En esta página, se abarcan las métricas de GPU compatibles con Dataflow. Puedes usar estas métricas para supervisar el estado y el uso de la GPU. La mayoría de las métricas son compatibles con todos los trabajos de Dataflow, pero algunas requieren configuración adicional para muchos modelos de GPU.
Requisitos previos
Dataflow solo recopila las métricas de GPU de los trabajos que solicitaron explícitamente GPU. Para obtener más información, consulta Compatibilidad con GPU.
Descripción general
Si bien Dataflow informa muchas métricas de GPU, las principales son la memoria total y la utilizada, que son equivalentes a las métricas de RAM, y la actividad y la ocupación del Streaming Multiprocessor (SM), que son los equivalentes más cercanos a las métricas de CPU de Dataflow. Se abarcan más métricas en Métricas comunes y Métricas de GPM.
De forma predeterminada, se informa la memoria total y utilizada de cada dispositivo de GPU en el trabajo. En la interfaz de supervisión de Dataflow, aparecen en "Uso básico de GPU". Estas métricas no son las mismas que "Porcentaje de acceso a la memoria", que también se encuentra en las métricas básicas de GPU, pero informa el porcentaje de tiempo en que se accedió a la memoria del dispositivo de GPU.
La actividad y la ocupación del SM son métricas de GPM. Estas métricas no son compatibles con los dispositivos P4 y P100, y son compatibles de forma predeterminada con los dispositivos H100 y versiones posteriores. Para todos los demás dispositivos, como los dispositivos T4 y L4, es necesaria una configuración adicional. Para conocer los pasos para habilitarlos, consulta Recopilación de GPM. Si se recopilan en el trabajo, estas métricas se encuentran en "Uso de GPM de GPU" en la interfaz de supervisión de Dataflow.
Conceptos básicos de las métricas de GPU de Dataflow
Los trabajadores de Dataflow envían todas las métricas de GPU a Cloud Monitoring. Las métricas por dispositivo se pueden encontrar en dataflow.googleapis.com/worker/accelerator/gpu. Todas estas métricas se agrupan en categorías generales, como el uso o la temperatura, y todas tienen las siguientes etiquetas:
- device_uuid: Identifica de forma única el dispositivo de GPU, independientemente del trabajador o la canalización.
- device_number: Es el número asignado al dispositivo en el trabajador en el rango de [0, N), donde N es la cantidad de dispositivos de GPU en el trabajador.
- device_model: Es el modelo de la GPU, como "Tesla T4".
device_uuid y device_model son independientes del trabajador y siempre son los mismos para el mismo dispositivo físico. device_number está vinculado a cómo se identifica en ese trabajador.
Métricas comunes de GPU para Dataflow
Todos los trabajos de Dataflow con GPU informan métricas comunes. En Monitoring, todos usan el siguiente formato:
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
En la siguiente tabla, se muestra cada métrica y su categoría, nombre, unidad y propósito.
| Métrica | Categoría | Nombre | Unidad | Descripción |
|---|---|---|---|---|
| Porcentaje de ejecución del kernel | uso | device_kernel_runtime | Porcentaje | Es el porcentaje de tiempo en que se ejecutó al menos un kernel en la GPU. Esto solo muestra que se usó la GPU, no si sus recursos de procesamiento se usan de manera eficiente. |
| Porcentaje de acceso a la memoria | uso | device_memory_access | Porcentaje | Es el porcentaje de tiempo en que se leyó o escribió en la memoria del dispositivo. Esto solo muestra que se accedió a la memoria, no el porcentaje de memoria en uso. |
| Límite de memoria | memoria | device_limit | MiB | Es la cantidad de memoria disponible en la GPU. |
| Uso de la memoria | memoria | device_usage | MiB | Es la cantidad de memoria en uso por la GPU. Esto incluye la memoria que usa el trabajo de Dataflow y la memoria reservada para el firmware, por lo que se espera un uso incluso si aún no se transfirió memoria a la GPU. |
| Errores de ECC volátiles corregibles | memory/ecc/volatile | device_correctable_total | Recuento | Es la cantidad de errores de ECC corregibles (de un solo bit) desde la última recarga del controlador. En Dataflow, la recarga del controlador solo ocurre en el inicio del trabajador, por lo que esto equivale a errores durante la vida útil del trabajador. |
| Errores de ECC volátiles no corregibles | memory/ecc/volatile | device_uncorrectable_total | Recuento | Es la cantidad de errores de ECC no corregibles (de doble bit) desde la última recarga del controlador. En Dataflow, la recarga del controlador solo ocurre en el inicio del trabajador, por lo que esto equivale a errores durante la vida útil del trabajador. |
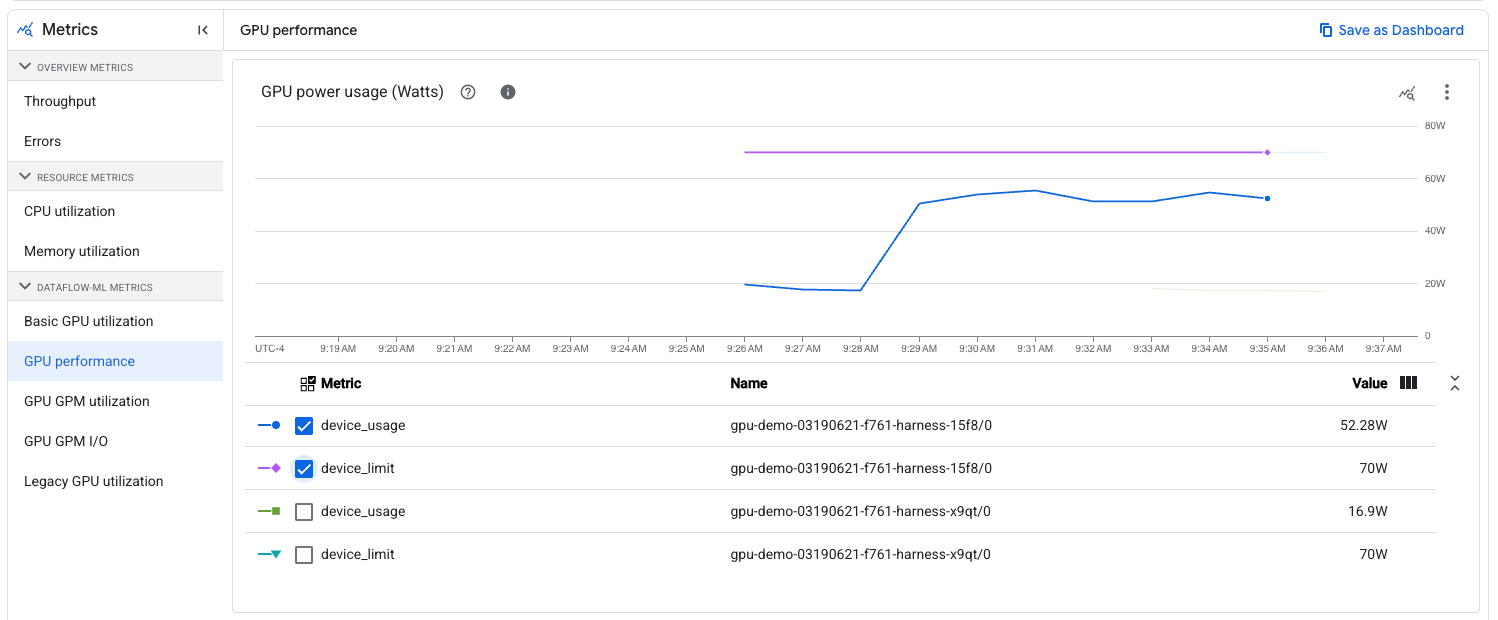
| Límite de potencia | potencia | device_limit | Watts | Es la cantidad máxima de energía que el dispositivo está configurado para usar. Dataflow no cambia esto del valor predeterminado. |
| Uso de energía | potencia | device_usage | Watts | Es la cantidad de energía en uso por el dispositivo. |
| Temperatura actual | temperatura | device_current | Celsius | Es la temperatura actual de la GPU. |
| Temperatura máx. de funcionamiento | temperatura | device_max_op | Celsius | Es la temperatura que debe mantener la GPU. Si la temperatura actual supera este valor, los controladores de GPU intentarán enfriar la GPU hasta que esté por debajo de esta temperatura. Dataflow no controla esto. |
| Temperatura de desaceleración | temperatura | device_slowdown | Celsius | Es la temperatura a la que la GPU comenzará a limitar el uso. Si la temperatura actual supera este valor, debes esperar una degradación del rendimiento hasta que se enfríe. Dataflow no controla esto. |
| Temperatura de apagado | temperatura | device_shutdown | Celsius | Es la temperatura a la que se apagará la GPU. Si la temperatura actual supera este valor, el dispositivo dejará de estar disponible. Dataflow no controla esta temperatura ni intenta recuperar las GPU que se apagaron debido a una temperatura excesivamente alta. |
| Reloj de SM actual | reloj | device_sm_current | MHz | Es la velocidad actual del reloj de SM. Si la temperatura supera el umbral de desaceleración, es posible que disminuya como parte de la limitación relacionada con el enfriamiento. |
| Reloj de SM máximo | reloj | device_sm_max | MHz | Es la velocidad máxima del reloj de SM. |
| Reloj de memoria actual | reloj | device_memory_current | MHz | Es la velocidad actual del reloj de memoria. Si la temperatura supera el umbral de desaceleración, es posible que disminuya como parte de la limitación relacionada con el enfriamiento. |
| Reloj de memoria máximo | reloj | device_memory_max | MHz | Es la velocidad máxima del reloj de memoria. |
Métricas de GPM para Dataflow
Dataflow ofrece cierta compatibilidad con las métricas de GPM. El nivel de compatibilidad depende del modelo de GPU y de la configuración del acelerador. De forma predeterminada, la mayoría de los trabajos de Dataflow con GPU requerirán alguna configuración adicional.
Las métricas de GPM siguen los mismos conceptos básicos que las métricas comunes.
Métricas admitidas
Al igual que las métricas comunes, las rutas de métricas de GPM tienen el siguiente formato:
dataflow.googleapis.com/worker/accelerator/gpu/CATEGORY/NAME
Algunas de estas métricas se encuentran en la misma categoría que algunas métricas comunes.
| Métrica | Categoría | Nombre | Unidad | Descripción |
|---|---|---|---|---|
| Actividad de SM | uso | device_sm_activity | Porcentaje | Es el porcentaje de tiempo que un warp estuvo activo en el SM, promediado en todos los SM del dispositivo. Es similar al porcentaje de ejecución del kernel, pero ofrece una imagen más detallada que muestra mejor si los recursos de la GPU se usan de manera eficiente. NVIDIA define el uso eficaz como 80% o más, y el uso ineficaz como 50% o menos. |
| Ocupación de SM | uso | device_sm_occupancy | Porcentaje | Es el porcentaje de warps activos en el dispositivo en relación con el máximo. Los trabajos con memoria limitada deben tener una ocupación más alta que los trabajos con procesamiento limitado, y la métrica de porcentaje de acceso a la memoria puede proporcionar información sobre esto. Puedes encontrar más detalles en la documentación de NVIDIA sobre la ocupación alcanzada. |
| Actividad de canalización de Tensor | uso | device_tensor_pipe_activity | Porcentaje | Es el porcentaje de tiempo que se usó la canalización de Tensor Core. Los valores más altos indican un mayor uso de los Tensor Cores de la GPU, que son importantes para las operaciones de matriz. |
| Actividad de canalización de FP64 | uso | device_fp64_pipe_activity | Porcentaje | Es el porcentaje de tiempo que se usó la canalización de FP64 Core. Los valores más altos indican un mayor uso de los FP64 Cores de la GPU, que controlan las operaciones escalares de valores de punto flotante de 64 bits. |
| Actividad de canalización de FP32 | uso | device_fp32_pipe_activity | Porcentaje | Es el porcentaje de tiempo que se usó la canalización de FP32 Core. Los valores más altos indican un mayor uso de los FP32 Cores de la GPU, que controlan las operaciones escalares de valores de punto flotante de 32 bits. |
| Actividad de canalización de FP16 | uso | device_fp16_pipe_activity | Porcentaje | Es el porcentaje de tiempo que se usó la canalización de FP16. A diferencia de FP64 y FP32, que están asociados con los núcleos CUDA de 64 y 32 bits, respectivamente, FP16 está asociado con el aprovechamiento de las capacidades de media precisión de los Tensor Cores. |
| Lectura de PCIe | pcie | device_read | MiB/s | Es la tasa de datos que lee la GPU de la VM host a través de PCIe. |
| Transferencia de PCIe | pcie | device_transfer | MiB/s | Es la tasa de transferencia de datos de la GPU a la VM host a través de PCIe. |
| Lectura de NVLink | nvlink | device_read | MiB/s | Es la tasa de datos que lee la GPU a través de NVLink. Dado que NVLink solo cubre la comunicación de GPU a GPU, esto es irrelevante si cada trabajador solo tiene una GPU. |
| Transferencia de NVLink | nvlink | device_transfer | MiB/s | Es la tasa de transferencia de datos de la GPU a través de NVLink. Dado que NVLink solo cubre la comunicación de GPU a GPU, esto es irrelevante si cada trabajador solo tiene una GPU. |
Recopilación de métricas de GPM
De forma predeterminada, cualquier trabajo de Dataflow con GPU que use la arquitectura Hopper o versiones posteriores (p.ej., H100, H100 Mega) recopila métricas de GPM, por lo que no se necesita configuración adicional. Sin embargo, los trabajos que usan la arquitectura Pascal o versiones anteriores (como P4 y P100) no admiten estas métricas.
Para todos los demás modelos, la recopilación de estas métricas requiere agregar install-gke-dcgm-exporter a la configuración del acelerador del trabajador. Por ejemplo:
--experiment="worker_accelerator=type:TYPE;count:COUNT;install-nvidia-driver;install-gke-dcgm-exporter"
Esta marca instala un equivalente administrado por GKE al DCGM-exporter de NVIDIA. Los siguientes tipos admiten esta opción:
- nvidia-l4
- nvidia-tesla-a100
- nvidia-a100-80gb
- nvidia-tesla-t4
- nvidia-tesla-v100
Si se proporciona otro tipo, el servicio de Dataflow muestra un error en la creación del trabajo. Esta verificación te ayuda a evitar ejecutar el contenedor en trabajos en los que no ayuda con la recopilación de métricas.
Métricas heredadas
En Monitoring, es posible que veas dos métricas llamadas dataflow.googleapis.com/job/gpu_utilization y dataflow.googleapis.com/job/gpu_memory_utilization. Estas métricas son similares
a porcentaje de ejecución del kernel y porcentaje de acceso a la memoria
respectivamente, pero los trabajadores las informan promediando las GPU en el trabajador. Te recomendamos que uses los equivalentes por dispositivo, en especial si los trabajadores están configurados para tener más de una GPU.
IU de Dataflow
Si el trabajo de Dataflow tiene GPU conectadas a sus trabajadores, las métricas deberían aparecer en la pestaña "Métricas del trabajo" en la página del trabajo, en la categoría "Dataflow ML". Esta categoría no aparece en los trabajos sin GPU y tarda unos segundos en cargarse, ya que primero verifica que las métricas sean relevantes para el trabajo.
Las siguientes subcategorías aparecen en "Dataflow ML":
| Subcategoría | Métricas | Condiciones |
|---|---|---|
| Uso básico de GPU | Porcentaje de ejecución del kernel Porcentaje de acceso a la memoria Memoria total/utilizada |
Todos los trabajos de GPU |
| Rendimiento de GPU | Consumo/límite de energía Lectura/límites de temperatura Reloj de SM actual/máximo Reloj de memoria actual/máximo Errores de ECC volátiles corregibles/no corregibles |
Todos los trabajos de GPU |
| Uso de GPM de GPU | Actividad de SM Ocupación de SM Actividad de canalización de CUDA/Tensor |
Métricas de GPM habilitadas |
| E/S de GPM de GPU | Lectura/transferencia de PCIe Lectura/transferencia de NVLink |
Métricas de GPM habilitadas |
| Uso de GPU heredada | Métricas heredadas | Todos los trabajos de GPU |
Cuando veas métricas no heredadas, puedes filtrar los gráficos a un nombre de trabajador y un número de dispositivo de GPU específicos. El nombre del trabajador es el mismo que el de la VM si se ve en Compute Engine. El número de dispositivo de GPU es el mismo que el de las etiquetas de métricas . Puedes usar este filtrado para verificar las métricas en un dispositivo de GPU específico, como ver qué tan cerca está su uso de energía en relación con su límite: