
בדף הזה נסביר למה כדאי להשתמש בתכונה MLTransform כדי להכין את הנתונים לאימון מודלים של למידת מכונה (ML), ואיך משתמשים בה. באופן ספציפי, בדף הזה מוסבר איך לעבד נתונים על ידי יצירת הטמעות באמצעות MLTransform.
כשמשלבים כמה טרנספורמציות של עיבוד נתונים במחלקה אחת, MLTransformהתהליך של החלת פעולות עיבוד נתונים של Apache Beam ML על תהליך העבודה מתייעל.
MLTransform בשלב העיבוד המקדים של תהליך העבודה.
סקירה כללית על הטמעות
הטמעות חיוניות לחיפוש סמנטי מודרני ולאפליקציות של Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). הטמעות מאפשרות למערכות להבין מידע ולקיים איתו אינטראקציה ברמה עמוקה יותר, ברמה מושגית. בחיפוש סמנטי, הטמעה משנה שאילתות ומסמכים לייצוגים וקטוריים. הייצוגים האלה משקפים את המשמעות הבסיסית שלהם ואת קשרי הגומלין ביניהם. כתוצאה מכך, אפשר למצוא תוצאות רלוונטיות גם כשמילות המפתח לא תואמות באופן ישיר. זו התקדמות משמעותית מעבר לחיפוש רגיל שמבוסס על מילות מפתח. אפשר גם להשתמש בהטמעות להמלצות על מוצרים. השימוש הזה כולל חיפושים מולטי-מודאליים שמתבססים על תמונות וטקסט, ניתוח יומנים ומשימות כמו הסרת כפילויות.
ב-RAG, הטמעות ממלאות תפקיד מכריע באחזור ההקשר הרלוונטי ביותר מבסיס ידע, כדי לבסס את התשובות של מודלים גדולים של שפה (LLM). על ידי הטמעת השאילתה של המשתמש וקטעי המידע בבסיס הידע, מערכות RAG יכולות לזהות ולאחזר ביעילות את החלקים הכי דומים מבחינה סמנטית. ההתאמה הסמנטית הזו מבטיחה שלמודל ה-LLM תהיה גישה למידע הנדרש כדי ליצור תשובות מדויקות ואינפורמטיביות.
הטמעה ועיבוד של נתונים להטמעות
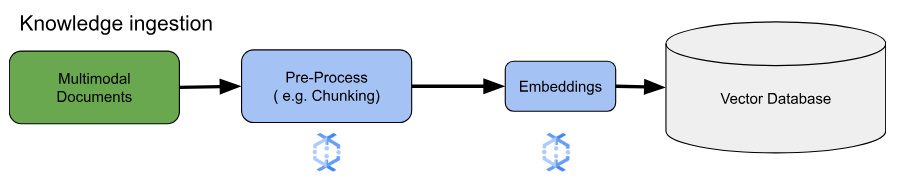
בתרחישי שימוש מרכזיים בהטמעה, השיקול העיקרי הוא איך להזין ולעבד ידע. ההעברה הזו יכולה להתבצע באצווה או בסטרימינג. המקור של הידע הזה יכול להיות מגוון מאוד. לדוגמה, המידע הזה יכול להגיע מקבצים ששמורים ב-Cloud Storage, או ממקורות סטרימינג כמו Pub/Sub או השירות המנוהל של Google Cloud ל-Apache Kafka.
במקורות סטרימינג, הנתונים עצמם יכולים להיות התוכן הגולמי (לדוגמה, טקסט פשוט) או כתובות URI שמפנות למסמכים. לא משנה מה המקור, בשלב הראשון בדרך כלל מתבצעת עיבוד מוקדם של המידע. במקרה של טקסט חופשי, יכול להיות שהפעולה תהיה מינימלית, כמו ניקוי בסיסי של הנתונים. עם זאת, כשמדובר במסמכים גדולים יותר או בתוכן מורכב יותר, שלב חיוני הוא חלוקה לחלקים. חלוקה לחלקים קטנים היא תהליך שבו מחלקים את חומר המקור ליחידות קטנות ופשוטות יותר. אין אסטרטגיה אופטימלית אחידה לפיצול נתונים, והיא תלויה בנתונים ובאפליקציה הספציפיים. פלטפורמות כמו Dataflow מציעות יכולות מובנות לטיפול בצורכי חלוקה מגוונים, וכך מפשטות את שלב העיבוד המקדים החיוני הזה.
יתרונות
היתרונות של סוג האחסון MLTransform:
- ליצור הטמעות שאפשר להשתמש בהן כדי להעביר נתונים למאגרי נתונים וקטוריים או כדי להריץ הסקה.
- אפשר לשנות את הנתונים בלי לכתוב קוד מורכב או לנהל ספריות בסיסיות.
- אפשר לשרשר ביעילות כמה סוגים של פעולות עיבוד בממשק אחד.
תמיכה ומגבלות
יש מגבלות על השימוש בסוג האחסון MLTransform:
- האפשרות הזו זמינה לצינורות שמשתמשים בגרסאות 2.53.0 ואילך של Apache Beam Python SDK.
- בצינורות צריך להשתמש בdefault windows.
טרנספורמציות של הטמעת טקסט:
- תמיכה ב-Python 3.8, 3.9, 3.10, 3.11 ו-3.12.
- תמיכה בצינורות עיבוד נתונים באצווה ובסטרימינג.
- תמיכה ב-Gemini Enterprise Agent Platform text-embeddings API וב-Hugging Face Sentence Transformers module.
תרחישים לדוגמה
במחברות לדוגמה אפשר לראות איך משתמשים ב-MLTransform לתרחישי שימוש ספציפיים.
- אני רוצה ליצור הטמעות של טקסט עבור מודל LLM באמצעות צינורות של Agent Platform
- משתמשים במחלקה
MLTransformשל Apache Beam עם Agent Platform Pipelines text-embeddings API כדי ליצור הטמעות של טקסט. הטמעות של טקסט הן דרך לייצג טקסט כווקטורים מספריים, וזה נחוץ להרבה משימות של עיבוד שפה טבעית (NLP). - אני רוצה ליצור הטמעות טקסט עבור מודל LLM באמצעות Hugging Face
- שימוש במחלקת Apache Beam
MLTransformעם מודלים של Hugging Face Hub כדי ליצור הטמעות טקסט. Hugging FaceSentenceTransformersמשתמש ב-Python כדי ליצור הטמעות של משפטים, טקסט ותמונות. - אני רוצה ליצור הטמעות של טקסט ולהטמיע אותן ב-AlloyDB ל-PostgreSQL
- שימוש ב-Apache Beam, במיוחד במחלקה
MLTransformשלו עם מודלים של Hugging Face Hub כדי ליצור הטמעות טקסט. לאחר מכן, משתמשים ב-VectorDatabaseWriteTransformכדי לטעון את ההטמעות האלה ואת המטא-נתונים המשויכים ל-AlloyDB ל-PostgreSQL. במחברת הזו מוצגות דוגמאות לבניית צינורות להעברת נתונים ב-Beam, שאפשר להרחיב אותם כדי לאכלס מסד נתונים וקטורי ב-AlloyDB ל-PostgreSQL. הפעולות האלה כוללות טיפול בנתונים ממקורות שונים כמו Pub/Sub או טבלאות קיימות במסד נתונים, יצירת סכימות מותאמות אישית ועדכון נתונים. - אני רוצה ליצור הטמעות טקסט ולהטמיע אותן ב-BigQuery
- שימוש במחלקת Apache Beam
MLTransformעם מודלים של Hugging Face Hub כדי ליצור הטמעות טקסט מנתוני אפליקציה, כמו קטלוג מוצרים. לצורך זה משתמשים בטרנספורמציהHuggingfaceTextEmbeddingsשל Apache Beam. הטרנספורמציה הזו משתמשת ב-framework SentenceTransformers של Hugging Face, שמספק מודלים ליצירת הטמעות של משפטים וטקסט. ההטמעות שנוצרו והמטא-נתונים שלהן מוזנים ל-BigQuery באמצעות Apache BeamVectorDatabaseWriteTransform. במחברת מוצגות דוגמאות נוספות לחיפושים של דמיון בין וקטורים ב-BigQuery באמצעות טרנספורמציית ההעשרה.
רשימה מלאה של טרנספורמציות זמינה במאמר Transforms במסמכי Apache Beam.
שימוש ב-MLTransform ליצירת הטמעה
כדי להשתמש במחלקה MLTransform כדי לחלק מידע לחלקים קטנים וליצור הטמעות, צריך לכלול את הקוד הבא בצינור העיבוד:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
בדוגמה הקודמת נוצר צ'אנק אחד לכל רכיב, אבל אפשר גם להשתמש ב-LangChain כדי ליצור צ'אנקים:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
המאמרים הבאים
- מומלץ לקרוא את פוסט הבלוג "How to enable real time semantic search and RAG applications with Dataflow ML".
- לפרטים נוספים על
MLTransform, אפשר לעיין במאמר Preprocess data (עיבוד מקדים של נתונים) במסמכי התיעוד של Apache Beam. - דוגמאות נוספות זמינות במאמר
MLTransformבנושא עיבוד נתונים בקטלוג הטרנספורמציות של Apache Beam. - הפעלת notebook אינטראקטיבי ב-Colab.