
אפשר לראות תרשימי מעקב של שינוי גודל אוטומטי של משימות סטרימינג בממשק של Dataflow monitoring. בתרשימים האלה מוצגים מדדים לאורך משך הזמן של משימת פייפליין, והם כוללים את הפרטים הבאים:
- מספר מופעי העובדים שנעשה בהם שימוש בעבודה בכל נקודת זמן
- קבצי היומן של ההתאמה האוטומטית לעומס
- העומס המשוער לאורך זמן
- ממוצע ניצול המעבד לאורך זמן
התרשימים מיושרים אנכית כדי שתוכלו ליצור קורלציה בין מדדי העומס והשימוש במעבד לבין אירועי שינוי הגודל של העובדים.
מידע נוסף על האופן שבו Dataflow מקבל החלטות לגבי התאמה אוטומטית לעומס, זמין במאמרי העזרה בנושא תכונות של כוונון אוטומטי. מידע נוסף על מדדים ומעקב ב-Dataflow זמין במאמר שימוש בממשק המעקב של Dataflow.
גישה לתרשימי מעקב של התאמה לעומס (autoscaling)
אפשר לגשת לממשק המעקב של Dataflow באמצעותGoogle Cloud console. כדי לגשת לכרטיסיית המדדים Autoscaling:
- נכנסים למסוף Google Cloud .
- בוחרים את הפרויקט Google Cloud .
- פותחים את תפריט הניווט.
- ב-Analytics, לוחצים על Dataflow (זרימת נתונים). מוצגת רשימה של משימות Dataflow עם הסטטוס שלהן.
- לוחצים על העבודה שרוצים לעקוב אחריה ואז על הכרטיסייה שינוי גודל אוטומטי.
מעקב אחרי מדדים של התאמה אוטומטית לעומס
שירות Dataflow בוחר באופן אוטומטי את מספר מכונות העבודה שנדרשות להפעלת העבודה שלכם עם התאמה אוטומטית לעומס. מספר המופעים של העובדים יכול להשתנות לאורך זמן בהתאם לדרישות העבודה.
אפשר לראות את מדדי ההתאמה האוטומטית לעומס בכרטיסייה התאמה אוטומטית לעומס בממשק של Dataflow. כל מדד מאורגן בתרשימים הבאים:
בסרגל הפעולות של התאמה אוטומטית לעומס מוצג הסטטוס הנוכחי של התאמה אוטומטית לעומס ומספר העובדים.
התאמה אוטומטית לעומס (Automatic scaling)
בתרשים Autoscaling מוצג גרף של סדרת זמנים של מספר העובדים הנוכחי, מספר העובדים המקסימלי ומספר העובדים המינימלי והמקסימלי.

כדי לראות את רישומי ההתאמה האוטומטית לעומס, לוחצים על הצגת רישומי ההתאמה האוטומטית לעומס.
כדי לראות את היסטוריית השינויים של התאמה אוטומטית לעומס (automatic scaling), לוחצים על היסטוריה נוספת. מוצגת טבלה עם מידע על היסטוריית העובדים של צינור הנתונים. ההיסטוריה כוללת אירועים של התאמה אוטומטית לעומס, כולל מידע על כך שמספר העובדים הגיע למספר המינימלי או המקסימלי של העובדים.
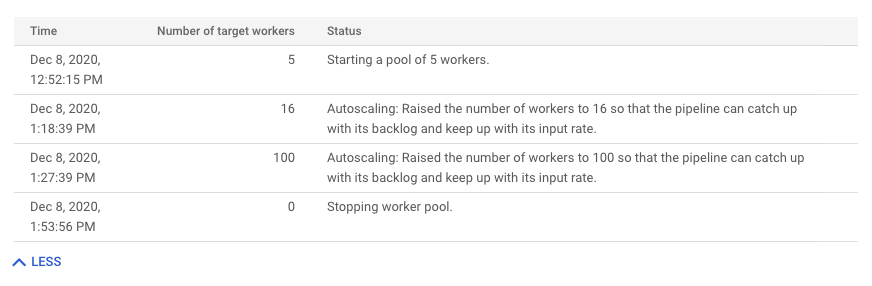
הסבר על ההתאמה האוטומטית לעומס (רק ב-Streaming Engine)
בתרשים הסבר על התאמה אוטומטית לעומס מוצגות הסיבות לכך שהמידרוג האוטומטי הגדיל את הקיבולת, הקטין אותה או לא ביצע פעולות במהלך תקופה מסוימת.
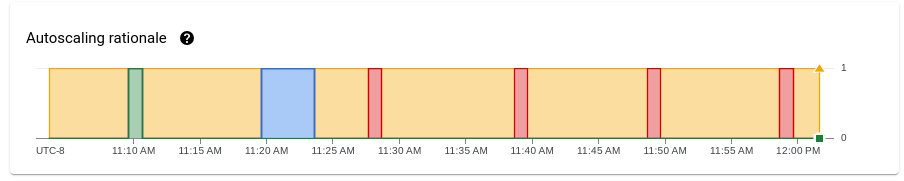
כדי לראות תיאור של ההיגיון בנקודה ספציפית, מעבירים את הסמן מעל התרשים.
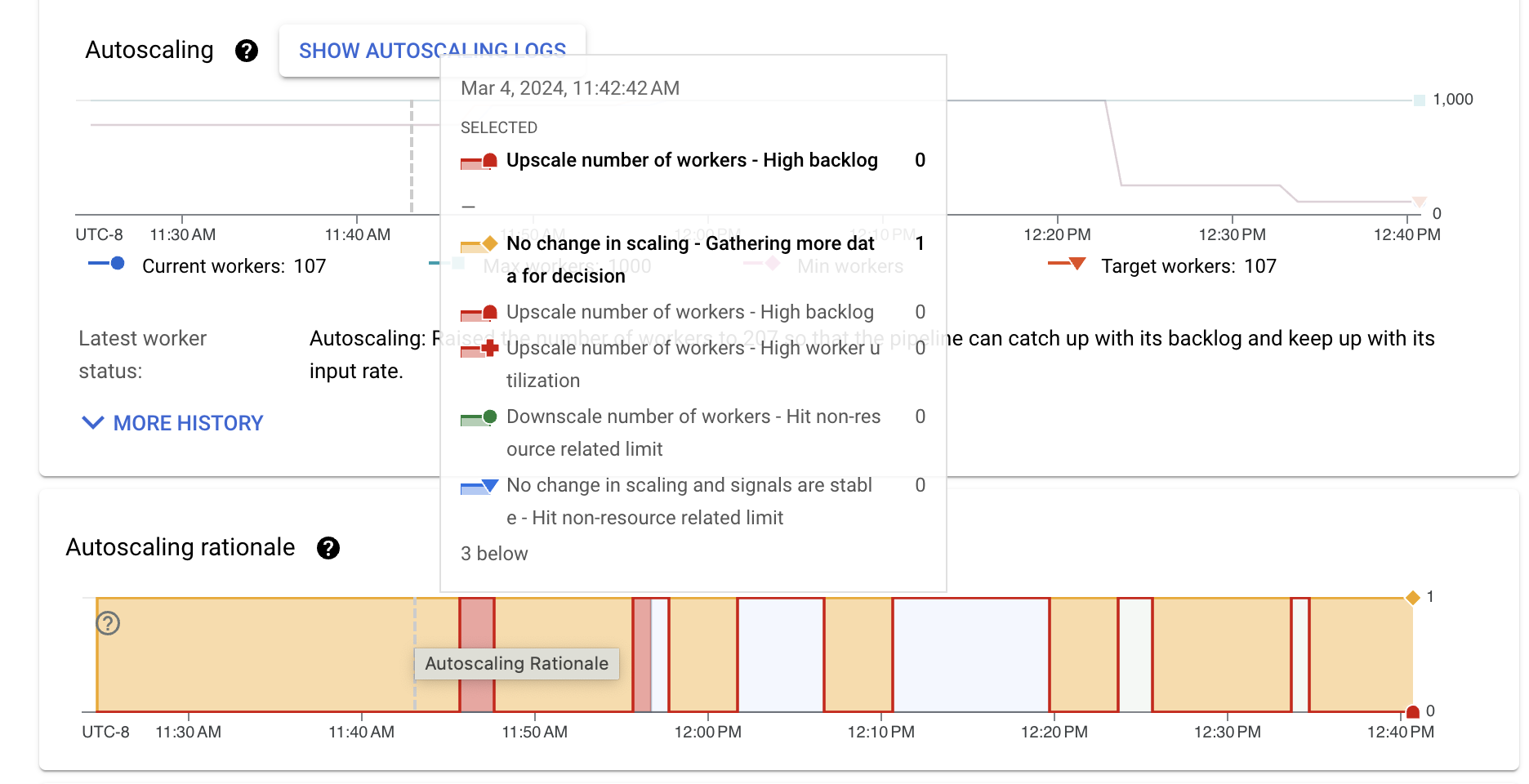
בטבלה הבאה מפורטות פעולות שינוי גודל וההסברים האפשריים לשינוי הגודל.
| פעולת שינוי גודל | הסבר | תיאור |
|---|---|---|
| אין שינוי בהתאמה | איסוף נתונים נוספים לצורך קבלת החלטה | למידרוג האוטומטי אין מספיק אותות כדי להגדיל או להקטין את הקבוצה. לדוגמה, הסטטוס של מאגר העובדים השתנה לאחרונה, או שיש תנודות במדדים של העומס או של ניצול המשאבים. |
| אין שינוי בהתאמה, אותות יציבים | הגעה למגבלה שלא קשורה למשאבים | ההתאמה של קנה המידה מוגבלת על ידי מגבלה כמו מקביליות של מפתח או מספר העובדים המינימלי והמקסימלי שהוגדר. |
| מלאי עבודה נמוך ושימוש גבוה בעובדים | ההתאמה האוטומטית לעומס של צינור העיבוד הגיעה לערך יציב בהתחשב בתנועה ובהגדרות הנוכחיות. אין צורך לשנות את ההיקף. | |
| הגדלת נפח הפעילות | High backlog | הגדלת היקף הפעילות כדי לצמצם את העומס. |
| שימוש גבוה בעובדים | הגדלת קנה המידה כדי להגיע לניצול יעד של יחידת העיבוד המרכזית (CPU). | |
| הגעה למגבלה שלא קשורה למשאבים | המספר המינימלי של העובדים עודכן, והמספר הנוכחי של העובדים נמוך מהמינימום שהוגדר. | |
| הקטנת קנה מידה | שיעור ניצול נמוך של העובדים | הקטנת מספר הליבות כדי להגיע ליעד ניצול המעבד. |
| הגעה למגבלה שלא קשורה למשאבים | המספר המקסימלי של העובדים עודכן, והמספר הנוכחי של העובדים גבוה מהמספר המקסימלי שהוגדר. |
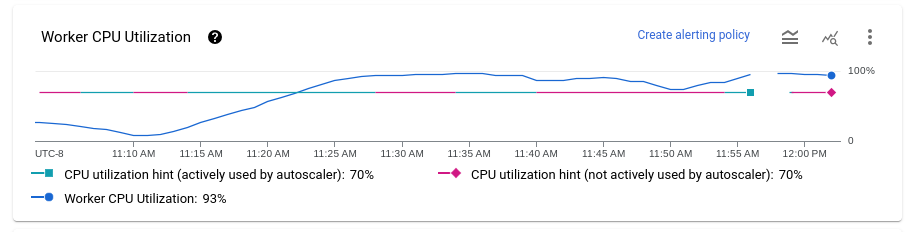
ניצול המעבד של העובד
ניצול המעבד הוא כמות המעבד שנעשה בה שימוש חלקי כמות המעבד שזמינה לעיבוד. בתרשים Mean CPU utilization מוצג ממוצע השימוש במעבד של כל העובדים לאורך זמן, ההצעה לשימוש בעובדים והשאלה אם Dataflow השתמש באופן פעיל בהצעה כיעד.
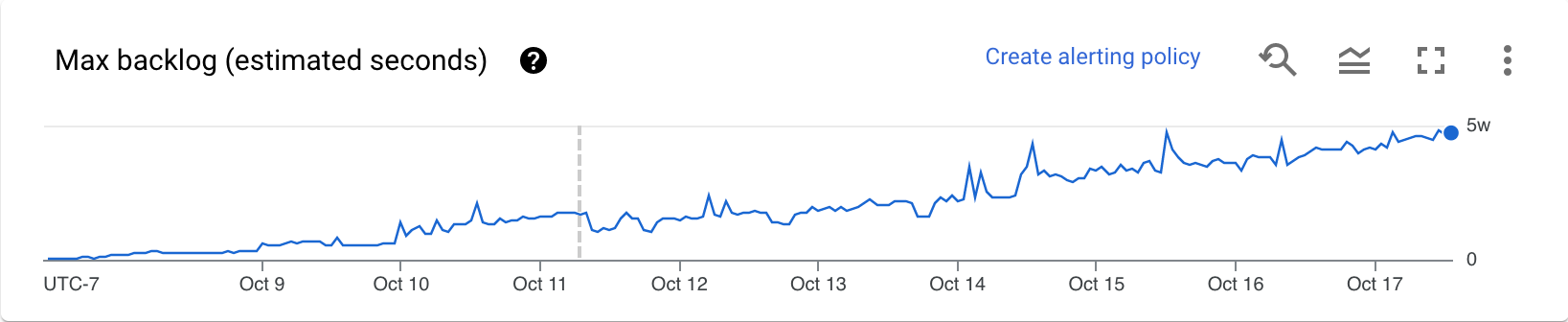
Backlog (מצבור משימות) (מנוע סטרימינג בלבד)
בתרשים Maximum backlog מוצג מידע על רכיבים שממתינים לעיבוד. בתרשים מוצגת הערכה של משך הזמן בשניות שיידרש כדי לעבד את הנתונים שממתינים כרגע בתור, אם לא יגיעו נתונים חדשים וקצב העברת הנתונים לא ישתנה. הזמן המשוער של הנתונים שממתינים לעיבוד מחושב על סמך קצב העברת הנתונים והנתונים שממתינים לעיבוד ממקור הקלט שעדיין צריך לעבד. המדד הזה משמש את התכונה התאמה אוטומטית לעומס של סטרימינג כדי לקבוע מתי להגדיל או להקטין את קצב הנתונים.
הנתונים בתרשים הזה זמינים רק לגבי משימות שנעשה בהן שימוש ב-Streaming Engine. אם משימת הסטרימינג לא משתמשת ב-Streaming Engine, התרשים ריק.
המלצות
ריכזנו כאן כמה התנהגויות שאולי תראו בצינור, והמלצות להתאמה אוטומטית לעומס:
הקטנה מוגזמת של התמונה. אם ערך היעד של ניצול המעבד מוגדר גבוה מדי, יכול להיות שתראו דפוס שבו Dataflow מצמצם את מספר העובדים, ה-backlog מתחיל לגדול ו-Dataflow מגדיל שוב את מספר העובדים כדי לפצות על כך, במקום להגיע למספר יציב של עובדים. כדי לפתור את הבעיה, אפשר לנסות להגדיר רמז לניצול נמוך יותר של העובדים. בודקים את ניצול המעבד בנקודה שבה מתחיל הגידול ב-backlog, ומגדירים את רמז הניצול לערך הזה.
ההגדלה הייתה איטית מדי. אם הגדלת הקיבולת איטית מדי, יכול להיות שהיא לא תעמוד בקצב של העליות הפתאומיות בנפח התנועה, וכתוצאה מכך יהיו תקופות של חביון מוגבר. כדאי לנסות להקטין את רמז הניצול של העובד, כדי ש-Dataflow יגדיל את הקיבולת שלו מהר יותר. בודקים את ניצול המעבד בנקודה שבה מתחיל הגידול בפיגור, ומגדירים את רמז הניצול לערך הזה. חשוב לעקוב אחרי זמן האחזור והעלות, כי ערך נמוך יותר של רמז יכול להגדיל את העלות הכוללת של צינור הנתונים, אם מוקצים יותר עובדים.
הגדלה מוגזמת של הרזולוציה. אם אתם מבחינים בהגדלת קנה מידה מוגזמת שגורמת לעלייה בעלויות, כדאי להגדיל את רמז הניצול של העובד. כדאי לעקוב אחרי זמן האחזור כדי לוודא שהוא נשאר בטווח המקובל לתרחיש שלכם.
מידע נוסף מפורט במאמר בנושא הגדרת רמז לניצול העובדים. כשעורכים ניסוי עם ערך חדש של רמז לניצול העובדים, צריך להמתין כמה דקות עד שהצינור יתייצב אחרי כל התאמה.
המאמרים הבאים
- התאמה של התאמה אוטומטית לעומס אופקית לצינורות עיבוד נתונים בסטרימינג
- פתרון בעיות בהתאמת קנה מידה אוטומטית ב-Dataflow