
PCollections לא מוגבלים, או אוספים לא מוגבלים, מייצגים נתונים בצינורות עיבוד נתונים בסטרימינג. אוסף לא מוגבל מכיל נתונים ממקור נתונים שמתעדכן כל הזמן, כמו Pub/Sub.
אי אפשר להשתמש רק במפתח כדי לקבץ רכיבים באוסף לא מוגבל. יכול להיות שיש אינסוף רכיבים למפתח נתון מסוים בנתונים שמוזרמים, כי מקור הנתונים מוסיף כל הזמן רכיבים חדשים. אפשר להשתמש בחלונות, בסימני מים ובטריגרים כדי לצבור רכיבים באוספים לא מוגבלים.
הקונספט של חלונות חל גם על PCollections מוגבלים שמייצגים נתונים בצינורות עיבוד נתונים באצווה. מידע על חלוקה לחלונות בצינורות של עיבוד באצווה זמין במאמר בנושא חלוקה לחלונות עם PCollections מוגבלים במסמכי Apache Beam.
אם צינור Dataflow כולל מקור נתונים מוגבל, כלומר מקור שלא מכיל נתונים שמתעדכנים באופן רציף, והצינור מועבר למצב סטרימינג באמצעות הדגל --streaming, כשהמקור המוגבל נצרך במלואו, הצינור מפסיק לפעול.
שימוש במצב סטרימינג
כדי להריץ צינור עיבוד נתונים במצב סטרימינג, מגדירים את הדגל --streaming בשורת הפקודה כשמריצים את צינור עיבוד הנתונים. אפשר גם להגדיר את מצב הסטרימינג באופן פרוגרמטי כשיוצרים את צינור עיבוד הנתונים.
אין תמיכה במקורות של עיבוד באצווה במצב סטרימינג.
כשמעדכנים את צינור הנתונים עם מאגר גדול יותר של עובדים, יכול להיות שעבודת הסטרימינג לא תוגדל כמו שציפיתם. במשימות של סטרימינג שלא נעשה בהן שימוש ב-Streaming Engine, אי אפשר להגדיל את מספר העובדים ואת משאבי הדיסק הקשיח הקבוע שהוקצו בתחילת המשימה המקורית. כשמעדכנים משימת Dataflow ומציינים מספר גדול יותר של מכונות worker במשימה החדשה, אפשר לציין רק מספר של מכונות worker ששווה למספר המקסימלי של מכונות worker שצוין במשימה המקורית.
כדי לציין את המספר המקסימלי של עובדים, משתמשים בדגלים הבאים:
Java
--maxNumWorkers
Python
--max_num_workers
המשך
--max_num_workers
חלונות ופונקציות של חלונות
פונקציות חלון מחלקות אוספים לא מוגבלים לרכיבים לוגיים, או חלונות. פונקציות חלון מקבצות אוספים לא מוגבלים לפי חותמות הזמן של האלמנטים הבודדים. כל חלון מכיל מספר סופי של רכיבים.
אתם מגדירים את חלונות הזמן הבאים באמצעות Apache Beam SDK:
- חלונות מתגלגלים (נקראים חלונות קבועים ב-Apache Beam)
- חלונות קופצים (נקראים חלונות הזזה ב-Apache Beam)
- חלונות של סשנים
חלונות מתגלגלים
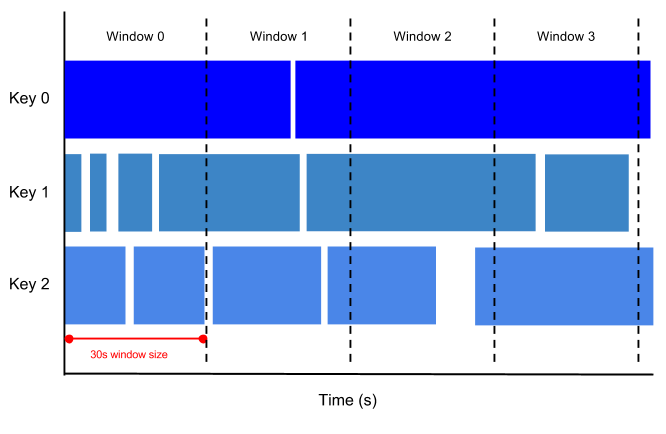
חלון עוקב (tumbling window) מייצג מרווח זמן עקבי ונפרד בזרם הנתונים.
לדוגמה, אם מגדירים חלון עוקב (tumbling window) של 30 שניות, הרכיבים עם ערכי חותמת הזמן [0:00:00-0:00:30) נמצאים בחלון הראשון. רכיבים עם ערכי חותמת זמן [0:00:30-0:01:00) נמצאים בחלון השני.
בתמונה הבאה אפשר לראות איך האלמנטים מחולקים לחלונות של 30 שניות.
חלונות קופצים
חלון קופץ מייצג מרווח זמן עקבי בזרם הנתונים. חלונות קופצים יכולים לחפוף, בעוד שחלונות מתגלגלים הם נפרדים.
לדוגמה, חלון קופץ יכול להתחיל כל 30 שניות ולתעד נתונים של דקה אחת. התדירות שבה מתחילים חלונות קופצים נקראת תקופה. בדוגמה הזו, חלון הזמן הוא דקה אחת והתקופה היא שלושים שניות.
בתמונה הבאה אפשר לראות איך הרכיבים מחולקים לחלונות של דקה אחת עם תקופה של 30 שניות.
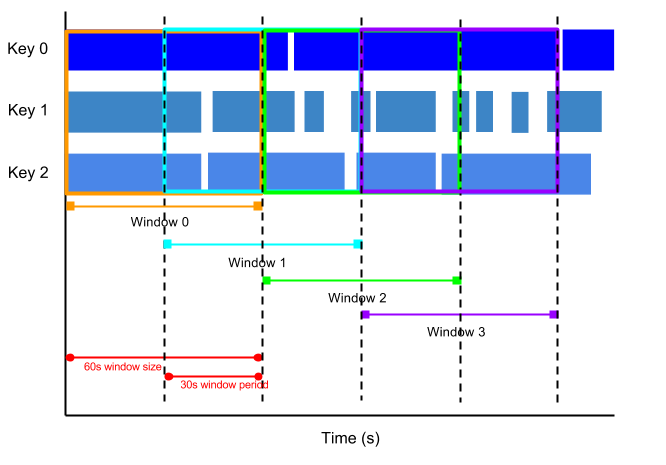
כדי לחשב ממוצעים נעים של נתונים, משתמשים בחלונות קופצים. אפשר להשתמש בחלונות של דקה אחת עם תקופה של 30 שניות כדי לחשב ממוצע נע של דקה אחת כל 30 שניות.
חלונות סשן
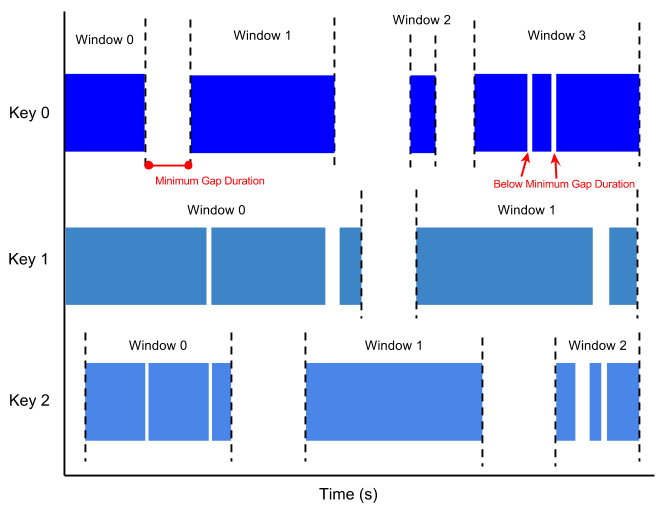
חלון סשן מכיל רכיבים בתוך משך הפער של רכיב אחר. משך הפער הוא מרווח הזמן בין נתונים חדשים במקור נתונים. אם הנתונים מגיעים אחרי משך הפער, הם משויכים לחלון חדש.
לדוגמה, חלונות סשן (session window) יכולים לחלק מקור נתונים שמייצג פעילות של עכבר המשתמש. יכול להיות שבמקור הנתונים הזה יהיו תקופות ארוכות של חוסר פעילות, שביניהן יהיו הרבה קליקים. חלון סשן (session window) יכול להכיל את הנתונים שנוצרו מהקליקים.
החלוקה לחלונות של סשנים מקצה חלונות שונים לכל מפתח נתונים. חלונות מתגלגלים וחלונות קופצים מכילים את כל הרכיבים במרווח הזמן שצוין, ללא קשר למפתחות הנתונים.
בתמונה הבאה אפשר לראות איך האלמנטים מחולקים לחלונות של סשנים.
סימני מים
סימן מים הוא סף שמציין מתי מערכת Dataflow מצפה שכל הנתונים בחלון יגיעו. אם סימן המים עבר את סוף החלון והגיעו נתונים חדשים עם חותמת זמן בתוך החלון, הנתונים נחשבים נתונים מאוחרים. מידע נוסף זמין במאמר Watermarks and late data (סימני מים ונתונים מאוחרים) במסמכי התיעוד של Apache Beam.
מערכת Dataflow עוקבת אחרי סימני מים מהסיבות הבאות:
- אין התחייבות שהנתונים יגיעו לפי סדר הזמן או במרווחי זמן צפויים.
- אין התחייבות שאירועי נתונים יופיעו בצינורות באותו סדר שבו הם נוצרו.
סימן המים נקבע לפי מקור הנתונים. אתם יכולים לאפשר נתונים מאוחרים באמצעות Apache Beam SDK.
טריגרים
טריגרים קובעים מתי לשלוח תוצאות מצטברות כשהנתונים מגיעים. כברירת מחדל, התוצאות מופקות כשסימן המים עובר את סוף החלון.
אפשר להשתמש ב-Apache Beam SDK כדי ליצור או לשנות טריגרים לכל אוסף בצינור להעברת נתונים בזמן אמת.
Apache Beam SDK יכול להגדיר טריגרים שפועלים על כל שילוב של התנאים הבאים:
- שעת האירוע, כפי שמצוין בחותמת הזמן של כל רכיב נתונים.
- זמן העיבוד, שהוא הזמן שבו רכיב הנתונים מעובד בכל שלב נתון בצינור העיבוד.
- מספר רכיבי הנתונים באוסף.
המאמרים הבאים
- סטרימינג – מדריך למתחילים: העולם שמעבר לעיבוד באצווה (בלוג)
- Streaming 102: The world beyond batch (בלוג)