
Anda dapat menggunakan infrastruktur logging bawaan Apache Beam SDK untuk mencatat informasi saat menjalankan pipeline. Anda dapat menggunakan Google Cloud konsol untuk memantau informasi logging selama dan setelah pipeline berjalan.
Menambahkan pesan log ke pipeline
Java
Apache Beam SDK untuk Java merekomendasikan agar Anda mencatat pesan pekerja melalui library Simple Logging Facade for Java (SLF4J) open source. Apache Beam SDK untuk Java menerapkan infrastruktur logging yang diperlukan sehingga kode Java Anda hanya perlu mengimpor SLF4J API. Kemudian, kode tersebut membuat instance Logger untuk mengaktifkan logging pesan dalam kode pipeline Anda.
Untuk kode atau library yang sudah ada, Apache Beam SDK untuk Java menyiapkan infrastruktur logging tambahan. Pesan log yang dihasilkan oleh library logging berikut untuk Java akan dicatat:
Python
Apache Beam SDK untuk Python menyediakan paket library logging, yang memungkinkan pekerja pipeline menampilkan pesan log. Untuk menggunakan fungsi library, Anda harus mengimpor library:
import logging
Go
Apache Beam SDK untuk Go menyediakan paket library log, yang memungkinkan pekerja pipeline menampilkan pesan log. Untuk menggunakan fungsi library, Anda harus mengimpor library:
import "github.com/apache/beam/sdks/v2/go/pkg/beam/log"
Contoh kode pesan log pekerja
Java
Contoh berikut menggunakan SLF4J untuk logging Dataflow. Untuk mempelajari lebih lanjut cara mengonfigurasi SLF4J untuk logging Dataflow, lihat artikel Tips Java.
Contoh WordCount Apache Beam dapat diubah untuk menampilkan pesan log saat kata "love" ditemukan dalam baris teks yang diproses. Kode yang ditambahkan ditunjukkan dalam huruf tebal dalam contoh berikut (kode di sekitarnya disertakan untuk konteks).
package org.apache.beam.examples; // Import SLF4J packages. import org.slf4j.Logger; import org.slf4j.LoggerFactory; ... public class WordCount { ... static class ExtractWordsFn extends DoFn<String, String> { // Instantiate Logger. // Suggestion: As shown, specify the class name of the containing class // (WordCount). private static final Logger LOG = LoggerFactory.getLogger(WordCount.class); ... @ProcessElement public void processElement(ProcessContext c) { ... // Output each word encountered into the output PCollection. for (String word : words) { if (!word.isEmpty()) { c.output(word); } // Log INFO messages when the word "love" is found. if(word.toLowerCase().equals("love")) { LOG.info("Found " + word.toLowerCase()); } } } } ... // Remaining WordCount example code ...
Python
Contoh Apache Beam wordcount.py dapat diubah untuk menampilkan pesan log saat kata "love" ditemukan dalam baris teks yang diproses.
# import Python logging module. import logging class ExtractWordsFn(beam.DoFn): def process(self, element): words = re.findall(r'[A-Za-z\']+', element) for word in words: yield word if word.lower() == 'love': # Log using the root logger at info or higher levels logging.info('Found : %s', word.lower()) # Remaining WordCount example code ...
Go
func (f *extractFn) ProcessElement(ctx context.Context, line string, emit func(string)) { for _, word := range wordRE.FindAllString(line, -1) { // increment the counter for small words if length of words is // less than small_word_length if strings.ToLower(word) == "love" { log.Infof(ctx, "Found : %s", strings.ToLower(word)) } emit(word) } } // Remaining Wordcount example
Java
Jika pipeline WordCount yang diubah dijalankan secara lokal menggunakan DirectRunner
default dengan output yang dikirim ke file lokal (--output=./local-wordcounts), output konsol
akan menyertakan pesan log yang ditambahkan:
INFO: Executing pipeline using the DirectRunner. ... Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love Feb 11, 2015 1:13:22 PM org.apache.beam.examples.WordCount$ExtractWordsFn processElement INFO: Found love ... INFO: Pipeline execution complete.
Secara default, hanya baris log yang ditandai INFO dan yang lebih tinggi yang dikirim ke
Cloud Logging. Untuk mengubah perilaku ini, lihat
Menetapkan Level Log Pekerja Pipeline.
Python
Jika pipeline WordCount yang diubah dijalankan secara lokal menggunakan DirectRunner
default dengan output yang dikirim ke file lokal (--output=./local-wordcounts), output konsol
akan menyertakan pesan log yang ditambahkan:
INFO:root:Found : love INFO:root:Found : love INFO:root:Found : love
Secara default, hanya baris log yang ditandai INFO dan yang lebih tinggi yang dikirim ke
Cloud Logging. Untuk mengubah perilaku ini, lihat
Menetapkan Level Log Pekerja Pipeline.
Jangan menimpa konfigurasi logging dengan logging.config
fungsi, karena tindakan ini dapat menonaktifkan pengendali log yang telah dikonfigurasi sebelumnya yang
mengirimkan log pipeline ke Dataflow dan Cloud Logging.
Go
Jika pipeline WordCount yang diubah dijalankan secara lokal menggunakan DirectRunner
default dengan output yang dikirim ke file lokal (--output=./local-wordcounts), output konsol
akan menyertakan pesan log yang ditambahkan:
2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love 2022/05/26 11:36:44 Found : love
Secara default, hanya baris log yang ditandai INFO dan yang lebih tinggi yang dikirim ke
Cloud Logging.
Menambahkan konteks terstruktur dan dapat ditelusuri ke log menggunakan MDC
Anda dapat menggunakan Mapped Diagnostic Context (MDC) untuk menambahkan pasangan nilai kunci terstruktur ke log Dataflow. Hal ini memudahkan kueri dan analisis pesan di Cloud Logging.
Mapped Diagnostic Context (MDC) adalah fitur standar dalam framework logging Java seperti SLF4J dan Logback. Fitur ini memungkinkan Anda meningkatkan pernyataan log dengan informasi kontekstual yang dikelola per thread. Misalnya, Anda dapat menambahkan
ID transaksi, nama file, atau kunci khusus bisnis ke log Anda yang mirip dengan
berikut ini: "custom_data": { "transactionId": "xyz-123", "sourceFile":
"customers.csv" }.
Integrasi MDC Dataflow
Saat Anda mengaktifkan MDC untuk pipeline Dataflow, runner Dataflow akan otomatis mengambil konteks MDC pada saat pesan log dibuat dan meneruskannya ke Logging. Atribut kustom muncul dalam peta custom_data di jsonPayload entri log Logging. Hal ini menjadikannya kolom tingkat atas yang dapat difilter.
Berikut adalah contoh entri log dengan data kustom dari MDC:
{ "jsonPayload": { "custom_data": { "messageId": "232323232" }, "message": "LOG_MESSAGE", "pipelineName": "PIPELINE_NAME", [...] } }
Prasyarat
- Pipeline Dataflow menggunakan Apache Beam SDK untuk Java.
- Untuk Dataflow Runner v1, Anda harus menggunakan Apache Beam SDK versi 2.69.0 atau yang lebih baru.
- Untuk Dataflow Runner v2, fitur ini didukung secara default.
- Fasad logging seperti SLF4J yang dikonfigurasi dalam project.
Mengaktifkan dan menggunakan MDC
Untuk mengaktifkan MDC, tambahkan opsi pipeline berikut saat Anda meluncurkan tugas:
--logMdc=true
Contoh kode berikut menunjukkan cara menggunakan MDC untuk menambahkan messageId ke log tugas Dataflow yang membaca pesan dari Pub/Sub.
import org.apache.beam.sdk.Pipeline; import org.apache.beam.sdk.io.gcp.pubsub.PubsubMessage; import org.apache.beam.sdk.io.gcp.pubsub.PubsubIO; import org.apache.beam.sdk.options.Description; import org.apache.beam.sdk.options.PipelineOptionsFactory; import org.apache.beam.sdk.options.SdkHarnessOptions; import org.apache.beam.sdk.transforms.DoFn; import org.apache.beam.sdk.transforms.ParDo; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import org.slf4j.MDC; public class SimpleDataflowJobMDC { public interface SimpleDataflowJobOptions extends SdkHarnessOptions { @Description("The Pub/Sub subscription to read from.") String getInputSubscription(); void setInputSubscription(String value); } public static class MessageReaderFn extends DoFn<PubsubMessage, Void> { private transient Logger logger; @Setup public void setup() { logger = LoggerFactory.getLogger(MessageReaderFn.class); } @ProcessElement public void processElement(ProcessContext c) { PubsubMessage message = c.element(); String messageId = message.getMessageId(); try (MDC.MDCCloseable ignored = MDC.putCloseable("messageId", messageId)) { String payload = new String(message.getPayload()); logger.info("Received message with payload: " + payload); // This is the example task logger.info("Executing example task..."); } catch (Exception e) { logger.info("failure"); } } } public static void main(String[] args) { SimpleDataflowJobOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(SimpleDataflowJobOptions.class); // options.setRunner(DirectRunner.class); options.setLogMdc(true); Pipeline p = Pipeline.create(options); p.apply( "Read Messages from Pub/Sub", PubsubIO.readMessagesWithAttributes().fromSubscription(options.getInputSubscription())) .apply("Process Message", ParDo.of(new MessageReaderFn())); p.run(); } }
Contoh perintah mvn berikut menunjukkan cara menjalankan pipeline dengan argumen --logMdc=true:
mvn -Pdataflow-runner compile exec:java \ -Dexec.mainClass=com.sample.SimpleDataflowJobMDC \ -Dexec.args=" \ [...] \ --logMdc=true \ [...]
Mengontrol volume log
Anda juga dapat mengurangi volume log yang dihasilkan dengan mengubah level log pipeline log levels. Jika Anda tidak ingin terus menyerap sebagian atau semua log Dataflow, tambahkan Pengecualian Logging untuk mengecualikan log Dataflow. Kemudian, ekspor log ke tujuan lain seperti BigQuery, Cloud Storage, atau Pub/Sub. Untuk mengetahui informasi selengkapnya, lihat Mengontrol penyerapan log Dataflow.
Batas dan throttling Logging
Pesan log pekerja dibatasi hingga 15.000 pesan setiap 30 detik, per pekerja. Jika batas ini tercapai, satu pesan log pekerja akan ditambahkan yang menyatakan bahwa logging dibatasi:
Throttling logger worker. It used up its 30s quota for logs in only 12.345s
Tidak ada lagi pesan yang dicatat hingga interval 30 detik berakhir. Batas ini dibagikan oleh pesan log yang dihasilkan oleh Apache Beam SDK dan kode pengguna.
Penyimpanan dan retensi log
Log operasional disimpan di
_Default bucket log. Nama layanan Logging API adalah dataflow.googleapis.com. Untuk mengetahui informasi selengkapnya
tentang Google Cloud jenis resource dan layanan yang dimonitor yang digunakan di
Cloud Logging, lihat Resource dan layanan yang
dimonitor.
Untuk mengetahui detail tentang berapa lama entri log disimpan oleh Logging, lihat informasi retensi di Kuota dan batas: Periode retensi log.
Untuk mengetahui informasi tentang cara melihat log operasional, lihat Memantau dan melihat log pipeline.
Memantau dan melihat log pipeline
Saat menjalankan pipeline di layanan Dataflow, Anda dapat menggunakan antarmuka pemantauan Dataflow untuk melihat log yang dikeluarkan oleh pipeline.
Contoh log pekerja Dataflow
Pipeline WordCount yang diubah dapat dijalankan di cloud dengan opsi berikut:
Java
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --tempLocation=gs://<bucket-name>/temp --stagingLocation=gs://<bucket-name>/binaries
Python
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Go
--project=WordCountExample --output=gs://<bucket-name>/counts --runner=DataflowRunner --staging_location=gs://<bucket-name>/binaries
Melihat log
Karena pipeline cloud WordCount menggunakan eksekusi pemblokiran, pesan konsol akan ditampilkan selama eksekusi pipeline. Setelah tugas dimulai, link ke halaman Google Cloud konsol akan ditampilkan ke konsol, diikuti dengan ID tugas pipeline:
INFO: To access the Dataflow monitoring console, please navigate to https://console.developers.google.com/dataflow/job/2017-04-13_13_58_10-6217777367720337669 Submitted job: 2017-04-13_13_58_10-6217777367720337669
URL konsol mengarah ke antarmuka pemantauan Dataflow dengan halaman ringkasan untuk tugas yang dikirimkan. URL ini menampilkan grafik eksekusi dinamis di sebelah kiri, dengan informasi ringkasan di sebelah kanan. Klik keyboard_capslock di panel bawah untuk meluaskan panel log.
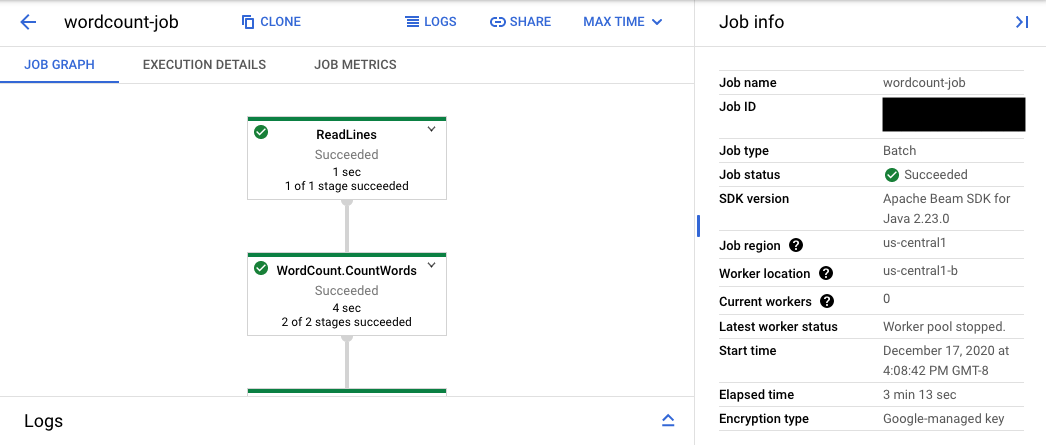
Panel log secara default menampilkan Log Tugas yang melaporkan status tugas secara keseluruhan. Anda dapat memfilter pesan yang muncul di panel log dengan mengklik Infoarrow_drop_down dan filter_listFilter log.
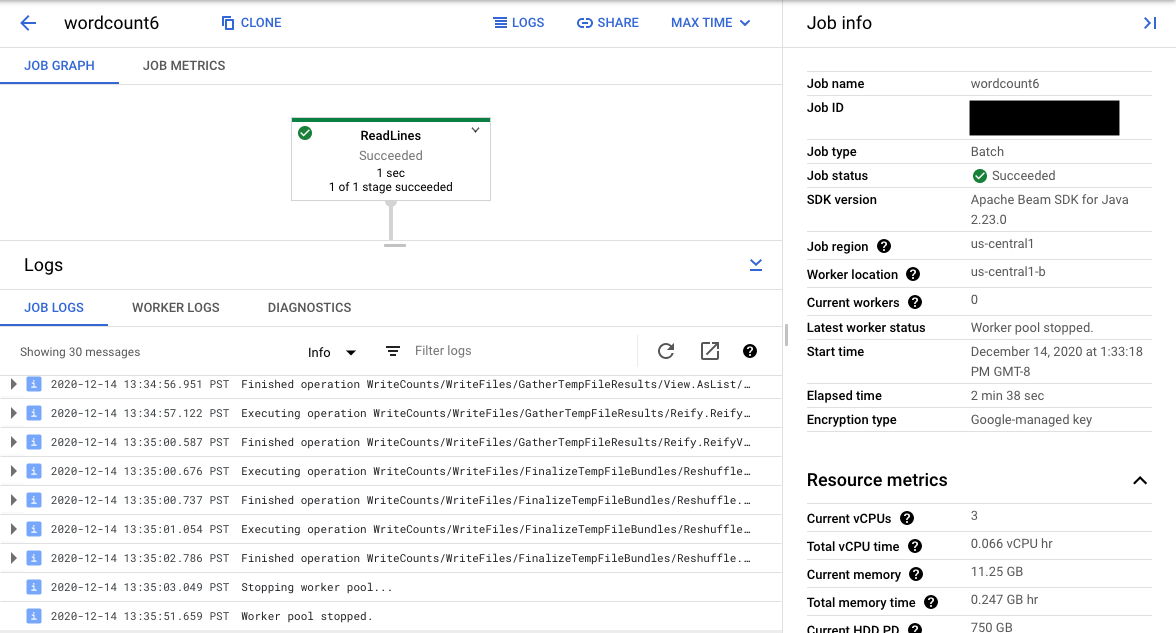
Memilih langkah pipeline dalam grafik akan mengubah tampilan menjadi Log Langkah yang dihasilkan oleh kode Anda dan kode yang dihasilkan yang berjalan di langkah pipeline.
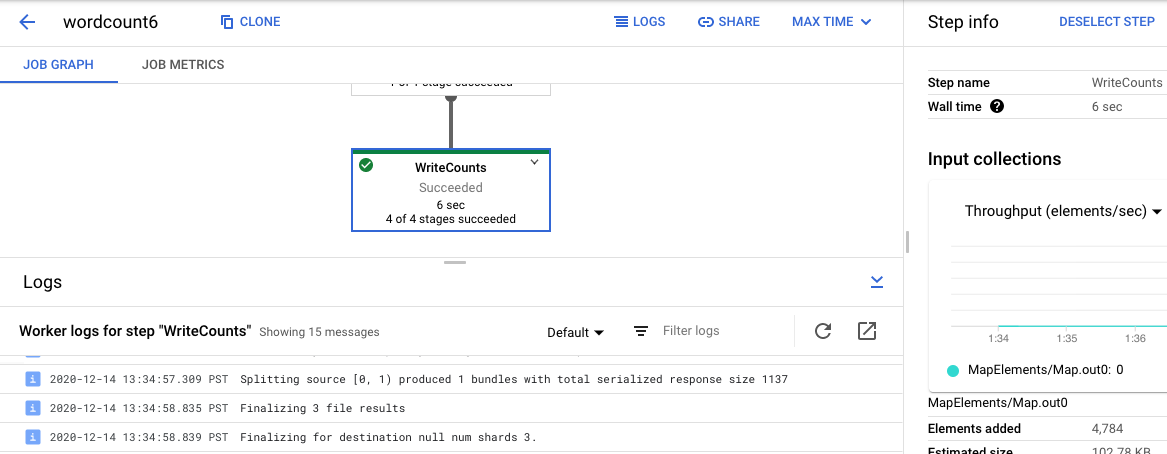
Untuk kembali ke Log Tugas, hapus langkah dengan mengklik di luar grafik atau menggunakan tombol Batalkan pilihan langkah di panel samping kanan.
Membuka Logs Explorer
Untuk membuka Logs Explorer dan memilih jenis log yang berbeda, di panel log, klik Lihat di Logs Explorer (tombol link eksternal).
Di Logs Explorer, untuk melihat panel dengan jenis log yang berbeda, klik tombol Kolom log.
Di halaman Logs Explorer, kueri mungkin memfilter log menurut langkah tugas atau menurut jenis log. Untuk menghapus filter, klik tombol Tampilkan kueri dan edit kueri.
Untuk melihat semua log yang tersedia untuk tugas, ikuti langkah-langkah berikut:
Di kolom Query, masukkan kueri berikut:
resource.type="dataflow_step" resource.labels.job_id="JOB_ID"Ganti JOB_ID dengan ID tugas Anda.
Klik Run query.
Jika Anda menggunakan kueri ini dan tidak melihat log untuk tugas Anda, klik Edit time.
Sesuaikan waktu mulai dan waktu berakhir, lalu klik Apply.
Jenis log
Logs Explorer juga menyertakan log infrastruktur untuk pipeline Anda. Gunakan log error dan peringatan untuk mendiagnosis masalah pipeline yang diamati. Error dan peringatan dalam log infrastruktur yang tidak berkorelasi dengan masalah pipeline tidak selalu menunjukkan masalah.
Berikut ringkasan berbagai jenis log yang dapat dilihat dari halaman Logs Explorer:
- Log job-message berisi pesan tingkat tugas yang dihasilkan oleh berbagai komponen Dataflow. Contohnya mencakup konfigurasi penskalaan otomatis, saat pekerja memulai atau menghentikan, progres pada langkah tugas, dan error tugas. Error tingkat pekerja yang berasal dari kode pengguna yang error dan yang ada dalam log pekerja juga disebarkan ke log job-message.
- Log pekerja dihasilkan oleh pekerja Dataflow. Pekerja melakukan sebagian besar pekerjaan pipeline (misalnya, menerapkan
ParDoke data). Log pekerja berisi pesan yang dicatat oleh kode dan Dataflow Anda. - Log worker-startup ada di sebagian besar tugas Dataflow dan dapat menangkap pesan yang terkait dengan proses startup. Proses startup mencakup mendownload jar tugas dari Cloud Storage, lalu memulai pekerja. Jika ada masalah saat memulai pekerja, log ini adalah tempat yang tepat untuk dilihat.
- Log harness berisi pesan dari harness runner Runner v2.
- Log shuffler berisi pesan dari pekerja yang menggabungkan hasil operasi pipeline paralel.
- Log sistem berisi pesan dari sistem operasi host VM pekerja. Dalam beberapa skenario, log ini mungkin menangkap error proses atau peristiwa kehabisan memori (OOM).
- Log docker dan kubelet berisi pesan yang terkait dengan teknologi publik ini, yang digunakan pada pekerja Dataflow.
- Log nvidia-mps berisi pesan tentang operasi NVIDIA Multi-Process Service (MPS).
Menetapkan level log pekerja pipeline
Java
Level logging SLF4J default yang ditetapkan pada pekerja oleh Apache Beam SDK untuk Java adalah
INFO. Semua pesan log INFO atau yang lebih tinggi (INFO,
WARN, ERROR) akan ditampilkan. Anda dapat menetapkan level log default yang berbeda
untuk mendukung level logging SLF4J yang lebih rendah (TRACE atau DEBUG) atau menetapkan level log yang berbeda
untuk paket class yang berbeda dalam kode Anda.
Opsi pipeline berikut disediakan untuk memungkinkan Anda menetapkan level log pekerja dari command line atau secara terprogram:
--defaultSdkHarnessLogLevel=<level>: gunakan opsi ini untuk menetapkan semua logger pada level default yang ditentukan. Misalnya, opsi command line berikut akan mengganti level log Dataflow defaultINFO, dan menetapkannya keDEBUG:
--defaultSdkHarnessLogLevel=DEBUG--sdkHarnessLogLevelOverrides={"<package or class>":"<level>"}: gunakan opsi ini untuk menetapkan level logging untuk paket atau class yang ditentukan. Misalnya, untuk mengganti level log pipeline default untuk paketorg.apache.beam.runners.dataflow, dan menetapkannya keTRACE:
--sdkHarnessLogLevelOverrides='{"org.apache.beam.runners.dataflow":"TRACE"}'
Untuk membuat beberapa penggantian, berikan peta JSON:
(--sdkHarnessLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...}).- Opsi pipeline
defaultSdkHarnessLogLeveldansdkHarnessLogLevelOverridestidak didukung dengan pipeline yang menggunakan Apache Beam SDK versi 2.50.0 dan yang lebih lama tanpa Runner v2. Dalam hal ini, gunakan--defaultWorkerLogLevel=<level>dan--workerLogLevelOverrides={"<package or class>":"<level>"}pipeline options. Untuk membuat beberapa penggantian, berikan peta JSON:
(--workerLogLevelOverrides={"<package/class>":"<level>","<package/class>":"<level>",...})
Contoh berikut menetapkan opsi logging pipeline secara terprogram dengan nilai default yang dapat diganti dari command line:
PipelineOptions options = ... SdkHarnessOptions loggingOptions = options.as(SdkHarnessOptions.class); // Overrides the default log level on the worker to emit logs at TRACE or higher. loggingOptions.setDefaultSdkHarnessLogLevel(LogLevel.TRACE); // Overrides the Foo class and "org.apache.beam.runners.dataflow" package to emit logs at WARN or higher. loggingOptions.getSdkHarnessLogLevelOverrides() .addOverrideForClass(Foo.class, LogLevel.WARN) .addOverrideForPackage(Package.getPackage("org.apache.beam.runners.dataflow"), LogLevel.WARN);
Python
Level logging default yang ditetapkan pada pekerja oleh Apache Beam SDK untuk Python adalah
INFO. Semua pesan log INFO atau yang lebih tinggi (INFO,
WARNING, ERROR, CRITICAL) akan ditampilkan.
Anda dapat menetapkan level log default yang berbeda untuk mendukung level logging yang lebih rendah (DEBUG)
atau menetapkan level log yang berbeda untuk modul yang berbeda dalam kode Anda.
Dua opsi pipeline disediakan untuk memungkinkan Anda menetapkan level log pekerja dari command line atau secara terprogram:
--default_sdk_harness_log_level=<level>: gunakan opsi ini untuk menetapkan semua logger pada level default yang ditentukan. Misalnya, opsi command line berikut mengganti level log Dataflow default, dan menetapkannya ke:--default_sdk_harness_log_level=DEBUGINFODEBUG--sdk_harness_log_level_overrides={\"<module>\":\"<level>\"}: gunakan opsi ini untuk menetapkan level logging untuk modul yang ditentukan. Misalnya, untuk mengganti level log pipeline default untuk modulapache_beam.runners.dataflow, dan menetapkannya keDEBUG:
--sdk_harness_log_level_overrides={\"apache_beam.runners.dataflow\":\"DEBUG\"}
Untuk membuat beberapa penggantian, berikan peta JSON:
(--sdk_harness_log_level_overrides={\"<module>\":\"<level>\",\"<module>\":\"<level>\",...}).
from apache_beam.options.pipeline_options import PipelineOptions, WorkerOptions pipeline_args = [ '--project=PROJECT_NAME', '--job_name=JOB_NAME', '--staging_location=gs://STORAGE_BUCKET/staging/', '--temp_location=gs://STORAGE_BUCKET/tmp/', '--region=DATAFLOW_REGION', '--runner=DataflowRunner' ] pipeline_options = PipelineOptions(pipeline_args) worker_options = pipeline_options.view_as(WorkerOptions) worker_options.default_sdk_harness_log_level = 'WARNING' # Note: In Apache Beam SDK 2.42.0 and earlier versions, use ['{"apache_beam.runners.dataflow":"WARNING"}'] worker_options.sdk_harness_log_level_overrides = {"apache_beam.runners.dataflow":"WARNING"} # Pass in pipeline options during pipeline creation. with beam.Pipeline(options=pipeline_options) as pipeline:
Ganti kode berikut:
PROJECT_NAME: nama projectJOB_NAME: nama tugasSTORAGE_BUCKET: nama Cloud StorageDATAFLOW_REGION: region tempat Anda ingin men-deploy tugas DataflowFlag
--regionmenggantikan region default yang ditetapkan di server metadata, klien lokal, atau variabel lingkungan.
Go
Fitur ini tidak tersedia di Apache Beam SDK untuk Go.
Melihat log tugas BigQuery yang diluncurkan
Saat menggunakan BigQuery di pipeline Dataflow, tugas BigQuery akan diluncurkan untuk melakukan berbagai tindakan atas nama Anda. Tindakan ini mungkin mencakup memuat data, mengekspor data, dan tugas serupa lainnya. Untuk tujuan pemecahan masalah dan pemantauan, antarmuka pemantauan Dataflow memiliki informasi tambahan tentang tugas BigQuery ini yang tersedia di panel Log.
Informasi tugas BigQuery yang ditampilkan di panel Log disimpan dan dimuat dari tabel sistem BigQuery. Biaya penagihan akan dikenakan saat tabel BigQuery yang mendasarinya dikueri.
Melihat detail tugas BigQuery
Untuk melihat informasi tugas BigQuery, pipeline Anda harus menggunakan Apache Beam 2.24.0 atau yang lebih baru.
Untuk mencantumkan tugas BigQuery, buka tab Tugas BigQuery dan pilih lokasi tugas BigQuery. Selanjutnya, klik Muat Tugas BigQuery dan konfirmasi dialog. Setelah kueri selesai, daftar tugas akan ditampilkan.
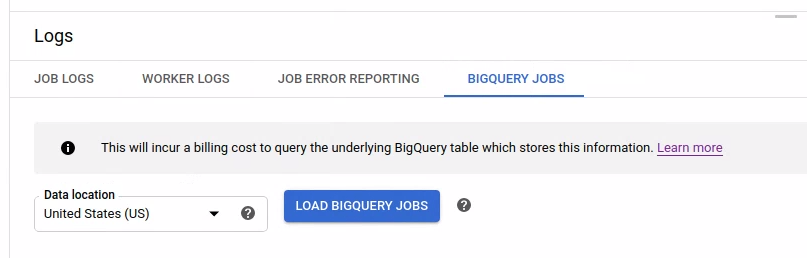
Informasi dasar tentang setiap tugas disediakan, termasuk ID tugas, jenis, durasi, dan detail lainnya.
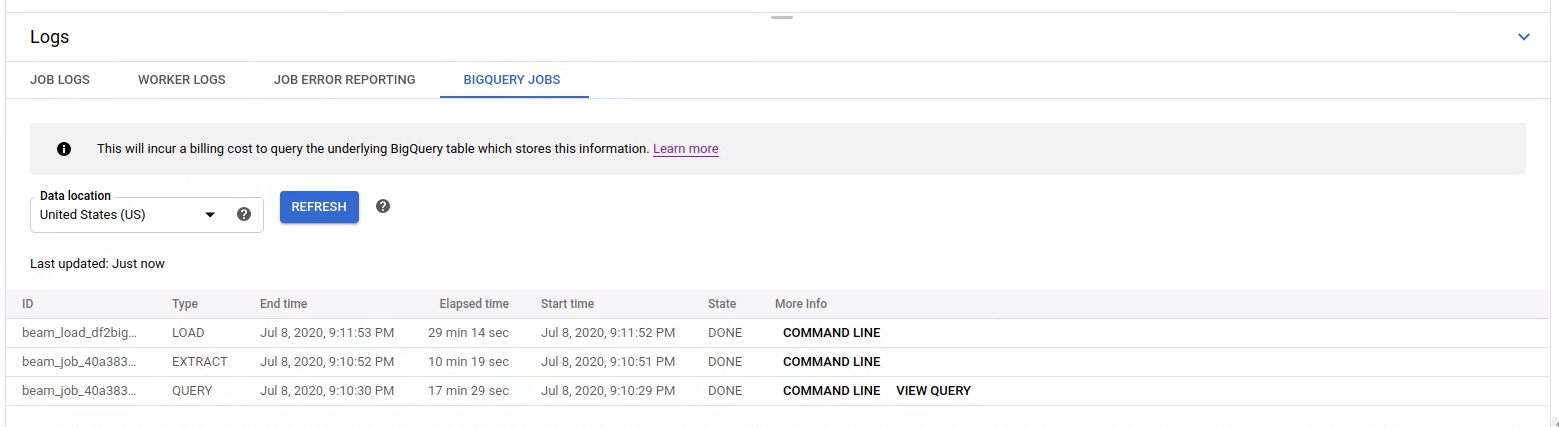
Untuk informasi yang lebih mendetail tentang tugas tertentu, klik Command line di kolom More Info.
Di jendela modal untuk command line, salin perintah bq jobs describe dan jalankan secara lokal atau di Cloud Shell.
gcloud alpha bq jobs describe BIGQUERY_JOB_ID
Perintah bq jobs describe menampilkan
JobStatistics,
yang memberikan detail lebih lanjut yang berguna saat mendiagnosis tugas BigQuery yang lambat atau macet.
Atau, saat Anda menggunakan BigQueryIO dengan kueri SQL, tugas kueri akan dikeluarkan. Untuk melihat kueri SQL yang digunakan oleh tugas, klik Lihat kueri di kolom More Info.
Melihat diagnostik
Tab Diagnostics di panel Logs mengumpulkan dan menampilkan entri log tertentu yang dihasilkan di pipeline Anda. Entri ini mencakup pesan yang menunjukkan kemungkinan masalah dengan pipeline dan pesan error dengan pelacakan tumpukan. Entri log yang dikumpulkan akan dide-duplikasi dan digabungkan ke dalam grup error.
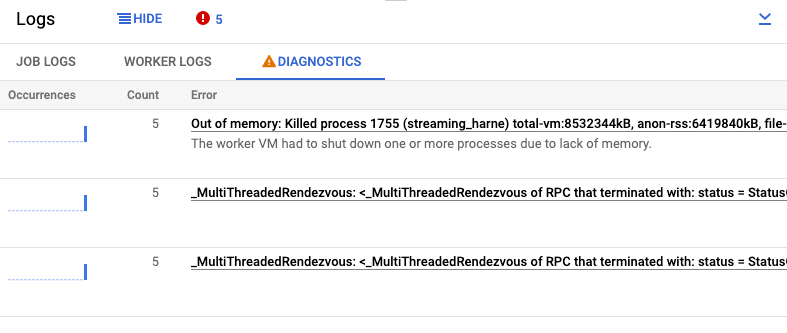
Laporan error mencakup informasi berikut:
- Daftar error dengan pesan error
- Jumlah kemunculan setiap error
- Histogram yang menunjukkan waktu terjadinya setiap error
- Waktu terjadinya error yang paling baru
- Waktu pertama kali error terjadi
- Status error
Untuk melihat laporan error untuk error tertentu, klik deskripsi di kolom Errors. Halaman Error reporting akan ditampilkan. Jika error adalah Error Layanan, link Troubleshooting guide akan ditampilkan.
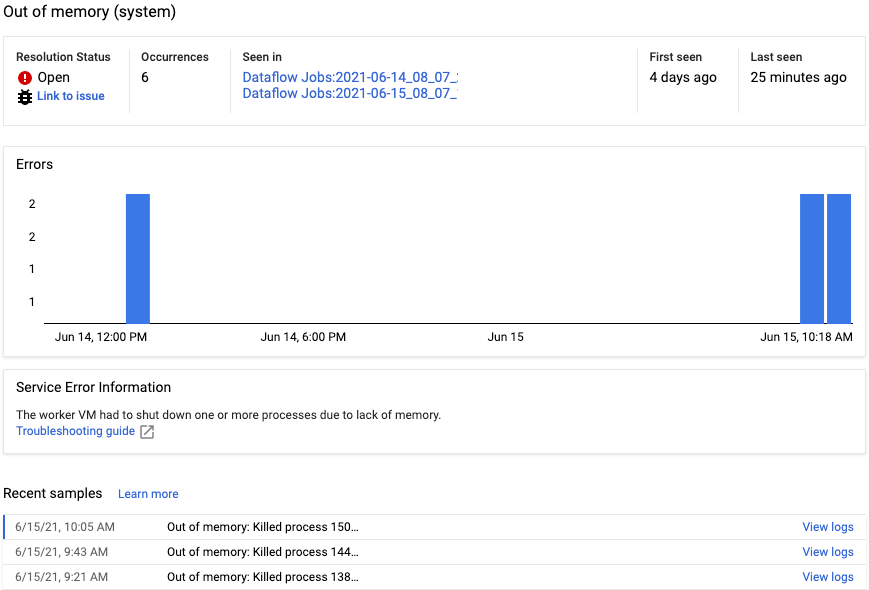
Untuk mengetahui informasi selengkapnya tentang halaman ini, lihat Melihat dan memfilter error.
Membisukan error
Untuk membisukan pesan error, ikuti langkah-langkah berikut:
- Buka tab Diagnostics.
- Klik error yang ingin Anda bisukan.
- Buka menu status resolusi. Status memiliki label berikut: Open, Acknowledged, Resolved, atau Muted.
- Pilih Muted.
Menggunakan penyedia logging SLF4J yang berbeda
Secara default, Apache Beam SDK untuk Java menggunakan java.util.logging sebagai penyedia logging SLF4J. Saat pipeline dimulai, Dataflow akan otomatis menambahkan JAR yang diperlukan ke classpath Java untuk mengonfigurasi lingkungan logging ini.
Untuk menggunakan penyedia logging SLF4J yang berbeda, seperti
Reload4J atau Logback,
Anda harus mencegah JAR default ditambahkan ke classpath, karena
SLF4J hanya mendukung satu penyedia logging saat runtime. Tambahkan eksperimen berikut ke opsi pipeline Anda: --experiments=use_custom_logging_libraries. Opsi ini hanya tersedia untuk
pipeline yang menggunakan Runner V2 sejak Apache Beam
SDK 2.63.0.
Saat Anda mengaktifkan eksperimen ini, Anda dapat menggabungkan penyedia logging SLF4J pilihan Anda dengan JAR pipeline Anda.