
In dieser Anleitung erfahren Sie, wie Sie mit der Apache Beam-YAML-Syntax Dataflow-Pipelines für die Datenverarbeitung erstellen. Sie erfahren, wie Sie Daten aus einer Datei lesen, Transformationen anwenden und die Ergebnisse in eine andere Datei schreiben. Dazu verwenden Sie die Job-Builder-UI in der Google Cloud -Konsole. Diese Anleitung richtet sich an Entwickler, die neu bei Apache Beam sind oder lernen möchten, wie sie die YAML API zum Erstellen von Pipelines verwenden.
In der folgenden Tabelle sehen Sie ein Pipeline-Diagramm in der Google Cloud -Konsole und die entsprechende YAML-Spezifikation.
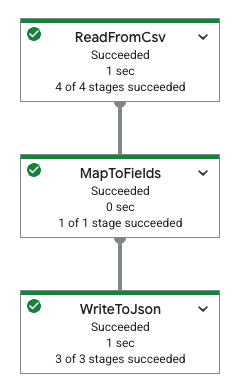
|
pipeline: transforms: - name: ReadFromCsv type: ReadFromCsv config: path: 'gs://[...]/restaurant-data.csv' - name: MapToFields type: MapToFields input: ReadFromCsv config: language: python fields: Lowercase_menu_item: Item.lower() Total_price: Price + Tax append: true - name: WriteToJson type: WriteToJson input: MapToFields config: path: 'gs://[...]/restaurant-data_map-fields.json' |
Ziele
In dieser Anleitung erfahren Sie, wie Sie Folgendes tun:
- Erstellen Sie Beam YAML-Pipelines, mit denen Daten gelesen, geschrieben und transformiert werden.
- Daten nach Inhalt filtern
- Felder mit Python-Ausdrücken zuordnen
- Daten mit SQL abfragen und aggregieren
- Erstellen und führen Sie Beam YAML-Pipelines mit dem Builder-Formular in der Job-Builder-UI in der Google Cloud Console aus.
Kosten
In diesem Dokument verwenden Sie die folgenden kostenpflichtigen Komponenten von Google Cloud:
Mit dem Preisrechner können Sie eine Kostenschätzung für Ihre voraussichtliche Nutzung vornehmen.
Nach Abschluss der in diesem Dokument beschriebenen Aufgaben können Sie weitere Kosten vermeiden, indem Sie die erstellten Ressourcen löschen. Weitere Informationen finden Sie unter Bereinigen.
Hinweis
Führen Sie die folgenden Schritte aus, bevor Sie die Pipeline ausführen.
Projekt einrichten
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie mit Google Cloudnoch nicht vertraut sind, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.
Cloud Storage-Bucket erstellen
Bevor Sie eine Pipeline ausführen können, müssen Sie einen Cloud Storage-Bucket erstellen.
Erstellen Sie einen Cloud Storage-Bucket:
- Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
- Klicken Sie auf Erstellen.
- Geben Sie auf der Seite Bucket erstellen die Bucket-Informationen ein. Klicken Sie auf Weiter, um mit dem nächsten Schritt fortzufahren.
- Geben Sie unter Bucket benennen einen eindeutigen Bucket-Namen ein. Der Bucket-Name darf keine vertraulichen Informationen enthalten, da der Bucket-Namespace global und öffentlich sichtbar ist.
-
Gehen Sie im Bereich Speicherort für Daten auswählen so vor:
- Standorttyp auswählen.
- Wählen Sie im Drop-down-Menü Standorttyp einen Standort aus, an dem die Daten Ihres Buckets dauerhaft gespeichert werden.
- Wenn Sie den Standorttyp Dual-Region auswählen, können Sie auch die Turboreplikation aktivieren, indem Sie das entsprechende Kästchen anklicken.
- Wenn Sie die Bucket-übergreifende Replikation einrichten möchten, wählen Sie Bucket-übergreifende Replikation über Storage Transfer Service hinzufügen aus und führen Sie die folgenden Schritte aus:
Bucket-übergreifende Replikation einrichten
- Wählen Sie im Menü Bucket einen Bucket aus.
Klicken Sie im Bereich Replikationseinstellungen auf Konfigurieren, um die Einstellungen für den Replikationsjob zu konfigurieren.
Der Bereich Bucket-übergreifende Replikation konfigurieren wird angezeigt.
- Wenn Sie die zu replizierenden Objekte nach dem Objektnamenspräfix filtern möchten, geben Sie ein Präfix ein, mit dem Sie Objekte ein- oder ausschließen möchten, und klicken Sie dann auf Präfix hinzufügen.
- Wenn Sie eine Speicherklasse für die replizierten Objekte festlegen möchten, wählen Sie im Menü Speicherklasse eine Speicherklasse aus. Wenn Sie diesen Schritt überspringen, wird für replizierte Objekte standardmäßig die Speicherklasse des Ziel-Buckets verwendet.
- Klicken Sie auf Fertig.
-
Gehen Sie im Bereich Speicherort für Daten auswählen so vor:
- Wählen Sie im Bereich Standardklasse festlegen die Option Standard aus.
- Wenn Sie den hierarchischen Namespace aktivieren möchten, wählen Sie im Bereich Speicher für datenintensive Arbeitslasten optimieren die Option Hierarchischen Namespace für diesen Bucket aktivieren aus.
- Wählen Sie im Abschnitt Zugriff auf Objekte steuern aus, ob der Bucket Verhinderung des öffentlichen Zugriffs durchsetzt, und wählen Sie eine Zugriffssteuerungsmethode für die Objekte Ihres Buckets aus.
-
Führen Sie im Bereich Auswählen, wie Objektdaten geschützt werden die folgenden Schritte aus:
- Wählen Sie unter Datenschutz die gewünschten Optionen für Ihren Bucket aus.
- Wenn Sie Vorläufiges Löschen aktivieren möchten, klicken Sie das Kästchen Richtlinie für vorläufiges Löschen (zur Datenwiederherstellung) an und geben Sie die Anzahl der Tage an, die Objekte nach dem Löschen beibehalten werden sollen.
- Wenn Sie die Objektversionsverwaltung festlegen möchten, klicken Sie das Kästchen Objektversionsverwaltung (zur Datenwiederherstellung) an und geben Sie die maximale Anzahl von Versionen pro Objekt und die Anzahl der Tage an, nach denen die nicht aktuellen Versionen ablaufen.
- Klicken Sie das Kästchen Aufbewahrung (für Compliance) an, um die Aufbewahrungsrichtlinie für Objekte und Buckets zu aktivieren, und gehen Sie dann so vor:
- Klicken Sie auf das Kästchen Objektaufbewahrung aktivieren, um die Objektaufbewahrungssperre zu aktivieren.
- Wenn Sie Bucket Lock aktivieren möchten, klicken Sie das Kästchen Bucket-Aufbewahrungsrichtlinie festlegen an und wählen Sie eine Zeiteinheit und eine Zeitdauer für die Aufbewahrungsdauer aus.
- Um auszuwählen, wie Ihre Objektdaten verschlüsselt werden, maximieren Sie den Bereich Datenverschlüsselung () und wählen Sie eine Methode für die Datenverschlüsselung aus.
- Wählen Sie unter Datenschutz die gewünschten Optionen für Ihren Bucket aus.
- Klicken Sie auf Erstellen.
Kopieren Sie Folgendes, was Sie in einem späteren Abschnitt benötigen:
- : Name Ihres Cloud Storage-Buckets
- Ihre Google Cloud -Projekt-ID.
Diese ID finden Sie unter Projekte identifizieren.
VPC-Netzwerk
Standardmäßig beginnt jedes neue Projekt mit einem Standardnetzwerk. Wenn das Standardnetzwerk für Ihr Projekt deaktiviert oder gelöscht wurde, benötigen Sie in Ihrem Projekt ein Netzwerk, für das Ihr Nutzerkonto die Rolle Compute-Netzwerknutzer (roles/compute.networkUser) hat.
Daten lesen, schreiben und transformieren
In diesem Abschnitt wird gezeigt, wie Sie die Beam YAML-Syntax mit Dataflow verwenden können, um Daten mit den folgenden Elementen zu lesen, zu schreiben und zu filtern:
- Benutzeroberflächengesteuerte Entwicklung zum Erstellen und Ausführen von Jobs in der Benutzeroberfläche des Job-Builders in der Google Cloud Console. Sie verwenden das Builder-Formular in der Job Builder-Benutzeroberfläche, sodass Sie die YAML-Dateien nicht manuell erstellen müssen.
Daten aus einer CSV-Datei, die in einem öffentlich sichtbaren Cloud Storage-Bucket gespeichert sind. Diese Daten enthalten Beispieldaten für Restaurantmenüs und sehen so aus:
restaurant-data.csvMenu item,Category,Price,Tax Classic Cheeseburger,Entree,9.99,0.7 Margherita Pizza,Entree,14.50,1.02 Grilled Salmon with Asparagus,Entree,21.99,1.54 Chicken Caesar Salad,Salad,12.75,0.89 Spaghetti Carbonara,Entree,16.25,1.14 Beef Tacos (3),Entree,10.50,0.74 Vegetable Stir-Fry,Entree,13.00,0.91 Shrimp Scampi,Entree,19.75,1.38 Chicken Pot Pie,Entree,15.50,1.09 Steak Frites,Entree,28.00,1.96 Lobster Mac and Cheese,Entree,25.50,1.79 Pork Belly Bao Buns (2),Appetizer/Side,11.25,0.79 Mushroom Risotto,Entree,17.50,1.23 Fish and Chips,Entree,14.00,0.98 Buffalo Wings (6),Appetizer/Side,9.50,0.67 French Onion Soup,Appetizer/Side,7.00,0.49 Tomato Soup with Grilled Cheese,Appetizer/Side,10.00,0.7 Avocado Toast,Appetizer/Side,8.50,0.6 Quesadilla with Chicken,Appetizer/Side,11.75,0.82 Pad Thai,Entree,15.00,1.05 Chicken Tikka Masala,Entree,18.50,1.3 Burrito Bowl,Entree,13.50,0.95 Sushi Combo (8 pieces),Entree,22.00,1.54 Greek Salad,Salad,11.00,0.77 Clam Chowder,Appetizer/Side,8.00,0.56 New York Cheesecake,Dessert,6.50,0.46 Chocolate Lava Cake,Dessert,7.50,0.53 Apple Pie,Dessert,5.00,0.35 Tiramisu,Dessert,8.00,0.56 Crème brûlée,Dessert,7.00,0.49 Iced Coffee,Beverage,3.50,0.25 Lemonade,Beverage,3.00,0.21 Orange Juice,Beverage,4.00,0.28 Soda,Beverage,2.50,0.18 Craft Beer,Beverage,6.00,0.42 Glass of Wine,Beverage,9.00,0.63 Margarita,Beverage,12.00,0.84 Moscow Mule,Beverage,11.50,0.81 Old Fashioned,Beverage,13.00,0.91 Espresso,Beverage,3.00,0.21 Cappuccino,Beverage,4.50,0.32 Latte,Beverage,5.00,0.35 Mocha,Beverage,5.50,0.39 Hot Chocolate,Beverage,4.00,0.28 Breakfast Burrito,Breakfast,10.50,0.74 Pancakes (3),Breakfast,8.00,0.56 Waffles,Breakfast,9.00,0.63 Eggs Benedict,Breakfast,14.00,0.98 Omelette,Breakfast,11.00,0.77 Fruit Salad,Salad,7.50,0.53 Yogurt Parfait,Breakfast,6.00,0.42
Daten lesen und filtern
Im folgenden Beispiel wird gezeigt, wie Sie Daten aus einer CSV-Datei lesen, nach bestimmten Informationen filtern und die gefilterten Daten in eine JSON-Datei schreiben.
In diesem Beispiel wird die Transformation Filter verwendet, mit der Sie Daten, die bestimmte Kriterien erfüllen, selektiv beibehalten können. Im folgenden Beispiel wird ein Dataset gefiltert, sodass nur die Datensätze beibehalten werden, in denen Price größer oder gleich 20.00 ist.
So lesen Sie die CSV-Daten und geben gefilterte JSON-Inhalte aus:
Rufen Sie in der Google Cloud Console die Dataflow-Seite Jobs auf.
Klicken Sie auf Job aus Builder erstellen.
Lassen Sie auf dem Tab Job Builder die Option Builder-Formular ausgewählt.
Geben Sie im Feld Jobname
filter-python-jobein.Lassen Sie für Jobtyp die Option Batch ausgewählt.
Im Abschnitt Quellen:
Ändern Sie im Bereich Neue Quelle im Feld Quellname den Namen in
ReadCsv.Wählen Sie in der Liste Quelltyp die Option CSV aus Cloud Storage aus.
Geben Sie im Feld CSV-Speicherort Folgendes ein:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvKlicken Sie auf Fertig.
Im Bereich Transformationen:
Klicken Sie auf Transformation hinzufügen.
Geben Sie im Feld Name der Transformation
FilterPriceein.Wählen Sie in der Liste Transformationsart die Option Filter (Python) aus.
Geben Sie im Feld Python-Filterausdruck den Wert
Price >= 20.00ein.Lassen Sie in der Liste Eingabeschritt für die Transformation die Option
ReadCsvausgewählt.Klicken Sie auf Fertig.
Im Bereich Sinks:
Ändern Sie im Feld Name der Senke den Namen in
WriteJson.Wählen Sie in der Liste Senkentyp die Option JSON-Dateien in Cloud Storage aus.
Geben Sie im Feld JSON-Speicherort Folgendes ein:
BUCKET_NAME/output/restaurant-data_filtered.jsonErsetzen Sie
BUCKET_NAMEdabei durch den Namen des Cloud Storage-Buckets.Lassen Sie in der Liste Eingabeschritt für die Senke die Option
FilterPriceausgewählt.Klicken Sie auf Fertig.
Klicken Sie im Abschnitt Dataflow-Optionen auf Job ausführen.
Jobausgabe prüfen
Wenn der Job abgeschlossen ist, führen Sie die folgenden Schritte aus, um die Ausgabe der Pipeline zu sehen:
Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
Klicken Sie in der Bucket-Liste auf den Namen des Buckets, den Sie unter Cloud Storage-Bucket erstellen erstellt haben.
Klicken Sie auf die Datei mit dem Namen
restaurant-data_filtered.json-00000-of-00001.Klicken Sie auf der Seite Objektdetails auf die authentifizierte URL, um die Pipelineausgabe aufzurufen.
Die Ausgabe sollte in etwa so aussehen:
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54}
{"Item":"Steak Frites","Category":"Entree","Price":28.0,"Tax":1.96}
{"Item":"Lobster Mac and Cheese","Category":"Entree","Price":25.5,"Tax":1.79}
{"Item":"Sushi Combo (8 pieces)","Category":"Entree","Price":22.0,"Tax":1.54}
Felder mit Python zuordnen
Mit der MapToFields-Transformation können Sie neue Felder auf Grundlage vorhandener Felder erstellen. Im folgenden Beispiel wird eine Kleinbuchstabenversion eines Menüpunkts erstellt, ein Gesamtpreis berechnet und die Werte nach den vorhandenen Werten angehängt.
Rufen Sie in derGoogle Cloud -Console die Dataflow-Seite Jobs auf.
Klicken Sie auf Job mit dem Builder erstellen.
Lassen Sie auf dem Tab Job Builder die Option Builder-Formular ausgewählt.
Geben Sie im Feld Jobname
map-python-jobein.Lassen Sie für Jobtyp die Option Batch ausgewählt.
Im Abschnitt Quellen:
Ändern Sie im Bereich Neue Quelle im Feld Quellname den Namen in
ReadFromCsvPy.Wählen Sie in der Liste Quelltyp die Option CSV aus Cloud Storage aus.
Geben Sie im Feld CSV-Speicherort Folgendes ein:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvKlicken Sie auf Fertig.
Im Bereich Transformationen:
Klicken Sie auf Transformation hinzufügen.
Geben Sie im Feld Name der Transformation
MapToFieldsPyein.Wählen Sie in der Liste Transformationstyp die Option Felder zuordnen (Python) aus.
Lassen Sie Vorhandene Felder beibehalten ausgewählt.
Klicken Sie im Bereich Zugeordnete Felder auf Feld hinzufügen.
Geben Sie im Bereich Neues Feld, der sich öffnet,
Lowercase_menu_itemals Feldname ein.Geben Sie im Feld Python-Ausdruck den Wert
Item.lower()ein.Klicken Sie auf Fertig.
Klicken Sie im selben Bereich Zugeordnete Felder noch einmal auf Feld hinzufügen.
Geben Sie im Bereich Neues Feld, der sich öffnet,
Total_priceals Feldname ein.Geben Sie im Feld Python-Ausdruck den Wert
Price + Taxein.Klicken Sie in diesem Bereich Neues Feld auf Fertig.
Klicken Sie in diesem Bereich Neue Transformation auf Fertig.
Im Bereich Sinks:
Ändern Sie im Feld Name der Senke den Namen in
WriteToJsonPy.Wählen Sie in der Liste Senkentyp die Option JSON-Dateien in Cloud Storage aus.
Geben Sie im Feld JSON-Speicherort Folgendes ein:
BUCKET_NAME/output/restaurant-data_map-fields.jsonErsetzen Sie
BUCKET_NAMEdabei durch den Namen des Cloud Storage-Buckets.Lassen Sie in der Liste Eingabeschritt für die Senke die Option
MapToFieldsPyausgewählt.Klicken Sie auf Fertig.
Klicken Sie im Abschnitt Dataflow-Optionen auf Job ausführen.
Jobausgabe prüfen
Wenn der Job abgeschlossen ist, führen Sie die folgenden Schritte aus, um die Ausgabe der Pipeline zu sehen:
Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
Klicken Sie in der Bucket-Liste auf den Namen des Buckets, den Sie unter Cloud Storage-Bucket erstellen erstellt haben.
Klicken Sie auf die Datei mit dem Namen
restaurant-data_map-fields.json-00000-of-00001.Klicken Sie auf der Seite Objektdetails auf die authentifizierte URL, um die Pipelineausgabe aufzurufen.
Die Ausgabe sollte in etwa so aussehen:
{"Item":"Classic Cheeseburger","Category":"Entree","Price":9.99,"Tax":0.7,"Lowercase_menu_item":"classic cheeseburger","Total_price":10.69}
{"Item":"Margherita Pizza","Category":"Entree","Price":14.5,"Tax":1.02,"Lowercase_menu_item":"margherita pizza","Total_price":15.52}
{"Item":"Grilled Salmon with Asparagus","Category":"Entree","Price":21.99,"Tax":1.54,"Lowercase_menu_item":"grilled salmon with asparagus","Total_price":23.53}
{"Item":"Chicken Caesar Salad","Category":"Salad","Price":12.75,"Tax":0.89,"Lowercase_menu_item":"chicken caesar salad","Total_price":13.64}
{"Item":"Spaghetti Carbonara","Category":"Entree","Price":16.25,"Tax":1.14,"Lowercase_menu_item":"spaghetti carbonara","Total_price":17.39}
{"Item":"Beef Tacos (3)","Category":"Entree","Price":10.5,"Tax":0.74,"Lowercase_menu_item":"beef tacos (3)","Total_price":11.24}
[...]
Daten mit SQL transformieren
Mit der Sql-Transformation können Sie SQL-Abfragen für Ihre Daten ausführen. Im folgenden Beispiel werden Menüelemente nach Kategorie (z. B. Entree, Beverage oder Dessert) gruppiert und eine Spalte mit der Anzahl der Elemente in jeder Kategorie hinzugefügt.
So erstellen Sie Ihre Pipeline über die Job-Builder-Benutzeroberfläche:
Rufen Sie in der Google Cloud -Console die Dataflow-Seite Jobs auf.
Klicken Sie auf Job mit dem Builder erstellen.
Geben Sie auf dem Tab Job Builder im Feld Jobname
sql-transform-jobein.Lassen Sie für Jobtyp die Option Batch ausgewählt.
Im Abschnitt Quellen:
Ändern Sie im Feld Quellname den Namen in
SqlTransformSource.Wählen Sie auf dem Tab Neue Quelle für Quelltyp die Option CSV aus Cloud Storage aus. Das Feld CSV-Speicherort wird geöffnet.
Geben Sie unter CSV-Speicherort Folgendes ein:
cloud-samples-data/dataflow/tutorials/restaurant-data.csvKlicken Sie auf Fertig.
Im Bereich Transformationen:
Klicken Sie auf Transformation hinzufügen.
Aktualisieren Sie den Namen im Feld Name der Transformation zu
SqlTransform.Wählen Sie als Transformationstyp die Option SQL-Transformation aus. Die Optionen für die SQL-Transformation werden geöffnet.
Geben Sie im Feld SQL-Ausdruck Folgendes ein:
select Category, count(*) as category_count from PCOLLECTION group by CategoryKlicken Sie auf Fertig.
Im Bereich Sinks:
Geben Sie als Namen der Senke
SqlTransformSinkein.Wählen Sie als Sink-Typ die Option JSON-Dateien in Cloud Storage aus. Die Optionen für In JSON-Dateien in Cloud Storage schreiben werden geöffnet.
Geben Sie für JSON-Speicherort Folgendes ein:
BUCKET_NAME/output/restaurant-data_transform-sql.jsonErsetzen Sie
BUCKET_NAMEdabei durch den Namen des Cloud Storage-Buckets.Klicken Sie auf Fertig.
Optional: Sehen Sie sich die generierte YAML-Definition für diese Pipeline an.
Wechseln Sie zum Anfang des Tabs „Job Builder“.
Wählen Sie YAML-Editor aus. Sie sollten die YAML-Definition sehen. Sie sollte so aussehen:
Generierte YAML-Spezifikation
pipeline: transforms: - name: SqlTransformSource type: ReadFromCsv config: path: 'gs://cloud-samples-data/dataflow/tutorials/restaurant-data.csv' - name: SqlTransform type: Sql config: query: >- select Category, count(*) as category_count from PCOLLECTION group by Category input: input0: SqlTransformSource - name: SqlTransformSink type: WriteToJson input: SqlTransform config: path: 'gs://BUCKET_NAME/output/restaurant-data_transform-sql.json'
Klicken Sie im Bereich Dataflow-Optionen auf Job ausführen.
Jobausgabe prüfen
Wenn der Job abgeschlossen ist, führen Sie die folgenden Schritte aus, um die Ausgabe der Pipeline zu sehen:
Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
Klicken Sie in der Bucket-Liste auf den Namen des Buckets, den Sie unter Cloud Storage-Bucket erstellen erstellt haben.
Klicken Sie auf die Datei mit dem Namen
restaurant-data_transform-sql.json-00000-of-00001.Klicken Sie auf der Seite Objektdetails auf die authentifizierte URL, um die Pipelineausgabe aufzurufen.
Die Ausgabe sollte in etwa so aussehen:
{"Category":"Entree","category_count":16}
{"Category":"Beverage","category_count":14}
{"Category":"Appetizer\/Side","category_count":7}
{"Category":"Dessert","category_count":5}
{"Category":"Breakfast","category_count":6}
{"Category":"Salad","category_count":3}
Bereinigen
Damit Ihrem Google Cloud-Konto die in dieser Anleitung verwendeten Ressourcen nicht in Rechnung gestellt werden, löschen Sie entweder das Projekt, das die Ressourcen enthält, oder Sie behalten das Projekt und löschen die einzelnen Ressourcen.
Projekt löschen
- Wechseln Sie in der Google Cloud -Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Beenden), um das Projekt zu löschen.
Einzelne Ressourcen löschen
Wenn Sie das Projekt später wiederverwenden möchten, können Sie es behalten, aber die Ressourcen löschen, die Sie während der Anleitung erstellt haben.
Dataflow-Pipeline anhalten
Rufen Sie in der Google Cloud Console die Dataflow-Seite Jobs auf.
Klicken Sie auf den Job, den Sie beenden möchten.
Zum Beeinden eines Jobs muss der Status des Jobs Wird ausgeführt sein.
Klicken Sie auf der Seite mit den Jobdetails auf Beenden.
Klicken Sie auf Abbrechen.
Klicken Sie auf Job anhalten, um die Auswahl zu bestätigen.
Cloud Storage-Bucket löschen
- Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
- Klicken Sie auf das Kästchen neben dem Bucket, der gelöscht werden soll.
- Klicken Sie zum Löschen des Buckets auf Löschen und folgen Sie der Anleitung.
Nächste Schritte
- Weitere Informationen zum Erstellen von Jobs mit der Job Builder-Benutzeroberfläche in der Google Cloud Console
- Weitere Informationen zu benutzerdefinierten Jobs im Job-Builder finden Sie unter Job mit dem Job-Builder erstellen.
- Lesen Sie die Übersicht zur Beam YAML API.
- Weitere Beispiele für Beam-YAML