
Das richtige Feature verwendet Apache Beam-Ressourcenhinweise, um Worker-Ressourcen für eine Pipeline anzupassen. Die Möglichkeit, mehrere verschiedene Ressourcen auf bestimmte Pipelineschritte anzuwenden, bietet zusätzliche Pipelineflexibilität und -funktionen sowie potenzielle Kosteneinsparungen. Sie können teurere Ressourcen auf Pipelineschritte anwenden, die sie benötigen, und weniger teure Ressourcen auf andere Pipelineschritte. Verwenden Sie die richtige Anpassung, um Ressourcenanforderungen für eine gesamte Pipeline oder für bestimmte Pipelineschritte anzugeben.
Unterstützung und Einschränkungen
- Ressourcenhinweise werden mit den Apache Beam Java SDK und Python SDK Version 2.31.0 und höher unterstützt.
- Right Fitting wird bei Batchpipelines unterstützt.
Right Fitting wird bei Streamingpipelines mit aktiviertem horizontalen Autoscaling unterstützt.
- Sie können sie aktivieren, indem Sie die Pipelineoption
--experiments=enable_streaming_rightfittingfestlegen.
- Sie können sie aktivieren, indem Sie die Pipelineoption
Right Fitting unterstützt Dataflow Prime.
Right Fitting unterstützt nicht FlexRS.
Wenn Sie die richtige Anpassung verwenden, verwenden Sie nicht die Dienstoption
worker_accelerator.Wenn Sie Dataflow Prime verwenden, wird die automatische VM-Auswahl nicht unterstützt.
Richtige Anpassung aktivieren
Verwenden Sie einen oder mehrere verfügbare Ressourcenhinweise in Ihrer Pipeline, um die richtige Anpassung zu aktivieren. Wenn Sie in Ihrer Pipeline einen Ressourcenhinweis verwenden, wird die korrekte Anpassung automatisch aktiviert. Weitere Informationen finden Sie im Abschnitt Ressourcenhinweise verwenden in diesem Dokument.
Verfügbare Ressourcenhinweise
Die folgenden Ressourcenhinweise sind verfügbar:
| Ressourcenhinweis | Beschreibung |
|---|---|
min_ram |
Die Mindestmenge an RAM in Gigabyte, die Workern zugewiesen werden soll. Dataflow verwendet diesen Wert als Untergrenze, wenn neuen Workern (horizontale Skalierung) oder vorhandenen Workern (vertikale Skalierung) Arbeitsspeicher zugewiesen wird. Beispiel: min_ram=NUMBERGB
|
cpu_count |
Die Anzahl der vCPUs, die pro Worker zugewiesen werden sollen. Wenn Sie diesen Ressourcenhinweis verwenden, wählt Dataflow Maschinentypen aus, die die angegebene Anzahl von vCPUs haben und die Arbeitsspeicheranforderungen erfüllen. Beispiel: cpu_count=NUMBER
|
accelerator |
Eine vom Nutzer bereitgestellte Zuweisung von GPUs, mit der Sie die Nutzung und Kosten von GPUs in Ihrer Pipeline und deren Schritten steuern können. Geben Sie den Typ und die Anzahl der GPUs an, die an Dataflow-Worker als Parameter für das Flag angehängt werden sollen. Beispiel: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
Weitere Informationen zur Verwendung von GPUs finden Sie unter GPUs mit Dataflow. |
Automatische VM-Auswahl für Worker-Maschinentypen
Wenn Sie min_ram- oder cpu_count-Ressourcenhinweise für Pipelineschritte verwenden, für die keine Beschleuniger erforderlich sind, wird Instanzflexibilität (automatische VM-Auswahl) automatisch aktiviert. Bei der automatischen VM-Auswahl werden Worker aus einer Auswahl von Maschinentypen bereitgestellt, die Ihre RAM- und CPU-Anforderungen erfüllen.
Bei der automatischen VM-Auswahl wird die VM-Auswahl in erster Linie auf Zuverlässigkeit und nicht auf Leistung optimiert. Das bedeutet, dass die Leistung möglicherweise geringer ist, wenn Sie die automatische VM-Auswahl verwenden, um die Zuverlässigkeit einiger Ihrer hochgradig optimierten Jobs zu verbessern. Wir empfehlen, die automatische VM-Auswahl für eine Teilmenge Ihrer vorhandenen Jobs zu testen, bevor Sie sie nach und nach breiter einsetzen.
Wenn Sie Compute Engine-Reservierungen mit der automatischen VM-Auswahl verwenden, beachten Sie Folgendes:
- Wenn Sie Reservierungen haben, die automatisch genutzt werden, können sie verwendet werden, wenn Compute Engine VMs eines passenden Maschinentyps bereitstellt.
- Die automatische VM-Auswahl unterstützt nicht das Nutzen von Instanzen aus einer bestimmten Reservierung.
- Die automatische VM-Auswahl wird in Dataflow Prime nicht unterstützt.
Weitere Informationen finden Sie unter Instanzflexibilität und Reservierungen.
Verschachtelung von Ressourcenhinweisen
Ressourcenhinweise werden so auf die Pipeline-Transformationshierarchie angewendet:
min_ram: Der Wert einer Transformation wird als der größtemin_ram-Hinweiswert unter den Werten ausgewertet, die für die Transformation selbst und alle übergeordneten Elemente in der Transformationshierarchie festgelegt sind.- Beispiel: Wenn ein Hinweis zur inneren Transformation
min_ramauf 16 GB und der Hinweis zur äußeren Transformation in der Hierarchiemin_ramauf 32 GB festlegt, wird ein Hinweis von 32 GB für alle Schritte in der gesamten Transformation verwendet. - Beispiel: Wenn ein Hinweis zur inneren Transformation
min_ramauf 16 GB und der Hinweis zur äußeren Transformation in der Hierarchiemin_ramauf 8 GB festlegt, wird für alle Schritte in der äußeren Transformation ein Hinweis von 8 GB verwendet, die nicht in der inneren Transformation sind, und für alle Schritte in der inneren Transformation wird ein 16-GB-Hinweis verwendet.
- Beispiel: Wenn ein Hinweis zur inneren Transformation
accelerator: Der innerste Wert in der Hierarchie der Transformation hat Vorrang.- Wenn sich beispielsweise ein Hinweis
acceleratorzur inneren Transformation von dem Hinweisacceleratorzur äußeren Transformation in einer Hierarchie unterscheidet, wird der Hinweisacceleratorzur inneren Transformation für die innere Transformation verwendet.
- Wenn sich beispielsweise ein Hinweis
Pipelinehinweise: Hinweise, die für die gesamte Pipeline festgelegt werden, werden so behandelt, als wären sie für eine separate äußerste Transformation festgelegt.
Ressourcenhinweise verwenden
Sie können Ressourcenhinweise für die gesamte Pipeline oder für Pipelineschritte festlegen.
Ressourcenhinweise für Pipelines
Ressourcenhinweise lassen sich für die gesamte Pipeline festlegen, wenn Sie die Pipeline über die Befehlszeile ausführen.
Informationen zum Einrichten Ihrer Python-Umgebung finden Sie im Python-Tutorial.
Beispiel:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=cpu_count=number \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
Ressourcenhinweise für Pipelineschritte
Sie können Ressourcenhinweise für Pipelineschritte (Transformationen) programmatisch festlegen.
Java
Informationen zum Installieren des Apache Beam SDK für Java finden Sie unter Apache Beam SDK installieren.
Mit der Klasse ResourceHints können Sie Ressourcenhinweise programmatisch für Pipelinetransformationen festlegen.
Das folgende Beispiel zeigt, wie Ressourcenhinweise programmatisch für Pipeline-Transformationen festgelegt werden.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withCpuCount(8)
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create()
.withMinRam("30GB")
.withCpuCount(16)))
Verwenden Sie die ResourceHintsOptions-Oberfläche, um Ressourcenhinweise für die gesamte Pipeline programmatisch festzulegen.
Python
Informationen zum Installieren des Apache Beam SDK für Python finden Sie unter Apache Beam SDK installieren.
Mit der Klasse PTransforms.with_resource_hints können Sie Ressourcenhinweise programmatisch für Pipelinetransformationen festlegen.
Weitere Informationen finden Sie im Artikel zur Klasse ResourceHint.
Das folgende Beispiel zeigt, wie Ressourcenhinweise programmatisch für Pipeline-Transformationen festgelegt werden.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
cpu_count=8,
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB",
cpu_count=16)
Wenn Sie Ressourcenhinweise für die gesamte Pipeline festlegen möchten, verwenden Sie beim Ausführen der Pipeline die Pipelineoption --resource_hints. Ein Beispiel finden Sie unter Ressourcenhinweise für Pipeline.
Go
Ressourcenhinweise werden in Go nicht unterstützt.
Unterstützung mehrerer Beschleuniger
Innerhalb einer Pipeline können verschiedene Transformationen unterschiedliche Beschleunigerkonfigurationen haben. Dazu gehören Konfigurationen, für die unterschiedliche Maschinentypen erforderlich sind. Diese Beschleunigerkonfigurationen auf Transformationsebene haben Vorrang vor der Konfiguration auf Pipelineebene, sofern eine angegeben wurde.
Richtige Anpassung und Zusammenführung
In einigen Fällen können im Rahmen der Zusammenführungsoptimierung Transformationen mit verschiedenen Ressourcenhinweisen auf Workern im selben Worker-Pool ausgeführt werden. Wenn Transformationen zusammengeführt werden, führt Dataflow sie in einer Umgebung aus, die die Vereinigung der auf den Transformationen festgelegten Ressourcenhinweise erfüllt. In einigen Fällen umfasst dies die gesamte Pipeline.
Wenn Ressourcenhinweise nicht zusammengeführt werden können, findet keine Zusammenführung statt. Ressourcenhinweise für verschiedene GPUs können beispielsweise nicht zusammengeführt werden. Daher werden diese Transformationen nicht zusammengeführt.
Sie können die Zusammenführung auch verhindern, indem Sie Ihrer Pipeline einen Vorgang hinzufügen, der Dataflow zwingt, eine zwischengeschaltete PCollection zu realisieren. Das ist besonders nützlich, wenn Sie versuchen, teure Ressourcen wie GPUs oder Maschinen mit hohem Arbeitsspeicher von langsamen oder rechenintensiven Schritten zu isolieren, für die diese speziellen Ressourcen nicht erforderlich sind. In diesen Fällen kann es hilfreich sein, einen Fusionsbruch zwischen den langsamen CPU-gebundenen Schritten und den Schritten zu erzwingen, für die die teuren GPUs oder Maschinen mit hohem Arbeitsspeicher erforderlich sind, und die Kosten für die Materialisierung zu tragen, die mit dem Aufbrechen der Fusion verbunden sind. Weitere Informationen finden Sie unter Zusammenführung verhindern.
Individuelle Anpassung für Streaming
Für Streamingjobs können Sie die richtige Anpassung aktivieren, indem Sie die Pipelineoption --experiments=enable_streaming_rightfitting festlegen.
Durch die richtige Anpassung kann die Leistung Ihrer Pipeline verbessert werden, wenn sie Phasen mit unterschiedlichen Ressourcenanforderungen umfasst.
Beispiel: Pipeline mit CPU-intensiver Phase und GPU-erforderlicher Phase
Ein Beispiel für eine Pipeline, die von Right Fitting profitieren kann, ist eine Pipeline, in der eine CPU-intensive Phase ausgeführt wird, gefolgt von einer Phase, die GPUs erfordert. Ohne Right Fitting muss ein einzelner GPU-Worker-Pool konfiguriert werden, um alle Pipelinephasen auszuführen, einschließlich der CPU-intensiven Phase. Dies kann zu einer Unterauslastung der GPU-Ressourcen führen, wenn im Worker-Pool die CPU-intensive Phase ausgeführt wird.
Wenn Right Fitting aktiviert ist und ein Ressourcenhinweis auf den GPU-erforderlichen Schritt angewendet wird, werden in der Pipeline zwei separate Pools erstellt, sodass die CPU-intensive Phase vom CPU-Worker-Pool und die GPU-erforderliche Phase vom GPU-Worker-Pool ausgeführt wird.
In der Autoscaling-Tabelle für diese Beispielpipeline ist zu sehen, dass der Worker-Pool, der die CPU-intensive Phase Pool 0 ausführt, zuerst auf 99 Worker hochskaliert und später auf 87 Worker herunterskaliert wird. Der Worker-Pool, in dem die GPU-erforderliche Phase Pool 1 ausgeführt wird, wird auf 13 Worker hochskaliert:
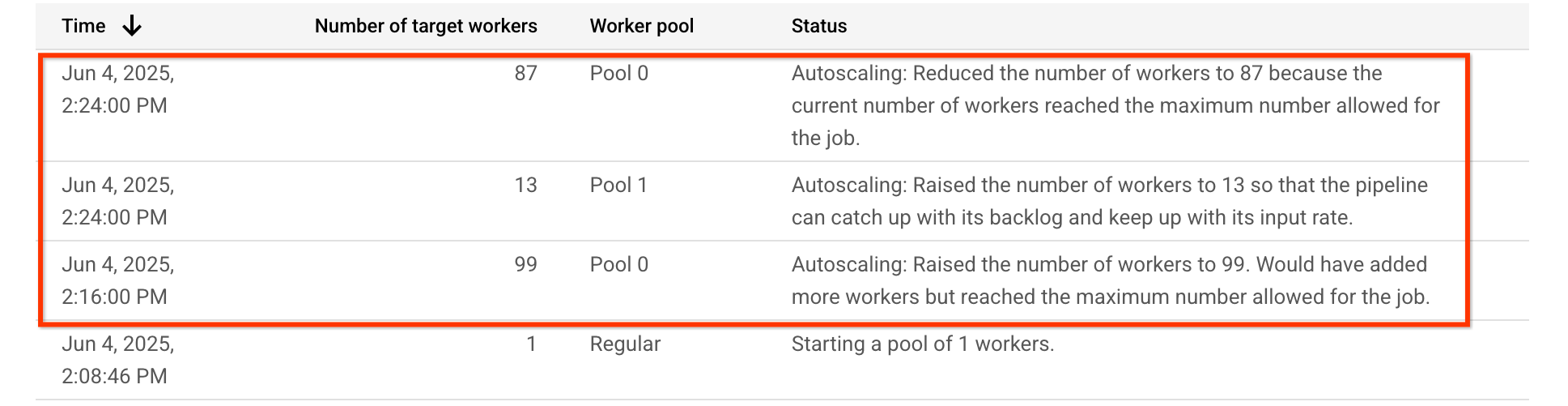
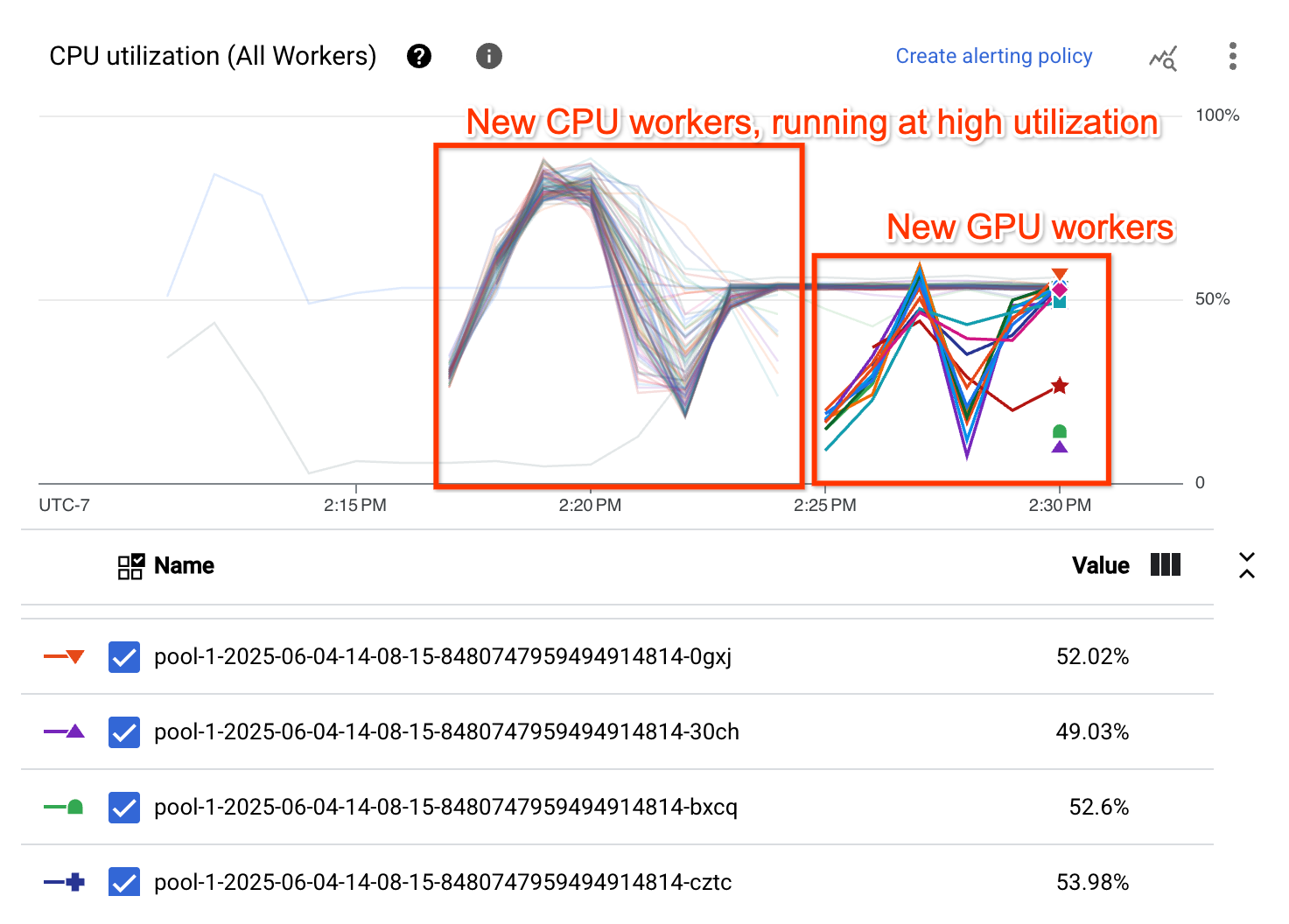
Das Diagramm zur CPU-Auslastung zeigt, dass die Worker in beiden Worker-Pools insgesamt eine hohe CPU-Auslastung aufweisen:
Fehler bei der richtigen Anpassung beheben
In diesem Abschnitt finden Sie eine Anleitung zur Behebung häufiger Probleme im Zusammenhang mit der richtigen Anpassung.
Ungültige Konfiguration
Wenn Sie versuchen, die richtige Anpassung zu verwenden, tritt der folgende Fehler auf:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
Dieser Fehler tritt auf, wenn der ausgewählte GPU-Typ nicht mit dem ausgewählten Maschinentyp kompatibel ist. Wählen Sie einen kompatiblen GPU-Typ und Maschinentyp aus, um diesen Fehler zu beheben. Weitere Informationen zur Kompatibilität finden Sie unter GPU-Plattformen.
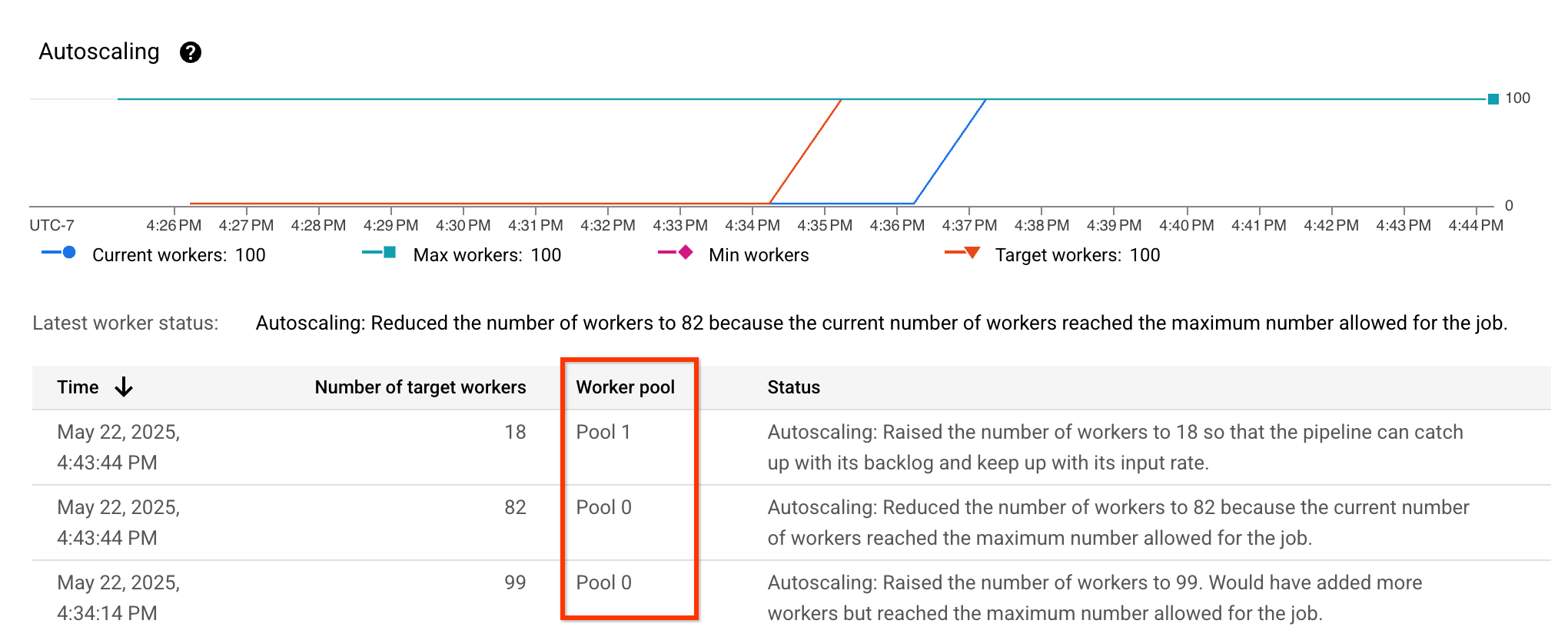
Richtige Anpassung prüfen
Sie können prüfen, ob die richtige Anpassung aktiviert ist, indem Sie sich die Autoscaling-Messwerte ansehen und prüfen, ob die Spalte Worker pool sichtbar ist und verschiedene Pools enthält:
Leistung bei der richtigen Anpassung von Streaming
Streaming-Pipelines mit aktivierter Right-Fitting-Funktion erzielen möglicherweise nicht immer eine bessere Leistung als Pipelines ohne aktivierte Right-Fitting-Funktion. Beispiel:
- Die Pipeline verwendet mehr Worker.
- Die Systemlatenz ist höher oder der Durchsatz ist niedriger.
- Die Größen der Worker-Pools ändern sich häufiger oder stabilisieren sich nicht.
Wenn Sie dieses Verhalten bei Ihrer Pipeline beobachten, können Sie die Anpassung deaktivieren, indem Sie die Pipelineoption --experiments=enable_streaming_rightfitting entfernen. Außerdem können Streamingpipelines, bei denen die richtige Anpassung mit Ressourcenhinweisen für Beschleuniger aktiviert ist, mehr Beschleuniger verwenden als gewünscht. Wenn Sie dies bei Ihrer Pipeline beobachten, können Sie eine maximale Anzahl von Beschleunigern konfigurieren, die von der Pipeline verwendet werden, indem Sie die Pipelineoption --experiments=max_num_accelerators=NUM festlegen.