
Exécuter un pipeline à l'aide du générateur de jobs
Ce guide de démarrage rapide explique comment exécuter un job Dataflow à l'aide du générateur de jobs Dataflow. Le générateur de jobs est une interface utilisateur visuelle permettant de créer et d'exécuter des pipelines Dataflow dans la console Google Cloud , sans avoir à écrire de code.
Dans ce guide de démarrage rapide, vous allez charger un exemple de pipeline dans le générateur de jobs, exécuter un job et vérifier que le job a créé une sortie.
Avant de commencer
Effectuez les étapes suivantes avant d'exécuter votre pipeline.
Configurer votre projet
- Connectez-vous à votre compte Google Cloud . Si vous débutez sur Google Cloud, créez un compte pour évaluer les performances de nos produits en conditions réelles. Les nouveaux clients bénéficient également de 300 $ de crédits sans frais pour exécuter, tester et déployer des charges de travail.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, and Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, and Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.- Créez un bucket Cloud Storage :
- Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
- Cliquez sur Créer.
- Sur la page Créer un bucket, saisissez les informations concernant votre bucket. Pour passer à l'étape suivante, cliquez sur Continuer.
- Pour Nommer votre bucket, saisissez un nom unique. N'incluez aucune information sensible dans le nom des buckets, car leur espace de noms est global et visible par tous.
-
Dans la section Choisir l'emplacement de stockage de vos données, procédez comme suit :
- Sélectionnez un type d'emplacement.
- Choisissez un emplacement où les données de votre bucket seront stockées de manière permanente dans le menu déroulant Type d'emplacement.
- Si vous sélectionnez le type d'emplacement birégional, vous pouvez également choisir d'activer la réplication turbo à l'aide de la case à cocher correspondante.
- Pour configurer la réplication entre buckets, sélectionnez Ajouter une réplication entre buckets via le service de transfert de stockage et suivez ces étapes :
Configurer la réplication entre buckets
- Dans le menu Bucket, sélectionnez un bucket.
Dans la section Paramètres de réplication, cliquez sur Configurer pour configurer les paramètres du job de réplication.
Le volet Configurer la réplication entre buckets s'affiche.
- Pour filtrer les objets à répliquer en fonction du préfixe de leur nom, saisissez le préfixe avec lequel vous souhaitez inclure ou exclure des objets, puis cliquez sur Ajouter un préfixe.
- Pour définir une classe de stockage pour les objets répliqués, sélectionnez-en une dans le menu Classe de stockage. Si vous ignorez cette étape, les objets répliqués utiliseront la classe de stockage par défaut du bucket de destination.
- Cliquez sur OK.
-
Dans la section Choisir comment stocker vos données, procédez comme suit :
- Dans la section Définir une classe par défaut, sélectionnez Standard.
- Pour activer l'espace de noms hiérarchique, dans la section Optimiser l'espace de stockage pour les charges de travail utilisant beaucoup de données, sélectionnez Activer l'espace de noms hiérarchique sur ce bucket.
- Dans la section Choisir comment contrôler l'accès aux objets, indiquez si votre bucket applique ou non la protection contre l'accès public et sélectionnez une méthode de contrôle des accès pour les objets de votre bucket.
-
Dans la section Choisir comment protéger les données d'objet, procédez comme suit :
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Pour activer la suppression réversible, cochez la case Règle de suppression réversible (pour la récupération de données), puis spécifiez le nombre de jours pendant lesquels vous souhaitez conserver les objets après leur suppression.
- Pour configurer la gestion des versions d'objets, cochez la case Gestion des versions des objets (pour le contrôle des versions), puis spécifiez le nombre maximal de versions par objet et le nombre de jours après lesquels les versions obsolètes expirent.
- Pour activer la règle de conservation sur les objets et les buckets, cochez la case Conservation (pour la conformité), puis procédez comme suit :
- Pour activer le verrou de conservation des objets, cochez la case Activer la conservation des objets.
- Pour activer le verrou de bucket, cochez la case Définir une règle de conservation du bucket, puis choisissez une unité de temps et une durée pour votre période de conservation.
- Pour choisir comment vos données d'objet seront chiffrées, développez la section Chiffrement des données (), puis sélectionnez une méthode de chiffrement des données.
- Sous Protection des données, sélectionnez les options que vous souhaitez définir pour votre bucket.
- Cliquez sur Créer.
Rôles requis
Pour obtenir les autorisations nécessaires pour exécuter ce guide de démarrage rapide, demandez à votre administrateur de vous accorder les rôles IAM suivants sur votre projet :
- Développeur Dataflow (
roles/dataflow.developer) - Utilisateur du compte de service (
roles/iam.serviceAccountUser)
Pour en savoir plus sur l'attribution de rôles, consultez la page Gérer l'accès aux projets, aux dossiers et aux organisations.
Vous pouvez également obtenir les autorisations requises avec des rôles personnalisés ou d'autres rôles prédéfinis.
Pour vous assurer que les comptes de service disposent des autorisations nécessaires pour exécuter ce guide de démarrage rapide, demandez à votre administrateur d'accorder les rôles IAM suivants aux comptes de service de votre projet :
- Nœud de calcul Dataflow (
roles/dataflow.worker) - Administrateur des objets de l'espace de stockage (
roles/storage.objectAdmin)
Pour en savoir plus sur l'attribution de rôles, consultez Gérer l'accès aux projets, aux dossiers et aux organisations.
Votre administrateur peut également attribuer aux comptes de service les autorisations requises à l'aide de rôles personnalisés ou d'autres rôles prédéfinis.
Réseau VPC
Par défaut, chaque nouveau projet démarre avec un réseau par défaut.
Si le réseau par défaut de votre projet est désactivé ou a été supprimé, vous devez disposer d'un réseau dans votre projet pour lequel votre compte utilisateur dispose du rôle Utilisateur de réseau Compute (roles/compute.networkUser).
Charger l'exemple de pipeline
À cette étape, vous allez charger un exemple de pipeline qui compte les mots dans Le Roi Lear de Shakespeare.
Accédez à la page Jobs de la console Google Cloud .
Cliquez sur Créer un job à partir d'un modèle.
Cliquez sur Générateur de tâches.
Cliquez sur Charger les plans.
Cliquez sur Nombre de mots. Le générateur de jobs est renseigné avec une représentation graphique du pipeline.
Pour chaque étape du pipeline, le générateur de jobs affiche une fiche qui spécifie les paramètres de configuration de cette étape. Par exemple, la première étape lit les fichiers texte à partir de Cloud Storage. L'emplacement des données sources est prérempli dans la zone Emplacement du texte.
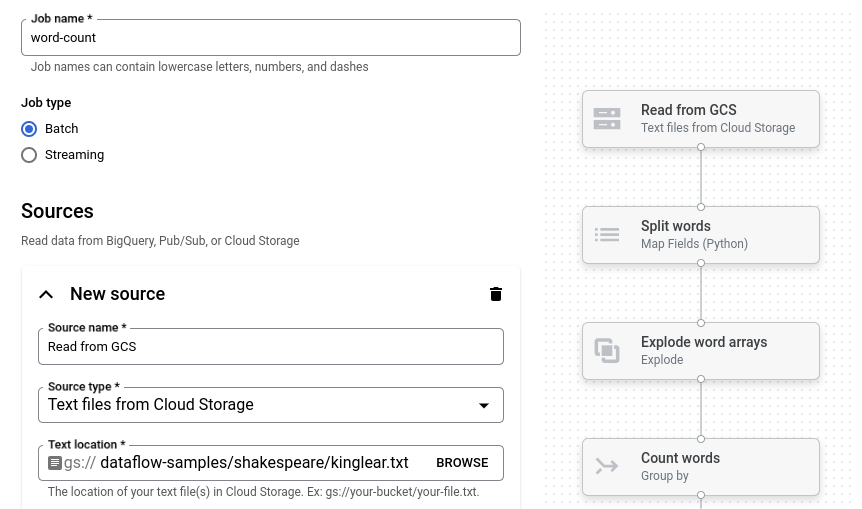
Définir l'emplacement de sortie
Au cours de cette étape, vous allez spécifier un bucket Cloud Storage dans lequel le pipeline écrit la sortie.
Recherchez la fiche intitulée Nouveau récepteur. Vous devrez peut-être faire défiler la page.
Dans la zone Emplacement du texte, cliquez sur Parcourir.
Sélectionnez le nom du bucket Cloud Storage que vous avez créé dans la section Avant de commencer.
Cliquez sur Afficher les ressources enfants.
Dans la zone "Nom de fichier", saisissez
words.Cliquez sur Sélectionner.
Exécuter le job
Cliquez sur Run Job (Exécuter la tâche). Le générateur de jobs crée un job Dataflow, puis accède au graphique de job. Au démarrage du job, le graphique de job affiche une représentation graphique du pipeline, semblable à celle affichée dans le générateur de jobs. À chaque étape du pipeline, l'état est mis à jour dans le graphique de job.
Le panneau Informations sur le job affiche l'état général du job. Si le job se termine correctement, le champ État du job est défini sur Succeeded.
Examiner le résultat du job
Une fois le job terminé, procédez comme suit pour afficher la sortie du pipeline :
Dans la console Google Cloud , accédez à la page Buckets Cloud Storage.
Dans la liste des buckets, cliquez sur le nom du bucket que vous avez créé à la section Avant de commencer.
Cliquez sur le fichier nommé
words-00000-of-00001.Sur la page Détails de l'objet, cliquez sur l'URL authentifiée pour afficher la sortie du pipeline.
Le résultat doit ressembler à ce qui suit :
brother: 20
deeper: 1
wrinkles: 1
'alack: 1
territory: 1
dismiss'd: 1
[....]
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cette démonstration soient facturées sur votre compte Google Cloud , procédez comme suit :
Supprimer le projet
Le moyen le plus simple d'éviter la facturation consiste à supprimer le Google Cloud projet que vous avez créé pour le guide de démarrage rapide.
- Dans la console Google Cloud , accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
Supprimer les ressources individuelles
Si vous souhaitez conserver le projet Google Cloud que vous avez utilisé dans ce guide de démarrage rapide, supprimez le bucket Cloud Storage :
- Dans la console Google Cloud , accédez à la page Buckets de Cloud Storage.
- Cochez la case correspondant au bucket que vous souhaitez supprimer.
- Pour supprimer le bucket, cliquez sur Supprimer , puis suivez les instructions.