
אפשר להשתמש ב-Apache Beam interactive runner עם מחברות JupyterLab כדי לבצע את המשימות הבאות:
- פיתוח צינורות עיבוד נתונים באופן איטרטיבי.
- בודקים את גרף הפייפליין.
- ניתוח של
PCollectionsבודד בתהליך עבודה של לולאת קריאה-הערכה-הדפסה (REPL).
מחברות Apache Beam זמינות דרך Gemini Enterprise Agent Platform Workbench, שירות שמארח מכונות וירטואליות של מחברות עם frameworks של מדעי נתונים ולמידת מכונה שהותקנו מראש. Dataflow תומך רק במופעי Workbench שמשתמשים בקונטיינר Apache Beam.
המדריך הזה מתמקד בתכונות החדשות של מחברות Apache Beam, אבל לא מראה איך ליצור מחברת. מידע נוסף על Apache Beam זמין במדריך לתכנות ב-Apache Beam.
תמיכה ומגבלות
- מחברות Apache Beam תומכות רק ב-Python.
- פלחים של צינורות Apache Beam שפועלים במחברות האלה מופעלים בסביבת בדיקה, ולא מול רכיב הפעלה של Apache Beam בסביבת ייצור. כדי להפעיל את ה-notebooks בשירות Dataflow, צריך לייצא את צינורות עיבוד הנתונים שנוצרו ב-notebook של Apache Beam. פרטים נוספים זמינים במאמר בנושא הפעלת משימות Dataflow מצינור שנוצר ב-notebook.
לפני שמתחילים
- נכנסים לחשבון Google Cloud . אם אתם משתמשים חדשים ב- Google Cloud, צרו חשבון כדי שתוכלו להעריך את הביצועים של המוצרים שלנו בתרחישים מהעולם האמיתי. לקוחות חדשים מקבלים בחינם גם קרדיט בשווי 300$ להרצה, לבדיקה ולפריסה של עומסי העבודה.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator role
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
Enable the Compute Engine and Notebooks APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.
לפני שיוצרים את מחברת Apache Beam, צריך להפעיל ממשקי API נוספים לצינורות שמשתמשים בשירותים אחרים, כמו Pub/Sub.
אם לא מציינים חשבון שירות, מחברת ה-Notebook מופעלת על ידי חשבון השירות שמוגדר כברירת מחדל ב-Compute Engine עם תפקיד עריכה בפרויקט IAM. אם הפרויקט מגביל באופן מפורש את התפקידים של חשבון השירות, צריך לוודא שעדיין יש לו מספיק הרשאות להרצת מחברות. לדוגמה, קריאה מנושא ב-Pub/Sub יוצרת מינוי באופן מרומז, וחשבון השירות צריך תפקיד עריכה ב-Pub/Sub ב-IAM. לעומת זאת, כדי לקרוא ממינוי ל-Pub/Sub נדרש רק תפקיד של מינוי ל-Pub/Sub ב-IAM.
כדי להימנע מחיובים נוספים אחרי שסיימתם את המדריך, תוכלו למחוק את המשאבים שיצרתם. פרטים נוספים זמינים במאמר בנושא ניקוי.
הפעלת מכונת notebook של Apache Beam
במסוף Google Cloud , עוברים לדף Workbench של Dataflow.
מוודאים שאתם בכרטיסייה מופעים.
בסרגל הכלים, לוחצים על יצירה.
בקטע Environment (סביבה), הערך של Container (קונטיינר) צריך להיות Apache Beam. יש תמיכה רק ב-JupyterLab 3.x עבור מחברות Apache Beam.
אופציונלי: אם רוצים להריץ מחברות ב-GPU, בקטע Machine type (סוג המכונה) בוחרים סוג מכונה שתומך ב-GPU. מידע נוסף זמין במאמר בנושא פלטפורמות GPU.
בקטע Networking, בוחרים רשת משנה למכונה הווירטואלית של מחברת.
אופציונלי: אם רוצים להגדיר מחברת בהתאמה אישית, אפשר לעיין במאמר בנושא יצירת מכונה באמצעות קונטיינר בהתאמה אישית.
לוחצים על יצירה. Dataflow Workbench יוצר מופע חדש של מחברת Apache Beam.
אחרי שיוצרים את מופע המחברת, הקישור Open JupyterLab הופך לפעיל. לוחצים על Open JupyterLab.
אופציונלי: התקנת יחסי תלות
מחברות Apache Beam כבר מגיעות עם Apache Beam ותלות במחבריGoogle Cloud שמותקנים. אם צינור הנתונים מכיל מחברים בהתאמה אישית או PTransforms בהתאמה אישית שתלויים בספריות של צד שלישי, צריך להתקין אותם אחרי שיוצרים מופע של מחברת.
דוגמאות ל-notebooks של Apache Beam
אחרי שיוצרים מכונת נוטבוק, פותחים אותה ב-JupyterLab. בכרטיסייה Files (קבצים) בסרגל הצד של JupyterLab, התיקייה Examples (דוגמאות) מכילה מחברות לדוגמה. מידע נוסף על עבודה עם קובצי JupyterLab זמין במאמר עבודה עם קבצים במדריך למשתמש של JupyterLab.
אלה מחברות ה-Notebook שזמינות:
- ספירת מילים
- ספירת מילים בשידור
- סטרימינג של נתוני נסיעות במוניות בניו יורק
- Apache Beam SQL במחברות עם השוואות לצינורות עיבוד נתונים
- Apache Beam SQL ב-notebooks עם Dataflow Runner
- Apache Beam SQL במחברות
- ספירת מילים ב-Dataflow
- Interactive Flink at Scale
- RunInference
- שימוש ב-GPU עם Apache Beam
- המחשה ויזואלית של נתונים
התיקייה Tutorials מכילה הדרכות נוספות שמסבירות את היסודות של Apache Beam. אלה המדריכים שזמינים:
- פעולות בסיסיות
- פעולות חכמות באלמנטים
- צבירות
- Windows
- פעולות קלט/פלט
- סטרימינג
- תרגילים סופיים
המחברות האלה כוללות טקסט הסבר ובלוקים של קוד עם הערות, כדי לעזור לכם להבין את המושגים של Apache Beam ואת השימוש ב-API. במדריכים יש גם תרגילים לתרגול המושגים.
בדוגמאות הקוד שבקטעים הבאים נעשה שימוש במחברת Streaming Word Count. יכול להיות שיהיו הבדלים קלים בין קטעי הקוד במדריך הזה לבין מה שמופיע במחברת Streaming Word Count.
יצירת מכונת Notebook
עוברים אל File > New > Notebook (קובץ > חדש > מחברת) ובוחרים ליבה שהיא Apache Beam 2.22 ואילך.
מחברות Apache Beam מבוססות על ענף הראשי של Apache Beam SDK. כלומר, יכול להיות שהגרסה האחרונה של ליבת המערכת שמוצגת בממשק המשתמש של מחברות ה-notebook תהיה מתקדמת יותר מהגרסה האחרונה של ה-SDK שפורסמה.
Apache Beam מותקן במכונת ה-notebook, לכן צריך לכלול את המודולים interactive_runner ו-interactive_beam ב-notebook.
import apache_beam as beam
from apache_beam.runners.interactive.interactive_runner import InteractiveRunner
import apache_beam.runners.interactive.interactive_beam as ib
אם מחברת ה-Notebook משתמשת ב-Google APIs אחרים, מוסיפים את הצהרות הייבוא הבאות:
from apache_beam.options import pipeline_options
from apache_beam.options.pipeline_options import GoogleCloudOptions
import google.auth
הגדרת אפשרויות אינטראקטיביות
השורה הבאה מגדירה את משך הזמן שבו InteractiveRunner מתעד נתונים ממקור לא מוגבל. בדוגמה הזו, משך הזמן מוגדר ל-10 דקות.
ib.options.recording_duration = '10m'
אפשר גם לשנות את מגבלת הגודל של ההקלטה (בבייטים) למקור לא מוגבל באמצעות המאפיין recording_size_limit.
# Set the recording size limit to 1 GB.
ib.options.recording_size_limit = 1e9
אפשרויות אינטראקטיביות נוספות מפורטות במחלקה interactive_beam.options.
יצירת פייפליין
מאתחלים את צינור העיבוד באמצעות אובייקט InteractiveRunner.
options = pipeline_options.PipelineOptions(flags={})
# Set the pipeline mode to stream the data from Pub/Sub.
options.view_as(pipeline_options.StandardOptions).streaming = True
# Set the project to the default project in your current Google Cloud environment.
# The project is used to create a subscription to the Pub/Sub topic.
_, options.view_as(GoogleCloudOptions).project = google.auth.default()
p = beam.Pipeline(InteractiveRunner(), options=options)
קריאה והמחשה של הנתונים
בדוגמה הבאה מוצג צינור עיבוד נתונים של Apache Beam שיוצר מינוי לנושא Pub/Sub שצוין וקורא מהמינוי.
words = p | "read" >> beam.io.ReadFromPubSub(topic="projects/pubsub-public-data/topics/shakespeare-kinglear")
הצינור סופר את המילים לפי חלונות מהמקור. היא יוצרת חלונות קבועים, כל חלון באורך של 10 שניות.
windowed_words = (words
| "window" >> beam.WindowInto(beam.window.FixedWindows(10)))
אחרי חלוקת הנתונים לחלונות, המילים נספרות לפי חלון.
windowed_word_counts = (windowed_words
| "count" >> beam.combiners.Count.PerElement())
ה-method show() יוצר ויזואליזציה של ה-PCollection שמתקבל במחברת.
ib.show(windowed_word_counts, include_window_info=True)
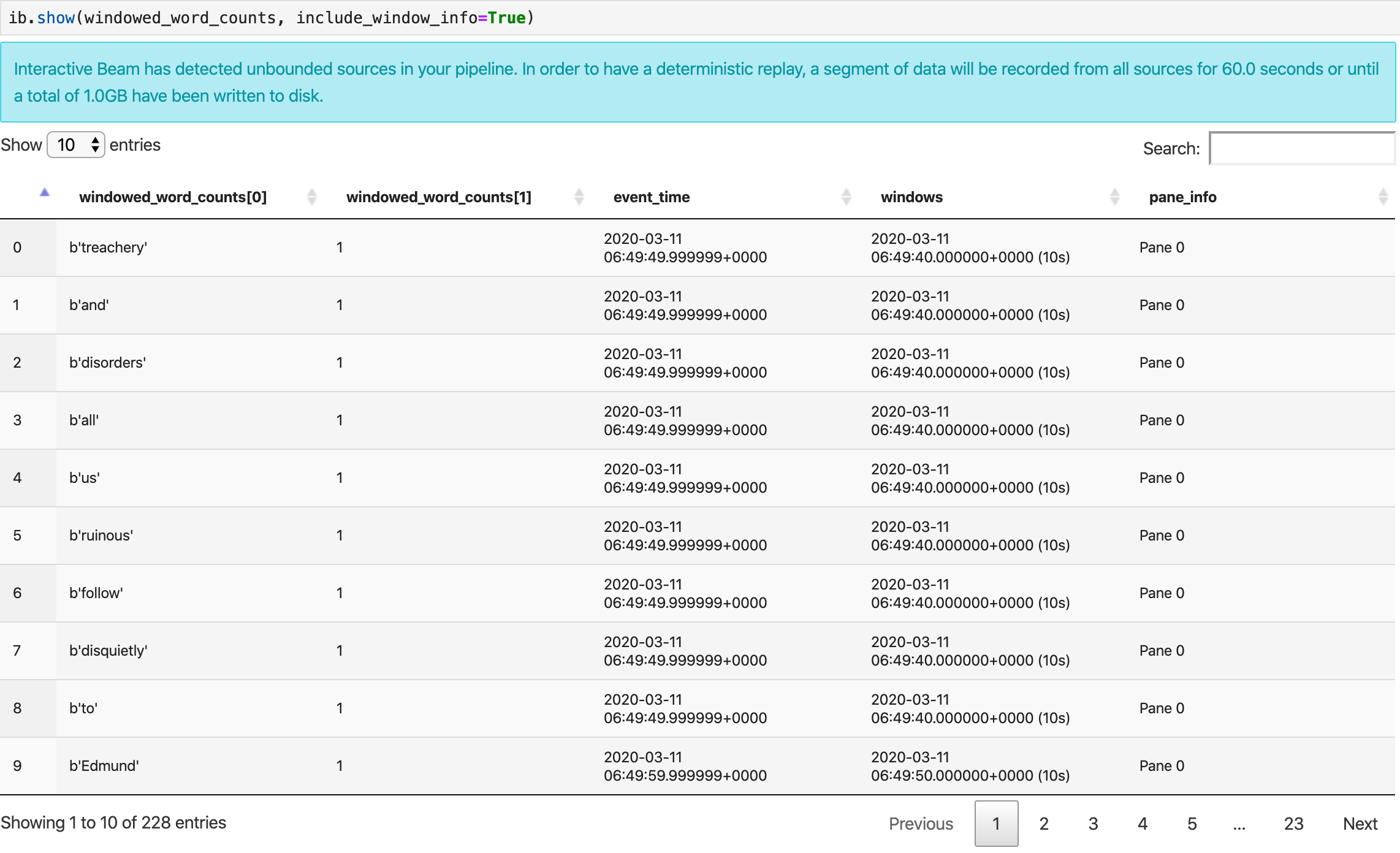
אפשר לצמצם את קבוצת התוצאות מ-show() באמצעות הגדרה של שני פרמטרים אופציונליים: n ו-duration.
- מגדירים את
nכדי להגביל את קבוצת התוצאות כך שיוצגו לכל היותרnמספר אלמנטים, כמו 20. אם לא מגדירים אתn, התנהגות ברירת המחדל היא הצגת הרכיבים האחרונים שצולמו עד לסיום ההקלטה מהמקור. - מגדירים את
durationכדי להגביל את קבוצת התוצאות למספר שניות מסוים של נתונים, החל מתחילת ההקלטה של המקור. אם לא מוגדרdurationהתנהגות ברירת המחדל היא הצגת כל הרכיבים עד לסיום ההקלטה.
אם מגדירים את שני הפרמטרים האופציונליים, show() מפסיק לפעול כשמתקיימת אחת מההגדרות של הסף. בדוגמה הבאה, הפונקציה show() מחזירה לכל היותר 20 רכיבים שמחושבים על סמך נתונים מ-30 השניות הראשונות ממקורות מוקלטים.
ib.show(windowed_word_counts, include_window_info=True, n=20, duration=30)
כדי להציג את הנתונים בהצגה חזותית, מעבירים את הערך visualize_data=True ל-method show(). אפשר להחיל כמה מסננים על הוויזואליזציות. בתרשים ההמחשה הבא אפשר לסנן לפי תווית וציר:
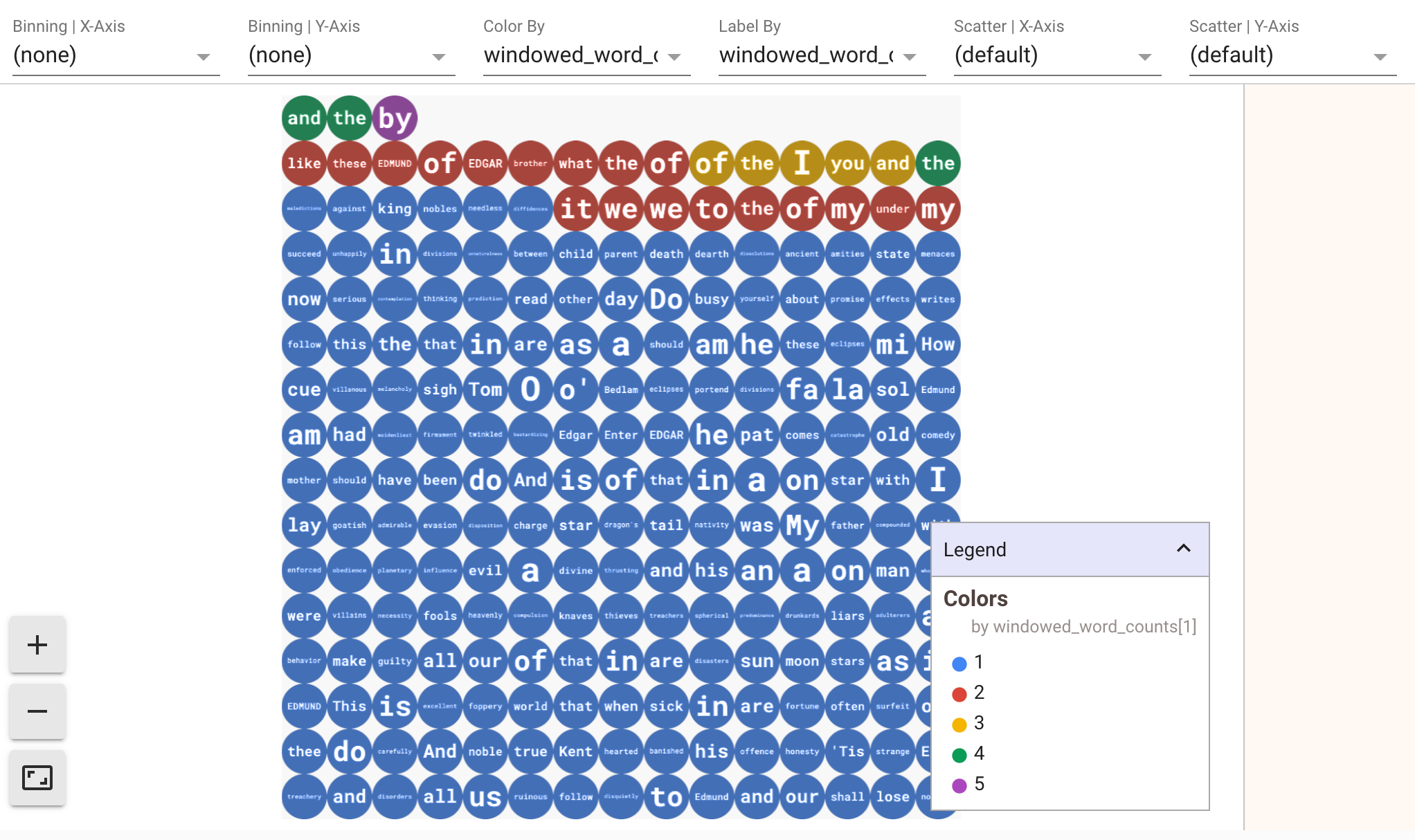
כדי להבטיח אפשרות הפעלה חוזרת בזמן יצירת אב טיפוס של צינורות עיבוד נתונים של סטרימינג, קריאות השיטה show() משתמשות מחדש בנתונים שנתפסו כברירת מחדל. כדי לשנות את ההתנהגות הזו ולגרום לשיטה show() לאחזר תמיד נתונים חדשים, צריך להגדיר את interactive_beam.options.enable_capture_replay = False. בנוסף, אם מוסיפים למחברת מקור שני ללא הגבלה, הנתונים מהמקור הקודם ללא הגבלה נמחקים.
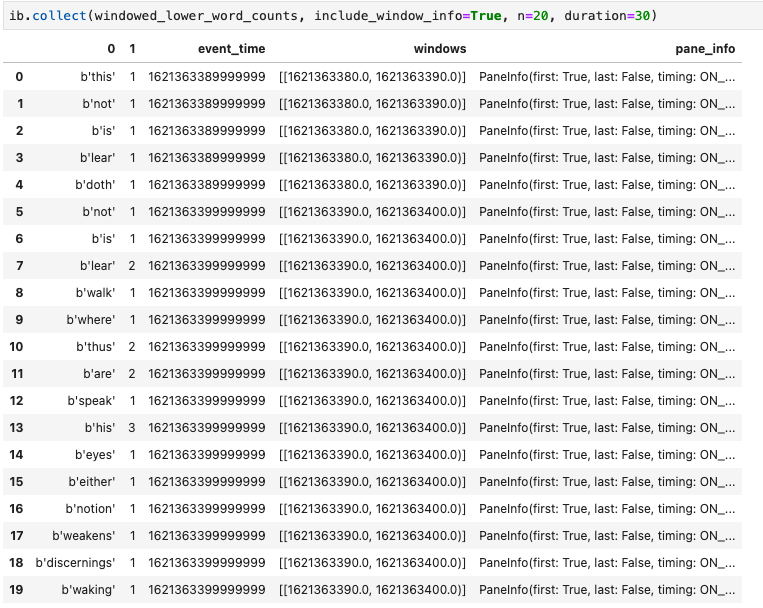
עוד תצוגה חזותית שימושית במחברות Apache Beam היא Pandas DataFrame. בדוגמה הבאה, המילים מומרות קודם לאותיות קטנות ואז מחושבת התדירות של כל מילה.
windowed_lower_word_counts = (windowed_words
| beam.Map(lambda word: word.lower())
| "count" >> beam.combiners.Count.PerElement())
הפלט של השיטה collect() הוא Pandas DataFrame.
ib.collect(windowed_lower_word_counts, include_window_info=True)
עריכה והרצה מחדש של תא הן פעולות נפוצות בפיתוח מחברות. כשעורכים ומריצים מחדש תא במחברת Apache Beam, הפעולה המיועדת של הקוד בתא המקורי לא מבוטלת. לדוגמה, אם תא מוסיף PTransform לצינור, הפעלה מחדש של התא הזה מוסיפה עוד PTransform לצינור. כדי לנקות את המצב, מפעילים מחדש את ליבת ה-Kernel ואז מריצים מחדש את התאים.
המחשה ויזואלית של הנתונים באמצעות הכלי האינטראקטיבי לבדיקת Beam
יכול להיות שזה יסיח את דעתכם אם תנסו לבדוק את הנתונים של PCollection על ידי קריאה חוזרת ונשנית ל-show() ול-collect(), במיוחד אם הפלט תופס הרבה מקום במסך ומקשה על הניווט ב-notebook. אפשר גם להשוות בין כמה PCollections זה לצד זה כדי לוודא שהטרנספורמציה פועלת כמצופה. לדוגמה, כש-PCollection עובר טרנספורמציה ומפיק את השני. במקרים כאלה, הכלי לבדיקת Interactive Beam הוא פתרון נוח.
הכלי האינטראקטיבי לבדיקת Beam מסופק כתוסף JupyterLab apache-beam-jupyterlab-sidepanel שמותקן מראש ב-notebook של Apache Beam. באמצעות התוסף, אפשר לבדוק באופן אינטראקטיבי את המצב של צינורות הנתונים והנתונים שמשויכים לכל PCollection בלי להפעיל במפורש את show() או collect().
יש 3 דרכים לפתוח את הכלי לבדיקת רכיבים:
לוחצים על
Interactive Beamבסרגל התפריטים העליון של JupyterLab. בתפריט הנפתח, מאתרים אתOpen Inspectorולוחצים עליו כדי לפתוח את כלי הבדיקה.
משתמשים בדף מרכז האפליקציות. אם לא נפתח דף של מרכז האפליקציות, לוחצים על
File->New Launcherכדי לפתוח אותו. בדף של מרכז האפליקציות, מאתרים אתInteractive Beamולוחצים עלOpen Inspectorכדי לפתוח את כלי הבדיקה.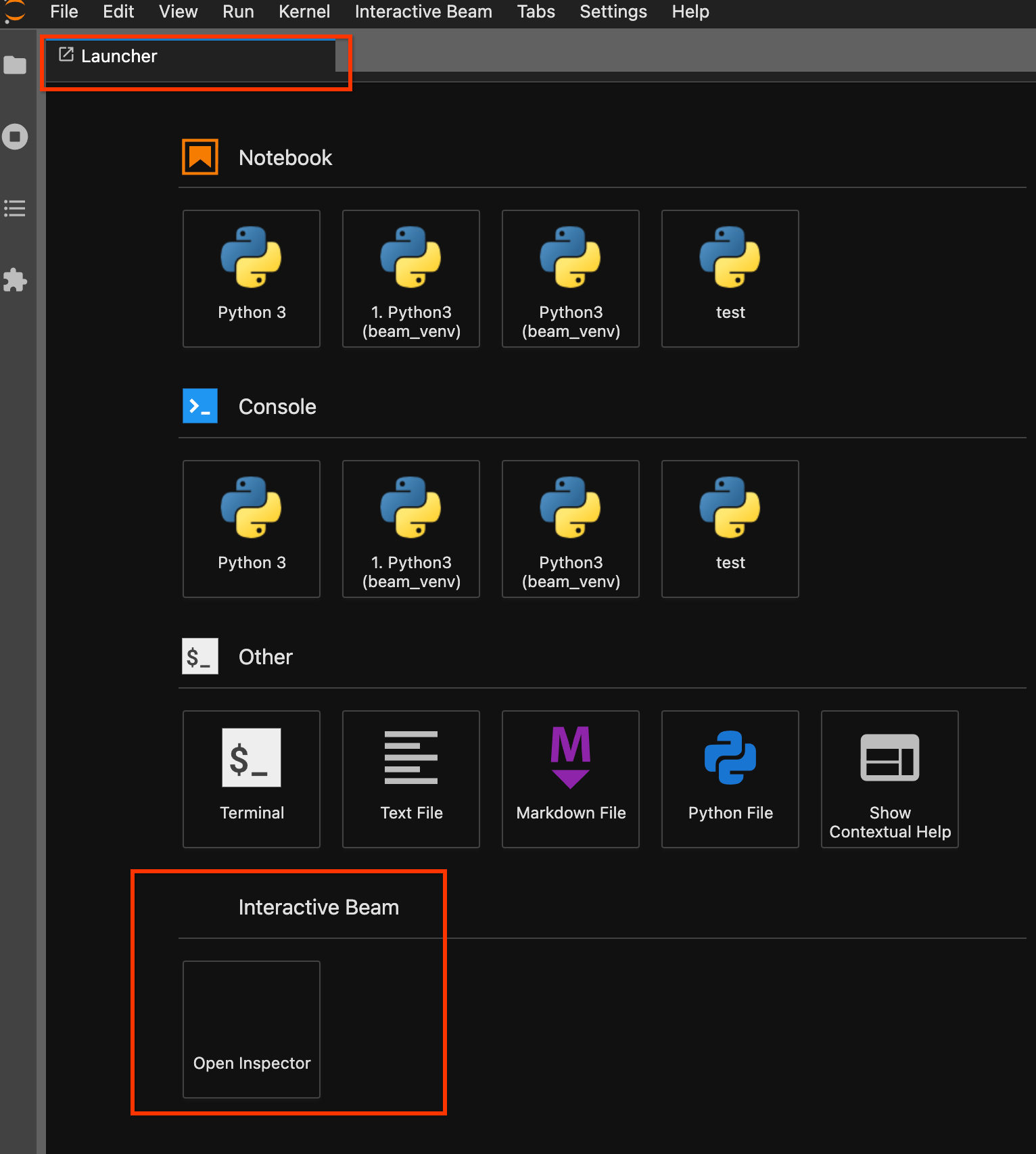
משתמשים בלוח הפקודות. בסרגל התפריטים של JupyterLab, לוחצים על
View>Activate Command Palette. בתיבת הדו-שיח, מחפשים אתInteractive Beamכדי להציג את כל האפשרויות של התוסף. לוחצים עלOpen Inspectorכדי לפתוח את כלי הבדיקה.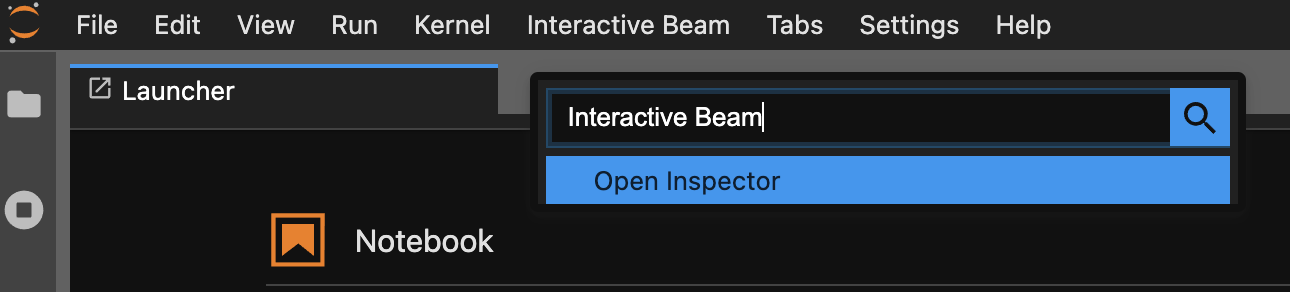
כאשר כלי הבדיקה עומד להיפתח:
אם פתוח מחברת אחת בלבד, כלי הבדיקה מתחבר אליה באופן אוטומטי.
אם אף מחברת לא פתוחה, מופיעה תיבת דו-שיח שמאפשרת לבחור ליבה.
אם פתוחים כמה מחברות, מופיע תיבת דו-שיח שמאפשרת לבחור את סשן המחברת.
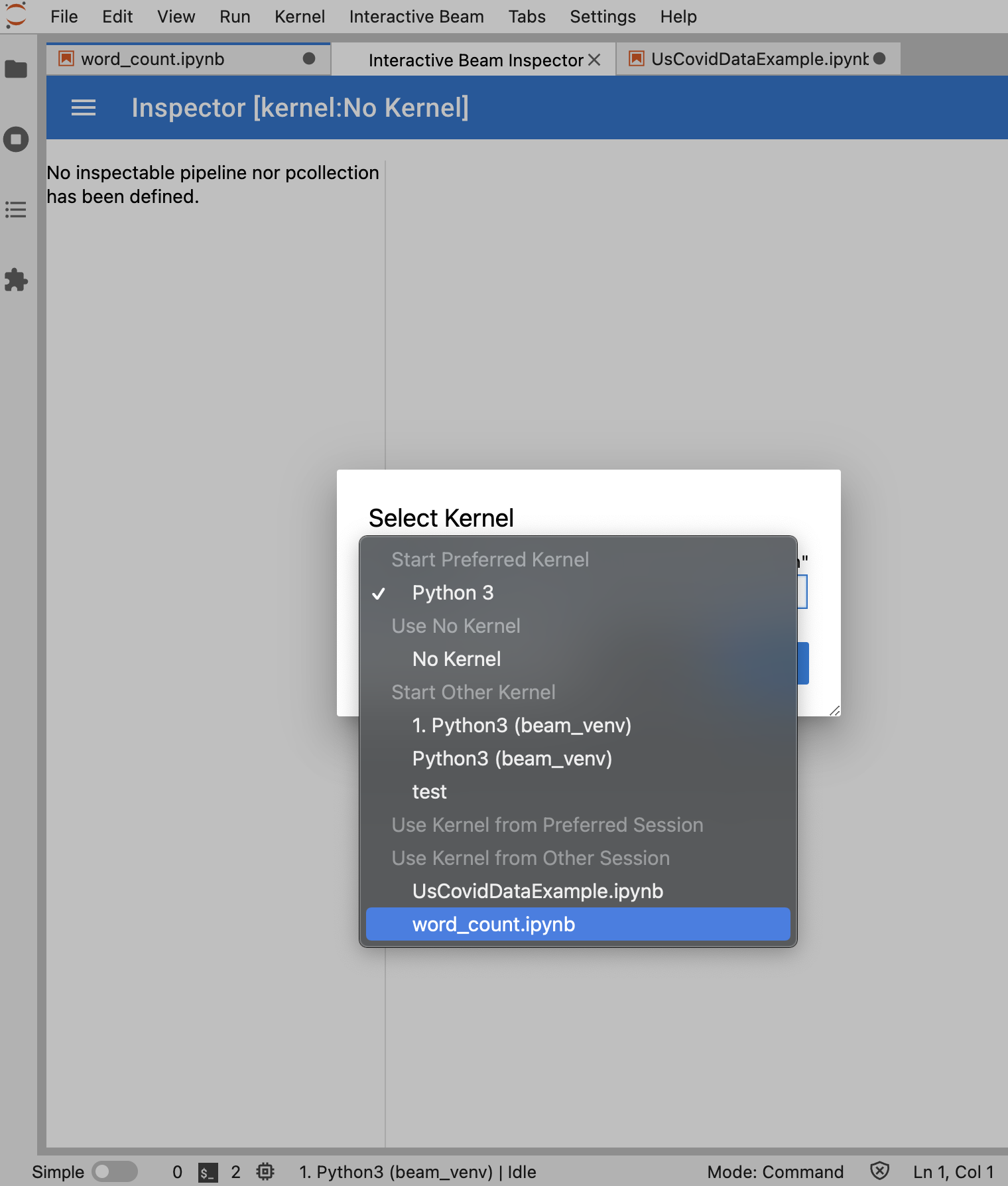
מומלץ לפתוח לפחות מחברת אחת ולבחור עבורה ליבה לפני שפותחים את כלי הבדיקה. אם פותחים כלי לבדיקת ליבה לפני שפותחים מחברת, כשפותחים מחברת כדי להתחבר לכלי לבדיקת ליבה, צריך לבחור את Interactive Beam Inspector Session מתוך Use
Kernel from Preferred Session. כלי לבדיקת קוד ו-Notebook מחוברים כשהם חולקים את אותו סשן, ולא סשנים שונים שנוצרו מאותו ליבה. בחירה באותו ליבה מתוך Start Preferred Kernel יוצרת סשן חדש שלא תלוי בסשנים קיימים של מחברות או כלי בדיקה פתוחים.
אתם יכולים לפתוח כמה חלונות של כלי הבדיקה למחברת פתוחה, ולסדר אותם על ידי גרירה ושחרור של הכרטיסיות שלהם באופן חופשי בסביבת העבודה.
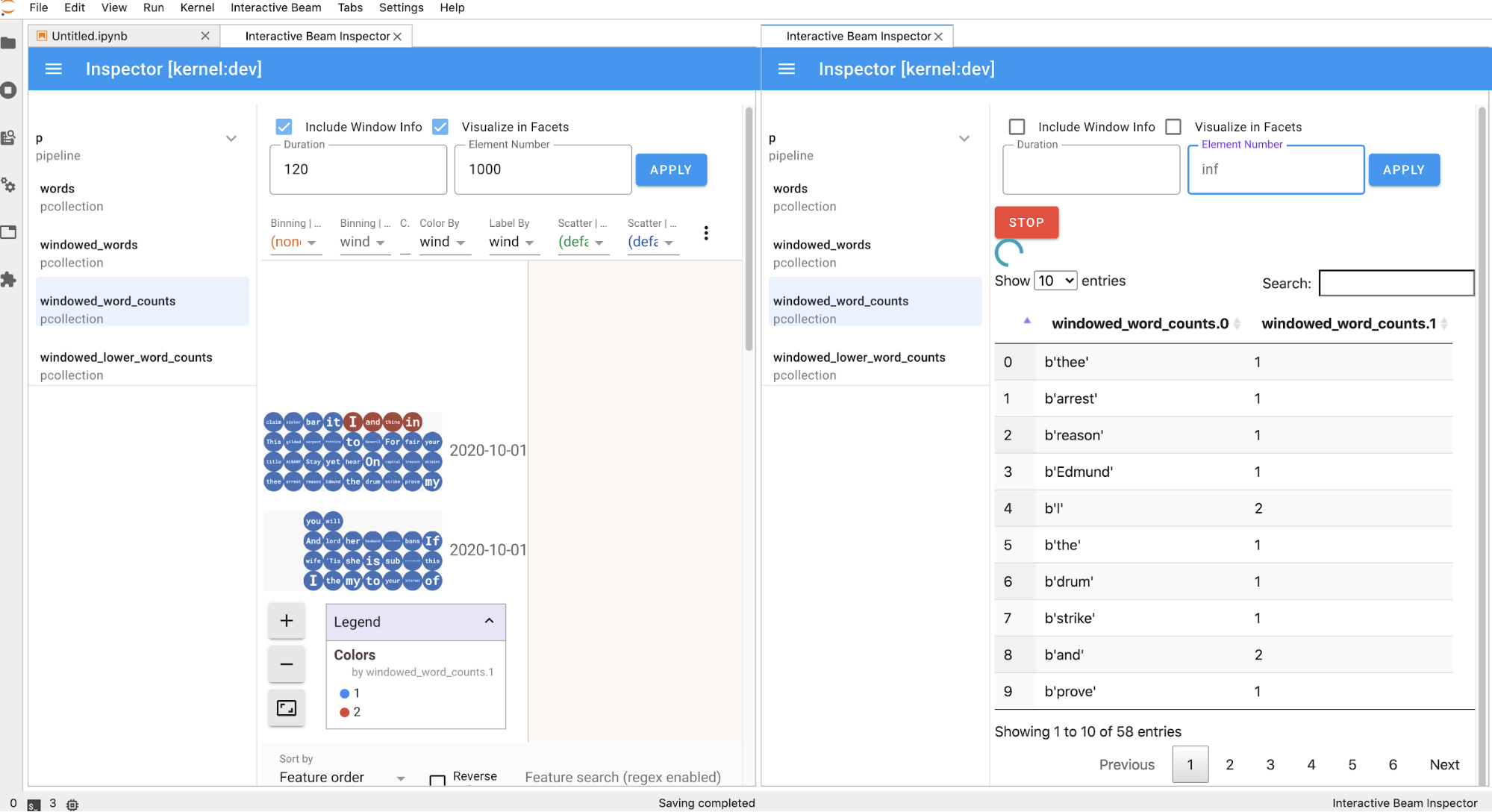
דף כלי הבדיקה מתעדכן אוטומטית כשמריצים תאים במחברת. בדף מופיעים צינורות (pipelines) ו-PCollections שהוגדרו במחברת המחוברת. PCollections מאורגנים לפי הצינורות שאליהם הם שייכים, ואפשר לכווץ אותם בלחיצה על כותרת הצינור.
כשלוחצים על הפריטים בצינורות ובPCollections, כלי הבדיקה מציג את ההדמיות התואמות בצד שמאל:
אם זה
PCollection, הכלי לבדיקת רכיבים מעבד את הנתונים שלו (באופן דינמי אם הנתונים עדיין מגיעים ל-PCollectionsלא מוגבל) עם ווידג'טים נוספים כדי לכוונן את הוויזואליזציה אחרי שלוחצים על הלחצןAPPLY.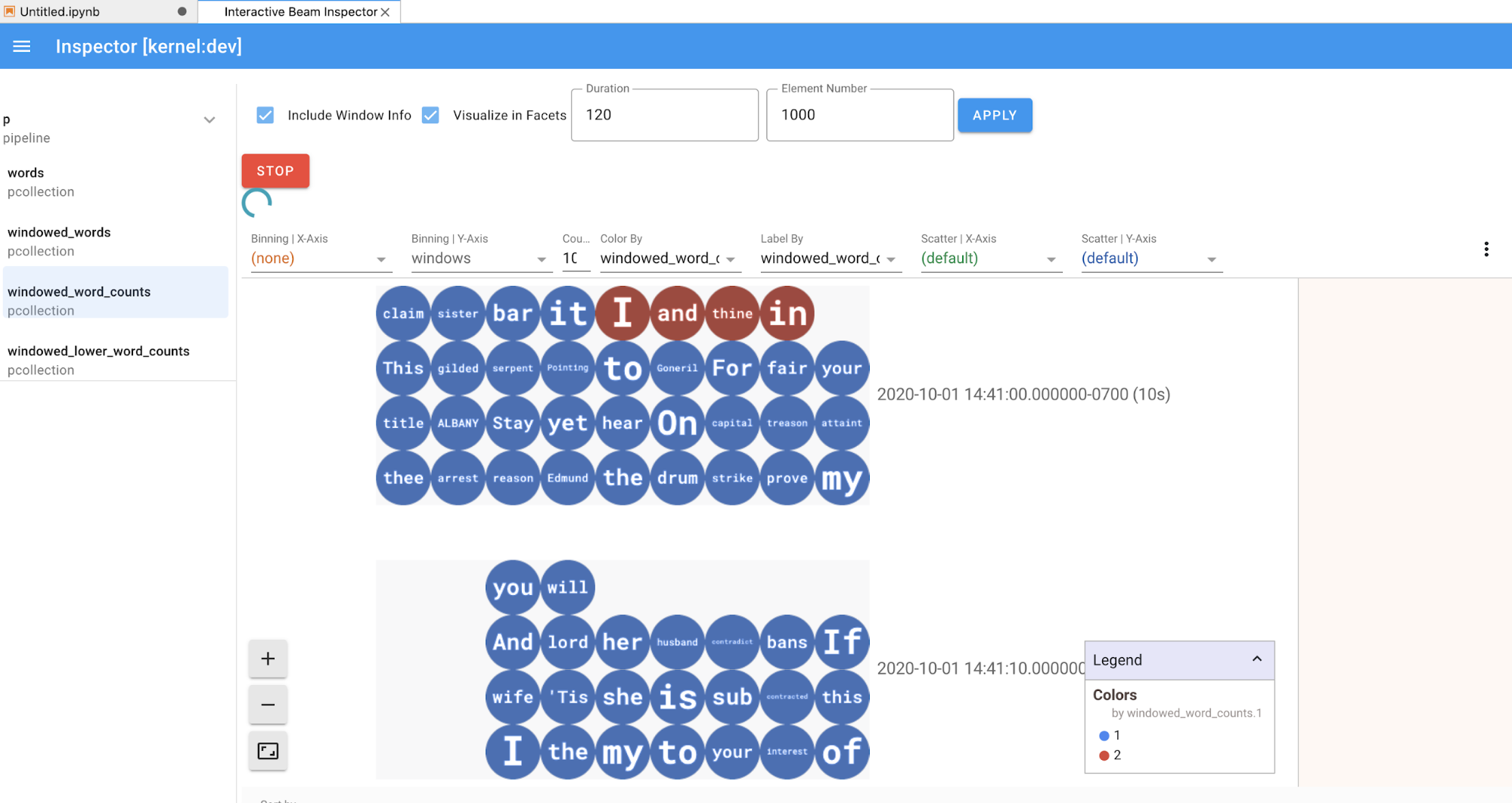
הכלי לבדיקת קוד והמחברת הפתוחה חולקים את אותו סשן של ליבת Python, ולכן הם מונעים אחד מהשני לפעול. לדוגמה, אם מחברת עסוקה בהרצת קוד, כלי הבדיקה לא מתעדכן עד שהמחברת מסיימת את ההרצה. לעומת זאת, אם רוצים להריץ קוד מיד במחברת בזמן שהכלי לבדיקת רכיבים חזותיים מציג
PCollectionבאופן דינמי, צריך ללחוץ על הלחצןSTOPכדי להפסיק את ההצגה החזותית ולשחרר את ליבת המערכת למחברת באופן יזום.אם מדובר בצינור, בחלונית הבדיקה מוצג תרשים הצינור.
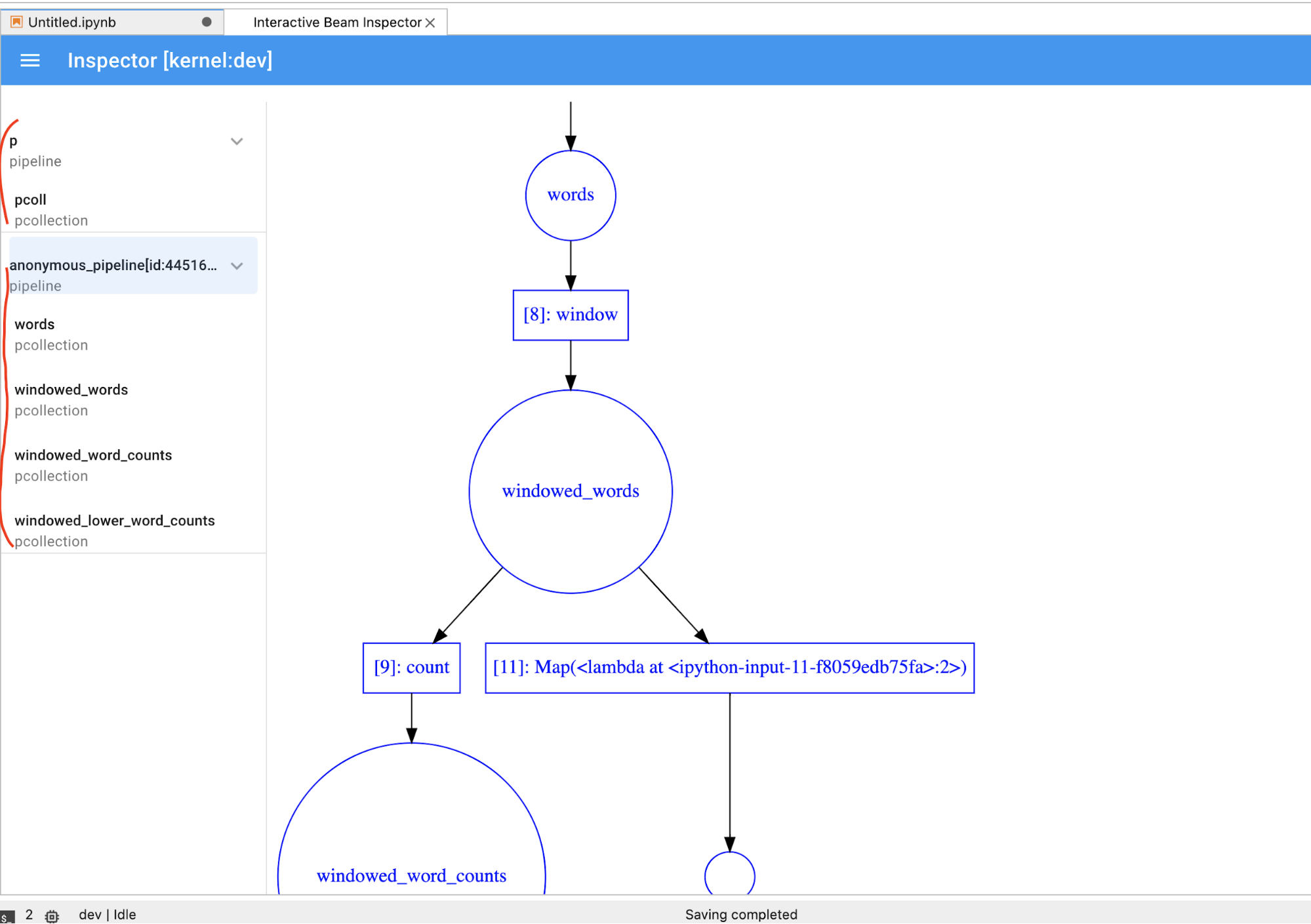
יכול להיות שתבחינו בצינורות אנונימיים. לצינורות האלה יש PCollections שאפשר לגשת אליהם, אבל הם כבר לא מוזכרים בסשן הראשי. לדוגמה:
p = beam.Pipeline()
pcoll = p | beam.Create([1, 2, 3])
p = beam.Pipeline()
בדוגמה הקודמת נוצר צינור ריק p וצינור אנונימי שמכיל PCollection pcoll אחד. אפשר לגשת לצינור האנונימי באמצעות pcoll.pipeline.
אפשר להחליף בין צינור העיבוד לרשימה PCollection כדי לחסוך מקום לתצוגות חזותיות גדולות.
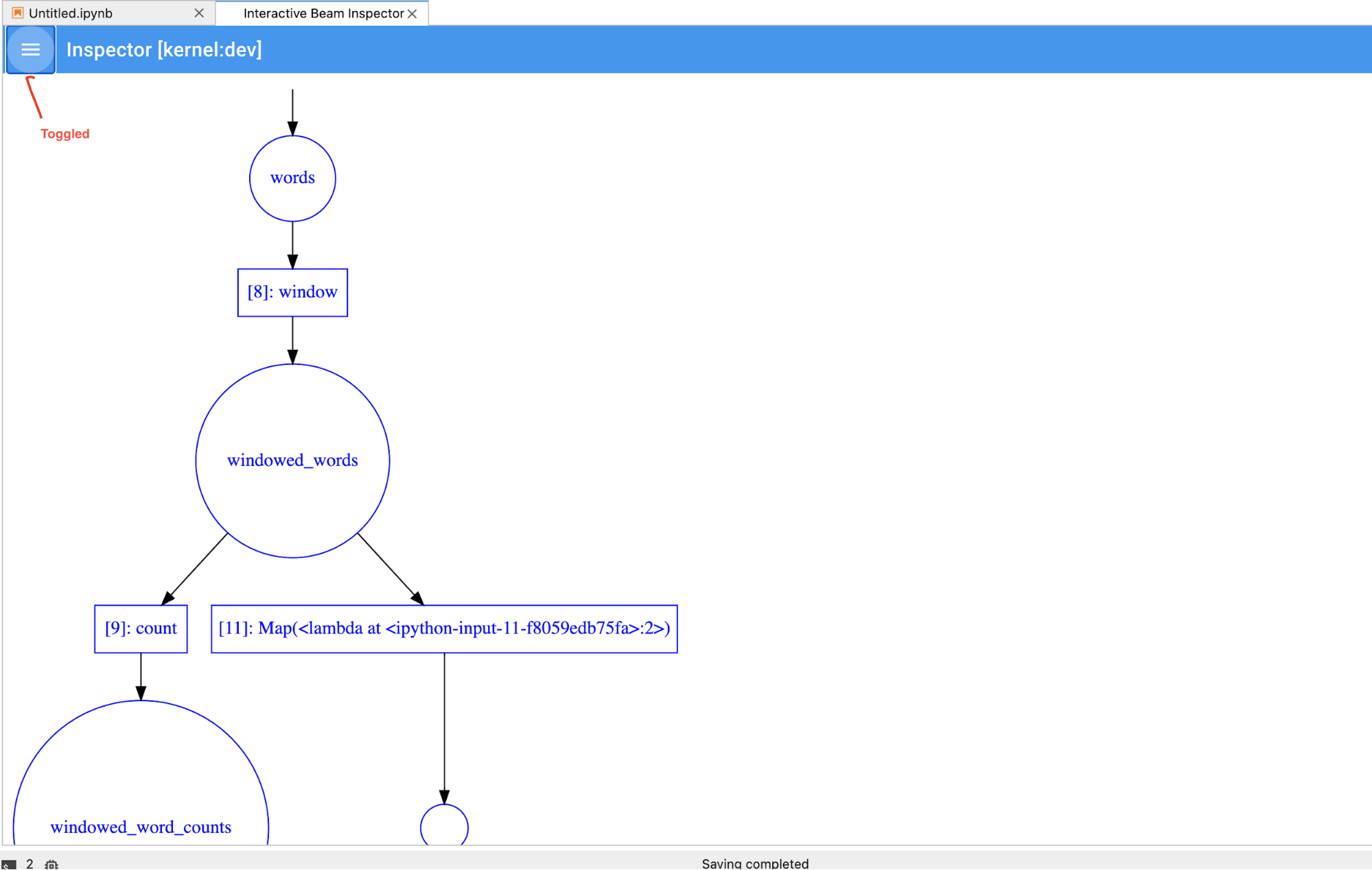
הסבר על סטטוס התיעוד של צינור
בנוסף להמחשות, אפשר גם לבדוק את סטטוס התיעוד של פייפליין אחד או של כל הפייפליינים במופע של מחברת Jupyter, באמצעות קריאה לפונקציה describe.
# Return the recording status of a specific pipeline. Leave the parameter list empty to return
# the recording status of all pipelines.
ib.recordings.describe(p)
השיטה describe() מספקת את הפרטים הבאים:
- הגודל הכולל (בבייטים) של כל ההקלטות של הצינור בדיסק
- שעת ההתחלה של עבודת ההקלטה ברקע (בשניות מאז ראשית זמן יוניקס)
- הסטטוס הנוכחי של הפייפליין של עבודת ההקלטה ברקע
- משתנה Python לצינור העיבוד
הפעלת משימות Dataflow מצינור שנוצר ב-notebook
- אופציונלי: לפני שמשתמשים במחברת כדי להריץ משימות Dataflow, מפעילים מחדש את ליבת המערכת, מריצים מחדש את כל התאים ומאמתים את הפלט. אם מדלגים על השלב הזה, יכול להיות שמצבים מוסתרים ב-notebook ישפיעו על תרשים העבודה באובייקט של צינור העיבוד.
- מפעילים את Dataflow API.
מוסיפים את הצהרת הייבוא הבאה:
from apache_beam.runners import DataflowRunnerמעבירים את אפשרויות צינור עיבוד הנתונים.
# Set up Apache Beam pipeline options. options = pipeline_options.PipelineOptions() # Set the project to the default project in your current Google Cloud # environment. _, options.view_as(GoogleCloudOptions).project = google.auth.default() # Set the Google Cloud region to run Dataflow. options.view_as(GoogleCloudOptions).region = 'us-central1' # Choose a Cloud Storage location. dataflow_gcs_location = 'gs://<change me>/dataflow' # Set the staging location. This location is used to stage the # Dataflow pipeline and SDK binary. options.view_as(GoogleCloudOptions).staging_location = '%s/staging' % dataflow_gcs_location # Set the temporary location. This location is used to store temporary files # or intermediate results before outputting to the sink. options.view_as(GoogleCloudOptions).temp_location = '%s/temp' % dataflow_gcs_location # If and only if you are using Apache Beam SDK built from source code, set # the SDK location. This is used by Dataflow to locate the SDK # needed to run the pipeline. options.view_as(pipeline_options.SetupOptions).sdk_location = ( '/root/apache-beam-custom/packages/beam/sdks/python/dist/apache-beam-%s0.tar.gz' % beam.version.__version__)אפשר לשנות את ערכי הפרמטרים. לדוגמה, אפשר לשנות את הערך
regionמ-us-central1.מריצים את צינור עיבוד הנתונים באמצעות
DataflowRunner. בשלב הזה, העבודה מופעלת בשירות Dataflow.runner = DataflowRunner() runner.run_pipeline(p, options=options)
pהוא אובייקט של צינור עיבוד נתונים מתוך יצירת צינור עיבוד נתונים.
דוגמה לאופן ביצוע ההמרה הזו ב-notebook אינטראקטיבי מופיעה ב-notebook של Dataflow Word Count במופע ה-notebook.
לחלופין, אפשר לייצא את המחברת כסקריפט שניתן להפעלה, לשנות את קובץ ה-.py שנוצר באמצעות השלבים הקודמים, ואז לפרוס את צינור הנתונים בשירות Dataflow.
שמירת ה-Notebook
מחברות שיוצרים נשמרות באופן מקומי במופע הפעיל של המחברת. אם מאפסים או משביתים את מופע ה-notebook במהלך הפיתוח, קובצי ה-notebook החדשים נשמרים כל עוד הם נוצרו בספרייה /home/jupyter.
עם זאת, אם מוחקים מופע של מחברת, גם המחברות האלה נמחקות.
כדי לשמור את קובצי ה-notebook לשימוש עתידי, אפשר להוריד אותם באופן מקומי לתחנת העבודה, לשמור אותם ב-GitHub או לייצא אותם לפורמט קובץ אחר.
שמירת מחברת בדיסקים נוספים של אחסון מתמיד
אם רוצים לשמור את העבודה, כמו מחברות וסקריפטים, בכמה מקרים שונים של מחברות, צריך לאחסן אותם ב-Persistent Disk.
יוצרים דיסק אחסון מתמיד (persistent disk) או מצרפים דיסק קיים. פועלים לפי ההוראות לשימוש ב-
sshכדי להתחבר למכונה הווירטואלית של מופע המחברת ולהנפיק פקודות ב-Cloud Shell שנפתח.שימו לב לספרייה שבה דיסק האחסון המתמיד (persistent disk) מותקן, למשל,
/mnt/myDisk.עורכים את פרטי המכונה הווירטואלית של מופע הנוטבוק כדי להוסיף רשומה ל-
Custom metadata: מפתח –container-custom-params; ערך –-v /mnt/myDisk:/mnt/myDisk.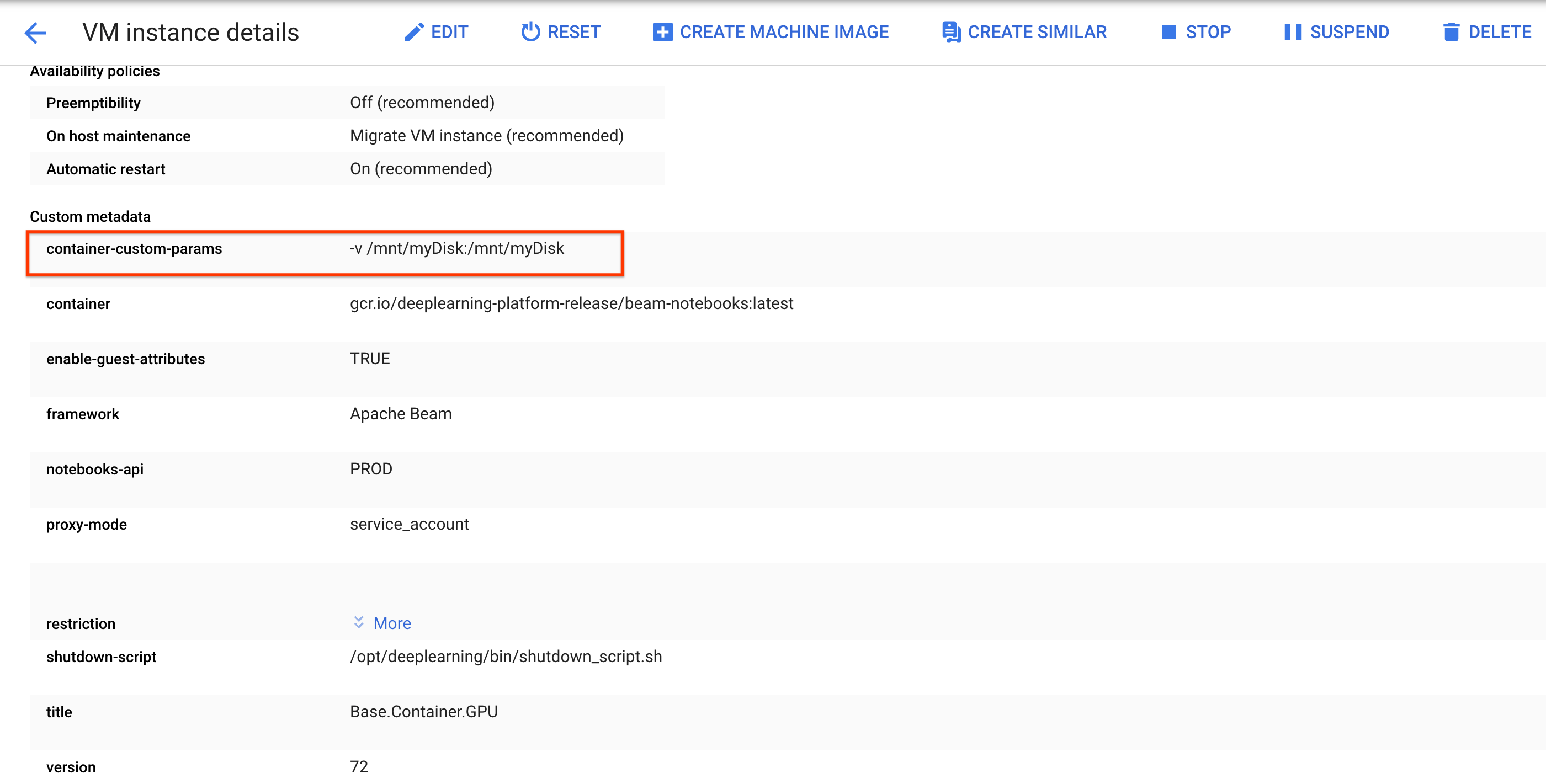
לוחצים על Save.
כדי לעדכן את השינויים האלה, מאפסים את מופע ה-notebook.
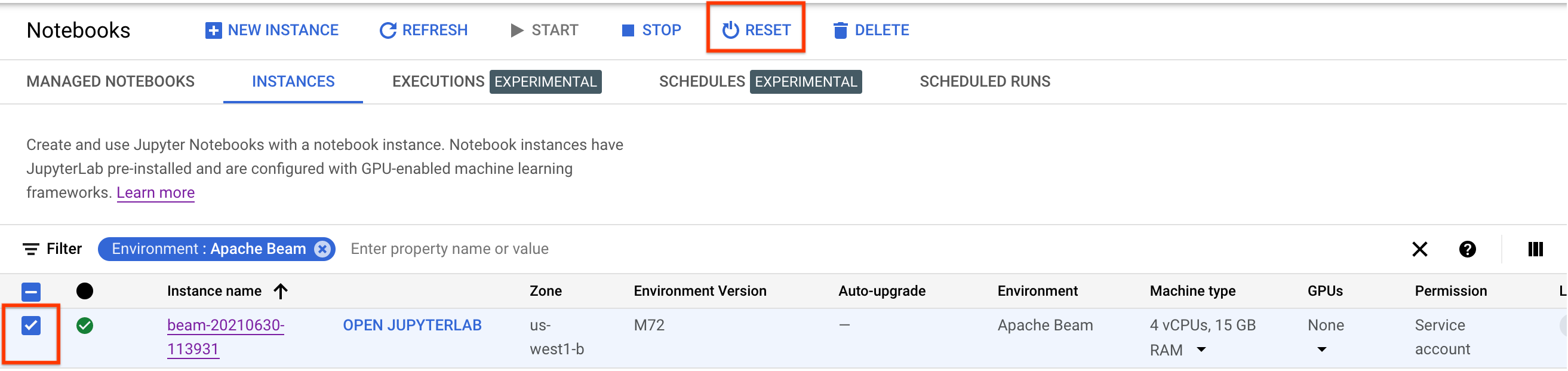
אחרי האיפוס, לוחצים על Open JupyterLab. יכול להיות שיעבור זמן עד שממשק המשתמש של JupyterLab יהיה זמין. אחרי שממשק המשתמש מופיע, פותחים טרמינל ומריצים את הפקודה הבאה:
ls -al /mntהספרייה/mnt/myDiskאמורה להופיע ברשימה.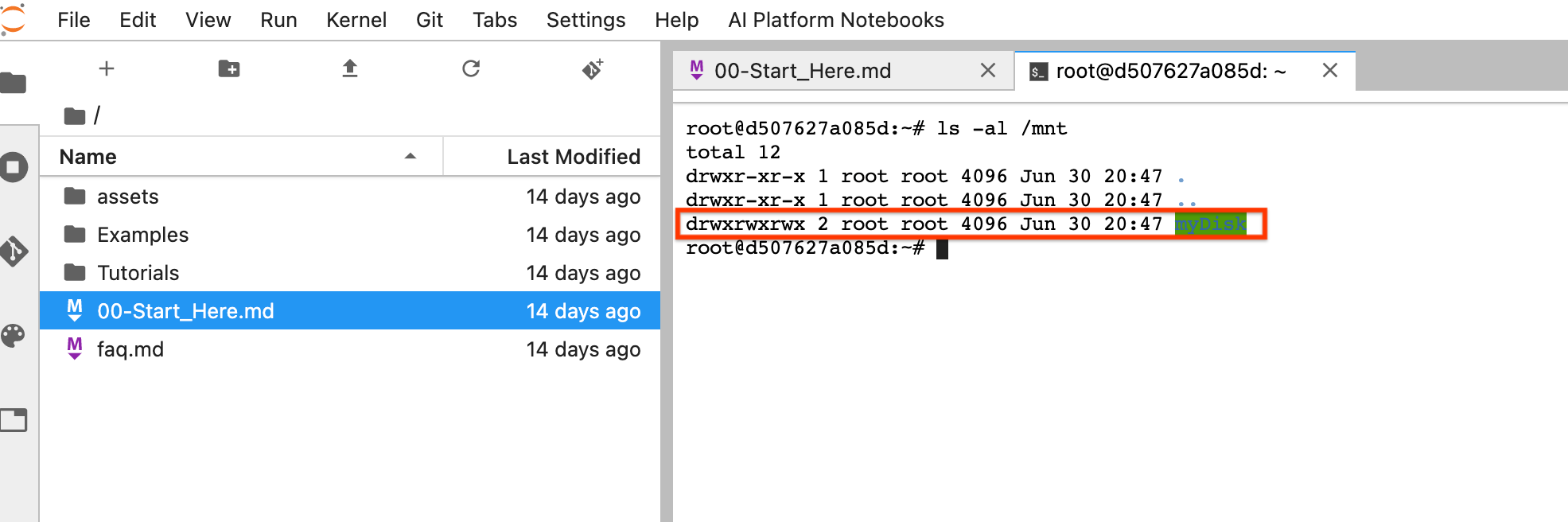
עכשיו אפשר לשמור את העבודה בספרייה /mnt/myDisk. גם אם מוחקים את מופע המחברת, הדיסק המתמיד עדיין קיים בפרויקט. לאחר מכן תוכלו לצרף את דיסק האחסון המתמיד הזה למופעי מחברת אחרים.
הסרת המשאבים
אחרי שמסיימים להשתמש במופע של מחברת Apache Beam, צריך למחוק את המשאבים שיצרתם ב- Google Cloud על ידי כיבוי המופע של המחברת.
המאמרים הבאים
- מידע נוסף על התכונות המתקדמות שאפשר להשתמש בהן במחברות Apache Beam. התכונות המתקדמות כוללות את תהליכי העבודה הבאים: