail par lot :
spark.dataproc.engine=lightningEnginesélectionne Lightning Engine pour la charge de travail par lot.spark.dataproc.driver.compute.tieretspark.dataproc.executor.compute.tiersont définis surpremium(voir Propriétés d'allocation des ressources). Ces paramètres de calcul de niveau Premium définis automatiquement ne peuvent pas être remplacés pour les lots utilisant des environnements d'exécution antérieurs à3.0.
Autre RuntimeConfig.properties :
Moteur de requête natif :
spark.dataproc.lightningEngine.runtime:native. Ajoutez cette propriété si vous souhaitez sélectionner l'environnement d'exécution Native Query Execution.Niveaux et tailles de disque : par défaut, les tailles de disque du pilote et de l'exécuteur sont définies sur les niveaux et tailles
standard. Vous pouvez ajouter des propriétés pour sélectionner des niveaux et des taillespremium(par multiples de375 GiB).
Pour en savoir plus, consultez Propriétés d'allocation des ressources.
Consultez Envoyer une charge de travail par lot Spark pour définir d'autres champs de l'API de charge de travail par lot.
Modèle de session
Activer Lightning Engine sur un modèle de session
Vous pouvez utiliser la console Google Cloud , Google Cloud CLI ou l'API Dataproc pour activer Lightning Engine sur un modèle de session pour une session Jupyter ou Spark Connect.
Console
Utilisez la console Google Cloud pour activer Lightning Engine sur une charge de travail par lot.
Dans la console Google Cloud :
- Accédez aux modèles de session Managed Service pour Apache Spark.
- Cliquez sur Créer pour ouvrir la page Créer un modèle de session.
Sélectionnez et renseignez les champs suivants :
- Informations sur le modèle de session :
- Sélectionnez "Activer Lightning Engine pour améliorer les performances Spark".
- Configuration de l'exécution :
- Version de l'environnement d'exécution : sélectionnez
2.3.
- Version de l'environnement d'exécution : sélectionnez
Propriétés : Saisissez les paires
Key(nom de propriété) etValuesuivantes pour sélectionner le niveau Premium :Clé Valeur dataproc.tierpremium spark.dataproc.enginelightningEngine Facultatif : Saisissez la paire
Key(nom de propriété) etValuesuivante pour sélectionner le runtime Exécution de requêtes natives :Clé Valeur spark.dataproc.lightningEngine.runtimenative
- Informations sur le modèle de session :
Renseignez, sélectionnez ou confirmez les autres paramètres du modèle de session. Consultez Créer un modèle de session.
Cliquez sur Envoyer pour créer le modèle de session.
gcloud
Vous ne pouvez pas créer directement de modèle de session Managed Service pour Apache Spark à l'aide de la gcloud CLI. Vous pouvez plutôt utiliser la commande gcloud beta dataproc session-templates import pour importer un modèle de session existant, le modifier pour activer le moteur Lightning et, éventuellement, le runtime Native Query, puis exporter le modèle modifié à l'aide de la commande gcloud beta dataproc session-templates export.
API
Pour activer Lightning Engine sur un modèle de session, dans votre requête sessionTemplates.create :
- Définissez RuntimeConfig.version sur
2.3. - Ajoutez "dataproc.tier":"premium" et "spark.dataproc.engine":"lightningEngine" à RuntimeConfig.properties.
Autre RuntimeConfig.properties :
- Moteur de requête natif :
spark.dataproc.lightningEngine.runtime:nativeAjoutez cette propriété à RuntimeConfig.properties pour sélectionner l'environnement d'exécution Exécution de requête native.
Consultez Créer un modèle de session pour définir d'autres champs de l'API de modèle de session.
Session interactive
Activer Lightning Engine dans une session interactive
Vous pouvez utiliser Google Cloud CLI ou l'API Dataproc pour activer Lightning Engine dans une session interactive Managed Service pour Apache Spark. Vous pouvez également activer Lightning Engine dans une session interactive d'un notebook BigQuery Studio.
gcloud
Définissez les indicateurs de commande gcloud beta dataproc sessions create spark de la gcloud CLI suivante pour activer Lightning Engine dans une session interactive.
gcloud beta dataproc sessions create spark \ --project=PROJECT_ID \ --location=REGION \ --version=2.3 \ --properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine \ OTHER_FLAGS_AS_NEEDED
Remarques :
- PROJECT_ID : ID de votre projet Google Cloud . Les ID de projet sont listés dans la section Informations sur le projet du tableau de bord de la console Google Cloud .
- REGION : Région Compute Engine disponible pour exécuter la charge de travail.
--properties=dataproc.tier=premium,spark.dataproc.engine=lightningEngine. Ces propriétés activent Lightning Engine dans la session.Autres propriétés :
- Moteur de requête natif :
spark.dataproc.lightningEngine.runtime=native: Ajoutez cette propriété pour sélectionner l'environnement d'exécution Exécution de requête native.
- Moteur de requête natif :
OTHER_FLAGS_AS_NEEDED : consultez Créer une session interactive.
API
Pour activer Lightning Engine sur une session, dans votre requête sessions.create :
- Définissez RuntimeConfig.version sur
2.3. - Ajoutez "dataproc.tier":"premium" et "spark.dataproc.engine":"lightningEngine" à RuntimeConfig.properties.
Autre RuntimeConfig.properties :
- Moteur de requête natif :
spark.dataproc.lightningEngine.runtime:nativeAjoutez cette propriété à RuntimeConfig.properties si vous souhaitez sélectionner l'environnement d'exécution Exécution de requête native.
Consultez Créer une session interactive pour définir d'autres champs de l'API de modèle de session.
Notebook BigQuery
Vous pouvez activer Lightning Engine lorsque vous créez une session dans un notebook PySpark BigQuery Studio.
from google.cloud.dataproc_spark_connect import DataprocSparkSession
from google.cloud.dataproc_v1 import Session
session = Session()
# Enable Lightning Engine.
session.runtime_config.properties["version"] = "2.3"
session.runtime_config.properties["dataproc.tier"] = "premium"
session.runtime_config.properties["spark.dataproc.engine"] = "lightningEngine"
# Enable THE Native Query Execution runtime.
session.runtime_config.properties["spark.dataproc.lightningEngine.runtime"] = "native"
# Create the Spark session.
spark = (
DataprocSparkSession.builder
.appName("APP_NAME")
.dataprocSessionConfig(session)
.getOrCreate())
# Add Spark application code here:
Vérifier les paramètres du moteur Lightning
Vous pouvez utiliser la console Google Cloud , la Google Cloud CLI ou l'API Dataproc pour vérifier les paramètres Lightning Engine sur une charge de travail par lot, un modèle de session ou une session interactive.
Charge de travail par lot
Pour vérifier que le niveau du lot est défini sur
premiumet que le moteur est défini surLightning Engine:- ConsoleGoogle Cloud : sur la page Lots, consultez les colonnes Niveau et Moteur pour le lot. Vous pouvez également cliquer sur l'ID de lot pour afficher ces paramètres sur la page d'informations sur le lot.
- gcloud CLI : exécutez la commande
gcloud dataproc batches describe. - API : envoyez une requête
batches.get.
Modèle de session
Pour vérifier que engine est défini sur
Lightning Enginepour un modèle de session :- ConsoleGoogle Cloud : sur la page Modèles de session, consultez la colonne Moteur pour votre modèle. Vous pouvez également cliquer sur le nom du modèle de session pour afficher ce paramètre sur la page d'informations du modèle de session.
- gcloud CLI : exécutez la commande
gcloud beta dataproc session-templates describe. - API : envoyez une requête
sessionTemplates.get.
Session interactive
engine est défini sur
Lightning Enginepour une session interactive :- ConsoleGoogle Cloud : sur la page Sessions interactives, consultez la colonne Moteur pour le modèle. Vous pouvez également cliquer sur l'ID de session interactive pour afficher ce paramètre sur la page d'informations du modèle de session.
- gcloud CLI : exécutez la commande
gcloud beta dataproc sessions describe. - API : envoyez une requête
sessions.get.
Exécution de requêtes natives
L'exécution native des requêtes (NQE, Native Query Execution) est une fonctionnalité optionnelle de Lightning Engine qui améliore les performances grâce à une implémentation native basée sur Apache Gluten et Velox, conçue pour le matériel Google.
L'environnement d'exécution de l'exécution de requêtes natives inclut une gestion unifiée de la mémoire pour le basculement dynamique entre la mémoire hors tas et la mémoire dans le tas, sans nécessiter de modifications des configurations Spark existantes. NQE offre une compatibilité étendue avec les opérateurs, les fonctions et les types de données Spark, ainsi qu'une intelligence permettant d'identifier automatiquement les opportunités d'utiliser le moteur natif pour des opérations de pushdown optimales.
Identifier les charges de travail d'exécution des requêtes natives
Utilisez l'exécution de requêtes natives dans les scénarios suivants :
API Spark DataFrame, API Spark Dataset et requêtes Spark SQL qui lisent les données des fichiers Parquet et ORC. Le format du fichier de sortie n'a aucune incidence sur les performances d'exécution des requêtes natives.
Charges de travail recommandées par l'outil de qualification de l'exécution des requêtes natives.
L'exécution de requêtes natives n'est pas recommandée pour les charges de travail avec des entrées des types de données suivants :
- Octet : ORC et Parquet
- Code temporel : ORC
- Struct, Array, Map : Parquet
Limites de l'exécution des requêtes natives
L'activation de l'exécution de requêtes natives dans les scénarios suivants peut entraîner des exceptions, des incompatibilités Spark ou le retour de la charge de travail au moteur Spark par défaut.
Actions de remplacement
L'exécution de requêtes natives peut entraîner le basculement de la charge de travail vers le moteur d'exécution Spark, ce qui peut entraîner une régression ou un échec.
ANSI : si le mode ANSI est activé, l'exécution revient à Spark.
Mode sensible à la casse : l'exécution de requêtes natives n'est compatible qu'avec le mode insensible à la casse par défaut de Spark. Si le mode sensible à la casse est activé, des résultats incorrects peuvent s'afficher.
Analyse de table partitionnée : l'exécution de requêtes natives n'est compatible avec l'analyse de table partitionnée que lorsque le chemin d'accès contient les informations de partition. Sinon, la charge de travail revient au moteur d'exécution Spark.
Comportement incompatible
Un comportement incompatible ou des résultats incorrects peuvent se produire lors de l'exécution de requêtes natives dans les cas suivants :
Fonctions JSON : l'exécution de requêtes natives accepte les chaînes entourées de guillemets doubles, et non de guillemets simples. Des résultats incorrects s'affichent avec les guillemets simples. L'utilisation de "*" dans le chemin d'accès avec la fonction
get_json_objectrenvoieNULL.Configuration de la lecture Parquet :
- L'exécution de requêtes natives traite
spark.files.ignoreCorruptFilescomme défini sur la valeur par défautfalse, même lorsqu'il est défini surtrue. - L'exécution de requêtes natives ignore
spark.sql.parquet.datetimeRebaseModeInReadet ne renvoie que le contenu du fichier Parquet. Les différences entre l'ancien calendrier hybride (julien-grégorien) et le calendrier grégorien proleptique ne sont pas prises en compte. Les résultats Spark peuvent varier.
- L'exécution de requêtes natives traite
NaN: non compatible. Des résultats inattendus peuvent se produire, par exemple, lorsque vous utilisezNaNdans une comparaison numérique.Lecture de colonnes Spark : une erreur fatale peut se produire, car le vecteur de colonnes Spark est incompatible avec l'exécution de requêtes natives.
Débordement : lorsque les partitions de brassage sont définies sur un grand nombre, la fonctionnalité de débordement sur disque peut déclencher un
OutOfMemoryException. Si cela se produit, vous pouvez éliminer cette exception en réduisant le nombre de partitions.