
여러 스토리지 시스템에 데이터를 저장하면 보안이 분산되어 관리가 어려워질 수 있습니다.
Google Cloud 스토리지의 Apache Iceberg와 같은 개방형 형식으로 저장하더라도 금융 기록과 같은 민감한 정보가 보호되도록 해야 합니다. BigQuery SQL 및 Apache Spark와 같은 다양한 쿼리 엔진에 적용하려면 이러한 보호 조치가 필요합니다.
이 튜토리얼에서는 이러한 문제를 해결하기 위해 안전한 데이터 레이크하우스를 빌드합니다. 스크립트를 사용하여 보안 정책을 정의하고 Knowledge Catalog (이전 명칭: Dataplex Universal Catalog)와 Lakehouse for Apache Iceberg가 함께 작동하여 다양한 쿼리 엔진에서 정책을 적용하는 것을 확인할 수 있습니다.
아키텍처 개요
Apache Iceberg와 같은 개방형 테이블 형식에 세분화된 액세스 제어를 설정하려면 엄격한 통합 보안 아키텍처를 만들어야 합니다.
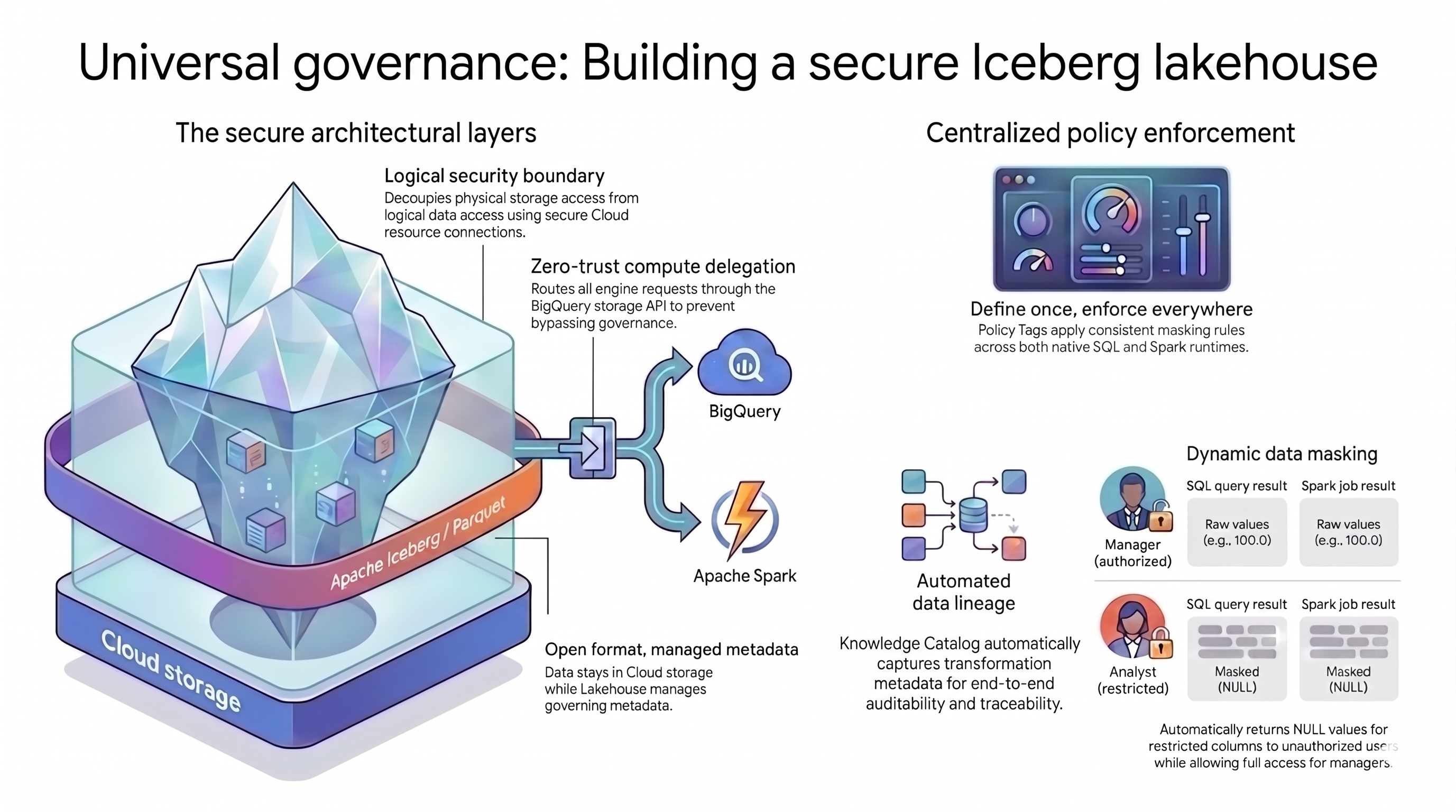
이 튜토리얼에서 사용하는 레이크하우스 패턴은 이 문제를 해결하기 위해 두 가지 주요 개념을 사용합니다.
- 보안 아키텍처 레이어: 사용자 또는 쿼리 엔진이 Cloud Storage 버킷에 직접 액세스하도록 허용하는 대신 다음 속성을 기반으로 보안 레이어 기반을 빌드합니다.
- 관리형 메타데이터가 있는 개방형 형식: 데이터는 Cloud Storage 내에 개방형 Apache Iceberg (Parquet) 형식으로 유지되고 Lakehouse for Apache Iceberg는 테이블 메타데이터를 관리합니다.
- 논리적 보안 경계: 보안 Cloud 리소스 연결을 사용하여 스토리지 권한을 데이터 쿼리에서 분리합니다. 최종 사용자에게 파일에 대한 직접 액세스 권한을 부여하지 않습니다.
- 컴퓨팅 위임: 쿼리 엔진이 규칙을 우회하지 못하도록 BigQuery Storage API를 통해 모든 데이터 요청을 라우팅합니다.
- 중앙 집중식 정책 시행: 보안 기반이 마련되면 Knowledge Catalog가 아키텍처의 단일 컨트롤 플레인 역할을 하여 규칙을 보편적으로 적용합니다.
- 한 번 정의하고 어디서나 적용: Knowledge Catalog에서 정책 태그를 한 번만 정의하면 플랫폼에서 지원되는 모든 쿼리 엔진에 일관된 마스킹 규칙이 적용됩니다.
- 동적 데이터 마스킹: 시스템이 쿼리 중에 사용자 ID를 평가합니다. 승인된 사용자는 원시 값을 볼 수 있는 반면 제한된 사용자는 모든 쿼리 엔진에서
NULL출력을 받습니다. - 자동 데이터 계보: Knowledge Catalog는 데이터 변환을 자동으로 추적하여 맞춤 로깅 코드 없이 감사 추적을 만듭니다.
목표
- BigQuery에서 관리하는 Apache Iceberg 테이블을 만듭니다. Lakehouse가 Iceberg 메타데이터를 관리합니다.
- 정책 태그를 사용하여 민감한 열을 마스킹하고 보호하는 중앙 보안 규칙을 설정합니다.
- Cloud 리소스 연결을 사용하여 물리적 스토리지 권한과 논리적 데이터 쿼리를 분리합니다.
- 외부 엔진이 보안 규칙을 우회할 수 없도록 Managed Service for Apache Spark를 통해 쿼리를 안전하게 라우팅합니다.
- 데이터 계보를 사용하여 데이터의 대화형 지도를 살펴봅니다.
시작하기 전에
시작하기 전에 다음을 수행합니다.
- 이 튜토리얼의 Google Cloud 프로젝트를 선택합니다.
- 프로젝트에 결제가 사용 설정되어 있는지 확인합니다.
개발 환경 준비
이 튜토리얼에서는 클라우드에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다.
Google Cloud 콘솔의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
프로젝트 변수를 설정합니다.
export PROJECT_ID=$(gcloud config get-value project) export REGION="us-central1" export ICEBERG_BUCKET="iceberg-retail-demo-${PROJECT_ID}" export DATASET_ID="lakehouse_retail_demo" export CONN_NAME="iceberg-bq-conn-demo"소매 분석가와 소매 관리자라는 두 사용자 페르소나의 변수를 정의합니다.
export USER_ANALYST="retail-analyst-demo" export EMAIL_ANALYST="${USER_ANALYST}@${PROJECT_ID}.iam.gserviceaccount.com" export USER_MANAGER="retail-manager-demo" export EMAIL_MANAGER="${USER_MANAGER}@${PROJECT_ID}.iam.gserviceaccount.com" export CURRENT_USER=$(gcloud config get-value account)필요한 Google Cloud API를 사용 설정합니다.
gcloud services enable \ bigquery.googleapis.com \ bigqueryconnection.googleapis.com \ datacatalog.googleapis.com \ bigquerydatapolicy.googleapis.com \ datalineage.googleapis.com \ dataplex.googleapis.com \ dataproc.googleapis.com \ storage-component.googleapis.com
튜토리얼 소스 코드 다운로드
Google Cloud DevRel 저장소에서 이 가이드의 Python 스크립트를 다운로드합니다.
# Shallow clone without full history
git clone --depth 1 --filter=blob:none --sparse https://github.com/GoogleCloudPlatform/devrel-demos.git
cd devrel-demos
# Download only the specific folder
git sparse-checkout set data-analytics/governed-lakehouse
cd data-analytics/governed-lakehouse
스토리지 버킷 만들기
Iceberg 테이블 파일을 저장할 새 버킷을 만듭니다.
gcloud storage buckets create gs://${ICEBERG_BUCKET} --location=${REGION}
ID 및 보안 준비
이 단계에서는 Cloud 리소스 연결을 만들어 컴퓨팅 위임을 설정합니다. 이 연결은 BigQuery가 Iceberg 파일을 관리하고 읽는 데 사용하는 보안 위임 ID 역할을 합니다. 이렇게 하면 개별 사용자가 Cloud Storage 버킷에 직접 액세스할 수 없습니다.
다음 명령어를 실행하여 연결을 만들고, 자동 생성된 서비스 계정을 가져오고, 해당 계정에 Iceberg 데이터를 관리하는 데 필요한 권한을 부여합니다.
# Create the Cloud resource connection
bq mk --connection \
--connection_type=CLOUD_RESOURCE \
--location=${REGION} \
${CONN_NAME}
# Retrieve the connection's automatically generated Service Account
export BQ_CONN_SVC_ACCT=$(bq show --format=json --connection ${REGION}.${CONN_NAME} \
| jq -r '.cloudResource.serviceAccountId')
# Grant Storage Object Admin to the connection for the Iceberg bucket
gcloud storage buckets add-iam-policy-binding gs://${ICEBERG_BUCKET} \
--member="serviceAccount:${BQ_CONN_SVC_ACCT}" \
--role="roles/storage.objectAdmin" \
--quiet
분석가와 관리자라는 두 페르소나의 서비스 계정을 만듭니다. 다음 명령어는 이러한 서비스 계정을 설정하고, 현재 사용자가 테스트를 위해 서비스 계정을 가장하도록 허용하며, 쿼리를 실행하고 데이터를 볼 수 있는 특정 역할을 부여합니다.
echo "Creating Service Accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
gcloud iam service-accounts create ${USER} --display-name="Lakehouse ${USER}"
done
echo "⏳ Waiting 15 seconds for rules to apply..."
sleep 15
echo "Granting roles to service accounts..."
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Allow Cloud Shell to impersonate them for testing
gcloud iam service-accounts add-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet
# Allow logical viewing of the catalog, querying, and running Dataproc jobs
for ROLE in "roles/datacatalog.viewer" "roles/bigquery.dataViewer" "roles/bigquery.user" "roles/bigquery.connectionUser" "roles/serviceusage.serviceUsageConsumer" "roles/dataproc.worker"; do
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL}" \
--role="${ROLE}" \
--quiet
done
done
# Grant the Manager data creation rights
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${EMAIL_MANAGER}" \
--role="roles/bigquery.dataEditor" \
--quiet
echo "✅ Identity and Security setup completed!"
Apache Iceberg 테이블 만들기
BigQuery SQL 엔진을 사용하여 Apache Iceberg 테이블을 만듭니다. BigQuery로 만들기 명령어를 실행하지만 레이크하우스는 테이블 메타데이터를 저장하고 Cloud Storage에서 기본 Parquet 파일을 보호하는 관리 레이어 역할을 합니다.
표를 만든 후 빠른 변환을 실행하여 Knowledge Catalog가 보안을 처리하고 데이터의 여정을 자동으로 추적하는 방법을 확인합니다.
BigQuery 데이터 세트 만들기
먼저 테이블을 그룹화할 BigQuery 데이터 세트를 만듭니다.
echo "Creating BigQuery Dataset..."
bq mk --location=${REGION} --dataset ${PROJECT_ID}:${DATASET_ID}
Iceberg 테이블 만들기
다음 명령어를 실행하여 인벤토리 및 거래 테이블을 만듭니다.
echo "Creating Iceberg tables..."
# Inventory table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.inventory\` (
product_id INT64,
product_name STRING,
stock_count INT64
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/inventory/'
);"
# Transactions table
bq query --use_legacy_sql=false \
"CREATE OR REPLACE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions\` (
id INT64,
item STRING,
amount FLOAT64,
transaction_date DATE
)
WITH CONNECTION \`${REGION}.${CONN_NAME}\`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://${ICEBERG_BUCKET}/transactions/'
);"
샘플 데이터 삽입
테이블에 샘플 데이터를 삽입합니다.
echo "Inserting data into Iceberg tables..."
# Insert into Inventory table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.inventory\` (product_id, product_name, stock_count)
VALUES (101, 'Widget A', 500), (102, 'Widget B', 250), (103, 'Widget C', 800);"
# Insert into Transactions table
bq query --use_legacy_sql=false \
"INSERT INTO \`${PROJECT_ID}.${DATASET_ID}.transactions\` (id, item, amount, transaction_date)
VALUES
(1, 'Widget A', 100.0, DATE '2024-01-01'),
(2, 'Widget B', 150.0, DATE '2024-01-02'),
(3, 'Widget C', 50.0, DATE '2024-01-03');"
이제 원시 샘플 데이터가 포함된 Iceberg 테이블이 두 개 있습니다. 레이크하우스는 메타데이터를 관리하지만 실제 Parquet 파일은 Cloud Storage 버킷에 있습니다.
자동 계보를 위한 데이터 변환
원시 거래를 일일 판매 요약으로 집계합니다. 이 변환은 새 테이블을 만들고 Knowledge Catalog에서 데이터의 여정을 자동으로 매핑하는 데 사용하는 메타데이터를 생성합니다.
echo "Creating transactions summary table..."
bq query --use_legacy_sql=false \
"CREATE TABLE \`${PROJECT_ID}.${DATASET_ID}.transactions_summary\` AS
SELECT transaction_date, SUM(amount) as total_sales, COUNT(id) as transaction_count
FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`
GROUP BY transaction_date;"
Python을 사용하여 정책 정의
프로덕션 환경에서 보안 규칙을 코드로 작성하면 (코드형 인프라) 정책을 반복 가능하고 버전 관리 가능하며 유지관리하기가 더 쉬워집니다. 이 섹션에서는 Google Cloud Python SDK를 사용하여 거버넌스 규칙을 자동으로 정의하고 적용합니다.
Python 가상 환경 준비
종속 항목을 관리하고 거버넌스 스크립트가 안정적으로 실행되도록 격리된 Python 가상 환경을 설정합니다.
# Create and activate a virtual environment
python3 -m venv lakehouse_env
source lakehouse_env/bin/activate
# Install required Knowledge Catalog and BigQuery governance libraries
pip install google-cloud-datacatalog google-cloud-bigquery-datapolicies google-cloud-bigquery --quiet
echo "✅ Python environment is ready!"
보안 분류 및 태그 정의
보안 규칙의 기반을 구축하는 것부터 시작하세요. 이 단계에서는 컨테이너 역할을 하는 분류와 민감한 정보의 특정 보안 라벨 역할을 하는 정책 태그를 만듭니다.
스크립트를 실행하여 리소스를 만듭니다.
python 1_create_taxonomy.py
1_create_taxonomy.py를 검토하여 핵심 로직을 확인합니다.
# Create Taxonomy with Fine-Grained Access Control enabled
taxonomy = datacatalog_v1.Taxonomy(
display_name="BusinessCritical",
activated_policy_types=[datacatalog_v1.Taxonomy.PolicyType.FINE_GRAINED_ACCESS_CONTROL]
)
created_taxonomy = client.create_taxonomy(parent=parent, taxonomy=taxonomy)
# Create Policy Tag inside the Taxonomy
policy_tag = datacatalog_v1.PolicyTag(display_name="RestrictedFinancial")
created_policy_tag = client.create_policy_tag(parent=created_taxonomy.name, policy_tag=policy_tag)
FINE_GRAINED_ACCESS_CONTROL 정책 유형을 명시적으로 설정하면 표준 메타데이터 태그가 엄격한 기본 거부 보안 경계로 변환됩니다. 이 태그가 있는 열은 기본적으로 모든 사용자의 액세스를 거부합니다.
동적 데이터 마스킹 정책 만들기
이제 권한이 없는 사용자가 태그가 지정된 열을 쿼리할 때 발생하는 상황을 정의합니다. 분석가 페르소나의 민감한 값을 NULL로 자동 대체하는 데이터 마스킹 정책을 만듭니다.
스크립트를 실행하여 마스킹 규칙을 구성합니다.
python 2_create_masking.py
2_create_masking.py 내에서 스크립트는 생성한 정책 태그의 ID를 조회하고 Analyst 서비스 계정에 데이터 정책을 적용합니다.
# Define a Masking Policy that always returns NULL
data_policy = bigquery_datapolicies_v1.DataPolicy(
data_policy_id="mask_financial_null",
policy_tag=policy_tag_id,
data_policy_type=bigquery_datapolicies_v1.DataPolicy.DataPolicyType.DATA_MASKING_POLICY,
data_masking_policy=bigquery_datapolicies_v1.DataMaskingPolicy(
predefined_expression=bigquery_datapolicies_v1.DataMaskingPolicy.PredefinedExpression.ALWAYS_NULL
)
)
# ... (Policy creation code) ...
# Bind the Masked Reader role to the Analyst
iam_policy.bindings.add(
role="roles/bigquerydatapolicy.maskedReader",
members=[f"serviceAccount:{analyst_email}"]
)
데이터에 대한 액세스 권한 부여
기본적으로 거부 설정으로 인해 태그가 지정된 열을 읽을 수 있는 사용자가 없습니다. 권한이 있는 사용자에게 명시적으로 액세스 권한을 부여해야 합니다. 관리자 페르소나와 내 계정에 세분화된 리더 역할을 부여합니다. 이를 통해 이러한 특정 사용자는 마스킹 규칙을 우회하고 마스킹되지 않은 데이터를 읽을 수 있습니다.
스크립트를 실행하여 액세스 권한을 부여합니다.
python 3_grant_access.py
3_grant_access.py 내에서 스크립트는 정책 태그의 IAM 정책을 수정합니다.
# Grant original data read access
iam_policy.bindings.add(
role="roles/datacatalog.categoryFineGrainedReader",
members=[f"serviceAccount:{manager_email}", f"user:{current_user}"]
)
client.set_iam_policy(request=iam_policy_pb2.SetIamPolicyRequest(resource=policy_tag_id, policy=iam_policy))
테이블 스키마에 보안 태그 연결
마지막으로 논리 규칙을 실제 데이터에 연결할 수 있습니다. Iceberg 테이블 스키마를 업데이트하여 정책 태그를 amount 열에 직접 연결합니다. 이렇게 하면 레이크하우스가 버킷의 Iceberg 테이블 파일에 보호를 즉시 적용합니다.
스크립트를 실행하여 정책 태그를 연결합니다.
python 4_attach_tag.py
4_attach_tag.py를 검토하세요. 스크립트는 BigQuery 테이블 스키마를 가져오고, 필드를 반복하고, amount 열에만 태그를 연결합니다.
new_schema =[]
for field in table.schema:
if field.name == 'amount':
# Wrap the Policy Tag ID and attach it to the column
policy_tags_list = bigquery.PolicyTagList(names=[policy_tag_id])
new_field = bigquery.SchemaField(
name=field.name, field_type=field.field_type, mode=field.mode,
description=field.description, policy_tags=policy_tags_list
)
new_schema.append(new_field)
else:
new_schema.append(field)
# Update the table schema in BigQuery
table.schema = new_schema
client.update_table(table, ["schema"])
보안 정책 확인
몇 가지 테스트 쿼리를 실행하여 권한이 예상대로 작동하는지 확인합니다. 레이크하우스가 쿼리 엔진을 전환할 때 동일한 보안 정책을 적용하는지 증명하려면 BigQuery와 Apache Spark를 모두 사용하여 이러한 테스트를 실행합니다.
BigQuery SQL로 테스트
BigQuery에서 직접 정책을 확인하세요. 마스킹 규칙과 권한이 활성 상태인지 가장 빠르게 확인할 수 있는 방법입니다.
관리자로 확인
관리자 페르소나에는 권한이 있는 세분화된 권한의 리더 액세스 권한이 있습니다. amount 열의 값을 비롯한 모든 세부정보가 표에 표시됩니다.
# Impersonate the Manager
gcloud config set auth/impersonate_service_account ${EMAIL_MANAGER}
# Query the transactions table
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
관리자에게 세분화된 리더 역할이 있으므로 쿼리에 원시 금액 값이 표시됩니다.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | 100.0 | 2024-01-01 |
| 3 | Widget C | 50.0 | 2024-01-03 |
| 2 | Widget B | 150.0 | 2024-01-02 |
+----+----------+--------+------------------+
분석가로 확인
분석가 페르소나로 전환하고 동일한 쿼리를 실행합니다.
gcloud config set auth/impersonate_service_account ${EMAIL_ANALYST}
bq query --use_legacy_sql=false "SELECT * FROM \`${PROJECT_ID}.${DATASET_ID}.transactions\`"
동일한 쿼리를 실행하더라도 Knowledge Catalog는 amount 열의 민감한 값을 마스킹합니다.
+----+----------+--------+------------------+
| id | item | amount | transaction_date |
+----+----------+--------+------------------+
| 1 | Widget A | NULL | 2024-01-01 |
| 3 | Widget C | NULL | 2024-01-03 |
| 2 | Widget B | NULL | 2024-01-02 |
+----+----------+--------+------------------+
계정으로 돌아가기
Cloud Shell 인증 상태를 정리하여 관리자 사용자로 돌아갑니다.
gcloud config unset auth/impersonate_service_account
Apache Spark로 테스트
사용자가 Cloud Storage의 데이터 파일로 바로 이동하면 보안이 깨지는 경우가 많습니다. 데이터 과학자가 Apache Spark를 사용하여 Iceberg 테이블 파일을 직접 읽는 경우 Cloud Storage는 버킷 수준 권한만 이해하므로 일반적으로 규칙을 우회합니다.
이를 방지하려면 컴퓨팅 위임을 사용하세요. Spark-BigQuery 커넥터를 사용하면 BigQuery Storage API를 통해 모든 Spark 요청을 라우팅하는 보안 브리지를 만들 수 있습니다. 이렇게 하면 데이터가 Spark 클러스터에 도달하기 전에 Knowledge Catalog에서 권한을 확인하고 마스킹 규칙을 적용합니다.
Managed Service for Apache Spark가 액세스할 수 있도록 Cloud Storage 버킷에 read_transactions.py 스크립트를 업로드합니다.
# Upload script to Cloud Storage
gsutil cp read_transactions.py gs://${ICEBERG_BUCKET}/scripts/read_transactions.py
업로드한 스크립트의 핵심 로직을 검토합니다.
# Reading data via Compute Delegation (Knowledge Catalog policies are applied dynamically here)
df = spark.read \
.format("bigquery") \
.option("table", f"{project_id}.{dataset_id}.{table_name}") \
.load()
print("\n=== 📊 Data Preview ===")
df.show(truncate=False)
스크립트가 Spark를 Iceberg 파일의 gs:// 경로로 안내하지 않습니다. .format("bigquery")를 지정하면 BigQuery Storage API가 읽기 요청을 가로채고, Spark 작업을 실행하는 사용자의 ID를 확인하고, Knowledge Catalog 마스킹 규칙을 적용하고, 승인된 데이터만 Spark DataFrame에 반환합니다.
관리자로 Spark 실행
관리자 페르소나로 Spark 작업을 제출합니다. 자체 클러스터를 관리하지 않고도 Spark 워크로드를 실행할 수 있는 관리형 서비스인 Managed Service for Apache Spark를 사용하세요.
echo "🚀 Submitting Dataproc Serverless Job as [MANAGER]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_MANAGER} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
터미널에서 작업 출력 로그를 검토합니다. 관리자에게 세분화된 권한의 리더 역할이 있으므로 Spark는 마스킹되지 않은 금액을 성공적으로 가져옵니다.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|100.0 |2024-01-01 |
|2 |Widget B|150.0 |2024-01-02 |
|3 |Widget C|50.0 |2024-01-03 |
+---+--------+------+-------------------+
분석가로 Spark 실행
마지막으로 분석가 페르소나와 동일한 Spark 코드를 실행합니다.
echo "🚀 Submitting Dataproc Serverless Job as [ANALYST]..."
gcloud dataproc batches submit pyspark gs://${ICEBERG_BUCKET}/scripts/read_transactions.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--service-account=${EMAIL_ANALYST} \
--version=2.3 \
-- ${PROJECT_ID} ${DATASET_ID} \
--format="value(name)"
로그를 다시 검토합니다. 분석가가 동일한 Spark 코드를 실행했지만 BigQuery Storage API가 요청을 가로채 Knowledge Catalog 정책을 적용했습니다. 분석가의 Spark DataFrame에는 금액이 null로 표시됩니다.
=== 📊 Data Preview ===
+---+--------+------+-------------------+
|id |item |amount|transaction_date |
+---+--------+------+-------------------+
|1 |Widget A|null |2024-01-01 |
|2 |Widget B|null |2024-01-02 |
|3 |Widget C|null |2024-01-03 |
+---+--------+------+-------------------+
적절한 엔진 선택: BigQuery SQL과 Apache Spark 비교
사용하는 쿼리 엔진과 관계없이 Knowledge Catalog에서 정책을 적용한다는 것을 증명했습니다. 하지만 프로덕션으로 이동할 때는 어떻게 적절한 도구를 선택해야 할까요?
- BigQuery SQL: 빠른 분석 및 비즈니스 인텔리전스에 사용합니다. SQL이 기본 언어인 경우 데이터가 있는 위치에서 직접 계산을 실행하므로 이 방법이 가장 적합합니다.
- Apache Spark: Python이 필요한 더 복잡한 작업에는 Spark를 선택합니다. Spark는 머신러닝 파이프라인에 가장 적합하며 기존 Hadoop 코드를 레이크하우스로 가져와야 하는 경우에도 적합합니다.
자동 계보로 데이터의 여정 확인
데이터 계보를 사용하면 데이터의 출처와 변환 방식을 파악할 수 있습니다. '이 판매 보고서를 생성하는 데 사용된 원시 테이블은 무엇인가요?'와 같은 필수 질문에 답변하면 규정 준수를 유지하고, 데이터 파이프라인을 신속하게 디버그하고, 신뢰할 수 있는 데이터 기반을 구축하는 데 도움이 됩니다.
복잡한 로깅 코드를 수동으로 작성하는 대신 Lakehouse에서 이 수명 주기를 자동으로 추적합니다. 예를 들어 이 튜토리얼의 앞부분에서 요약 테이블을 만들 때 BigQuery는 변환 세부정보를 즉시 캡처하여 Knowledge Catalog로 전송했습니다.
대화형 계보 그래프 살펴보기
Knowledge Catalog에서 생성한 대화형 지도를 확인하세요. transactions 테이블에서 transactions_summary 테이블로 원시 데이터가 흐르는 방식을 보여줍니다. 이를 통해 데이터 감사에 필요한 엔드 투 엔드 추적 가능성을 제공합니다.
- Google Cloud 콘솔에서 Knowledge Catalog > Search로 이동합니다.
- 검색창에
lakehouse_retail_demo.transactions_summary를 입력하고 표를 클릭합니다. - 계보 탭을 클릭합니다.
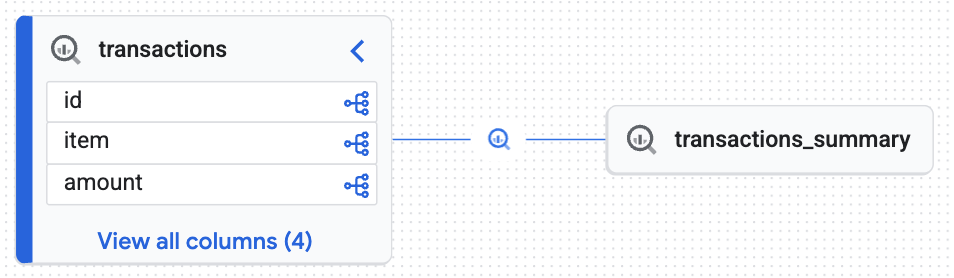
대화형 그래프를 통해 타겟 테이블 (transactions_summary)이 관리되는 원시 Iceberg 테이블 (transactions)에서 파생되었음을 확인할 수 있습니다. 이 시각화는 데이터의 엔드 투 엔드 추적 가능성을 보여줍니다.
삭제
요금이 계속 청구되지 않도록 이 튜토리얼에서 만든 리소스를 삭제합니다.
거버넌스 리소스 삭제
BigQuery 데이터 세트 또는 Cloud Storage 버킷을 삭제하려면 먼저 거버넌스 규칙을 삭제해야 합니다.
Python 정리 스크립트를 실행합니다.
python cleanup_governance.py
저장소의 cleanup_governance.py 스크립트를 검토하여 다음 종료 로직을 찾습니다. 삭제 순서가 중요합니다. 먼저 데이터 마스킹 정책을 삭제합니다. 그런 다음 상위 분류를 삭제하면 모든 기본 정책 태그가 자동으로 삭제되고 리소스 종속성 오류가 방지됩니다.
# 1. Delete Data Policy
data_policy_name = f"{parent_loc}/dataPolicies/mask_financial_null"
dp_client.delete_data_policy(name=data_policy_name)
# 2. Find and Delete Taxonomy (This auto-deletes child Policy Tags)
taxonomies = catalog_client.list_taxonomies(parent=parent_loc)
taxonomy_id = next((t.name for t in taxonomies if t.display_name == "BusinessCritical"), None)
catalog_client.delete_taxonomy(name=taxonomy_id)
ID, 스토리지, 컴퓨팅 애셋 삭제
BigQuery 테이블, Cloud Storage 버킷, 서비스 계정, 로컬 Python 가상 환경을 삭제합니다.
Cloud Shell에서 다음 정리 스크립트를 복사하여 실행합니다.
echo "Deleting Service Accounts and Impersonation Bindings..."
export CURRENT_USER=$(gcloud config get-value account)
for USER in "${USER_ANALYST}" "${USER_MANAGER}"; do
EMAIL="${USER}@${PROJECT_ID}.iam.gserviceaccount.com"
# Remove impersonation binding
gcloud iam service-accounts remove-iam-policy-binding ${EMAIL} \
--member="user:${CURRENT_USER}" \
--role="roles/iam.serviceAccountTokenCreator" \
--quiet > /dev/null 2>&1
# Delete the Service Account
gcloud iam service-accounts delete ${EMAIL} --quiet
done
echo "Removing BigQuery Dataset and Tables..."
bq rm -f ${DATASET_ID}.transactions_summary
bq rm -f ${DATASET_ID}.transactions
bq rm -f ${DATASET_ID}.inventory
bq rm -f -d ${DATASET_ID}
echo "Removing BigQuery Cloud Resource Connection..."
bq rm --connection --location=${REGION} ${CONN_NAME}
echo "Removing Iceberg Cloud Storage Bucket..."
gcloud storage rm --recursive gs://${ICEBERG_BUCKET} --quiet
echo "Removing Auto-generated Dataproc Staging & Temp Buckets..."
for BUCKET in $(gcloud storage ls | grep -E "gs://dataproc-(staging|temp)-${REGION}"); do
gcloud storage rm --recursive $BUCKET --quiet
done
echo "✅ Clean up completed successfully!"
프로젝트 파일을 정리합니다.
echo "Deactivating and removing the local Python environment..."
deactivate
cd ../..
rm -rf devrel-demos
결론
안전한 데이터 레이크하우스를 빌드했습니다. Lakehouse for Apache Iceberg를 사용하여 Iceberg 테이블을 관리하면 Cloud Storage에서 기본 테이블 파일의 보안을 유지할 수 있습니다. 중앙 위치에서 정책 태그를 정의하고 다양한 쿼리 엔진에 범용적으로 적용했습니다. 마지막으로 실시간 데이터 계보를 사용하여 데이터의 전체 여정을 자동으로 추적했습니다.
다음 단계
- Managed Service for Apache Spark: 서버리스 Spark 문서 페이지에서 클러스터를 프로비저닝하지 않고 데이터 파이프라인을 확장하는 방법을 알아보세요.
- 고급 액세스 제어 살펴보기: 더 복잡한 보안 시나리오를 구현하려면 추가 기능으로 Lakehouse 맞춤설정에 관한 공식 문서를 검토하세요.
- 생성형 AI를 위한 비정형 데이터 관리: 객체 테이블을 알아봅니다. 이 보안 브리지 패턴을 Cloud Storage의 비정형 파일 (PDF, 이미지)로 확장하여 Vertex AI 및 RAG 파이프라인을 위한 안전하고 관리되는 데이터 기반을 구축합니다.
- 다른 사용 사례 시도: 다른 Knowledge Catalog 사용 사례를 사용해 보세요.