
Questa pagina spiega come eseguire una pipeline Apache Beam su Dataflow con le GPU. I job che utilizzano le GPU comportano addebiti come specificato nella pagina dei prezzi di Dataflow.
Per ulteriori informazioni sull'utilizzo delle GPU con Dataflow, consulta la pagina Supporto delle GPU in Dataflow. Per ulteriori informazioni sul flusso di lavoro dello sviluppatore per la creazione di pipeline utilizzando le GPU, consulta la pagina Informazioni sulle GPU con Dataflow.
Utilizzare i notebook Apache Beam
Se hai già una pipeline che vuoi eseguire con le GPU su Dataflow, puoi saltare questa sezione.
I notebook Apache Beam offrono un modo pratico per creare prototipi e sviluppare in modo iterativo la pipeline con le GPU senza configurare un ambiente di sviluppo. Per iniziare, leggi la guida Sviluppare con i notebook Apache Beam , avvia un'istanza dei notebook Apache Beam e segui il notebook di esempio Utilizzare le GPU con Apache Beam.
Eseguire il provisioning della quota di GPU
I dispositivi GPU sono soggetti alla disponibilità della quota del tuo Google Cloud progetto. Richiedi la quota di GPU nella regione di tua scelta.
Installare i driver della GPU
Per installare i driver NVIDIA sui worker Dataflow, aggiungi install-nvidia-driver all'opzione di servizio
worker_accelerator.
Quando specifichi l'opzione install-nvidia-driver,
Dataflow installa i driver NVIDIA sui worker Dataflow utilizzando
l'utilità cos-extensions
fornita da Container-Optimized OS. Se specifichi install-nvidia-driver, accetti il contratto di licenza NVIDIA.
Dataflow supporta l'aggiunta di una versione all'install-nvidia-driver
opzione come install-nvidia-driver:VERSION. Sono supportate le seguenti versioni:
- predefinito
- più recente
Se non viene fornita alcuna versione, è equivalente a install-nvidia-driver:default. Se viene fornita una versione non riconosciuta, l'installazione del driver GPU non riesce.
I file binari e le librerie forniti dal programma di installazione del driver NVIDIA vengono montati nel container che esegue il codice utente della pipeline in /usr/local/nvidia/.
La versione del driver GPU
per le versioni default e latest dipende dalla
versione di Container-Optimized OS utilizzata da Dataflow. Per trovare la
versione del driver GPU per un determinato job Dataflow, cerca GPU driver nei
log dei passaggi di Dataflow
del job.
Quando controlli i log di Dataflow dopo l'installazione del driver, potresti notare una riga simile alla seguente:
| NVIDIA-SMI 535.261.03 Driver Version: 535.261.03 CUDA Version: 12.2 |
In questo caso, "CUDA Version" è la versione CUDA del driver, diversa dalla versione CUDA del runtime installata nell' immagine container personalizzata o esistente. Se la versione del driver è maggiore o uguale alla versione del runtime, non è necessario eseguire ulteriori passaggi. Se è una versione precedente, dovrai seguire la documentazione sulla compatibilità di NVIDIA CUDA durante la creazione dell'immagine container.
Creare un'immagine container personalizzata
Per interagire con le GPU, potresti aver bisogno di software NVIDIA aggiuntivi, come le librerie con accelerazione GPU e il toolkit CUDA. Fornisci queste librerie nel container Docker che esegue il codice utente.
Per personalizzare l'immagine container, fornisci un'immagine che soddisfi il contratto dell'immagine container dell'SDK Apache Beam e che contenga le librerie GPU necessarie.
Per fornire un'immagine container personalizzata, utilizza
Dataflow Runner v2 e fornisci l'
immagine container utilizzando l'opzione della pipeline sdk_container_image.
Se utilizzi Apache Beam versione 2.29.0 o precedenti, utilizza l'opzione della pipeline worker_harness_container_image. Per ulteriori informazioni, consulta la pagina
Utilizzare container personalizzati.
Per creare un'immagine container personalizzata, utilizza uno dei seguenti due approcci:
- Utilizzare un'immagine esistente configurata per l'utilizzo della GPU
- Utilizzare un'immagine container Apache Beam
Utilizzare un'immagine esistente configurata per l'utilizzo della GPU
Puoi creare un'immagine Docker che soddisfi il contratto del container dell'SDK Apache Beam da un'immagine di base esistente preconfigurata per l'utilizzo della GPU. Ad esempio, le immagini Docker di TensorFlow, e le immagini container NVIDIA sono preconfigurate per l'utilizzo della GPU.
Un Dockerfile di esempio basato sull'immagine Docker di TensorFlow con Python 3.6 è simile all'esempio seguente:
ARG BASE=tensorflow/tensorflow:2.5.0-gpu
FROM $BASE
# Check that the chosen base image provides the expected version of Python interpreter.
ARG PY_VERSION=3.6
RUN [[ $PY_VERSION == `python -c 'import sys; print("%s.%s" % sys.version_info[0:2])'` ]] \
|| { echo "Could not find Python interpreter or Python version is different from ${PY_VERSION}"; exit 1; }
RUN pip install --upgrade pip \
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.6 SDK image.
COPY --from=apache/beam_python3.6_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# Some images have pip in a different location. If necessary, make a symlink.
# This line can be omitted in Beam 2.30.0 and later versions.
RUN [[ `which pip` == "/usr/local/bin/pip" ]] || ln -s `which pip` /usr/local/bin/pip
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Quando utilizzi
le immagini Docker di TensorFlow, utilizza
TensorFlow 2.5.0 o versioni successive. Le immagini Docker di TensorFlow
precedenti installano il pacchetto tensorflow-gpu anziché il tensorflow
pacchetto. La distinzione non è importante dopo la release di TensorFlow 2.1.0, ma diversi pacchetti downstream, come tfx, richiedono il pacchetto tensorflow.
Le dimensioni dei container di grandi dimensioni rallentano il tempo di avvio dei worker. Questa modifica delle prestazioni potrebbe verificarsi quando utilizzi container come Deep Learning Containers.
Installare una versione specifica di Python
Se hai requisiti rigorosi per la versione di Python, puoi creare l'immagine da un'immagine di base NVIDIA che contenga le librerie GPU necessarie. Poi, installa l'interprete Python.
L'esempio seguente mostra come selezionare un'immagine NVIDIA che non include l'interprete Python dal catalogo delle immagini container CUDA. Modifica l'esempio per installare la versione necessaria di Python 3 e pip. L'esempio utilizza TensorFlow. Pertanto, quando scegli un'immagine, le versioni CUDA e cuDNN in l'immagine di base soddisfano i requisiti per la versione di TensorFlow.
Un Dockerfile di esempio è simile al seguente:
# Select an NVIDIA base image with needed GPU stack from https://ngc.nvidia.com/catalog/containers/nvidia:cuda
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
RUN \
# Add Deadsnakes repository that has a variety of Python packages for Ubuntu.
# See: https://launchpad.net/~deadsnakes/+archive/ubuntu/ppa
apt-key adv --keyserver keyserver.ubuntu.com --recv-keys F23C5A6CF475977595C89F51BA6932366A755776 \
&& echo "deb http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& echo "deb-src http://ppa.launchpad.net/deadsnakes/ppa/ubuntu focal main" >> /etc/apt/sources.list.d/custom.list \
&& apt-get update \
&& apt-get install -y curl \
python3.8 \
# With python3.8 package, distutils need to be installed separately.
python3-distutils \
&& rm -rf /var/lib/apt/lists/* \
&& update-alternatives --install /usr/bin/python python /usr/bin/python3.8 10 \
&& curl https://bootstrap.pypa.io/get-pip.py | python \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check
# Copy the Apache Beam worker dependencies from the Beam Python 3.8 SDK image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
In alcune distribuzioni del sistema operativo, potrebbe essere difficile installare versioni specifiche di Python utilizzando il gestore di pacchetti del sistema operativo. In questo caso, installa l'interprete Python con strumenti come Miniconda o pyenv.
Un Dockerfile di esempio è simile al seguente:
FROM nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
# The Python version of the Dockerfile must match the Python version you use
# to launch the Dataflow job.
ARG PYTHON_VERSION=3.8
# Update PATH so we find our new Conda and Python installations.
ENV PATH=/opt/python/bin:/opt/conda/bin:$PATH
RUN apt-get update \
&& apt-get install -y wget \
&& rm -rf /var/lib/apt/lists/* \
# The NVIDIA image doesn't come with Python pre-installed.
# We use Miniconda to install the Python version of our choice.
&& wget -q https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh \
&& bash Miniconda3-latest-Linux-x86_64.sh -b -p /opt/conda \
&& rm Miniconda3-latest-Linux-x86_64.sh \
# Create a new Python environment with needed version, and install pip.
&& conda create -y -p /opt/python python=$PYTHON_VERSION pip \
# Remove unused Conda packages, install necessary Python packages via pip
# to avoid mixing packages from pip and Conda.
&& conda clean -y --all --force-pkgs-dirs \
&& pip install --upgrade pip \
# Install Apache Beam and Python packages that will interact with GPUs.
&& pip install --no-cache-dir apache-beam[gcp]==2.29.0 tensorflow==2.4.0 \
# Verify that there are no conflicting dependencies.
&& pip check \
# Apache Beam worker expects pip at /usr/local/bin/pip by default.
# You can omit this line when using Beam 2.30.0 and later versions.
&& ln -s $(which pip) /usr/local/bin/pip
# Copy the Apache Beam worker dependencies from the Apache Beam SDK for Python 3.8 image.
COPY --from=apache/beam_python3.8_sdk:2.29.0 /opt/apache/beam /opt/apache/beam
# Set the entrypoint to Apache Beam SDK worker launcher.
ENTRYPOINT [ "/opt/apache/beam/boot" ]
Utilizzare un'immagine container Apache Beam
Puoi configurare un'immagine container per l'utilizzo della GPU senza utilizzare immagini preconfigurate. Questo approccio è consigliato solo quando le immagini preconfigurate non funzionano per te. Per configurare la tua immagine container, devi selezionare le librerie compatibili e configurare il relativo ambiente di esecuzione.
Un Dockerfile di esempio è simile al seguente:
FROM apache/beam_python3.7_sdk:2.24.0
ENV INSTALLER_DIR="/tmp/installer_dir"
# The base image has TensorFlow 2.2.0, which requires CUDA 10.1 and cuDNN 7.6.
# You can download cuDNN from NVIDIA website
# https://developer.nvidia.com/cudnn
COPY cudnn-10.1-linux-x64-v7.6.0.64.tgz $INSTALLER_DIR/cudnn.tgz
RUN \
# Download CUDA toolkit.
wget -q -O $INSTALLER_DIR/cuda.run https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run && \
# Install CUDA toolkit. Print logs upon failure.
sh $INSTALLER_DIR/cuda.run --toolkit --silent || (egrep '^\[ERROR\]' /var/log/cuda-installer.log && exit 1) && \
# Install cuDNN.
mkdir $INSTALLER_DIR/cudnn && \
tar xvfz $INSTALLER_DIR/cudnn.tgz -C $INSTALLER_DIR/cudnn && \
cp $INSTALLER_DIR/cudnn/cuda/include/cudnn*.h /usr/local/cuda/include && \
cp $INSTALLER_DIR/cudnn/cuda/lib64/libcudnn* /usr/local/cuda/lib64 && \
chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn* && \
rm -rf $INSTALLER_DIR
# A volume with GPU drivers will be mounted at runtime at /usr/local/nvidia.
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/nvidia/lib64:/usr/local/cuda/lib64
Le librerie dei driver in /usr/local/nvidia/lib64 devono essere rilevabili nel container come librerie condivise. Per rendere rilevabili le librerie dei driver, configura la variabile di ambiente LD_LIBRARY_PATH.
Se utilizzi TensorFlow, devi scegliere una combinazione compatibile di versioni del toolkit CUDA e di cuDNN. Per ulteriori informazioni, consulta la pagina Requisiti software e Configurazioni di build testate.
Selezionare il tipo e il numero di GPU per i worker Dataflow
Per configurare il tipo e il numero di GPU da collegare ai worker Dataflow, utilizza l'
worker_accelerator opzione di servizio.
Seleziona il tipo e il numero di GPU in base al tuo caso d'uso e a come prevedi di utilizzare le GPU nella pipeline.
Per un elenco dei tipi di GPU supportati da Dataflow, consulta la pagina Supporto delle GPU in Dataflow.
Eseguire il job con le GPU
Le considerazioni per l'esecuzione di un job Dataflow con le GPU includono quanto segue:
Poiché i container GPU sono in genere di grandi dimensioni, per evitare di esaurire lo spazio su disco:
- Aumenta la dimensione predefinita del disco di avvio a 50 gigabyte o più.
Considera il numero di processi che utilizzano contemporaneamente la stessa GPU su una VM worker. Poi, decidi se vuoi limitare la GPU a un singolo processo o consentire a più processi di utilizzare la GPU.
- Se un processo dell'SDK Apache Beam può utilizzare la maggior parte della memoria GPU disponibile, ad esempio caricando un modello di grandi dimensioni su una GPU, potresti voler configurare i worker in modo che utilizzino un singolo processo impostando l'opzione della pipeline
--experiments=no_use_multiple_sdk_containers. In alternativa, utilizza i worker con una vCPU utilizzando un tipo di macchina personalizzato, ad esempion1-custom-1-NUMBER_OF_MBon1-custom-1-NUMBER_OF_MB-ext, per la memoria estesa. Per ulteriori informazioni, consulta la pagina Utilizzare un tipo di macchina con più memoria per vCPU. - Se la GPU è condivisa da più processi, abilita l'elaborazione simultanea su una GPU condivisa utilizzando il NVIDIA Multi-Processing Service (MPS).
Per informazioni di base, consulta la pagina GPU e parallelismo dei worker.
- Se un processo dell'SDK Apache Beam può utilizzare la maggior parte della memoria GPU disponibile, ad esempio caricando un modello di grandi dimensioni su una GPU, potresti voler configurare i worker in modo che utilizzino un singolo processo impostando l'opzione della pipeline
Per eseguire un job Dataflow con le GPU, utilizza il seguente comando.
Per utilizzare la funzionalità di dimensionamento corretto, anziché utilizzare l'opzione di servizio
worker_accelerator,
utilizza il suggerimento per la risorsa
accelerator.
Python
python PIPELINE \
--runner "DataflowRunner" \
--project "PROJECT" \
--temp_location "gs://BUCKET/tmp" \
--region "REGION" \
--worker_harness_container_image "IMAGE" \
--disk_size_gb "DISK_SIZE_GB" \
--dataflow_service_options "worker_accelerator=type:GPU_TYPE;count:GPU_COUNT;install-nvidia-driver" \
--experiments "use_runner_v2"
Sostituisci quanto segue:
- PIPELINE: il file del codice sorgente della pipeline
- PROJECT: il Google Cloud nome del progetto
- BUCKET: il bucket Cloud Storage
- REGION: una regione Dataflow, ad esempio
us-central1. Seleziona una `REGION` che contenga zone che supportinoGPU_TYPE. Dataflow assegna automaticamente i worker a una zona con GPU in questa regione. - IMAGE: il percorso di Artifact Registry per l'immagine Docker
- DISK_SIZE_GB: la dimensione del disco di avvio per ogni VM worker, ad esempio
50 - GPU_TYPE: un tipo di GPU disponibile
, ad esempio
nvidia-tesla-t4. - GPU_COUNT: il numero di GPU da collegare a ogni VM worker, ad esempio
1
Verificare il job Dataflow
Per verificare che il job utilizzi VM worker con GPU:
- Verifica che i worker Dataflow per il job siano stati avviati.
- Mentre un job è in esecuzione, trova una VM worker associata al job.
- Nel prompt Cerca prodotti e risorse, incolla l'ID job.
- Seleziona l'istanza VM di Compute Engine associata al job.
Puoi anche trovare un elenco di tutte le istanze in esecuzione nella console di Compute Engine.
Nella Google Cloud console, vai alla pagina Istanze VM.
Fai clic su Dettagli istanza VM.
Verifica che la pagina dei dettagli contenga una sezione GPU e che le GPU siano collegate.
Se il job non è stato avviato con le GPU, verifica che l'opzione di servizio worker_accelerator sia configurata correttamente e visibile nell'interfaccia di monitoraggio di Dataflow in dataflow_service_options. L'ordine dei token nei metadati dell'acceleratore è importante.
Ad esempio, un'opzione della pipeline dataflow_service_options nell'interfaccia di monitoraggio di Dataflow potrebbe essere simile alla seguente:
['worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver', ...]
Visualizzare l'utilizzo della GPU
Per visualizzare l'utilizzo della GPU nelle VM worker:
Nella Google Cloud console, vai a Monitoraggio o utilizza il seguente pulsante:
Nel riquadro di navigazione di Monitoring, fai clic su Esplora metriche.
Per Tipo di risorsa, specifica
Dataflow Job. Per la metrica, specificaGPU utilizationoGPU memory utilization, a seconda della metrica che vuoi monitorare.
Per ulteriori informazioni, consulta la pagina Esplora metriche.
Abilitare NVIDIA Multi-Processing Service
Nelle pipeline Python eseguite su worker con più di una vCPU, puoi migliorare la concorrenza per le operazioni GPU abilitando NVIDIA Multi-Process Service (MPS). Per ulteriori informazioni e passaggi per utilizzare MPS, consulta la pagina Migliorare le prestazioni su una GPU condivisa utilizzando NVIDIA MPS.
(Facoltativo) Configurare un modello di provisioning
Puoi migliorare la possibilità di accedere alle risorse GPU configurando un modello di provisioning per la pipeline.
Dataflow supporta i seguenti modelli di provisioning: standard e con avvio flessibile.
Provisioning standard
Il provisioning standard è il modello di provisioning predefinito per tutti i job Dataflow con GPU. Le istanze che utilizzano risorse di accelerazione vengono create immediatamente in base alla disponibilità delle risorse.
Non devi configurare nulla per utilizzare il modello di provisioning standard.
Se le GPU non sono immediatamente disponibili nella zona o nella regione in cui esegui il job Dataflow, il job potrebbe non essere avviato. Per ulteriori informazioni, consulta la pagina Il job non viene avviato immediatamente.
Provisioning con avvio flessibile
Con il modello di provisioning con avvio flessibile, le istanze e le risorse di accelerazione vengono pianificate per il provisioning e soddisfatte in base alla disponibilità delle risorse. Puoi utilizzare il modello di provisioning con avvio flessibile per aumentare le tue possibilità di ottenere le GPU.
Per utilizzare il modello di provisioning con avvio flessibile, aggiungi provisioning_model:FLEX_START all'
worker_accelerator opzione di servizio. Ad esempio:
worker_accelerator=type:nvidia-tesla-t4;count:1;install-nvidia-driver:latest;provisioning_model:FLEX_START
I job con l'avvio flessibile abilitato vengono inviati per l'esecuzione, ma vengono eseguiti solo quando le risorse richieste diventano disponibili. Per verificare che il provisioning con avvio flessibile sia stato abilitato, cerca la seguente voce di log nel log dei messaggi del job job-message:
FLEX_START è abilitato per il job JOB_ID
Per determinare se il job ha iniziato l'esecuzione, visualizza il grafico di scalabilità automatica nella pagina delle metriche del job:
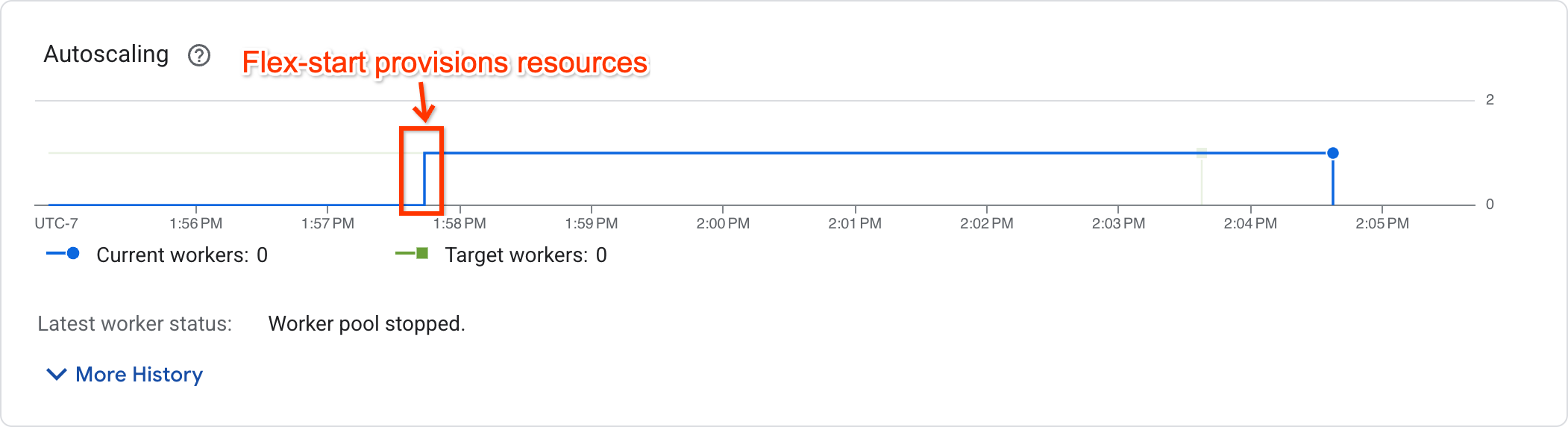
I job che hanno iniziato l'esecuzione mostreranno un numero di worker diverso da zero, mentre i job in attesa di risorse avranno un numero di worker pari a zero.
Supporto e limitazioni
- L'avvio flessibile è supportato solo nelle pipeline batch. Le pipeline di streaming non sono supportate.
- Le VM worker di cui è stato eseguito il provisioning utilizzando il modello di provisioning con avvio flessibile hanno un runtime massimo di sette giorni. Trascorso questo periodo, le VM worker con acceleratori vengono prerilasciate. Dataflow tenterà di eseguire nuovamente il provisioning delle risorse. Se non è possibile eseguire nuovamente il provisioning delle risorse, la pipeline non riuscirà.
- L'avvio flessibile tenterà di eseguire il provisioning delle risorse per un massimo di 1 ora dopo l'invio del job. Se non è in grado di eseguire il provisioning delle risorse dopo 1 ora, il job non riuscirà.
- L'avvio flessibile utilizza la quota prerilasciabile. Se il progetto non dispone di quota prerilasciabile, viene utilizzata la quota standard. Per ulteriori informazioni, consulta la pagina Quote prerilasciabili.
- Se non viene fornita una configurazione della zona worker, Dataflow sceglierà una singola zona in cui creare tutte le risorse in base al supporto hardware, alla disponibilità corrente delle risorse e delle quote e alle prenotazioni corrispondenti. Questa zona potrebbe essere diversa dalla zona in cui si trovano le risorse di servizio per il job.
- La scalabilità automatica orizzontale non è supportata. Per utilizzare più di un worker, imposta l'opzione della pipeline
--num_workers. - Le TPU non sono supportate.
- Il dimensionamento corretto non è supportato.
Risoluzione dei problemi relativi all'avvio flessibile
Se il job non riesce 1 ora dopo l'invio con l'errore:
The Dataflow job appears to be stuck because no worker activity has been seen in the last 1h.
Vai alla pagina Quote nella Google Cloud console per assicurarti che il tuo progetto disponga di una quota PREEMPTIBLE_GPU_TYPE_GPUS sufficiente nella regione configurata del job.
Se nel progetto era presente una quota sufficiente, l'avvio flessibile non è riuscito a eseguire il provisioning delle risorse in 1 ora. Valuta la possibilità di avviare la pipeline in un'altra zona o con un altro tipo di acceleratore.
Utilizzare le GPU con Dataflow Prime
Dataflow Prime ti consente di
richiedere gli acceleratori per un passaggio specifico della pipeline. Per utilizzare le GPU con Dataflow Prime, non utilizzare l'opzione della pipeline --dataflow-service_options=worker_accelerator. Richiedi invece le GPU con il suggerimento per la risorsa accelerator.
Per ulteriori informazioni, consulta la pagina
Utilizzare i suggerimenti per le risorse.
Risolvere i problemi relativi al job Dataflow
Se riscontri problemi durante l'esecuzione del job Dataflow con le GPU, consulta la pagina Risolvere i problemi relativi al job Dataflow GPU.
Passaggi successivi
- Scopri di più sul supporto delle GPU in Dataflow.
- Esegui la pipeline di inferenza di machine learning con il tipo di GPU NVIDIA L4.
- Consulta la pagina Elaborazione di immagini satellitari Landsat con le GPU.