
La funzionalità di adattabilità utilizza gli hint di risorse di Apache Beam per personalizzare le risorse dei worker per una pipeline. La possibilità di indirizzare più risorse diverse a passaggi specifici della pipeline offre maggiore flessibilità e capacità alla pipeline, nonché potenziali risparmi sui costi. Puoi applicare risorse più costose ai passaggi della pipeline che le richiedono e risorse meno costose ad altri passaggi della pipeline. Utilizza l'adattabilità per specificare i requisiti delle risorse per un'intera pipeline o per passaggi specifici della pipeline.
Supporto e limitazioni
- Gli hint di risorse sono supportati con gli SDK Apache Beam Java e Python, versioni 2.31.0 e successive.
- L'adattabilità è supportata con le pipeline in modalità batch.
L'adattabilità è supportata con le pipeline in modalità flusso con la scalabilità automatica orizzontale abilitata.
- Puoi abilitarla impostando l'opzione della pipeline
--experiments=enable_streaming_rightfitting.
- Puoi abilitarla impostando l'opzione della pipeline
L'adattabilità supporta Dataflow Prime.
L'adattabilità non supporta FlexRS.
Quando utilizzi l'adattabilità, non utilizzare l'opzione del
worker_acceleratorservizio.Quando utilizzi Dataflow Prime, la selezione automatica delle VM non è supportata.
Abilita l'adattabilità
Per attivare l'adattabilità, utilizza uno o più degli hint di risorse disponibili nella pipeline. Quando utilizzi un hint di risorse nella pipeline, l'adattabilità viene attivata automaticamente. Per ulteriori informazioni, consulta la sezione Utilizzare gli hint di risorse di questo documento.
Hint di risorse disponibili
Sono disponibili i seguenti hint di risorse.
| Hint di risorse | Descrizione |
|---|---|
min_ram |
La quantità minima di RAM in gigabyte da allocare ai worker. Dataflow utilizza questo valore come limite inferiore quando alloca memoria a nuovi worker (scalabilità orizzontale) o a worker esistenti (scalabilità verticale). Ad esempio: min_ram=NUMBERGB
|
cpu_count |
Il numero di vCPU da allocare per worker. Quando utilizzi questo hint di risorse, Dataflow seleziona i tipi di macchine che hanno il numero specificato di vCPU e soddisfano i requisiti di memoria. Ad esempio: cpu_count=NUMBER
|
accelerator |
Un'allocazione di GPU fornita dall'utente che consente di controllare l'utilizzo e il costo delle GPU nella pipeline e nei relativi passaggi. Specifica il tipo e il numero di GPU da collegare ai worker Dataflow come parametri del flag. Ad esempio: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
Per ulteriori informazioni sull'utilizzo delle GPU, consulta GPU con Dataflow. |
Selezione automatica delle VM per i tipi di macchine worker
Quando utilizzi gli hint di risorse min_ram o cpu_count per i passaggi della pipeline che
non richiedono acceleratori,
la flessibilità delle istanze (selezione automatica delle VM)
viene abilitata automaticamente. Con la selezione automatica delle VM, i worker vengono sottoposti a provisioning da una selezione di tipi di macchine che soddisfano i requisiti di RAM e CPU.
La selezione automatica delle VM ottimizza la selezione delle VM principalmente per l'affidabilità e non per le prestazioni. Ciò significa che potresti riscontrare una riduzione delle prestazioni durante l'utilizzo della selezione automatica delle VM per migliorare l'affidabilità di alcuni dei tuoi job altamente ottimizzati. Ti consigliamo di testare la selezione automatica delle VM su un sottoinsieme dei job esistenti prima di eseguirne il deployment graduale su una scala più ampia.
Se utilizzi le prenotazioni di Compute Engine con la selezione automatica delle VM, tieni presente quanto segue:
- Se hai prenotazioni che vengono utilizzate automaticamente, potrebbero essere utilizzate se Compute Engine esegue il provisioning delle VM di un tipo di macchina corrispondente.
- La selezione automatica delle VM non supporta l'utilizzo di istanze da una prenotazione specifica.
- La selezione automatica delle VM non è supportata con Dataflow Prime.
Per ulteriori informazioni, consulta Flessibilità delle istanze e prenotazioni.
Nidificazione degli hint di risorse
Gli hint di risorse vengono applicati alla gerarchia di trasformazione della pipeline come segue:
min_ram: il valore di una trasformazione viene valutato come il valore dell'hintmin_rampiù grande tra i valori impostati sulla trasformazione stessa e su tutti i relativi genitori nella gerarchia della trasformazione.- Esempio: se un hint di trasformazione interno imposta
min_ramsu 16 GB e l'hint di trasformazione esterno nella gerarchia impostamin_ramsu 32 GB, viene utilizzato un hint di 32 GB per tutti i passaggi dell'intera trasformazione. - Esempio: se un hint di trasformazione interno imposta
min_ramsu 16 GB e l'hint di trasformazione esterno nella gerarchia impostamin_ramsu 8 GB, viene utilizzato un hint di 8 GB per tutti i passaggi della trasformazione esterna che non si trovano nella trasformazione interna e un hint di 16 GB viene utilizzato per tutti i passaggi della trasformazione interna.
- Esempio: se un hint di trasformazione interno imposta
accelerator: il valore più interno nella gerarchia della trasformazione ha la precedenza.- Esempio: se un hint
acceleratordi trasformazione interno è diverso da un hintacceleratordi trasformazione esterno in una gerarchia, l'hintacceleratordi trasformazione interno viene utilizzato per la trasformazione interna.
- Esempio: se un hint
Gli hint impostati per l'intera pipeline vengono trattati come se fossero impostati su una trasformazione esterna separata.
Utilizza gli hint di risorse
Puoi impostare gli hint di risorse sull'intera pipeline o sui passaggi della pipeline.
Hint di risorse della pipeline
Puoi impostare gli hint di risorse sull'intera pipeline quando esegui la pipeline dalla riga di comando.
Per configurare l'ambiente Python, consulta il tutorial su Python.
Esempio:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=cpu_count=number \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
Hint di risorse dei passaggi della pipeline
Puoi impostare gli hint di risorse sui passaggi della pipeline (trasformazioni) a livello di programmazione.
Java
Per installare l'SDK Apache Beam per Java, consulta Installa l'SDK Apache Beam.
Puoi impostare gli hint di risorse a livello di programmazione sulle trasformazioni della pipeline utilizzando la
ResourceHints classe.
L'esempio seguente mostra come impostare gli hint di risorse a livello di programmazione sulle trasformazioni della pipeline.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withCpuCount(8)
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create()
.withMinRam("30GB")
.withCpuCount(16)))
Per impostare gli hint di risorse a livello di programmazione sull'intera pipeline, utilizza l'
ResourceHintsOptions interfaccia.
Python
Per installare l'SDK Apache Beam per Python, consulta Installa l'SDK Apache Beam.
Puoi impostare gli hint di risorse a livello di programmazione sulle trasformazioni della pipeline utilizzando la
PTransforms.with_resource_hints classe.
Per ulteriori informazioni, consulta la
ResourceHint classe.
L'esempio seguente mostra come impostare gli hint di risorse a livello di programmazione sulle trasformazioni della pipeline.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
cpu_count=8,
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB",
cpu_count=16)
Per impostare gli hint di risorse sull'intera pipeline, utilizza l'opzione della pipeline --resource_hints quando esegui la pipeline. Per un esempio, consulta
Hint di risorse della pipeline.
Vai
Gli hint di risorse non sono supportati in Go.
Supporto di più acceleratori
All'interno di una pipeline, trasformazioni diverse possono avere configurazioni di acceleratori diverse. Queste includono configurazioni che richiedono tipi di macchine diversi. Queste configurazioni di acceleratori a livello di trasformazione hanno la precedenza sulla configurazione a livello di pipeline, se ne è stata fornita una.
Adattabilità e fusione
In alcuni casi, le trasformazioni impostate con hint di risorse diversi possono essere eseguite sui worker nello stesso pool di worker, nell'ambito del processo di ottimizzazione della fusione. Quando le trasformazioni vengono unite, Dataflow le esegue in un ambiente che soddisfa l'unione degli hint di risorse impostati sulle trasformazioni. In alcuni casi, ciò include l'intera pipeline.
Quando gli hint di risorse non possono essere uniti, non si verifica la fusione. Ad esempio, gli hint di risorse per GPU diverse non sono unibili, quindi queste trasformazioni non vengono unite.
Puoi anche impedire la fusione aggiungendo un'operazione alla pipeline che costringe Dataflow a materializzare un PCollection intermedio. Questa operazione è particolarmente utile quando si tenta di isolare risorse costose come le GPU o le macchine con memoria elevata da passaggi lenti o costosi dal punto di vista computazionale che non richiedono queste risorse speciali. In questi casi, potrebbe essere utile forzare un'interruzione della fusione tra i passaggi lenti vincolati alla CPU e i passaggi che richiedono le GPU costose o le macchine con memoria elevata e pagare il costo della materializzazione associato all'interruzione della fusione. Per scoprire di più, consulta
Impedire la fusione.
Adattabilità in modalità flusso
Per i job in modalità flusso, puoi abilitare l'adattabilità impostando l'opzione della pipeline --experiments=enable_streaming_rightfitting.
L'adattabilità può migliorare il rendimento della pipeline se include fasi con requisiti di risorse diversi.
Esempio: pipeline con fase a uso intensivo di CPU e fase che richiede GPU
Una pipeline di esempio che potrebbe trarre vantaggio dall'adattabilità è quella che esegue una fase a uso intensivo di CPU, seguita da una fase che richiede GPU. Senza l'adattabilità, sarà necessario configurare un singolo pool di worker GPU per eseguire tutte le fasi della pipeline, inclusa la fase a uso intensivo di CPU. Ciò potrebbe comportare un sottoutilizzo delle risorse GPU quando il pool di worker esegue la fase a uso intensivo di CPU.
Se l'adattabilità è abilitata e un hint di risorse viene applicato al passaggio che richiede GPU, la pipeline creerà due pool separati, in modo che la fase a uso intensivo di CPU venga eseguita dal pool di worker CPU e la fase che richiede GPU venga eseguita dal pool di worker GPU.
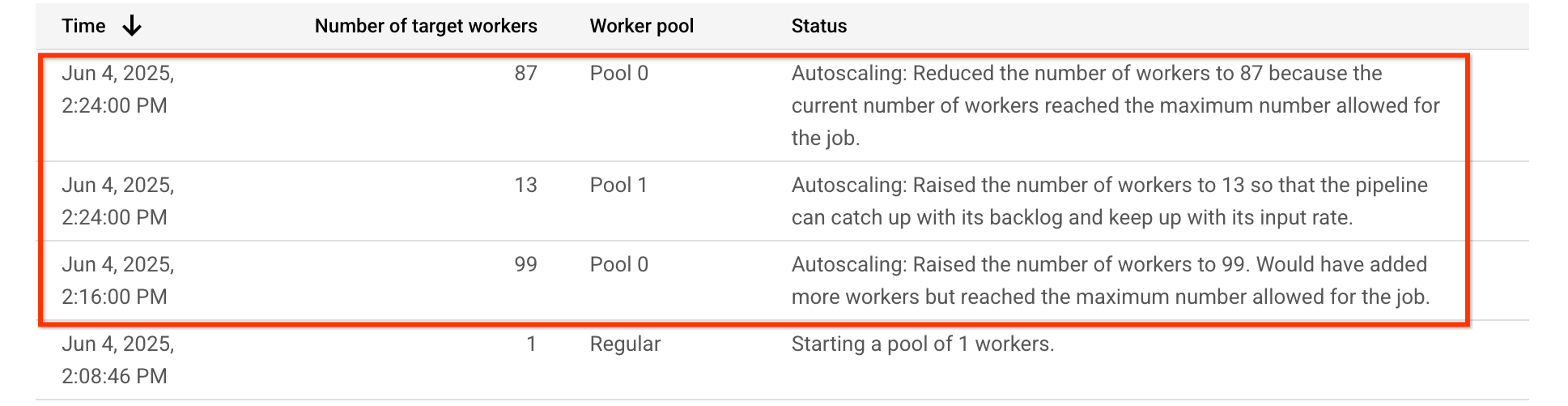
Per questa pipeline di esempio, la tabella di scalabilità automatica mostra che il pool di worker che esegue la fase a uso intensivo di CPU, Pool 0, viene inizialmente aumentato a 99 worker e successivamente ridotto a 87 worker. Il pool di worker che esegue la fase che richiede GPU, Pool 1, viene aumentato a 13 worker:
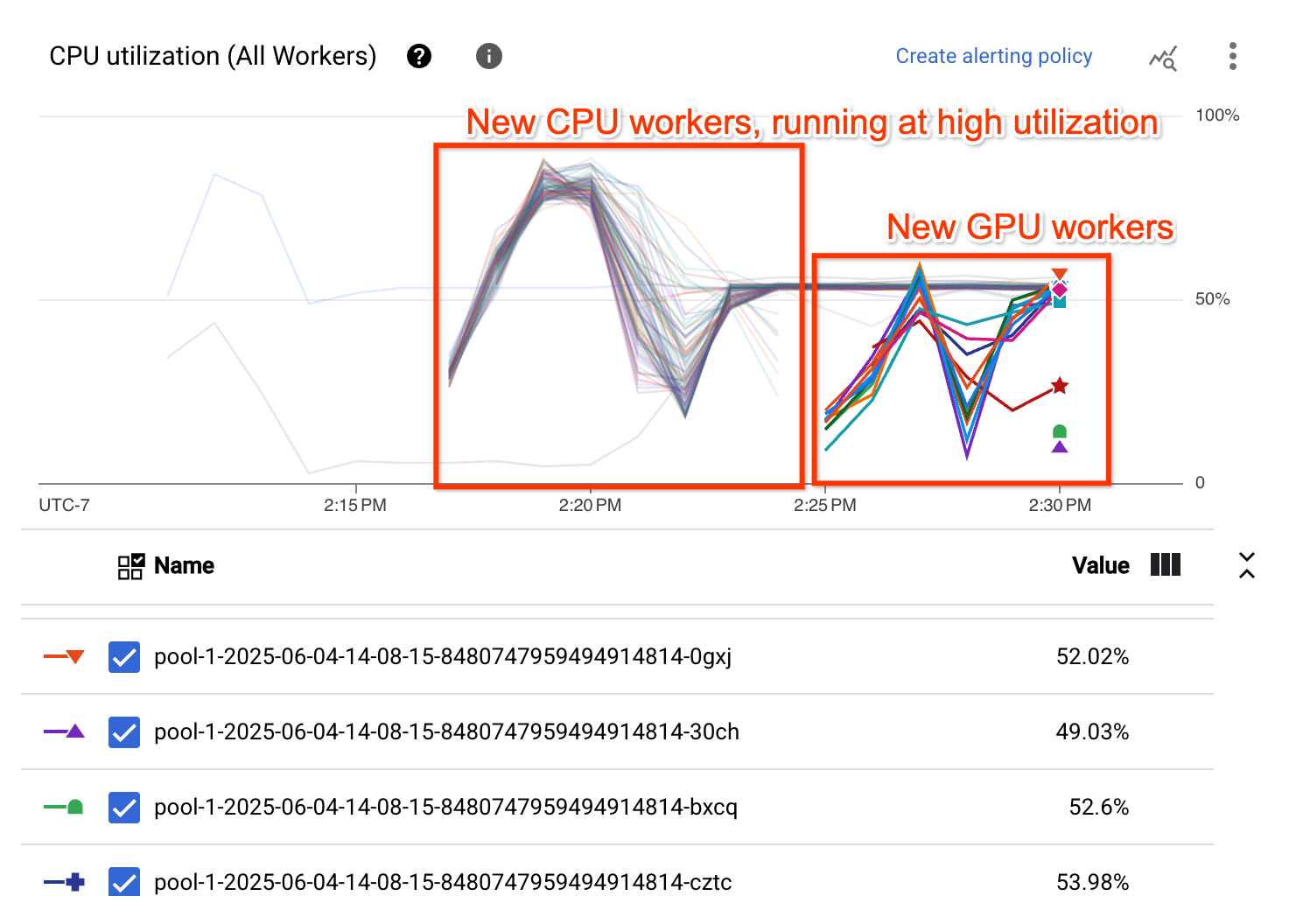
Il grafico Utilizzo CPU mostra che i worker in entrambi i pool di worker dimostrano un utilizzo complessivo elevato della CPU:
Risolvere i problemi relativi all'adattabilità
Questa sezione fornisce istruzioni per la risoluzione dei problemi comuni relativi all'adattabilità.
Configurazione non valida
Quando provi a utilizzare l'adattabilità, si verifica il seguente errore:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
Questo errore si verifica quando il tipo di GPU selezionato non è compatibile con il tipo di macchina selezionato. Per risolvere questo errore, seleziona un tipo di GPU e un tipo di macchina compatibili. Per informazioni dettagliate sulla compatibilità, consulta Piattaforme GPU.
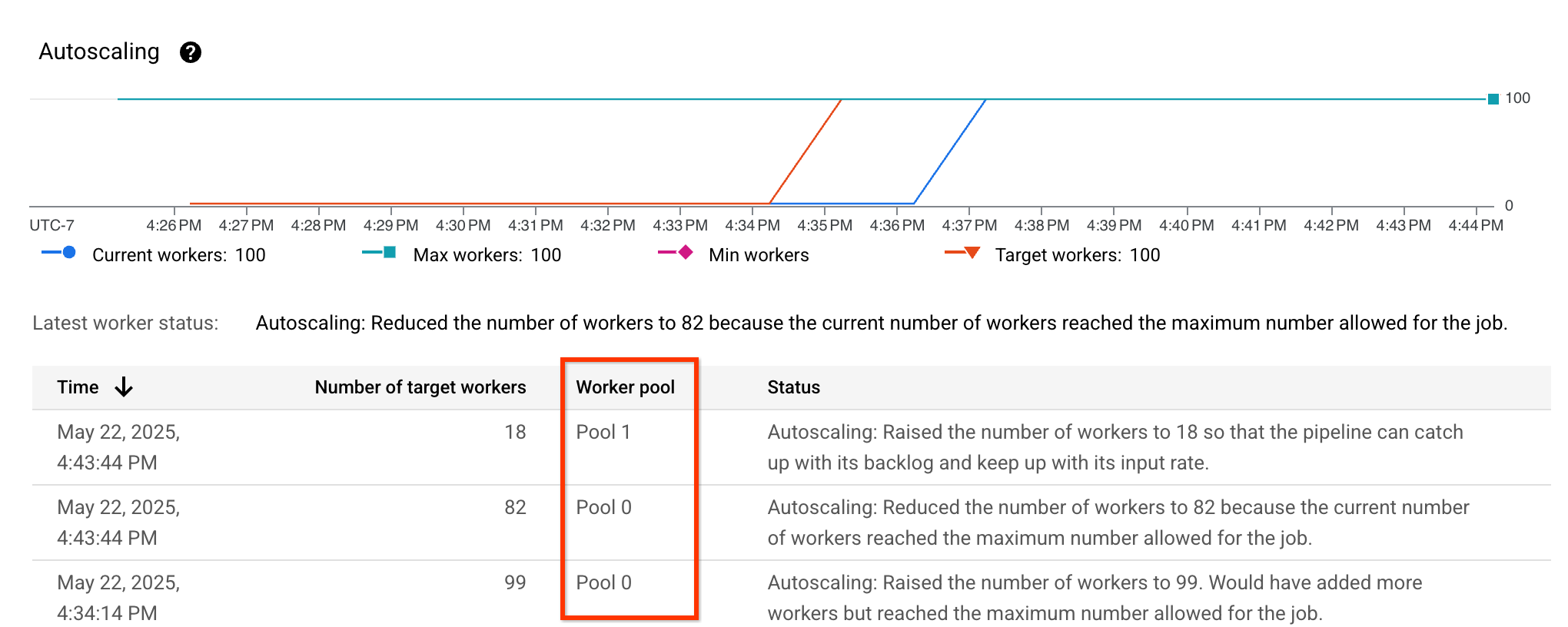
Verifica l'adattabilità
Puoi verificare che l'adattabilità sia abilitata visualizzando le metriche di scalabilità automatica e verificando che la colonna Worker pool sia visibile ed elenchi pool diversi:
Rendimento dell'adattabilità in modalità flusso
Le pipeline in modalità flusso con l'adattabilità abilitata potrebbero non sempre avere un rendimento migliore rispetto alle pipeline senza l'adattabilità abilitata. Ad esempio:
- La pipeline utilizza più worker
- La latenza del sistema è maggiore o la velocità effettiva è inferiore
- Le dimensioni dei pool di worker cambiano più spesso o non si stabilizzano
Se riscontri questo problema per la tua pipeline, puoi disabilitare l'adattabilità rimuovendo l'opzione della pipeline --experiments=enable_streaming_rightfitting. Inoltre, le pipeline in modalità flusso con l'adattabilità abilitata che utilizzano gli hint di risorse dell'acceleratore potrebbero utilizzare più acceleratori di quanto sia auspicabile. Se riscontri questo problema per la tua pipeline, puoi configurare un numero massimo di acceleratori utilizzati dalla pipeline impostando l'opzione della pipeline --experiments=max_num_accelerators=NUM.