
A migração gerenciada é um recurso automatizado que ajuda a migrar dados de um metastore do Hive autogerenciado para um serviço Metastore do Dataproc sem tempo de inatividade significativo (também conhecido como dia da bandeira).
Arquitetura de migração gerenciada
O diagrama a seguir mostra a arquitetura de alto nível de uma migração gerenciada.
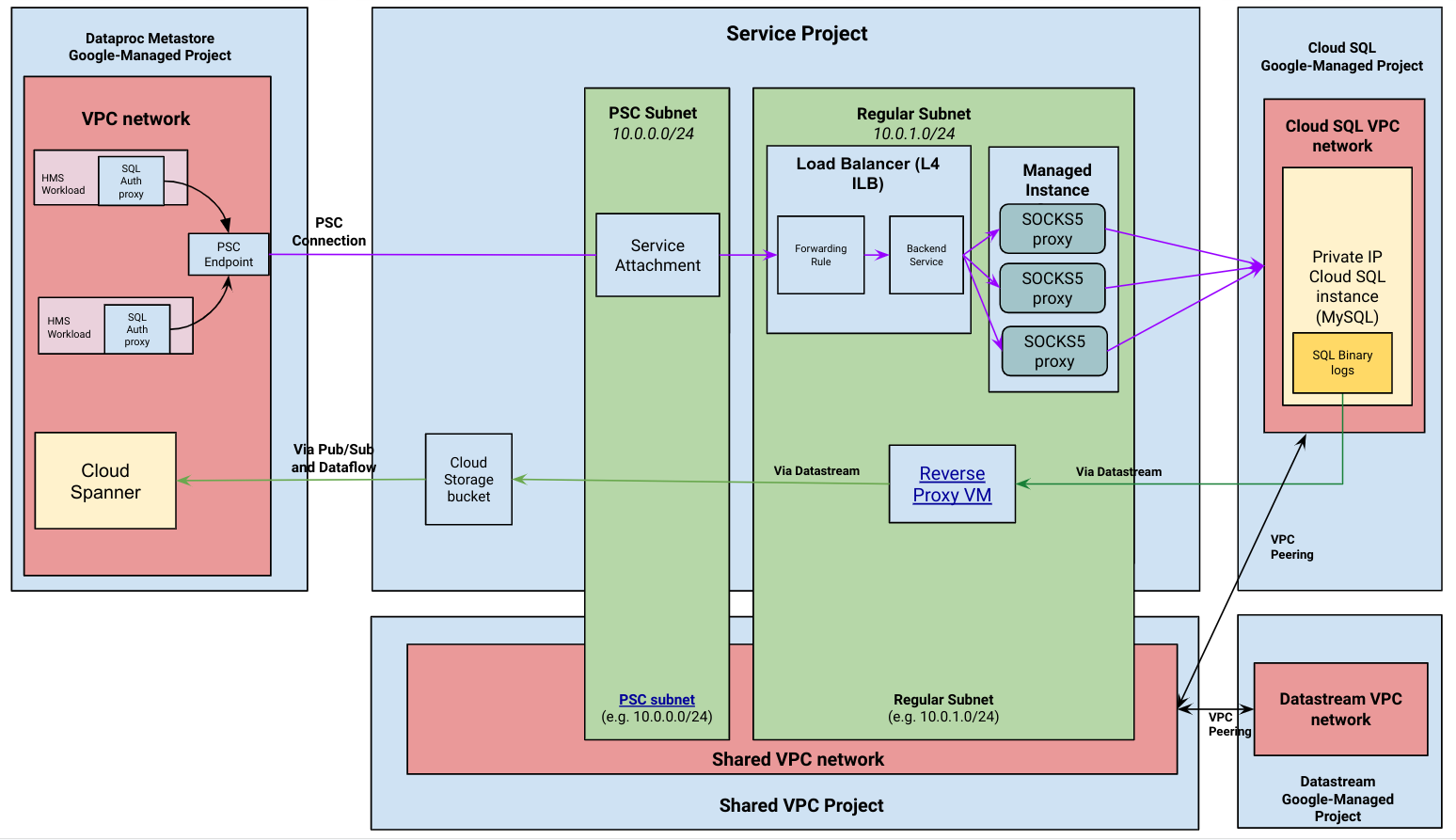
Fluxo de migração gerenciada
Para concluir uma migração gerenciada, seu serviço passa por dois processos de migração: iniciar migração e concluir migração. É possível cancelar uma migração a qualquer momento com o processo cancelar migração. Há também vários comandos operacionais que podem ser executados, mas não são necessários para concluir uma migração. Por exemplo, list migrations ou delete migrations.
À medida que seu serviço passa por esse processo, ele também passa por vários estados de migração e fases de migração. Esses estados e fases representam os processos que estão ocorrendo em segundo plano. Por exemplo, o estado MIGRATING
indica que seu serviço está transferindo dados ativamente do banco de dados do
Cloud SQL para o metastore do Dataproc.
Iniciar migração
O Dataproc Metastore estabelece uma conexão com sua instância do Cloud SQL de IP particular. Depois que a conexão é feita, o metastore do Dataproc usa a instância do Cloud SQL como o banco de dados de back-end do metastore do Hive (HMS, na sigla em inglês). Ele também permanece como a fonte de verdade dos seus dados durante a migração. As leituras e gravações de metadados ainda ocorrem no Cloud SQL quando a migração está ativa.
Um pipeline de captura de dados alterados (CDC) é iniciado. Esse pipeline mantém a instância do Cloud SQL no seu projeto e o Spanner no projeto gerenciado do Dataproc Metastore sincronizados. Isso significa que todas as mudanças no banco de dados do HMS na instância do Cloud SQL são capturadas pelo Datastream e gravadas no banco de dados do Dataproc Metastore Spanner.
Depois que o processo de início da migração for concluído, você poderá começar a rotear cargas de trabalho de dados para o metastore do Dataproc. Neste momento, o Cloud SQL ainda é a fonte de verdade dos seus dados.
Concluir a migração
Depois de mover as cargas de trabalho para o Metastore do Dataproc, você pode concluir a migração. Quando um processo de migração completa é chamado, acontece o seguinte:
- O Dataproc Metastore entra em um modo somente leitura até que o processo de migração completa seja concluído.
- O stream de CDC transfere todos os dados em trânsito para o metastore do Dataproc.
- O Dataproc Metastore se conecta ao Spanner e se desconecta do Cloud SQL. O metastore do Dataproc agora atua como a fonte de verdade para seus dados do HMS.
Considerações sobre proxy e pipeline
Proxies
O Dataproc Metastore usa um proxy de autenticação do Cloud SQL encadeado a um proxy SOCKS5 para se conectar à instância do Cloud SQL de IP particular. Os servidores proxy SOCKS5 são expostos por um anexo de serviço, conforme mostrado no diagrama de arquitetura anterior.
Cada migração requer uma sub-rede NAT dedicada. Isso ocorre porque uma sub-rede NAT não pode ter mais de um anexo de serviço.
Para evitar problemas de latência entre regiões, forneça sub-redes que estejam na mesma região da instância do Cloud SQL para hospedar o proxy SOCKS5. Por exemplo,
proxy_subnetenat_subnet.
Pipeline de captura de dados de alterações
O pipeline de captura de dados alterados usa o peering de VPC para estabelecer uma conexão entre o Datastream e o Cloud SQL de IP particular.
Para cada migração, uma nova conexão particular é criada e uma nova conexão de peering é estabelecida.
A rede VPC que hospeda a instância do Cloud SQL tem tantas conexões de peering quanto migrações ativas. Verifique se a rede VPC tem capacidade para hospedar todas as conexões de peering necessárias.