
אפשר להשתמש ב-RunInference API כדי ליצור צינורות שמכילים כמה מודלים. צינורות של כמה מודלים שימושיים למשימות כמו בדיקות A/B ויצירת קבוצות של מודלים כדי לפתור בעיות עסקיות שדורשות יותר ממודל אחד של למידת מכונה.
שימוש בכמה מודלים
בדוגמאות הקוד הבאות אפשר לראות איך משתמשים בטרנספורמציה RunInference כדי להוסיף כמה מודלים לצינור.
כשיוצרים צינורות עם כמה מודלים, אפשר להשתמש באחד משני דפוסים:
- תבנית של הסתעפות A/B: חלק מנתוני הקלט מועבר למודל אחד, ושאר הנתונים מועברים למודל שני.
- דפוס רצף: נתוני הקלט עוברים דרך שני מודלים, אחד אחרי השני.
דפוס A/B
בדוגמת הקוד הבאה אפשר לראות איך מוסיפים תבנית A/B לצינור העיבוד באמצעות רכיב ה-RunInference Transform.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('a_source')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = data | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A ו-MODEL_HANDLER_B הם קוד ההגדרה של רכיב ה-handler של המודל.
הדיאגרמה הבאה מספקת הצגה חזותית של תהליך זה.
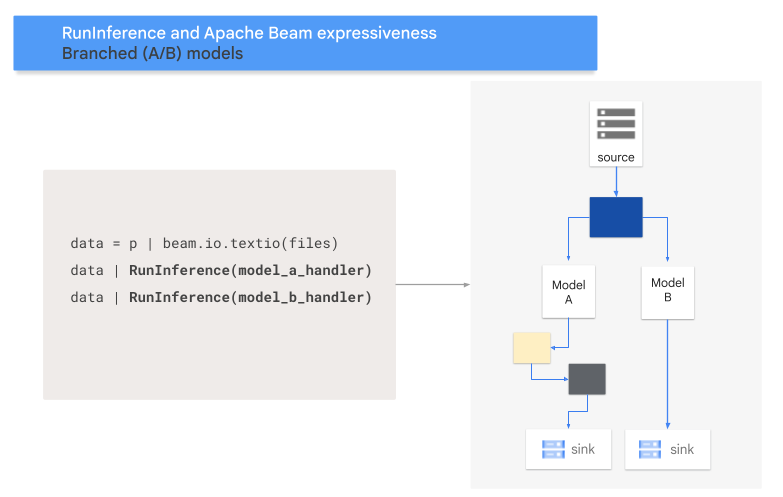
תבנית רצף
בדוגמה הבאה אפשר לראות איך מוסיפים תבנית רצף לצנרת באמצעות הטרנספורמציה RunInference.
with pipeline as p:
data = p | 'Read' >> beam.ReadFromSource('A_SOURCE')
model_a_predictions = data | RunInference(MODEL_HANDLER_A)
model_b_predictions = model_a_predictions | beam.Map(some_post_processing) | RunInference(MODEL_HANDLER_B)
MODEL_HANDLER_A ו-MODEL_HANDLER_B הם קוד ההגדרה של רכיב ה-handler של המודל.
הדיאגרמה הבאה מספקת הצגה חזותית של תהליך זה.
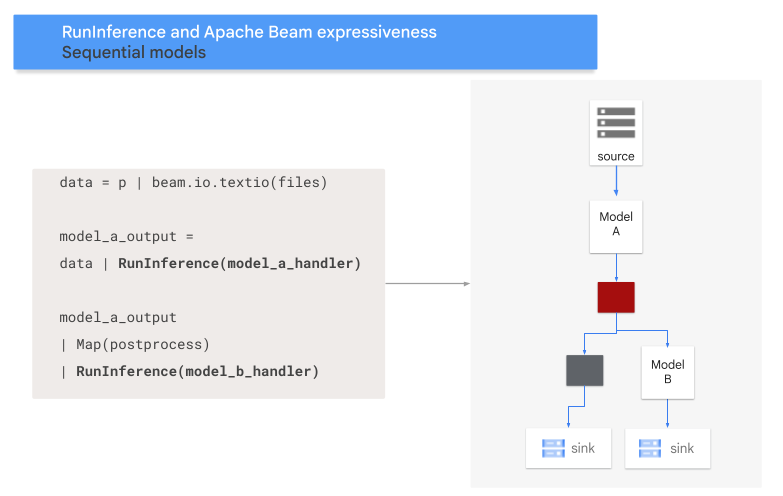
מיפוי מודלים למקשים
אפשר לטעון כמה מודלים ולמפות אותם למקשים באמצעות handler של מודל עם מקשים.
מיפוי מודלים למפתחות מאפשר להשתמש במודלים שונים באותה טרנספורמציה RunInference.
בדוגמה הבאה נעשה שימוש ב-handler של מודל עם מפתח, שטוען מודל אחד באמצעות CONFIG_1 ומודל שני באמצעות CONFIG_2.
בצינור נעשה שימוש במודל שמשויך ל-CONFIG_1 כדי להריץ הסקה על דוגמאות שמשויכות ל-KEY_1.
המודל שמשויך ל-CONFIG_2 מריץ הסקה על דוגמאות שמשויכות ל-KEY_2 ול-KEY_3.
from apache_beam.ml.inference.base import KeyedModelHandler
keyed_model_handler = KeyedModelHandler([
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2))
])
with pipeline as p:
data = p | beam.Create([
('KEY_1', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_2', torch.tensor([[1,2,3],[4,5,6],...])),
('KEY_3', torch.tensor([[1,2,3],[4,5,6],...])),
])
predictions = data | RunInference(keyed_model_handler)
דוגמה מפורטת יותר זמינה במאמר בנושא הפעלת הסקה של ML עם כמה מודלים שאומנו בצורה שונה.
ניהול הזיכרון
כשמעמיסים כמה מודלים בו-זמנית, יכול להיות שיופיעו שגיאות של חוסר זיכרון (OOM). כשמשתמשים ב-handler של מודל עם מפתח, Apache Beam לא מגביל באופן אוטומטי את מספר המודלים שנטענים לזיכרון. אם כל המודלים לא נכנסים לזיכרון, מתרחשת שגיאת חוסר זיכרון, והצינור נכשל.
כדי להימנע מהבעיה הזו, כדאי להשתמש בפרמטר max_models_per_worker_hint כדי להגביל את מספר המודלים שנטענים לזיכרון בו-זמנית. בדוגמה הבאה נעשה שימוש בפרמטר max_models_per_worker_hint עם handler של מודל עם מפתח.
הסיבה לכך היא שערך הפרמטר max_models_per_worker_hint מוגדר ל-2, ולכן הצינור טוען לכל היותר שני מודלים בכל תהליך עובד של ה-SDK בו-זמנית.
mhs = [
KeyModelMapping(['KEY_1'], PytorchModelHandlerTensor(CONFIG_1)),
KeyModelMapping(['KEY_2', 'KEY_3'], PytorchModelHandlerTensor(CONFIG_2)),
KeyModelMapping(['KEY_4'], PytorchModelHandlerTensor(CONFIG_3)),
KeyModelMapping(['KEY_5', 'KEY_5', 'KEY_6'], PytorchModelHandlerTensor(CONFIG_4)),
]
keyed_model_handler = KeyedModelHandler(mhs, max_models_per_worker_hint=2)
כשמתכננים את צינור עיבוד הנתונים, חשוב לוודא שלעובדים יש מספיק זיכרון גם למודלים וגם לטרנספורמציות של צינור עיבוד הנתונים. יכול להיות שהזיכרון שבו משתמשים המודלים לא ישוחרר באופן מיידי, ולכן כדי להימנע משגיאות OOM, כדאי לכלול מאגר זיכרון נוסף.
אם יש לכם הרבה מודלים ואתם משתמשים בערך נמוך עם הפרמטר max_models_per_worker_hint, יכול להיות שתיתקלו בבעיה של thrashing בזיכרון. תופעת ה-thrashing בזיכרון מתרחשת כשמשתמשים בזמן ביצוע מוגזם כדי להחליף מודלים בזיכרון ומחוצה לו. כדי להימנע מהבעיה הזו, צריך לכלול טרנספורמציה של GroupByKey בצינור לפני שלב ההסקה. הטרנספורמציה GroupByKey מוודאת שרכיבים עם אותו מפתח ומודל נמצאים באותו worker.
מידע נוסף
- מידע נוסף על צינורות של כמה מודלים זמין במסמכי התיעוד של Apache Beam
- הפעלת הסקה של ML עם כמה מודלים שאומנו בצורה שונה.
- הפעלת קובץ notebook אינטראקטיבי ב-Colab.