
Pipeline mit dem Job-Builder ausführen
In diesem Schnellstart erfahren Sie, wie Sie einen Dataflow-Job mit dem Dataflow Job Builder ausführen. Der Job Builder ist eine visuelle Benutzeroberfläche zum Erstellen und Ausführen von Dataflow Pipelines in der Google Cloud Console, ohne Code schreiben zu müssen.
In diesem Schnellstart laden Sie eine Beispielpipeline in den Job-Builder, führen einen Job aus und prüfen, ob der Job eine Ausgabe erstellt hat.
Hinweis
Führen Sie die folgenden Schritte aus, bevor Sie Ihre Pipeline ausführen.
Projekt einrichten
- Melden Sie sich in Ihrem Google Cloud -Konto an. Wenn Sie noch kein Google Cloud-Konto haben, erstellen Sie ein Konto, um die Leistungsfähigkeit unserer Produkte in der Praxis sehen und bewerten zu können. Neukunden erhalten außerdem ein Guthaben von 300 $, um Arbeitslasten auszuführen, zu testen und bereitzustellen.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, and Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Dataflow, Compute Engine, Cloud Logging, Cloud Storage, Google Cloud Storage JSON, and Resource Manager APIs.
Roles required to enable APIs
To enable APIs, you need the
serviceusage.services.enablepermission. If you created the project, then you likely already have this permission through the Owner role (roles/owner). Otherwise, you can get this permission through the Service Usage Admin role (roles/serviceusage.serviceUsageAdmin). Learn how to grant roles.- Erstellen Sie einen Cloud Storage-Bucket:
- Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
- Klicken Sie auf Erstellen.
- Geben Sie auf der Seite Bucket erstellen die Bucket-Informationen ein. Klicken Sie auf Weiter, um mit dem nächsten
Schritt fortzufahren.
- Geben Sie unter Bucket benennen einen eindeutigen Bucket-Namen ein. Der Bucket-Name darf keine vertraulichen Informationen enthalten, da der Bucket-Namespace global und öffentlich sichtbar ist.
-
Gehen Sie im Abschnitt Speicherort für Daten auswählen so vor:
- Wählen Sie einen Standorttyp aus.
- Wählen Sie im Drop-down-Menü Standorttyp einen Standort aus, an dem die Daten Ihres Buckets dauerhaft gespeichert werden sollen.
- Wenn Sie den Standorttyp Dual-Region auswählen, können Sie auch die Turboreplikation aktivieren, indem Sie das entsprechende Kästchen anklicken.
- Wenn Sie die Bucket-übergreifende Replikation einrichten möchten, wählen Sie
Bucket-übergreifende Replikation über Storage Transfer Service hinzufügen aus und
führen Sie die folgenden Schritte aus:
Bucket-übergreifende Replikation einrichten
- Wählen Sie im Menü Bucket einen Bucket aus.
Klicken Sie im Bereich Replikationseinstellungen auf Konfigurieren , um die Einstellungen für den Replikationsjob zu konfigurieren.
Der Bereich Bucket-übergreifende Replikation konfigurieren wird angezeigt.
- Wenn Sie die zu replizierenden Objekte nach dem Objektnamenspräfix filtern möchten, geben Sie ein Präfix ein, mit dem Sie Objekte ein- oder ausschließen möchten, und klicken Sie dann auf Präfix hinzufügen.
- Wenn Sie eine Speicherklasse für die replizierten Objekte festlegen möchten, wählen Sie im Menü Speicherklasse eine Speicherklasse aus. Wenn Sie diesen Schritt überspringen, wird für replizierte Objekte standardmäßig die Speicherklasse des Ziel-Buckets verwendet.
- Klicken Sie auf Fertig.
-
Gehen Sie im Abschnitt Speicherort für Daten auswählen so vor:
- Wählen Sie im Abschnitt Standardklasse festlegen die Option: Standard aus.
- Wenn Sie den hierarchischen Namespace aktivieren möchten, wählen Sie im Abschnitt Speicher für datenintensive Arbeitslasten optimieren die Option Hierarchischen Namespace für diesen Bucket aktivieren aus.
- Im Abschnitt Zugriff auf Objekte steuern wählen Sie aus, ob der Bucket Verhinderung des öffentlichen Zugriffs durchsetzt, und wählen Sie eine Methode für die Zugriffssteuerung für die Objekte Ihres Buckets.
-
Gehen Sie im Bereich Auswählen, wie Objektdaten geschützt werden so vor:
- Wählen Sie eine der Optionen unter Datenschutz aus, die Sie
für Ihren Bucket festlegen möchten.
- Wenn Sie das vorläufige Löschen aktivieren möchten, klicken Sie das Kästchen Richtlinie für vorläufiges Löschen (zur Datenwiederherstellung) an, und geben Sie die Anzahl der Tage an, die Objekte nach dem Löschen aufbewahrt werden sollen.
- Wenn Sie die Objektversionsverwaltung einrichten möchten, klicken Sie das Kästchen Objektversionierung (zur Versionsverwaltung) an und geben Sie die maximale Anzahl der Versionen pro Objekt und die Anzahl der Tage an, nach denen die nicht aktuellen Versionen ablaufen.
- Wenn Sie die Aufbewahrungsrichtlinie für Objekte und Buckets aktivieren möchten, klicken Sie das Kästchen Aufbewahrung (zur Compliance) an und gehen Sie so vor:
- Wenn Sie die Objektaufbewahrungssperre aktivieren möchten, klicken Sie das Kästchen Objektaufbewahrung aktivieren an.
- Wenn Sie die Bucket-Sperre aktivieren möchten, klicken Sie das Kästchen Aufbewahrungsrichtlinie für Bucket festlegen an und wählen Sie eine Zeiteinheit und eine Zeitdauer für die Aufbewahrungsdauer aus.
- Wenn Sie auswählen möchten, wie Ihre Objektdaten verschlüsselt werden, maximieren Sie den Datenverschlüsselung-Bereich () und wählen Sie eine Datenverschlüsselung-Methode aus.
- Wählen Sie eine der Optionen unter Datenschutz aus, die Sie
für Ihren Bucket festlegen möchten.
- Klicken Sie auf Erstellen.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen für Ihr Projekt zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Ausführen dieser Kurzanleitung benötigen:
- Dataflow-Entwickler (
roles/dataflow.developer) - Service Account User (
roles/iam.serviceAccountUser)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Damit die Dienstkonten die erforderlichen Berechtigungen zum Ausführen dieser Kurzanleitung haben, bitten Sie Ihren Administrator, den Dienstkonten in Ihrem Projekt die folgenden IAM-Rollen zuzuweisen:
- Dataflow-Worker (
roles/dataflow.worker) - Storage-Objekt-Administrator (
roles/storage.objectAdmin)
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Ihr Administrator kann den Dienstkonten möglicherweise auch die erforderlichen Berechtigungen über benutzerdefinierte Rollen oder andere vordefinierte Rollen erteilen.
VPC-Netzwerk
Standardmäßig beginnt jedes neue Projekt mit einem
Standardnetzwerk.
Wenn das Standardnetzwerk für Ihr Projekt deaktiviert
oder gelöscht wurde, benötigen Sie in Ihrem Projekt ein Netzwerk, für das
Ihr Nutzerkonto die
Rolle Compute-Netzwerknutzer
(roles/compute.networkUser) hat.
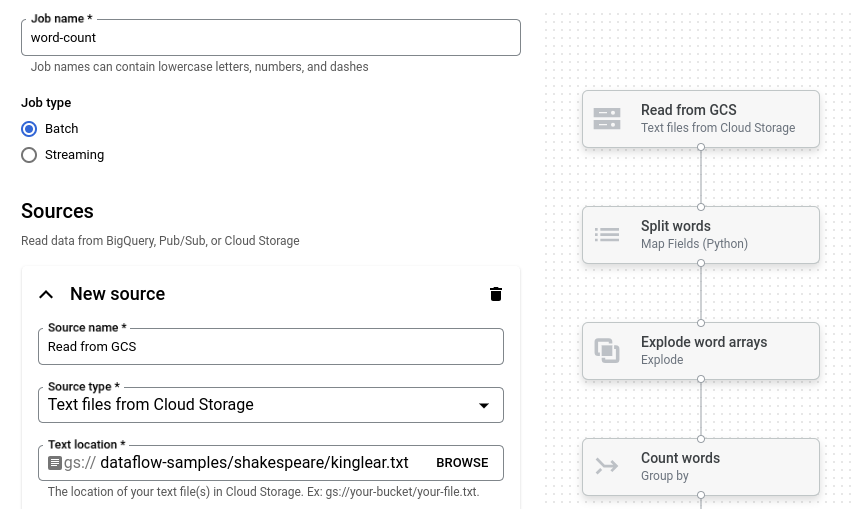
Beispielpipeline laden
In diesem Schritt laden Sie eine Beispielpipeline, die die Wörter in King Lear von Shakespeare zählt.
Rufen Sie in der Google Cloud Console die Seite Jobs auf.
Klicken Sie auf Job aus Vorlage erstellen.
Klicken Sie auf Job-Builder.
Klicken Sie auf Blaupausen laden.
Klicken Sie auf Wörter zählen. Der Job-Builder wird mit einer grafischen Darstellung der Pipeline gefüllt.
Für jeden Pipelineschritt zeigt der Job-Builder eine Karte mit den Konfigurationsparametern für diesen Schritt an. Im ersten Schritt werden beispielsweise Textdateien aus Cloud Storage gelesen. Der Speicherort der Quelldaten ist im Feld Textspeicherort bereits eingetragen.
Ausgabespeicherort festlegen
In diesem Schritt geben Sie einen Cloud Storage-Bucket an, in den die Pipeline die Ausgabe schreibt.
Suchen Sie die Karte mit dem Titel Neue Senke. Möglicherweise müssen Sie scrollen.
Klicken Sie im Feld Textspeicherort auf Durchsuchen.
Wählen Sie den Namen des Cloud Storage-Bucket aus, den Sie in Vorbereitung erstellt haben.
Klicken Sie auf Untergeordnete Ressourcen ansehen.
Geben Sie im Feld „Dateiname“
wordsein.Klicken Sie auf Auswählen.
Job ausführen
Klicken Sie auf Job ausführen. Der Job-Builder erstellt einen Dataflow-Job und wechselt dann zur Jobgrafik. Wenn der Job gestartet wird, zeigt die Jobgrafik eine grafische Darstellung der Pipeline an, ähnlich der im Job-Builder. Bei der Ausführung der einzelnen Schritte der Pipeline wird der Status in der Jobgrafik aktualisiert.
Im Bereich Jobinformationen wird der Gesamtstatus des Jobs angezeigt. Wenn der Job erfolgreich abgeschlossen wurde, wird das Feld Jobstatus auf Succeeded aktualisiert.
Jobausgabe prüfen
Führen Sie nach Abschluss des Jobs die folgenden Schritte aus, um die Ausgabe der Pipeline zu sehen:
Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
Klicken Sie in der Bucket-Liste auf den Namen des Buckets, den Sie in Vorbereitungerstellt haben.
Klicken Sie auf die Datei mit dem Namen
words-00000-of-00001.Klicken Sie auf der Seite Objektdetails auf die authentifizierte URL, um die Pipelineausgabe anzusehen.
Die Ausgabe sollte in etwa so aussehen:
brother: 20
deeper: 1
wrinkles: 1
'alack: 1
territory: 1
dismiss'd: 1
[....]
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden:
Projekt löschen
Am einfachsten vermeiden Sie weitere Kosten durch Löschen des Google Cloud Projekts das Sie für diesen Schnellstart erstellt haben.
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie dann auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Shut down (Herunterfahren), um das Projekt zu löschen.
Einzelne Ressourcen löschen
Wenn Sie das Google Cloud in diesem Schnellstart verwendete Projekt beibehalten möchten, löschen Sie den Cloud Storage-Bucket:
- Wechseln Sie in der Google Cloud Console unter „Cloud Storage“ zur Seite Buckets.
- Klicken Sie auf das Kästchen neben dem Bucket, der gelöscht werden soll.
- Klicken Sie zum Löschen des Buckets, auf Löschen und folgen Sie der Anleitung.