
Halaman ini menjelaskan alasan dan cara menggunakan fitur MLTransform untuk menyiapkan data Anda guna melatih model machine learning (ML). Secara khusus, halaman ini menunjukkan cara memproses data dengan membuat embedding menggunakan MLTransform.
Dengan menggabungkan beberapa transformasi pemrosesan data dalam satu class, MLTransform menyederhanakan proses penerapan operasi pemrosesan data ML Apache Beam ke alur kerja Anda.
MLTransform dalam tahap pra-pemrosesan alur kerja.
Ringkasan embedding
Embedding sangat penting untuk aplikasi penelusuran semantik modern dan Retrieval Augmented Generation (RAG). Embedding memungkinkan sistem memahami dan berinteraksi dengan informasi pada tingkat yang lebih dalam dan konseptual. Dalam penelusuran semantik, embedding mengubah kueri dan dokumen menjadi representasi vektor. Representasi ini menangkap makna dan hubungan yang mendasarinya. Oleh karena itu, Anda dapat menemukan hasil yang relevan meskipun kata kuncinya tidak cocok secara langsung. Hal ini merupakan lompatan signifikan di luar penelusuran berbasis kata kunci standar. Anda juga dapat menggunakan embedding untuk rekomendasi produk. Hal ini mencakup penelusuran multimodal yang menggunakan gambar dan teks, log analytics, dan untuk tugas seperti penghapusan duplikat.
Dalam RAG, embedding memainkan peran penting dalam mengambil konteks yang paling relevan dari pusat informasi untuk merujuk respons model bahasa besar (LLM). Dengan embedding kueri pengguna dan potongan informasi dalam pusat informasi, sistem RAG dapat secara efisien mengidentifikasi dan mengambil potongan yang paling mirip secara semantik. Pencocokan semantik ini memastikan bahwa LLM memiliki akses ke informasi yang diperlukan untuk menghasilkan jawaban yang akurat dan informatif.
Menyerap dan memproses data untuk embedding
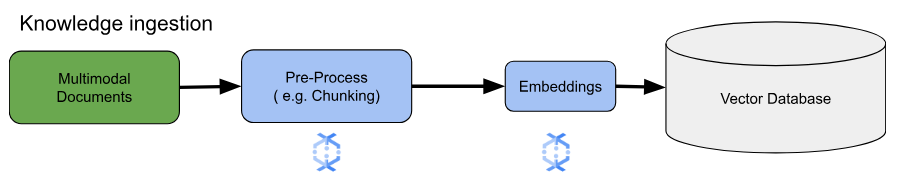
Untuk kasus penggunaan embedding inti, pertimbangan utamanya adalah cara menyerap dan memproses pengetahuan. Penyerapan ini dapat dilakukan secara batch atau streaming. Sumber pengetahuan ini dapat sangat bervariasi. Misalnya, informasi ini dapat berasal dari file yang disimpan di Cloud Storage, atau dapat berasal dari sumber streaming seperti Pub/Sub atau Layanan Terkelola Google Cloud untuk Apache Kafka.
Untuk sumber streaming, data itu sendiri mungkin berupa konten mentah (misalnya, teks biasa) atau URI yang mengarah ke dokumen. Terlepas dari sumbernya, tahap pertama biasanya melibatkan pra-pemrosesan informasi. Untuk teks mentah, hal ini mungkin minimal, seperti pembersihan data dasar. Namun, untuk dokumen yang lebih besar atau konten yang lebih kompleks, langkah pentingnya adalah chunking. Chunking melibatkan pemecahan materi sumber menjadi unit-unit yang lebih kecil dan mudah dikelola. Strategi chunking yang optimal tidak distandardisasi dan bergantung pada data dan aplikasi tertentu. Platform seperti Dataflow menawarkan kemampuan bawaan untuk menangani berbagai kebutuhan chunking, sehingga menyederhanakan tahap pra-pemrosesan penting ini.
Manfaat
Class MLTransform memberikan manfaat berikut:
- Membuat embedding yang dapat Anda gunakan untuk mengirimkan data ke database vektor atau untuk menjalankan inferensi.
- Mentransformasikan data Anda tanpa perlu menulis kode yang kompleks atau mengelola library yang mendasarinya.
- Merangkai beberapa jenis operasi pemrosesan secara efisien dengan satu antarmuka.
Dukungan dan batasan
Class MLTransform memiliki batasan berikut:
- Tersedia untuk pipeline yang menggunakan Apache Beam Python SDK versi 2.53.0 dan yang lebih baru.
- Pipeline harus menggunakan jendela default.
Transformasi embedding teks:
- Mendukung Python 3.8, 3.9, 3.10, 3.11, dan 3.12.
- Mendukung pipeline batch dan streaming.
- Mendukung Vertex AI text-embeddings API dan modul Hugging Face Sentence Transformers.
Kasus penggunaan
Notebook contoh menunjukkan cara menggunakan MLTransform untuk kasus penggunaan tertentu.
- Saya ingin membuat embedding teks untuk LLM saya menggunakan Vertex AI
- Gunakan class
MLTransformApache Beam dengan Vertex AI text-embeddings API untuk membuat embedding teks. Embedding teks adalah cara untuk merepresentasikan teks sebagai vektor numerik, yang diperlukan untuk banyak tugas natural language processing (NLP). - Saya ingin membuat embedding teks untuk LLM saya menggunakan Hugging Face
- Gunakan class
MLTransformApache Beam dengan model Hugging Face Hub untuk membuat embedding teks. Framework Hugging FaceSentenceTransformersmenggunakan Python untuk membuat embedding kalimat, teks, dan gambar. - Saya ingin membuat embedding teks dan memasukkannya ke AlloyDB untuk PostgreSQL
- Gunakan Apache Beam, khususnya
MLTransformclass dengan modelHugging Face Hub untuk membuat embedding teks. Kemudian, gunakanVectorDatabaseWriteTransformuntuk memuat embedding dan metadata terkait ini ke dalam AlloyDB untuk PostgreSQL. Notebook ini menunjukkan cara membuat pipeline data batch dan streaming Beam yang skalabel untuk mengisi database vektor AlloyDB untuk PostgreSQL Hal ini mencakup penanganan data dari berbagai sumber seperti Pub/Sub atau tabel database yang ada, pembuatan skema kustom, dan update data. - Saya ingin membuat embedding teks dan memasukkannya ke BigQuery
- Gunakan class
MLTransformApache Beam dengan model Hugging Face Hub untuk membuat embedding teks dari data aplikasi, seperti katalog produk. TransformasiHuggingfaceTextEmbeddingsApache Beam digunakan untuk hal ini. Transformasi ini menggunakan framework SentenceTransformers Hugging Face, yang menyediakan model untuk membuat embedding kalimat dan teks. Embedding yang dibuat dan metadatanya kemudian diserap ke BigQuery menggunakanVectorDatabaseWriteTransformApache Beam. Notebook ini selanjutnya mendemonstrasikan penelusuran kemiripan vektor di BigQuery menggunakan transformasi Enrichment.
Untuk mengetahui daftar lengkap transformasi yang tersedia, lihat Transformasi dalam dokumentasi Apache Beam.
Menggunakan MLTransform untuk pembuatan embedding
Untuk menggunakan class MLTransform guna membagi informasi dan membuat embedding, sertakan kode berikut dalam pipeline Anda:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
Contoh sebelumnya membuat satu bagian per elemen, tetapi Anda juga dapat menggunakan LangChain untuk membuat potongan:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
Langkah berikutnya
- Baca postingan blog "Cara mengaktifkan aplikasi RAG dan penelusuran semantik real-time dengan Dataflow ML".
- Untuk mengetahui detail selengkapnya tentang
MLTransform, lihat Pra-pemrosesan data di dokumentasi Apache Beam. - Untuk contoh lainnya, lihat
MLTransformuntuk pemrosesan data di katalog transformasi Apache Beam. - Jalankan notebook interaktif di Colab.