
Auf dieser Seite wird erläutert, wie eine Apache Beam-Pipeline in Dataflow mit GPUs ausgeführt wird. Für Jobs, die GPUs verwenden, fallen Gebühren an, wie auf der Preisseite für Dataflow beschrieben.
Weitere Informationen zur Verwendung von GPUs mit Dataflow finden Sie unter Dataflow-Unterstützung für GPUs. Weitere Informationen zum Entwickler-Workflow beim Erstellen von Pipelines mit GPUs finden Sie unter Informationen zu GPUs mit Dataflow.
Apache Beam-Notebooks verwenden
Wenn Sie bereits eine Pipeline haben, die Sie mit GPUs in Dataflow ausführen möchten, können Sie diesen Abschnitt überspringen.
Apache Beam-Notebooks bieten eine bequeme Möglichkeit, Prototypen zu erstellen und Ihre Pipeline mit GPUs iterativ zu entwickeln, ohne eine Entwicklungsumgebung einzurichten. Lesen Sie zuerst die Anleitung Mit Apache Beam-Notebooks entwickeln, starten Sie eine Apache Beam-Notebookinstanz und folgen Sie dem Beispiel-Notebook GPUs mit Apache Beam verwenden.
GPU-Kontingent bereitstellen
GPU-Geräte unterliegen der Kontingentverfügbarkeit Ihres Google Cloud Projekts. Fordern Sie das GPU-Kontingent in der Region Ihrer Wahl an.
GPU-Treiber installieren
Zum Installieren von NVIDIA-Treibern auf den Dataflow-Workern hängen Sie install-nvidia-driver an die worker_accelerator-Dienstoption an.
Wenn Sie die Option install-nvidia-driver angeben, installiert Dataflow NVIDIA-Treiber auf den Dataflow-Workern mit dem Dienstprogramm cos-extensions von Container-Optimized OS. Durch die Angabe von install-nvidia-driver stimmen Sie der NVIDIA-Lizenzvereinbarung zu.
Dataflow unterstützt das Hinzufügen einer Version zur install-nvidia-driver
Option als install-nvidia-driver:VERSION. Die folgenden Versionen werden unterstützt:
- Standard
- Neueste
Wenn keine Version angegeben ist, entspricht dies install-nvidia-driver:default. Wenn eine nicht erkannte Version angegeben wird, schlägt die Installation des GPU-Treibers fehl.
Binärprogramme und Bibliotheken der NVIDIA-Treiberinstallation werden unter /usr/local/nvidia/ bereitgestellt.
Die GPU-Treiberversion
für die Versionen default und latest hängt von der
Version von Container-Optimized OS ab, die derzeit von Dataflow verwendet wird. Suchen Sie in den
Dataflow-Schrittlogs
des Jobs nach GPU driver, um die
GPU-Treiberversion für einen bestimmten Dataflow-Job zu ermitteln.
Wenn Sie nach der Treiberinstallation die Dataflow-Logs prüfen, sehen Sie möglicherweise eine Zeile wie diese:
| NVIDIA-SMI 535.261.03 Driver Version: 535.261.03 CUDA Version: 12.2 |
Die "CUDA-Version" ist in diesem Fall die CUDA-Version des Treibers, die sich unterscheidet von der CUDA-Laufzeitversion, die im benutzerdefinierten oder vorhandenen Container-Image installiert ist. Wenn diese Treiberversion größer oder gleich der Laufzeitversion ist, sind keine weiteren Schritte erforderlich. Wenn es sich um eine frühere Version handelt, müssen Sie beim Erstellen des Container-Images die NVIDIA CUDA-Kompatibilitätsdokumentation beachten.
Benutzerdefiniertes Container-Image erstellen
Für die Interaktion mit den GPUs benötigen Sie möglicherweise zusätzliche NVIDIA-Software, z. B. GPU-beschleunigte Bibliotheken und das CUDA Toolkit. Stellen Sie diese Bibliotheken einem Docker-Container bereit, in dem Nutzercode ausgeführt wird.
Wenn Sie das Container-Image anpassen möchten, stellen Sie ein Image bereit, das den Container-Image-Vertrag des Apache Beam SDK erfüllt und über die erforderlichen GPU-Bibliotheken verfügt.
Wenn Sie ein benutzerdefiniertes Container-Image bereitstellen möchten, verwenden Sie
Dataflow Portable Runner und stellen Sie das
Container-Image mit der sdk_container_image Pipeline-Option bereit.
Wenn Sie Apache Beam Version 2.29.0 oder niedriger verwenden, verwenden Sie die Pipeline-Option worker_harness_container_image. Weitere Informationen finden Sie unter Benutzerdefinierte Container verwenden.
Nutzen Sie einen der folgenden Ansätze, um ein benutzerdefiniertes Container-Image zu erstellen:
- Vorhandenes Image verwenden, das für die GPU-Nutzung konfiguriert ist
- Apache Beam-Container-Image verwenden
Vorhandenes Image verwenden, das für die GPU-Nutzung konfiguriert ist
Sie können ein Docker-Image erstellen, das den Apache Beam SDK-Containervertrag aus einem vorhandenen Basis-Image erfüllt, das für die GPU-Nutzung vorkonfiguriert ist. Zum Beispiel sind TensorFlow-Docker-Images und NVIDIA-Container-Images für die GPU-Nutzung vorkonfiguriert.
Ein Beispiel-Dockerfile, das auf dem Docker-Image von TensorFlow mit Python 3.6 aufbaut, sieht so aus:
ARG BASE=tensorflow/tensorflow:2.5.0-gpu
FROM $BASE
# Check that the chosen base image provides the expected version of Python interpreter.
ARG PY_VERSION=3.6
RUN [[ $PY_VERSION == `python -c 'import sys; print("%s.%s" % sys.version_info[0:2])'` ]] \
|| { echo "Could not find Python interpreter or Python version is different from ${PY_VERSION}"; exit 1; }
RUN pip install --upgrade pip \
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.6 SDK image.
COPY --from=apache/beam_python3.6_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# Some images have pip in a different location. If necessary, make a symlink.
# This line can be omitted in Beam 2.30.0 and later versions.
RUN [[ `which pip` == "/usr/local/bin/pip" ]] || ln -s `which pip` /usr/local/bin/pip
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Wenn Sie TensorFlow-Docker-Images verwenden, verwenden Sie TensorFlow 2.5.0 oder höher. In früheren TensorFlow-Docker-Images wird das Paket tensorflow-gpu anstelle des Pakets tensorflow installiert. Die Unterscheidung ist nach TensorFlow 2.1.0 nicht wichtig, für mehrere nachgelagerte Pakete wie tfx ist jedoch das Paket tensorflow erforderlich.
Große Container verlangsamen die Worker-Startzeit. Diese Leistungsänderung kann auftreten, wenn Sie Container wie Deep Learning Container verwenden.
Bestimmte Python-Version installieren
Wenn Sie strenge Anforderungen an die Python-Version haben, können Sie das Image aus einem NVIDIA-Basis-Image erstellen, das die erforderlichen GPU-Bibliotheken enthält. Anschließend installieren Sie den Python-Interpreter.
Im folgenden Beispiel wird gezeigt, wie Sie ein NVIDIA-Image auswählen, das nicht den Python-Interpreter aus dem CUDA-Container-Image-Katalog enthält. Passen Sie das Beispiel an, um die erforderliche Version von Python 3 und pip zu installieren. Im Beispiel wird TensorFlow verwendet. Achten Sie deshalb bei der Auswahl eines Images darauf, dass die CUDA- und cuDNN-Versionen im Basis-Image die Anforderungen für die TensorFlow-Version erfüllen.
Beispiel für ein Dockerfile:
# Select an NVIDIA base image with needed GPU stack from https://ngc.nvidia.com/catalog/containers/nvidia:cuda
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
RUN \
# Add Deadsnakes repository that has a variety of Python packages for Ubuntu.
# See: https://launchpad.net/~deadsnakes/+archive/ubuntu/ppa
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F23C5A6CF475977595C89F51BA6932366A755776 \
&& echo "deb http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& echo "deb-src http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& apt-get update \
&& apt-get install -y curl \
python3.8 \
# With python3.8 package, distutils need to be installed separately.
python3-distutils \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.8 10 \
&& curl https://bootstrap.pypa.io/get-pip.py | python \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.8 SDK image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Bei einigen Betriebssystem-Distributionen ist es möglicherweise schwierig, bestimmte Python-Versionen mit dem Betriebssystem-Paketmanager zu installieren. In diesem Fall können Sie den Python-Interpreter mit Tools wie Miniconda oder pyenv installieren.
Beispiel für ein Dockerfile:
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
# The Python version of the Dockerfile must match the Python version you use
# to launch the Dataflow job.
ARG PYTHON_VERSION=3.8
# Update PATH so we find our new Conda and Python installations.
ENV PATH=/opt/python/bin:/opt/conda/bin:$PATH
RUN apt-get update \
&& apt-get install -y wget \
&& rm -rf /var/lib/apt/lists/* \
# The NVIDIA image doesn't come with Python pre-installed.
# We use Miniconda to install the Python version of our choice.
&& wget -q https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& bash Miniconda3-latest-Linux-x86_64.sh -b -p /opt/conda \
&& rm Miniconda3-latest-Linux-x86_64.sh \
# Create a new Python environment with needed version, and install pip.
&& conda create -y -p /opt/python python=$PYTHON_VERSION pip \
# Remove unused Conda packages, install necessary Python packages using pip
# to avoid mixing packages from pip and Conda.
&& conda clean -y --all --force-pkgs-dirs \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check \
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# You can omit this line when using Beam 2.30.0 and later versions.
&& ln -s $(which pip) /usr/local/bin/pip
# Copy the Apache Beam worker dependencies from the Apache Beam SDK for Python 3.8 image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Apache Beam-Container-Image verwenden
Sie können ein Container-Image für die GPU-Nutzung konfigurieren, ohne vorkonfigurierte Images zu verwenden. Dieser Ansatz wird nur empfohlen, wenn vorkonfigurierte Images nicht für Sie geeignet sind. Wenn Sie ein eigenes Container-Image einrichten möchten, müssen Sie kompatible Bibliotheken auswählen und deren Ausführungsumgebung konfigurieren.
Beispiel für ein Dockerfile:
FROM apache/beam_python3.7_sdk:2.24.0
ENV INSTALLER_DIR="/tmp/installer_dir"
# The base image has TensorFlow 2.2.0, which requires CUDA 10.1 and cuDNN 7.6.
# You can download cuDNN from NVIDIA website
# https://developer.nvidia.com/cudnn
COPY cudnn-10.1-linux-x64-v7.6.0.64.tgz $INSTALLER_DIR/cudnn.tgz
RUN \
# Download CUDA toolkit.
wget -q -O $INSTALLER_DIR/cuda.run https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run && \
# Install CUDA toolkit. Print logs upon failure.
sh $INSTALLER_DIR/cuda.run --toolkit --silent || (egrep '^\[ERROR\]' /var/log/cuda-installer.log && exit 1) && \
# Install cuDNN.
mkdir $INSTALLER_DIR/cudnn && \
tar xvfz $INSTALLER_DIR/cudnn.tgz -C $INSTALLER_DIR/cudnn && \
cp $INSTALLER_DIR/cudnn/cuda/include/cudnn*.h /usr/local/cuda/include && \
cp $INSTALLER_DIR/cudnn/cuda/lib64/libcudnn* /usr/local/cuda/lib64 && \
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* && \
rm -rf $INSTALLER_DIR
# A volume with GPU drivers will be mounted at runtime at /usr/local/nvidia.
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nvidia/lib64:/usr/local/cuda/lib64
Treiberbibliotheken in /usr/local/nvidia/lib64 müssen im Container als freigegebene Bibliotheken sichtbar sein. Konfigurieren Sie die Umgebungsvariable LD_LIBRARY_PATH, um die Treiberbibliotheken auffindbar zu machen.
Wenn Sie TensorFlow verwenden, müssen Sie eine kompatible Kombination aus CUDA Toolkit- und cuDNN-Versionen auswählen. Weitere Informationen finden Sie unter Softwareanforderungen und Getestete Build-Konfigurationen.
Typ und Anzahl der GPUs für Dataflow-Worker wählen
Mit der Dienstoption worker_accelerator können Sie Typ und Anzahl der GPUs konfigurieren, die an Dataflow-Worker angehängt werden sollen.
Wählen Sie den Typ und die Anzahl der GPUs je nach Anwendungsfall aus und legen Sie fest, wie die GPUs in der Pipeline verwendet werden sollen.
Eine Liste der GPU-Typen, die mit Dataflow unterstützt werden, finden Sie unter Dataflow-Unterstützung für GPUs.
Job mit GPUs ausführen
Folgendes ist für die Ausführung eines Dataflow-Jobs mit GPUs zu beachten:
Da GPU-Container in der Regel groß sind, sollten Sie so vorgehen, um zu vermeiden, dass der Speicherplatz aufgebraucht wird:
- Erhöhen Sie die Standardgröße des Bootlaufwerks auf 50 Gigabyte oder mehr.
Überlegen Sie, wie viele Prozesse gleichzeitig dieselbe GPU auf einer Worker-VM verwenden. Entscheiden Sie dann, ob Sie die GPU auf einen einzelnen Prozess beschränken möchten oder mehrere Prozesse die GPU verwenden möchten.
- Wenn ein Apache Beam SDK-Prozess den Großteil des verfügbaren GPU-Arbeitsspeichers nutzen kann, z. B. durch Laden eines großen Modells auf einer GPU, können Sie Worker so konfigurieren, dass ein einzelner Prozess verwendet wird. Legen Sie dazu die Pipelineoption
--experiments=no_use_multiple_sdk_containersfest. Alternativ können Sie Worker mit einer vCPU verwenden. Verwenden Sie einen benutzerdefinierten Maschinentyp wien1-custom-1-NUMBER_OF_MBodern1-custom-1-NUMBER_OF_MB-extfür erweiterten Speicher: Weitere Informationen finden Sie unter Maschinentyp mit mehr Arbeitsspeicher pro vCPU verwenden. - Wenn die GPU von mehreren Prozessen gemeinsam genutzt wird, aktivieren Sie die gleichzeitige Verarbeitung auf einer freigegebenen GPU mithilfe des NVIDIA-Multi-Verarbeitungsdienstes (MPS).
Weitere Informationen finden Sie unter GPUs und Worker-Parallelität.
- Wenn ein Apache Beam SDK-Prozess den Großteil des verfügbaren GPU-Arbeitsspeichers nutzen kann, z. B. durch Laden eines großen Modells auf einer GPU, können Sie Worker so konfigurieren, dass ein einzelner Prozess verwendet wird. Legen Sie dazu die Pipelineoption
Führen Sie den folgenden Befehl aus, um einen Dataflow-Job mit GPUs auszuführen.
Um die richtige Anpassung zu verwenden, verwenden Sie anstelle der worker_accelerator-Dienstoption den accelerator-Ressourcenhinweis.
Python
python PIPELINE \
--runner="DataflowRunner" \
--project="PROJECT" \
--temp_location="gs://BUCKET/tmp" \
--region="REGION" \
--worker_harness_container_image="IMAGE" \
--disk_size_gb="DISK_SIZE_GB" \
--dataflow_service_options="worker_accelerator=type:GPU_TYPE;count:GPU_COUNT;install-nvidia-driver" \
--experiments="use_runner_v2"
Ersetzen Sie Folgendes:
- PIPELINE: Ihre Quellcode-Pipelinedatei
- PROJECT: der Google Cloud Projektname
- BUCKET: der Cloud Storage-Bucket
- REGION: eine Dataflow-Region, z. B.
us-central1. Wählen Sie eine "REGION" aus, die Zonen enthält, die denGPU_TYPEunterstützen. Dataflow weist Worker einer Zone mit GPUs in dieser Region automatisch zu. - IMAGE: Artifact Registry-Pfad für das Docker-Image
- DISK_SIZE_GB: Größe des Bootlaufwerks für jede Worker-VM, z. B.
50 - GPU_TYPE: ein verfügbarer GPU-Typ, z. B.
nvidia-tesla-t4 - GPU_COUNT: Anzahl der GPUs, die an jede Worker-VM angehängt werden, z. B.
1
Dataflow-Job prüfen
So prüfen Sie, ob der Job Worker-VMs mit GPUs verwendet:
- Überprüfen Sie, ob Dataflow-Worker für den Job gestartet wurden.
- Suchen Sie während der Jobausführung nach einer Worker-VM, die dem Job zugeordnet ist.
- Fügen Sie die Job-ID in den Prompt Produkte und Ressourcen suchen ein.
- Wählen Sie die dem Job zugeordnete Compute Engine-VM-Instanz aus.
Sie können in der Compute Engine-Konsole auch eine Liste aller ausgeführten Instanzen aufrufen.
Rufen Sie in der Google Cloud Console die Seite VM-Instanzen auf:
Klicken Sie auf VM-Instanzdetails.
Prüfen Sie, ob auf der Detailseite ein Abschnitt GPUs vorhanden ist und dass Ihre GPUs angehängt sind.
Wenn Ihr Job nicht mit GPUs gestartet wurde, prüfen Sie, ob die worker_accelerator-Dienstoption richtig konfiguriert ist und in der Dataflow-Monitoring-Oberfläche in dataflow_service_options angezeigt wird. Die Reihenfolge der Tokens in den Accelerator-Metadaten ist wichtig.
Die Pipelineoption dataflow_service_options in der Dataflow-Monitoring-Oberfläche könnte beispielsweise so aussehen:
['worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver', ...]
GPU-Auslastung ansehen
So rufen Sie die GPU-Auslastung auf den Worker-VMs ab:
Rufen Sie in der Google Cloud Console Monitoring auf oder verwenden Sie die folgende Schaltfläche:
Klicken Sie im Navigationsbereich von Monitoring auf Metrics Explorer.
Geben Sie als Ressourcentyp
Dataflow Joban. Geben Sie für den MesswertGPU utilizationoderGPU memory utilizationan, je nachdem, welchen Messwert Sie überwachen möchten.
Weitere Informationen finden Sie unter Metrics Explorer.
NVIDIA-Multi-Verarbeitungsdienst aktivieren
Bei Python-Pipelines, die auf Workern mit mehr als einer vCPU ausgeführt werden, können Sie die Gleichzeitigkeit für GPU-Vorgänge verbessern, indem Sie den NVIDIA Multi-Process-Dienst (MPS) aktivieren. Weitere Informationen und Schritte zur Verwendung von MPS finden Sie unter Leistung auf einer gemeinsam genutzten GPU mit NVIDIA MPS verbessern.
Optional: Bereitstellungsmodell konfigurieren
Sie können die Wahrscheinlichkeit erhöhen, Zugriff auf GPU-Ressourcen zu erhalten, indem Sie ein Bereitstellungsmodell für Ihre Pipeline konfigurieren.
Die folgenden Bereitstellungsmodelle werden von Dataflow unterstützt: „Standard“ und „Flex-Start“.
Standardbereitstellung
Die Standardbereitstellung ist das Standardbereitstellungsmodell für alle Dataflow-Jobs mit GPUs. Instanzen, die Beschleunigerressourcen verwenden, werden sofort basierend auf der Ressourcenverfügbarkeit erstellt.
Sie müssen nichts konfigurieren, um das Standardbereitstellungsmodell zu verwenden.
Wenn GPUs in der Zone oder Region, in der Sie Ihren Dataflow-Job ausführen, nicht sofort verfügbar sind, kann der Job möglicherweise nicht gestartet werden. Weitere Informationen finden Sie unter Job wird beim Start sofort beendet.
Flex-Start-Bereitstellung
Beim Bereitstellungsmodell „Flex-Start“ werden Instanzen und Beschleunigerressourcen zur Bereitstellung geplant und basierend auf der Ressourcenverfügbarkeit bereitgestellt. Mit dem Bereitstellungsmodell „Flex-Start“ können Sie Ihre Chancen erhöhen, GPUs zu erhalten.
Wenn Sie das Bereitstellungsmodell „Flex-Start“ verwenden möchten, hängen Sie provisioning_model:FLEX_START an die
worker_accelerator Dienstoption an. Beispiel:
worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver:latest;provisioning_model:FLEX_START
Jobs mit aktivierter Flex-Start-Funktion werden zur Ausführung eingereicht, aber erst ausgeführt, wenn die erforderlichen Ressourcen verfügbar sind. Prüfen Sie im Job-Meldungslog, ob die Flex-Start-Bereitstellung aktiviert wurde. Suchen Sie nach dem folgenden Logeintrag:
FLEX_START is enabled for job JOB_ID
Auf der Seite mit den Jobmesswerten können Sie im Autoscaling-Diagramm sehen, ob die Jobausführung begonnen hat:
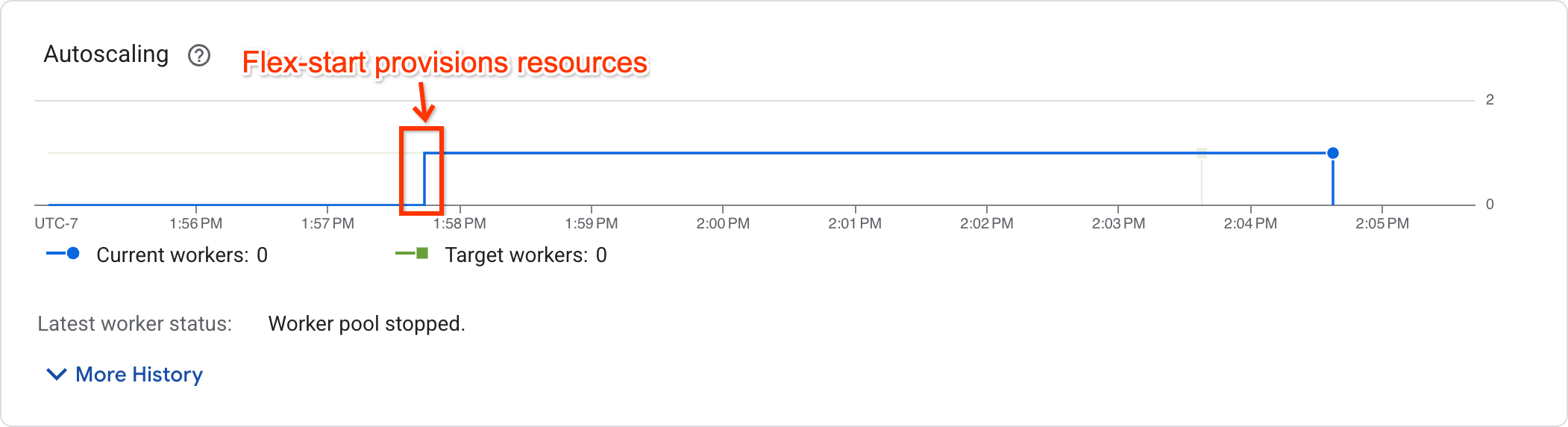
Bei Jobs, deren Ausführung begonnen hat, wird eine Worker-Anzahl ungleich null angezeigt. Bei Jobs, die auf Ressourcen warten, ist die Worker-Anzahl null.
Unterstützung und Einschränkungen
- Flex-Start wird nur für Batchpipelines unterstützt. Streamingpipelines werden nicht unterstützt.
- Worker-VMs, die mit dem Bereitstellungsmodell „Flex-Start“ bereitgestellt werden, haben eine maximale Laufzeit von sieben Tagen. Nach diesem Zeitraum werden Worker-VMs mit Beschleunigern auf Abruf beendet. Dataflow versucht, Ressourcen neu bereitzustellen. Wenn Ressourcen nicht neu bereitgestellt werden können, schlägt die Pipeline fehl.
- Flex-Start versucht bis zu einer Stunde nach der Jobeinreichung, Ressourcen bereitzustellen. Wenn Ressourcen nach einer Stunde nicht bereitgestellt werden können, schlägt der Job fehl.
- Flex-Start verbraucht das Kontingent auf Abruf. Wenn Ihr Projekt kein Kontingent auf Abruf hat, wird das Standardkontingent verwendet. Weitere Informationen finden Sie unter Kontingente auf Abruf.
- Wenn keine Worker-Zonenkonfiguration angegeben ist, wählt Dataflow eine einzelne Zone aus, in der alle Ressourcen erstellt werden. Die Auswahl erfolgt basierend auf Hardwaresupport, aktueller Ressourcen- und Kontingentverfügbarkeit sowie übereinstimmenden Reservierungen. Diese Zone kann sich von der Zone unterscheiden, in der sich die Dienstressourcen für den Job befinden.
- Horizontales Autoscaling wird nicht unterstützt. Wenn Sie mehr als einen Worker verwenden möchten, legen Sie die Pipelineoption
--num_workersfest. - TPUs werden nicht unterstützt.
- Right Fitting wird nicht unterstützt.
Fehlerbehebung bei Flex-Start
Wenn Ihr Job eine Stunde nach der Einreichung mit dem folgenden Fehler fehlschlägt:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Prüfen Sie auf der Seite Kontingente in der Google Cloud Console, ob Ihr Projekt in der konfigurierten Region Ihres Jobs ein ausreichendes PREEMPTIBLE_GPU_TYPE_GPUS Kontingent hat.
Wenn in Ihrem Projekt ein ausreichendes Kontingent vorhanden war, konnte Flex-Start Ressourcen nicht innerhalb einer Stunde bereitstellen. Versuchen Sie, die Pipeline in einer anderen Zone oder mit einem anderen Beschleunigertyp zu starten.
GPUs mit Dataflow Prime verwenden
Mit Dataflow Prime können Sie Beschleuniger für einen bestimmten Schritt Ihrer Pipeline anfordern. Verwenden Sie die Pipeline-Option --dataflow-service_options=worker_accelerator nicht, um GPUs mit Dataflow Prime zu verwenden. Fordern Sie stattdessen die GPUs mit dem Ressourcenhinweis accelerator an.
Weitere Informationen finden Sie unter Ressourcenhinweise verwenden.
Fehlerbehebung bei Dataflow-Jobs
Wenn bei der Ausführung Ihres Dataflow-Jobs mit GPUs Probleme auftreten, lesen Sie die Informationen unter Fehlerbehebung bei Dataflow-GPU-Jobs.
Nächste Schritte
- Weitere Informationen zur GPU-Unterstützung in Dataflow
- Führen Sie Ihre ML-Inferenzpipeline mit dem NVIDIA L4-GPU-Typ aus.
- Landsat-Satellitenbilder mit GPUs verarbeiten