
התכונה התאמה נכונה משתמשת ברמזים למשאבים של Apache Beam כדי להתאים אישית את משאבי העובדים לצינור עיבוד נתונים. האפשרות לטרגט כמה משאבים שונים לשלבים ספציפיים בצינור עיבוד הנתונים מספקת גמישות ויכולת נוספות לצינור עיבוד הנתונים, וגם פוטנציאל לחיסכון בעלויות. אפשר להקצות משאבים יקרים יותר לשלבים בצינור עיבוד הנתונים שדורשים אותם, ומשאבים זולים יותר לשלבים אחרים בצינור עיבוד הנתונים. אפשר להשתמש בהתאמה הנכונה כדי לציין דרישות משאבים לצינור עיבוד נתונים שלם או לשלבים ספציפיים בצינור עיבוד הנתונים.
תמיכה ומגבלות
- יש תמיכה ברמזים למשאבים ב-Apache Beam Java וב-Python SDK, בגרסאות 2.31.0 ואילך.
- התאמה נכונה נתמכת בצינורות להעלאה בכמות גדולה.
התאמה נכונה נתמכת בצינורות סטרימינג עם שינוי גודל אוטומטי אופקי מופעל.
- כדי להפעיל את האפשרות הזו, מגדירים את אפשרות הצינור
--experiments=enable_streaming_rightfitting.
- כדי להפעיל את האפשרות הזו, מגדירים את אפשרות הצינור
התאמה נכונה תומכת ב-Dataflow Prime.
התאמה נכונה לא תומכת ב-FlexRS.
כשמשתמשים בהתאמה לזרימה מימין לשמאל, לא משתמשים ב
worker_acceleratorservice option.כשמשתמשים ב-Dataflow Prime, אי אפשר להשתמש בבחירה אוטומטית של מכונות וירטואליות.
הפעלה של התאמה נכונה
כדי להפעיל התאמה נכונה, משתמשים באחת או יותר מרמזים זמינים למשאבים בצינור. כשמשתמשים ברמז למשאב בצינור, התאמה נכונה מופעלת באופן אוטומטי. מידע נוסף זמין בקטע שימוש בהצעות למשאבים במסמך הזה.
רמזים זמינים למשאבים
אלה רמזים למשאבים שזמינים:
| רמז למשאב | תיאור |
|---|---|
min_ram |
כמות ה-RAM המינימלית בגיגה-בייט להקצאה לעובדים. Dataflow משתמש בערך הזה כגבול תחתון כשמקצים זיכרון לעובדים חדשים (שינוי קנה מידה אופקי) או לעובדים קיימים (שינוי קנה מידה אנכי). לדוגמה: min_ram=NUMBERGB
|
cpu_count |
מספר המעבדים הווירטואליים להקצאה לכל עובד. כשמשתמשים ברמז המשאבים הזה, Dataflow בוחר סוגי מכונות עם מספר ה-vCPU שצוין ועומדות בדרישות הזיכרון. לדוגמה: cpu_count=NUMBER
|
accelerator |
הקצאה של יחידות GPU שסופקה על ידי המשתמש, שמאפשרת לכם לשלוט בשימוש ביחידות GPU ובעלות שלהן בצינור העיבוד ובשלבים שלו. מציינים את הסוג והמספר של יחידות ה-GPU לצירוף לעובדי Dataflow כפרמטרים של הדגל. לדוגמה: accelerator="type:GPU_TYPE;count:GPU_COUNT;machine_type:MACHINE_TYPE;CONFIGURATION_OPTIONS"
למידע נוסף על שימוש ביחידות GPU, אפשר לעיין במאמר בנושא יחידות GPU ב-Dataflow. |
בחירה אוטומטית של מכונות וירטואליות לסוגי מכונות worker
כשמשתמשים ברמזים למשאבים min_ram או cpu_count בשלבים של צינור עיבוד נתונים שלא דורשים מאיצים, הגמישות של המופע (בחירת מכונה וירטואלית אוטומטית) מופעלת באופן אוטומטי. באמצעות התכונה 'בחירה אוטומטית של מכונות וירטואליות', העובדים מקבלים הקצאת משאבים מתוך מבחר של סוגי מכונות שעומדים בדרישות ה-RAM וה-CPU שלכם.
התכונה 'בחירה אוטומטית של מכונות וירטואליות' מייעלת את בחירת המכונות הווירטואליות בעיקר לצורך אמינות ולא לצורך ביצועים. המשמעות היא שאולי תהיה ירידה בביצועים בזמן השימוש בתכונה 'בחירת מכונה וירטואלית אוטומטית' כדי לשפר את האמינות של חלק מהמשימות המותאמות במיוחד. מומלץ לבדוק את התכונה 'בחירה אוטומטית של מכונות וירטואליות' בקבוצת משנה של המשימות הקיימות, לפני שפורסים אותה בהדרגה לכלל המשימות.
אם אתם משתמשים בשמירת מקום ב-Compute Engine עם התכונה 'בחירה אוטומטית של מכונות וירטואליות', חשוב לשים לב לנקודות הבאות:
- אם יש לכם הזמנות עם שימוש אוטומטי, יכול להיות שהמערכת תשתמש בהן אם Compute Engine יקצה מכונות וירטואליות מסוג מכונה תואם.
- התכונה 'בחירה אוטומטית של מכונות וירטואליות' לא תומכת בשימוש במופעים מתוך הזמנה ספציפית.
- אין תמיכה בבחירה אוטומטית של מכונות וירטואליות ב-Dataflow Prime.
מידע נוסף זמין במאמר גמישות בהזמנות של מכונות וירטואליות.
הוספת רמזים לגבי משאבים בתוך רמזים אחרים
הצעות לשיפור הביצועים של משאבים מוחלות על ההיררכיה של צינור הטרנספורמציה באופן הבא:
-
min_ram: הערך של טרנספורמציה מוערך כערך הרמז הגדול ביותרmin_ramמבין הערכים שמוגדרים בטרנספורמציה עצמה ובכל ההורים שלה בהיררכיה של הטרנספורמציה.- לדוגמה: אם רמז להמרת נתונים פנימי מגדיר את
min_ramל-16GB, ורמז להמרת נתונים חיצוני בהיררכיה מגדיר אתmin_ramל-32GB, רמז של 32GB ישמש לכל השלבים בהמרה כולה. - לדוגמה: אם רמז לשינוי פנימי מגדיר את
min_ramל-16GB, ורמז לשינוי חיצוני בהיררכיה מגדיר אתmin_ramל-8GB, רמז של 8GB ישמש לכל השלבים בשינוי החיצוני שלא נכללים בשינוי הפנימי, ורמז של 16GB ישמש לכל השלבים בשינוי הפנימי.
- לדוגמה: אם רמז להמרת נתונים פנימי מגדיר את
-
accelerator: הערך הפנימי ביותר בהיררכיית הטרנספורמציה מקבל עדיפות.- דוגמה: אם רמז להמרת נתונים פנימית
acceleratorשונה מרמז להמרת נתונים חיצוניתacceleratorבהיררכיה, הרמז להמרת נתונים פנימיתacceleratorישמש להמרת הנתונים הפנימית.
- דוגמה: אם רמז להמרת נתונים פנימית
רמזים שמוגדרים לכל צינור העיבוד נחשבים כאילו הם מוגדרים בהמרת הנתונים החיצונית הנפרדת.
שימוש ברמזים למשאבים
אפשר להגדיר רמזים למשאבים בכל צינור הנתונים או בשלבים של צינור הנתונים.
הינטים של משאבים בפייפליין
אפשר להגדיר רמזים למשאבים בצינור כולו כשמריצים את צינור העיבוד משורת הפקודה.
הוראות להגדרת סביבת Python מופיעות במדריך ל-Python.
לדוגמה:
python my_pipeline.py \
--runner=DataflowRunner \
--resource_hints=min_ram=numberGB \
--resource_hints=cpu_count=number \
--resource_hints=accelerator="type:type;count:number;install-nvidia-driver" \
...
רמזים לגבי משאבים בשלב של צינור עיבוד נתונים
אפשר להגדיר רמזים למשאבים בשלבים של צינורות (טרנספורמציות) באופן פרוגרמטי.
Java
כדי להתקין את Apache Beam SDK ל-Java, אפשר לעיין במאמר בנושא התקנה של Apache Beam SDK.
אפשר להגדיר רמזים למשאבים באופן פרוגרמטי בהמרות של צינורות באמצעות הסיווג ResourceHints.
בדוגמה הבאה אפשר לראות איך מגדירים רמזים למשאבים באופן פרוגרמטי בהמרות של צינור עיבוד נתונים.
pcoll.apply(MyCompositeTransform.of(...)
.setResourceHints(
ResourceHints.create()
.withMinRam("15GB")
.withCpuCount(8)
.withAccelerator(
"type:nvidia-l4;count:1;install-nvidia-driver")))
pcoll.apply(ParDo.of(new BigMemFn())
.setResourceHints(
ResourceHints.create()
.withMinRam("30GB")
.withCpuCount(16)))
כדי להגדיר רמזים למשאבים באופן פרוגרמטי בכל צינור הנתונים, משתמשים בממשק ResourceHintsOptions.
Python
כדי להתקין את Apache Beam SDK ל-Python, אפשר לעיין במאמר בנושא התקנה של Apache Beam SDK.
אפשר להגדיר רמזים למשאבים באופן פרוגרמטי בהמרות של צינורות באמצעות הסיווג PTransforms.with_resource_hints.
מידע נוסף זמין במאמר בנושא ResourceHint class.
בדוגמה הבאה אפשר לראות איך מגדירים רמזים למשאבים באופן פרוגרמטי בהמרות של צינור עיבוד נתונים.
pcoll | MyPTransform().with_resource_hints(
min_ram="4GB",
cpu_count=8,
accelerator="type:nvidia-tesla-l4;count:1;install-nvidia-driver")
pcoll | beam.ParDo(BigMemFn()).with_resource_hints(
min_ram="30GB",
cpu_count=16)
כדי להגדיר רמזים למשאבים בכל צינור העיבוד, משתמשים באפשרות --resource_hints של צינור העיבוד כשמריצים את צינור העיבוד. דוגמה מופיעה במאמר בנושא רמזים למשאבי צינורות.
המשך
אין תמיכה ברמזים למשאבים ב-Go.
תמיכה במספר מאיצים
בצינור, לטרנספורמציות שונות יכולות להיות הגדרות שונות של האצת החישובים. ההגדרות האלה כוללות הגדרות שדורשות סוגים שונים של מכונות. ההגדרות האלה של האצת טרנספורמציה מקבלות קדימות על פני ההגדרה ברמת צינור הנתונים, אם היא סופקה.
התאמה ומיזוג מימין
במקרים מסוימים, טרנספורמציות שהוגדרו עם רמזים שונים למשאבים יכולות להתבצע על עובדים באותו מאגר עובדים, כחלק מהתהליך של אופטימיזציה של מיזוג. כשממזגים טרנספורמציות, Dataflow מריץ אותן בסביבה שעומדת בדרישות של איחוד רמזי המשאבים שהוגדרו בטרנספורמציות. במקרים מסוימים, זה כולל את כל הצינור.
אם אי אפשר למזג רמזים למשאבים, לא מתבצע מיזוג. לדוגמה, אי אפשר למזג רמזים לגבי משאבים של GPU שונים, ולכן לא ניתן לבצע מיזוג של טרנספורמציות כאלה.
אפשר גם למנוע מיזוג על ידי הוספת פעולה לצינור העיבוד שמאלצת את Dataflow ליצור PCollection ביניים. האפשרות הזו שימושית במיוחד כשמנסים לבודד משאבים יקרים כמו מעבדי GPU או מכונות עם זיכרון גבוה משלבים איטיים או משלבים שדורשים הרבה משאבי מחשוב ולא צריכים את המשאבים המיוחדים האלה. במקרים כאלה, יכול להיות שיהיה כדאי לכפות פיצול של המיזוג בין השלבים האיטיים שמוגבלים על ידי המעבד לבין השלבים שדורשים שימוש במעבדים גרפיים יקרים או במכונות עם זיכרון גבוה, ולשלם את העלות של יצירת חומרים שקשורה לפיצול המיזוג. מידע נוסף זמין במאמר בנושא מניעת מיזוג.
התאמה של סטרימינג
במשימות סטרימינג, אפשר להפעיל התאמה נכונה על ידי הגדרת אפשרות הצינור --experiments=enable_streaming_rightfitting.
התאמה נכונה יכולה לשפר את הביצועים של צינור העיבוד אם הוא כולל שלבים עם דרישות שונות של משאבים.
דוגמה: צינור עם שלב שדורש הרבה משאבי CPU ושלב שדורש GPU
דוגמה לצינור עיבוד נתונים שיכול להפיק תועלת מהתאמה נכונה היא צינור שמבצע שלב שדורש הרבה משאבי CPU, ואחריו שלב שדורש GPU. אם לא מתאימים את הגודל של מאגר העובדים, צריך להגדיר מאגר עובדים יחיד של GPU כדי להריץ את כל שלבי צינור עיבוד הנתונים, כולל השלב שדורש הרבה משאבי CPU. זה עלול להוביל לניצול חלקי של משאבי ה-GPU כשמאגר העובדים מבצע את השלב שדורש הרבה משאבי CPU.
אם האפשרות 'התאמה נכונה' מופעלת ורמז למשאב מוחל על השלב שדורש GPU, צינור הנתונים ייצור שני מאגרי עובדים נפרדים, כך שהשלב שדורש CPU יבוצע על ידי מאגר העובדים של ה-CPU, והשלב שדורש GPU יבוצע על ידי מאגר העובדים של ה-GPU.
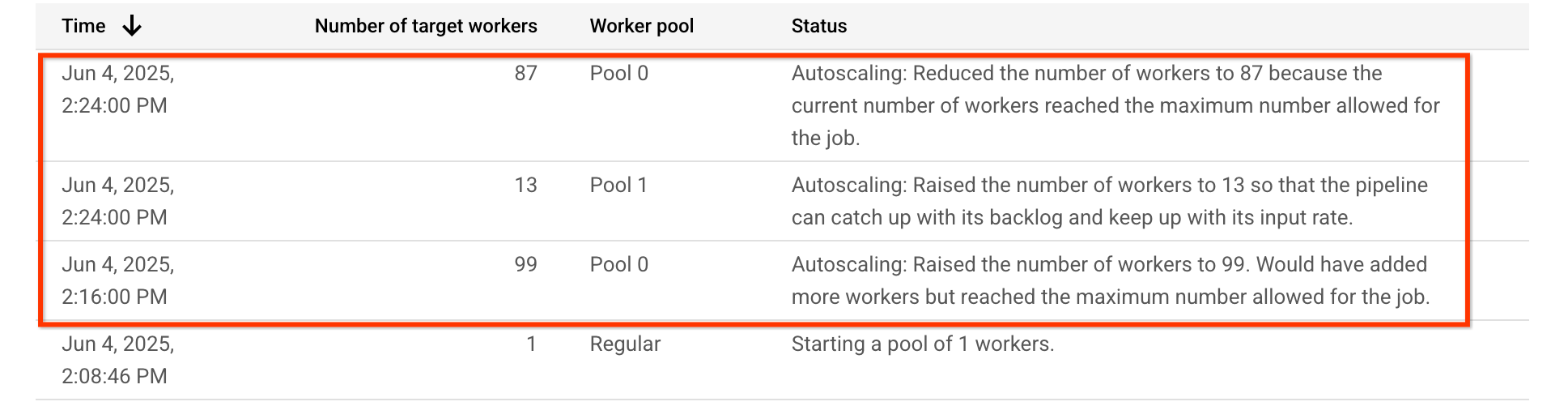
בפייפליין לדוגמה הזה, בטבלה של התאמה אוטומטית לעומס אפשר לראות שמאגר ה-workers שמבצע את השלב שדורש הרבה משאבי מעבד (CPU), Pool 0, גדל בהתחלה ל-99 workers, ואחר כך קטן ל-87 workers. מאגר העובדים שמבצע את השלב שדורש GPU, Pool 1, מוגדל ל-13 עובדים:
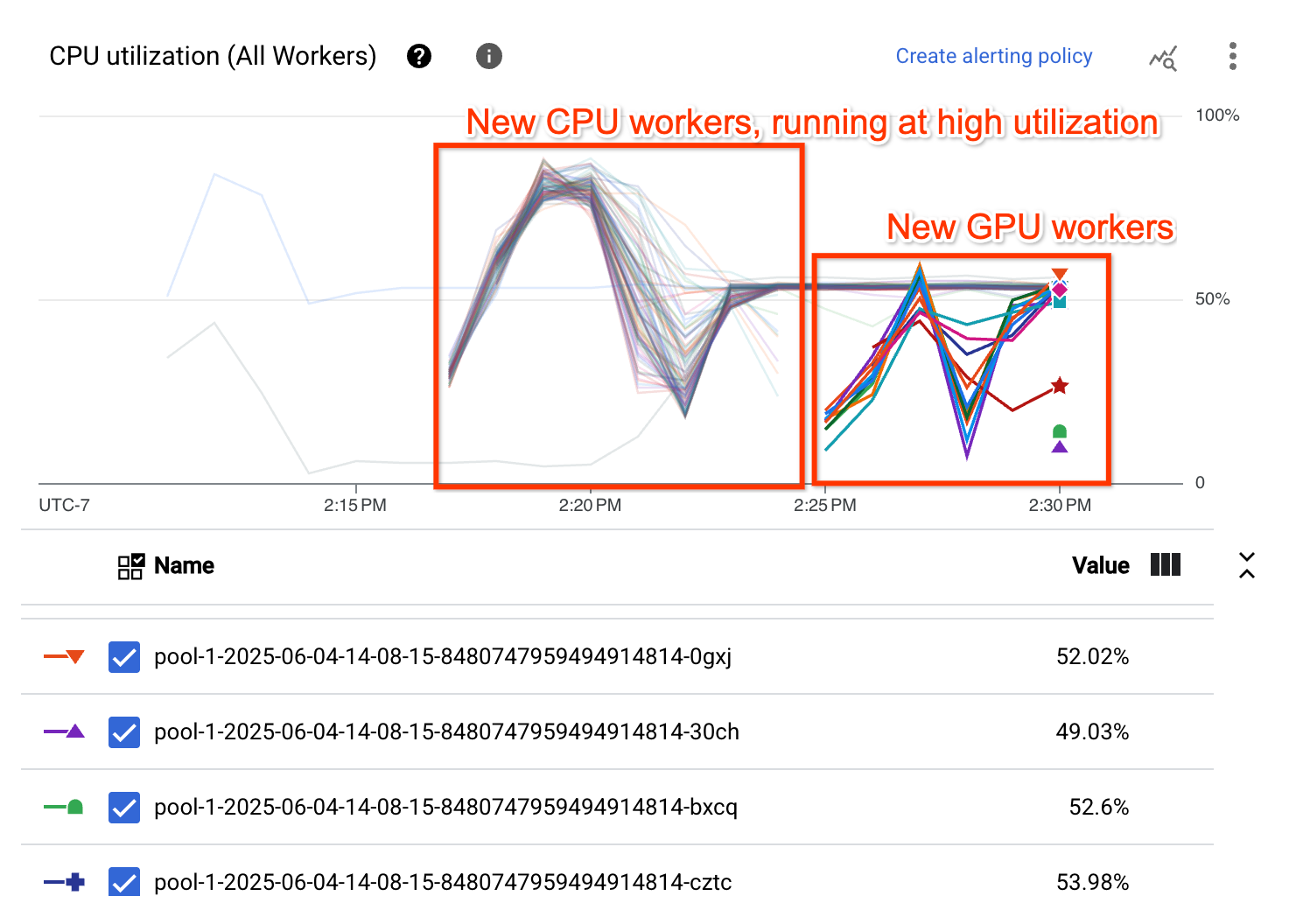
בתרשים של ניצול המעבד (CPU) אפשר לראות שרמת הניצול של המעבד גבוהה באופן כללי בשני מאגרי העובדים:
פתרון בעיות שקשורות להתאמה נכונה
בקטע הזה מפורטות הוראות לפתרון בעיות נפוצות שקשורות להתאמה נכונה.
הגדרות אישיות לא תקינות
כשמנסים להשתמש בהתאמה לימין, מופיעה השגיאה הבאה:
Workflow failed. Causes: One or more operations had an error: 'operation-OPERATION_ID':
[UNSUPPORTED_OPERATION] 'NUMBER vCpus with NUMBER MiB memory is
an invalid configuration for NUMBER count of 'GPU_TYPE' in family 'MACHINE_TYPE'.'.
השגיאה הזו מתרחשת כשסוג ה-GPU שנבחר לא תואם לסוג המכונה שנבחר. כדי לפתור את השגיאה הזו, צריך לבחור סוג GPU וסוג מכונה שתואמים זה לזה. פרטים על התאימות מופיעים במאמר בנושא פלטפורמות GPU.
איך לוודא שהאוזניות מתאימות
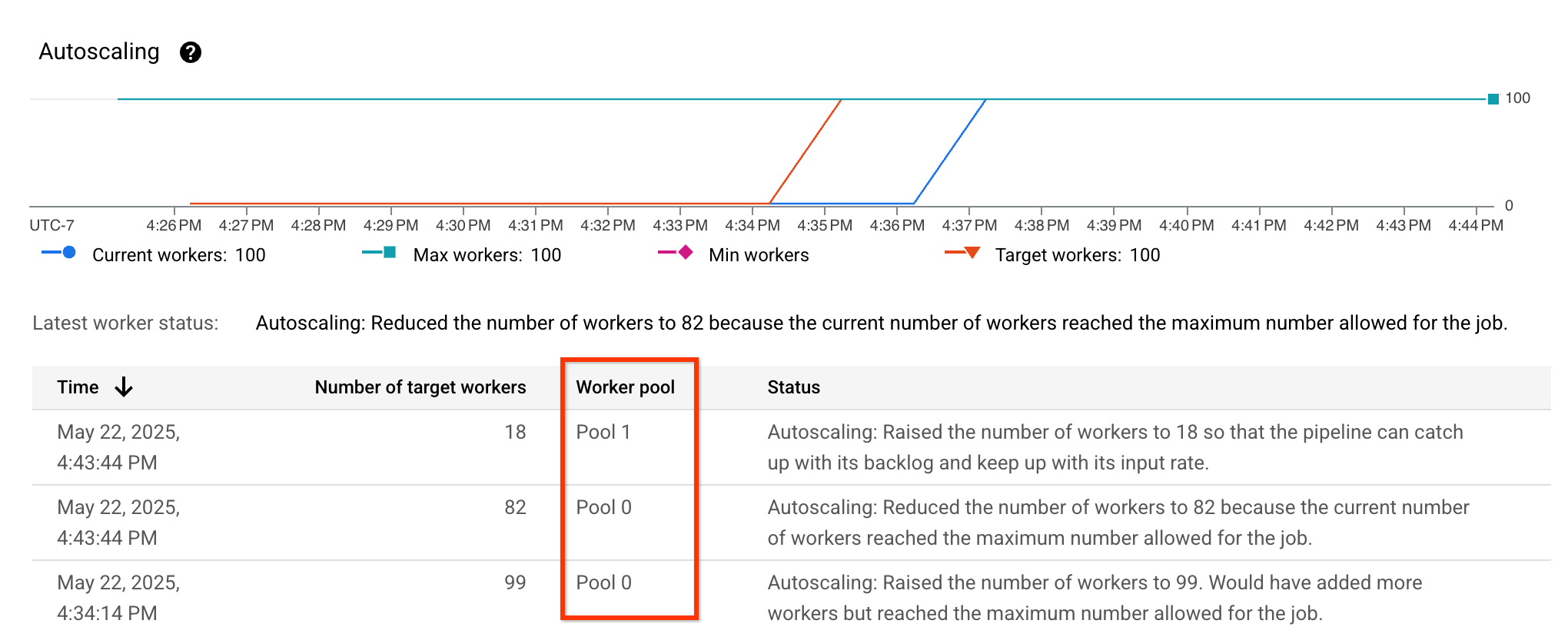
כדי לוודא שהתאמה נכונה מופעלת, אפשר לעיין במדדי שינוי הגודל האוטומטי ולוודא שהעמודה Worker pool מוצגת ומופיעים בה מאגרי משאבים שונים:
ביצועים של התאמת זכויות יוצרים לסטרימינג
יכול להיות שצינורות סטרימינג עם התאמה נכונה לא תמיד יניבו ביצועים טובים יותר מצינורות בלי התאמה נכונה. לדוגמה:
- הצינור משתמש ביותר עובדים
- זמן האחזור של המערכת ארוך יותר או שהתפוקה נמוכה יותר
- הגדלים של מאגרי העובדים משתנים בתדירות גבוהה יותר, או שלא מתייצבים
אם אתם רואים את זה בפייפליין שלכם, אתם יכולים להשבית את ההתאמה הנכונה על ידי הסרת --experiments=enable_streaming_rightfitting אפשרות הפייפליין. בנוסף, צינורות סטרימינג עם התאמה נכונה מופעלת באמצעות רמזים למשאבי האצה עשויים להשתמש ביותר מאיצי תוכנה מהרצוי. אם אתם רואים את זה בצינור עיבוד הנתונים שלכם, אתם יכולים להגדיר מספר מקסימלי של מאיצים שצינור עיבוד הנתונים משתמש בהם על ידי הגדרת אפשרות צינור עיבוד הנתונים --experiments=max_num_accelerators=NUM.