
En este instructivo, se muestra cómo usar la sintaxis de YAML de Apache Beam para crear canalizaciones de procesamiento de datos de Dataflow. Aprenderás a leer datos de un archivo, aplicar transformaciones y escribir los resultados en otro archivo con la IU del compilador de trabajos en la consola de Google Cloud . Este instructivo está dirigido a desarrolladores que no conocen Apache Beam o que desean aprender a usar la API de YAML para compilar canalizaciones.
En la siguiente tabla, se muestra un gráfico de canalización en la consola de Google Cloud y su especificación YAML correspondiente.
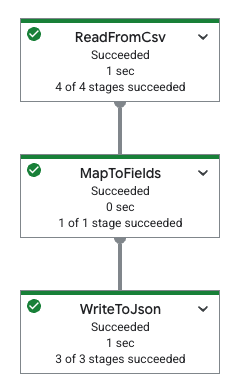
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
Objetivos
En este instructivo, aprenderás a realizar las siguientes tareas:
- Crear canalizaciones de Beam en YAML que lean, escriban y transformen datos
- Filtrar datos según el contenido
- Asigna campos con expresiones de Python.
- Usar SQL para consultar y agregar datos
- Crea y ejecuta canalizaciones de Beam YAML con el formulario del compilador en la IU del compilador de trabajos de la consola de Google Cloud .
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
Para generar una estimación de costos en función del uso previsto,
usa la calculadora de precios.
Cuando completes las tareas que se describen en este documento, podrás borrar los recursos que creaste para evitar que se te siga facturando. Para obtener más información, consulta Realiza una limpieza.
Antes de comenzar
Completa los siguientes pasos antes de ejecutar tu canalización.
Configura tu proyecto
- Accede a tu cuenta de Google Cloud . Si eres nuevo en Google Cloud, crea una cuenta para evaluar el rendimiento de nuestros productos en situaciones reales. Los clientes nuevos también obtienen $300 en créditos gratuitos para ejecutar, probar y, además, implementar cargas de trabajo.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.
Cree un bucket de Cloud Storage
Antes de ejecutar una canalización, debes crear un bucket de Cloud Storage.
Crea un bucket de Cloud Storage:
- En la consola de Google Cloud , ve a la página Buckets de Cloud Storage.
- Haz clic en Crear.
- En la página Crear un bucket, ingresa la información de tu bucket. Para ir al paso siguiente, haz clic en Continuar.
- En Asigna un nombre a tu bucket, ingresa un nombre de bucket único. No incluyas información sensible en el nombre del bucket porque su espacio de nombres es global y públicamente visible.
-
En la sección Elige dónde almacenar tus datos, haz lo siguiente:
- Selecciona un tipo de ubicación
- Elige una ubicación en la que se almacenen de forma permanente los datos de tu bucket en el menú desplegable Tipo de ubicación.
- Si seleccionas el tipo de ubicación birregional, también puedes habilitar la replicación turbo con la casilla de verificación correspondiente.
- Para configurar la replicación bucket buckets, selecciona
Agregar replicación entre bucket a través del Servicio de transferencia de almacenamiento y
sigue estos pasos:
Configura la replicación entre buckets
- En el menú Bucket, selecciona un bucket.
En la sección Configuración de replicación, haz clic en Configurar para configurar los parámetros del trabajo de replicación.
Aparecerá el panel Configurar la replicación entre buckets.
- Para filtrar los objetos que se replicarán por prefijo de nombre de objeto, ingresa un prefijo con el que quieras incluir o excluir objetos y, luego, haz clic en Agregar un prefijo.
- Para establecer una clase de almacenamiento para los objetos replicados, selecciona una clase de almacenamiento en el menú Clase de almacenamiento. Si omites este paso, los objetos replicados usarán la clase de almacenamiento del bucket de destino de forma predeterminada.
- Haz clic en Listo.
-
En la sección Elige cómo almacenar tus datos, haz lo siguiente:
- En la sección Establecer una clase predeterminada, selecciona lo siguiente: Estándar.
- Para habilitar el espacio de nombres jerárquico, en la sección Optimizar el almacenamiento para cargas de trabajo con uso intensivo de datos, selecciona Habilitar el espacio de nombres jerárquico en este bucket.
- En la sección Elige cómo controlar el acceso a los objetos, selecciona si tu bucket aplica o no la prevención del acceso público y elige un método de control de acceso para los objetos del bucket.
-
En la sección Elige cómo proteger los datos de objetos, haz lo siguiente:
- Selecciona cualquiera de las opciones de Protección de datos que
desees configurar para tu bucket.
- Para habilitar la eliminación no definitiva, haz clic en la casilla de verificación Política de eliminación no definitiva (para la recuperación de datos) y especifica la cantidad de días que deseas conservar los objetos después de la eliminación.
- Para configurar el control de versiones de objetos, haz clic en la casilla de verificación Control de versiones de objetos (para el control de versión) y especifica la cantidad máxima de versiones por objeto y la cantidad de días después de los cuales vencen las versiones no actuales.
- Para habilitar la política de retención en objetos y buckets, haz clic en la casilla de verificación Retención (para cumplimiento) y, luego, haz lo siguiente:
- Para habilitar el bloqueo de retención de objetos, haz clic en la casilla de verificación Habilitar la retención de objetos.
- Para habilitar el Bloqueo del bucket, haz clic en la casilla de verificación Establecer política de retención del bucket y elige una unidad de tiempo y una duración para tu período de retención.
- Para elegir cómo se encriptarán los datos de tus objetos, expande la sección Encriptación de datos () y selecciona un método de encriptación de datos.
- Selecciona cualquiera de las opciones de Protección de datos que
desees configurar para tu bucket.
- Haz clic en Crear.
Copia lo siguiente, ya que lo necesitarás en una sección posterior:
- : Es el nombre del bucket de Cloud Storage.
- Es el ID de tu proyecto de Google Cloud .
Para encontrar este ID, consulta Identifica proyectos.
Red de VPC
De forma predeterminada, cada proyecto nuevo comienza con una red predeterminada. Si la red predeterminada de tu proyecto está inhabilitada o se borró, debes tener una red en tu proyecto para la que tu cuenta de usuario tenga el rol de usuario de la red de Compute (roles/compute.networkUser).
Leer, escribir y transformar datos
En esta sección, se muestra cómo puedes usar la sintaxis de Beam YAML con Dataflow para leer, escribir y filtrar datos con los siguientes elementos:
- Desarrollo basado en la interfaz de usuario para crear y ejecutar trabajos en la IU del compilador de trabajos en la consola de Google Cloud . Específicamente, usarás el formulario del compilador en la IU del compilador de trabajos, por lo que no necesitarás crear los archivos YAML de forma manual.
Datos de archivos CSV almacenados en un bucket de Cloud Storage visible públicamente Estos datos contienen datos simulados del menú de un restaurante y se ven de la siguiente manera:
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
Cómo leer y filtrar datos
En el siguiente ejemplo, se muestra cómo leer datos de un archivo CSV, filtrarlos para obtener información específica y escribir los datos filtrados en un archivo JSON.
En este ejemplo, se usa la transformaciónFilter, que te permite conservar de forma selectiva los datos que cumplen con ciertos criterios. En el siguiente ejemplo, se filtra un conjunto de datos para conservar solo los registros en los que Price es mayor o igual que 20.00.
Para leer los datos CSV y generar contenido JSON filtrado, completa los siguientes pasos:
En la consola de Google Cloud , ve a la página Trabajos de Dataflow.
Haz clic en Crear trabajo a partir de un compilador.
En la pestaña Creador de trabajos, deja seleccionada la opción Formulario del creador.
En el campo Nombre del trabajo, ingresa
filter-python-job.En Tipo de trabajo, deja seleccionada la opción Batch.
En la sección Fuentes, haz lo siguiente:
En el campo Nombre de la fuente del panel Fuente nueva, cambia el nombre a
ReadCsv.En la lista Tipo de fuente, selecciona CSV desde Cloud Storage.
En el campo Ubicación del CSV, ingresa lo siguiente:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvHaz clic en Listo.
En la sección Transformaciones, haz lo siguiente:
Haz clic en Agregar una transformación.
En el campo Nombre de la transformación, ingresa
FilterPrice.En la lista Tipo de transformación, selecciona Filtrar (Python).
En el campo Expresión de filtro de Python, ingresa
Price >= 20.00.En la lista Paso de entrada para la transformación, deja seleccionado
ReadCsv.Haz clic en Listo.
En la sección Receptores, haz lo siguiente:
En el campo Nombre del receptor, cambia el nombre a
WriteJson.En la lista Tipo de receptor, selecciona Archivos JSON en Cloud Storage.
En el campo Ubicación del JSON, ingresa lo siguiente:
BUCKET_NAME/output/restaurant-data_filtered.jsonReemplaza
BUCKET_NAMEpor el nombre de tu depósito de Cloud Storage.En la lista Paso de entrada del receptor, deja seleccionado
FilterPrice.Haz clic en Listo.
En la sección Opciones de Dataflow, haz clic en Ejecutar trabajo.
Examina el resultado del trabajo
Cuando se complete el trabajo, realiza los siguientes pasos para ver el resultado de la canalización:
En la Google Cloud consola, ve a la página Buckets de Cloud Storage.
En la lista de buckets, haz clic en el nombre del bucket que creaste en Crea un bucket de Cloud Storage.
Haz clic en el archivo llamado
restaurant-data_filtered.json-00000-of-00001.En la página Detalles del objeto, haz clic en la URL autenticada para ver el resultado de la canalización.
El resultado debería ser similar al siguiente:
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
Asigna campos con Python
Con la transformación MapToFields, puedes crear campos nuevos basados en los existentes. En el siguiente ejemplo, se crea una versión en minúsculas de un elemento de menú, se calcula un precio total y se agregan los valores después de los valores existentes.
Ve a la página Trabajos de Dataflow en la consola deGoogle Cloud .
Haz clic en Crear trabajo a partir del compilador.
En la pestaña Creador de trabajos, deja seleccionada la opción Formulario del creador.
En el campo Nombre del trabajo, ingresa
map-python-job.En Tipo de trabajo, deja seleccionada la opción Batch.
En la sección Fuentes, haz lo siguiente:
En el campo Nombre de la fuente del panel Fuente nueva, cambia el nombre a
ReadFromCsvPy.En la lista Tipo de fuente, selecciona CSV desde Cloud Storage.
En el campo Ubicación del CSV, ingresa lo siguiente:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvHaz clic en Listo.
En la sección Transformaciones, haz lo siguiente:
Haz clic en Agregar una transformación.
En el campo Nombre de la transformación, ingresa
MapToFieldsPy.En la lista Tipo de transformación, selecciona Asignar campos (Python).
Deja seleccionada la opción Conservar los campos existentes.
En la sección Campos asignados, haz clic en Agregar un campo.
En el panel Campo nuevo que se abre, ingresa
Lowercase_menu_itemcomo el Nombre del campo.En el campo Expresión de Python, ingresa
Item.lower().Haz clic en Listo.
En la misma sección Campos asignados, vuelve a hacer clic en Agregar un campo.
En el panel Campo nuevo que se abre, ingresa
Total_pricecomo el Nombre del campo.En el campo Expresión de Python, ingresa
Price + Tax.En este panel Nuevo campo, haz clic en Listo.
En este panel Nueva transformación, haz clic en Listo.
En la sección Receptores, haz lo siguiente:
En el campo Nombre del receptor, cambia el nombre a
WriteToJsonPy.En la lista Tipo de receptor, selecciona Archivos JSON en Cloud Storage.
En el campo Ubicación del JSON, ingresa lo siguiente:
BUCKET_NAME/output/restaurant-data_map-fields.jsonReemplaza
BUCKET_NAMEpor el nombre de tu depósito de Cloud Storage.En la lista Paso de entrada del receptor, deja seleccionado
MapToFieldsPy.Haz clic en Listo.
En la sección Opciones de Dataflow, haz clic en Ejecutar trabajo.
Examina el resultado del trabajo
Cuando se complete el trabajo, realiza los siguientes pasos para ver el resultado de la canalización:
En la Google Cloud consola, ve a la página Buckets de Cloud Storage.
En la lista de buckets, haz clic en el nombre del bucket que creaste en Crea un bucket de Cloud Storage.
Haz clic en el archivo llamado
restaurant-data_map-fields.json-00000-of-00001.En la página Detalles del objeto, haz clic en la URL autenticada para ver el resultado de la canalización.
El resultado debería ser similar al siguiente:
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
Transformar los datos con SQL
La transformaciónSql te permite ejecutar consultas en SQL sobre tus datos. En el siguiente ejemplo, se agrupan los elementos del menú por categoría (como Entree, Beverage o Dessert) y se agrega una columna con el recuento de los elementos en cada categoría.
Para usar la IU del compilador de trabajos y crear tu canalización, sigue estos pasos:
Ve a la página Trabajos de Dataflow en la consola de Google Cloud .
Haz clic en Crear trabajo a partir del compilador.
En la pestaña Job builder, en el campo Job name, ingresa
sql-transform-job.En Tipo de trabajo, deja seleccionada la opción Batch.
En la sección Fuentes, haz lo siguiente:
En el campo Nombre de la fuente, cambia el nombre a
SqlTransformSource.En la pestaña Nueva fuente, en Tipo de fuente, selecciona CSV desde Cloud Storage. Se abrirá el campo Ubicación del CSV.
En Ubicación del CSV, ingresa lo siguiente:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvHaz clic en Listo.
En la sección Transformaciones, haz lo siguiente:
Haz clic en Agregar una transformación.
En el campo Nombre de la transformación, actualiza el nombre a
SqlTransform.En Tipo de transformación, selecciona Transformación SQL. Se abrirán las opciones de transformación de SQL.
En el campo Expresión SQL, ingresa lo siguiente:
select Category, count(*) as category_count from PCOLLECTION group by CategoryHaz clic en Listo.
En la sección Receptores, haz lo siguiente:
En Nombre del receptor, ingresa
SqlTransformSink.En Tipo de receptor, selecciona Archivos JSON en Cloud Storage. Se abrirán las opciones de Escribir en archivos JSON en Cloud Storage.
En Ubicación del archivo JSON, ingresa lo siguiente:
BUCKET_NAME/output/restaurant-data_transform-sql.jsonReemplaza
BUCKET_NAMEpor el nombre de tu depósito de Cloud Storage.Haz clic en Listo.
Opcional: Consulta la definición en formato YAML generada para esta canalización.
Navega a la parte superior de la pestaña Job builder.
Selecciona Editor de YAML. Deberías ver la definición de YAML. Debería verse de la siguiente manera:
Especificación de YAML generada
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
En la sección Opciones de Dataflow, haz clic en Ejecutar trabajo.
Examina el resultado del trabajo
Cuando se complete el trabajo, realiza los siguientes pasos para ver el resultado de la canalización:
En la Google Cloud consola, ve a la página Buckets de Cloud Storage.
En la lista de buckets, haz clic en el nombre del bucket que creaste en Crea un bucket de Cloud Storage.
Haz clic en el archivo llamado
restaurant-data_transform-sql.json-00000-of-00001.En la página Detalles del objeto, haz clic en la URL autenticada para ver el resultado de la canalización.
El resultado debería ser similar al siguiente:
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
Realiza una limpieza
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Borra el proyecto
- En la Google Cloud consola, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que quieres borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrar el proyecto.
Borra los recursos individuales
Si quieres reutilizar el proyecto más adelante, puedes conservarlo, pero borrar los recursos que creaste durante el instructivo.
Detén la canalización de Dataflow
En la consola de Google Cloud , ve a la página Trabajos de Dataflow.
Haz clic en el trabajo que deseas detener.
Para detener un trabajo, su estado debe ser En ejecución.
En la página de detalles del trabajo, haz clic en Detener.
Haz clic en Cancelar.
Para confirmar tu elección, haz clic en Detener trabajo.
Borra el bucket de Cloud Storage
- En la Google Cloud consola, ve a la página Buckets de Cloud Storage.
- Haz clic en la casilla de verificación del bucket que deseas borrar.
- Para borrar el bucket, haz clic en Borrar y sigue las instrucciones.
¿Qué sigue?
- Obtén más información para crear trabajos con el resumen de la IU del compilador de trabajos en la consola de Google Cloud .
- Obtén más información sobre los trabajos personalizados del Creador de trabajos en Crea un trabajo personalizado con el Creador de trabajos.
- Lee la descripción general de la API de YAML de Beam.
- Consulta más ejemplos de YAML de Beam.