
כלי בניית המשימות הוא ממשק משתמש ויזואלי לבנייה ולהרצה של צינורות Dataflow במסוף, בלי לכתוב קוד. Google Cloud
בתמונה הבאה מוצג פרט מממשק המשתמש של כלי יצירת המשרות. בתמונה הזו, המשתמש יוצר צינור להעברת נתונים מקריאה מ-Pub/Sub אל BigQuery:
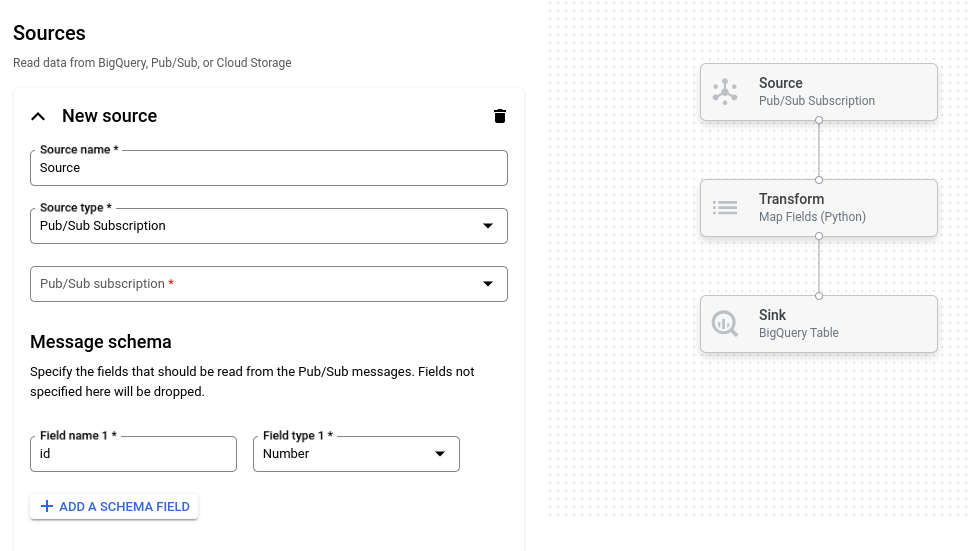
סקירה כללית
הכלי ליצירת משימות תומך בקריאה ובכתיבה של סוגי הנתונים הבאים:
- הודעות Pub/Sub
- נתונים בטבלה ב-BigQuery
- קובצי CSV, קובצי JSON וקובצי טקסט ב-Cloud Storage
- נתוני טבלה של PostgreSQL, MySQL, Oracle ו-SQL Server
- נתונים מטבלה של Apache Iceberg
היא תומכת בטרנספורמציות של צינורות, כולל filter, map, SQL, group-by, join ו-explode (השטחה של מערך).
בעזרת הכלי ליצירת משרות תוכלו:
- סטרימינג מ-Pub/Sub ל-BigQuery עם טרנספורמציות וצבירה בחלון
- כתיבת נתונים מ-Cloud Storage ל-BigQuery
- שימוש בטיפול בשגיאות כדי לסנן נתונים שגויים (תור הודעות שלא ניתן למסור)
- שינוי או צבירה של נתונים באמצעות SQL עם טרנספורמציית SQL
- הוספה, שינוי או הסרה של שדות מנתונים באמצעות טרנספורמציות של מיפוי
- תזמון של משימות חוזרות של עיבוד באצווה
הכלי ליצירת משימות יכול גם לשמור צינורות עיבוד נתונים כקובצי Apache Beam YAML ולטעון הגדרות של צינורות עיבוד נתונים מקובצי Beam YAML. באמצעות התכונה הזו, אתם יכולים לעצב את צינור העיבוד בבונה המשימות ואז לשמור את קובץ ה-YAML ב-Cloud Storage או במאגר של בקרת מקור לשימוש חוזר. אפשר להשתמש בהגדרות של משימות ב-YAML גם כדי להפעיל משימות באמצעות ה-CLI של gcloud.
כדאי להשתמש בכלי ליצירת משרות בתרחישים הבאים:
- אתם רוצים לבנות צינור במהירות בלי לכתוב קוד.
- רוצים לשמור צינור בקובץ YAML לשימוש חוזר.
- אפשר להגדיר את צינור עיבוד הנתונים באמצעות המקורות, היעדים והטרנספורמציות הנתמכים.
- אין תבנית ש-Google מספקת שמתאימה לתרחיש לדוגמה שלכם.
הפעלת משימה לדוגמה
הדוגמה של ספירת מילים היא צינור (pipeline) של עיבוד באצווה שקורא טקסט מ-Cloud Storage, מבצע טוקניזציה של שורות הטקסט למילים נפרדות ומבצע ספירת תדירות של כל אחת מהמילים.
אם קטגוריית Cloud Storage נמצאת מחוץ למתחם השירות, צריך ליצור כלל תעבורת נתונים יוצאת (egress) שמאפשר גישה לקטגוריה.
כדי להפעיל את צינור הנתונים של ספירת המילים:
נכנסים לדף Jobs במסוף Google Cloud .
לוחצים על Create job from template.
בחלונית הצדדית, לוחצים על Job builder (כלי ליצירת משרות).
לוחצים על טעינת תוכניות.
לוחצים על ספירת מילים. בונה המשימות מאוכלס בייצוג גרפי של הצינור.
לכל שלב בצינור העיבוד, בונה המשימות מציג כרטיס עם פרמטרי ההגדרה של השלב הזה. לדוגמה, בשלב הראשון קוראים קובצי טקסט מ-Cloud Storage. המיקום של נתוני המקור מאוכלס מראש בתיבה מיקום הטקסט.
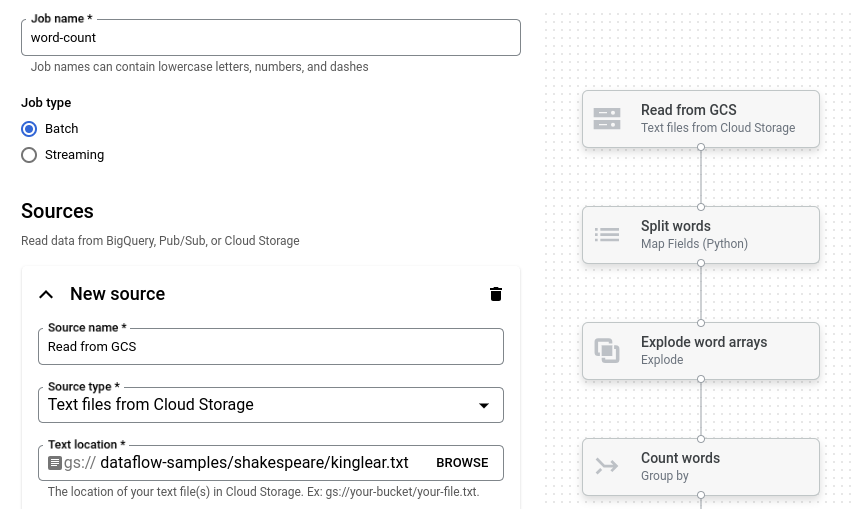
מחפשים את הכרטיס עם הכותרת New sink (כיור חדש). יכול להיות שתצטרכו לגלול.
בתיבה Text location (מיקום הטקסט), מזינים את קידומת הנתיב של מיקום Cloud Storage לקובצי הטקסט של הפלט.
לוחצים על הפעלת העבודה. כלי ליצירת משימות יוצר משימת Dataflow ואז עובר אל תרשים המשימה. כשהמשימה מתחילה, גרף המשימה מציג ייצוג גרפי של צינור עיבוד הנתונים. הייצוג הגרפי הזה דומה לזה שמוצג בכלי ליצירת משרות. במהלך ההרצה של כל שלב בצינור, הסטטוס מתעדכן בתרשים המשימות.
בחלונית פרטי המשרה מוצג הסטטוס הכולל של המשרה. אם העבודה מסתיימת בהצלחה, השדה Job status מתעדכן ל-Succeeded.
המאמרים הבאים
- שימוש בממשק למעקב אחרי משימות ב-Dataflow.
- יוצרים משימה בהתאמה אישית בכלי ליצירת משימות.
- שמירה וטעינה של הגדרות משימות ב-YAML בכלי ליצירת משימות.
- מידע נוסף על Beam YAML