
סביבות עבודה להמרות עוזרות לכם להמיר את הסכימה ואת האובייקטים ממסד הנתונים של המקור לתחביר SQL שתואם למסד הנתונים של היעד. בדף הזה יש סקירה כללית על סביבות עבודה להמרת נתונים ב-Database Migration Service:
סקירות כלליות של המרות מספקות חתך של התקדמות ההמרה בסכימה.
אובייקטים שנתמכים על ידי ההמרה הדטרמיניסטית של קוד וסכימה מפרטת אובייקטים של Oracle שנתמכים בהמרה דטרמיניסטית של סכימה.
במאמר עורך SQL אינטראקטיבי מוסבר אילו אובייקטים אפשר לשנות ישירות בעורך של סביבת העבודה להמרות.
תכונות המרה מבוססות-Gemini מסבירות איך אפשר לשלב תמיכה ב-AI גנרטיבי כדי לזרז את תהליך ההמרה של הסכימה.
בקטע קבצים למיפוי המרות מופיעה סקירה כללית של הנחיות ההתאמה האישית שבהן אפשר להשתמש כדי לבטל את הכללים של המרת סכימה דטרמיניסטית.
במאמר Legacy conversion workspaces מוסבר על סביבות עבודה מדור קודם שלא תומכות בעורך SQL אינטראקטיבי.
יש סוגי נתונים מסוימים שלא נתמכים בהעברות של Oracle. מידע נוסף זמין במאמר מגבלות ידועות על סוגי נתונים.
סקירות כלליות של התקדמות ההמרה
בסביבות העבודה של ההמרות מוצג מידע מקיף, שבעזרתו אפשר לקבל תובנות לגבי המספר הכולל של בעיות בהמרות שעדיין לא נפתרו או שכבר נפתרו, שיפורים שבוצעו בעזרת Gemini והתקינות הכללית של תהליך ההמרה.
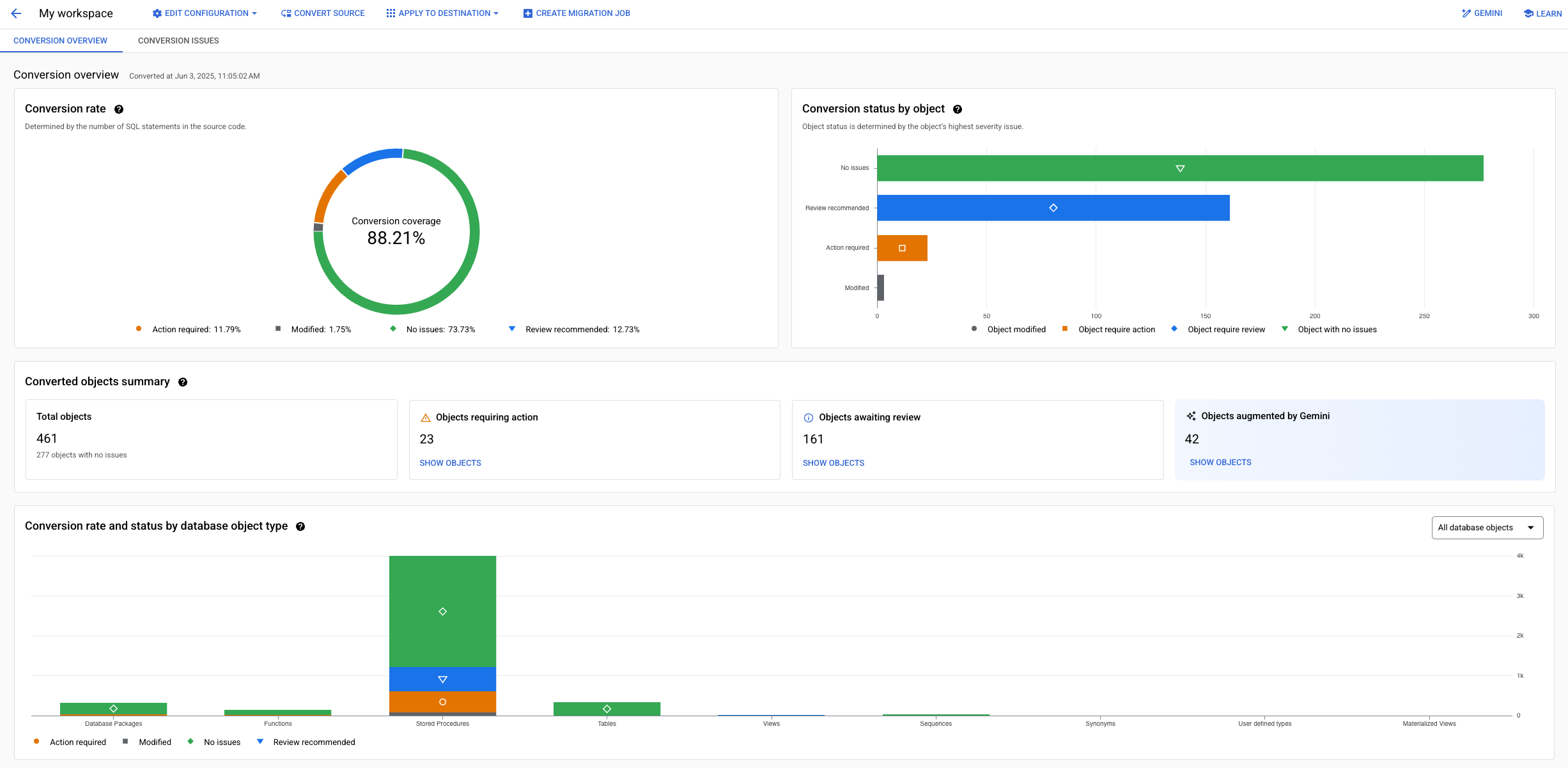
בתצוגה הזו אפשר לסנן אובייקטים בסכימה לפי סוג, חומרת הבעיה, פעולות שנדרשות או סטטוס ההמרה.

מידע נוסף על שימוש בתצוגות הכלליות של ההמרות כדי לבדוק את תוצאות ההמרות זמין במאמר שימוש בסביבות עבודה של המרות.
המרת קוד וסכימה דטרמיניסטית
כש יוצרים סביבת עבודה להמרת נתונים, שירות Database Migration Service מבצע באופן מיידי את ההמרה הראשונית של הסכימה באמצעות קבוצה של כללי המרה דטרמיניסטיים, שבהם סוגים ואובייקטים ספציפיים של נתונים ב-Oracle ממופים לסוגים ולאובייקטים ספציפיים של נתונים ב-PostgreSQL. התהליך הזה תומך בקבוצת משנה מאוד ספציפית של אובייקטים זמינים במסד נתונים של אורקל.
המרת קוד דטרמיניסטית מספקת תמיכה באובייקטים הבאים של מסד נתונים של Oracle:
רכיבי סכימה נתמכים של Oracle
- מגבלות
- אינדקסים (רק אינדקסים שנוצרו באותה סכימה כמו הטבלה שלהם)
- תצוגות מהותיות
- סוגי אובייקטים (תמיכה חלקית)
- רצפים
- מילים נרדפות
- Tables
- תצוגות
רכיבי קוד נתמכים של Oracle
- טריגרים (ברמת הטבלה בלבד)
- חבילות
- פונקציות
- נהלים מאוחסנים
עורך SQL אינטראקטיבי
בעורך ה-SQL האינטראקטיבי אפשר לשנות את תחביר PostgreSQL שהומר ישירות ב-Database Migration Service. אתם יכולים להשתמש בו כדי לפתור בעיות שקשורות להמרות או כדי להתאים את הסכימה לצרכים שלכם. אי אפשר לשנות חלק מהאובייקטים בכלי העריכה המובנה.
אובייקטים של Oracle שאפשר לערוך
אחרי שממירים את הקוד והסכימה של מסד הנתונים של המקור, אפשר להשתמש בכלי העריכה האינטראקטיבי כדי לשנות את ה-SQL שנוצר עבור סוגים מסוימים של אובייקטים. האובייקטים הבאים של Oracle נתמכים על ידי הכלי לעריכה:
- טריגרים של טבלה (נדרשת הרשאה)
- תצוגות מהותיות
- חבילות
- פונקציות, נהלים מאוחסנים
- מילים נרדפות
- תצוגות
- מגבלות
- מדדים
- רצפים
בנוסף, חלק מהאובייקטים מומרים אבל לא זמינים לעריכה ישירה ב-Database Migration Service. כדי לשנות אובייקטים כאלה, צריך לבצע את העדכונים ישירות במסד הנתונים של היעד אחרי שמחילים את הסכימה והקוד שהומרו.
אובייקטים שלא נתמכים לעריכה:
- סוגי אובייקטים שהמשתמש מגדיר
- Tables
- סכימות
המרת קוד וסכימות מהירה יותר עם Gemini
שירות העברת מסדי נתונים משלב את Gemini ל- Google Cloud בסביבות עבודה להמרה כדי לעזור לכם להאיץ ולשפר את תהליך ההמרה בתחומים הבאים:
כדי לשפר את התוצאות הדטרמיניסטיות של ההמרות, אפשר להשתמש בהמרה אוטומטית מבוססת-Gemini. כך תוכלו לנצל את יכולות ה-AI כדי לצמצם באופן משמעותי את מספר ההתאמות הידניות שנדרשות בקוד PostgreSQL.
אפשר להשתמש בהערכות איכות מבוססות-Gemini כדי לוודא שהקוד שהומר איכותי ושווה ערך מבחינת הפונקציונליות. במסגרת ההערכות האלה, המערכת מנתחת את הקוד שהומר ומספקת משוב על הנכונות והפונקציונליות שלו בהשוואה לקוד המקור.
העוזר להמרות מספק תכונות להסבר קוד: קבוצה של הנחיות ייעודיות שיכולות לעזור לכם להבין טוב יותר את לוגיקת ההמרה, להציע תיקונים לבעיות בהמרה או לבצע אופטימיזציה של קוד שהומר.
האצת תיקון בעיות בהמרות באמצעות הצעות להמרת קוד מ-Gemini: מנגנון שבו מודל Gemini יכול ללמוד תוך כדי תיקון בעיות בהמרות ולהציע שינויים באובייקטים פגומים אחרים בסביבת העבודה.
מידע נוסף על המרה באמצעות Gemini זמין בדפים הבאים:
קבצים של מיפוי המרות
אפשר להתאים אישית את לוגיקת ההמרה באמצעות קובץ מיפוי המרות. קובץ מיפוי ההמרות הוא קובץ טקסט שמכיל הוראות מדויקות (שנקראות הוראות המרה) להמרה של אובייקטים של Oracle לאובייקטים של PostgreSQL.
הוראות המרה נתמכות
Database Migration Service תומך בהנחיות ההמרה הבאות לקבצים של מיפוי המרות:
EXPORT_SCHEMA
EXPORT_SCHEMA היא הוראה שחובה להשתמש בה בכל קובצי מיפוי ההמרות. Database Migration Service מחייב את ההוראה הזו כדי לוודא שהסכימות של המקור מומרות לסכימות היעד הנכונות.
חשוב לוודא שקבצי מיפוי ההמרות כוללים את השורה הבאה:
EXPORT_SCHEMA 1
SCHEMA
Database Migration Service צריך להיות מסוגל לקבוע איזו סכימה מכילה את האובייקטים שצריך לשנות באמצעות הנחיות ההמרה.
ההנחיה SCHEMA גורמת לכל שאר ההנחיות להתאמה אישית שמופיעות בקובץ לחול על אובייקטים בסכימה הספציפית הזו.
- כשמשתמשים בהנחיה הזו, גם סכימות אחרות במסד הנתונים מומרות, אבל האובייקטים שלהן לא עוברים שינויים.
- אם כוללים את ההנחיה הזו בקובץ מיפוי ההמרות, כל ההתאמות האישיות חלות רק על אובייקטים שנכללים בסכימה הספציפית הזו.
- אם מדלגים על ההנחיה הזו, צריך לספק שמות אובייקטים שמוגדרים במלואם, כולל שם הסכימה של האובייקטים שמשתנים על ידי הנחיות אחרות להמרות.
לדוגמה, במקום להשתמש בהנחיה
SOURCE_TABLE_NAMEבשבילREPLACE_TABLES, צריך להשתמש בהנחיה"SCHEMA_NAME.SOURCE_TABLE_NAME". - כדי להתאים אישית אובייקטים בסכימות שונות, אפשר לנסות את הפעולות הבאות:
- יוצרים קובצי מיפוי המרות נפרדים לסכימות אחרות ומעלים אותם למרחב העבודה להמרות.
- צריך להשתמש בשמות אובייקטים מלאים שכוללים את שם הסכימה לאובייקטים שנמצאים בסכימות שונות מהסכימה שצוינה בהנחיה
SCHEMA.
צריך להשתמש בפורמט הבא:
SCHEMA SCHEMA_NAME
כאשר SCHEMA_NAME הוא שם הסכימה במסד הנתונים של המקור.
CASE_HANDLING
כברירת מחדל, Database Migration Service ממיר את כל שמות האובייקטים לאותיות קטנות.
אפשר להשתמש בהנחיית CASE_HANDLING כדי לשנות את ההתנהגות הזו.
- ההוראה הזו לא מושפעת מההוראה
SCHEMA. הוא פועל באופן גלובלי ומשפיע על כל האובייקטים בסביבת העבודה של ההמרות. - ההוראות
RENAME_*, MOVE_*ו-REPLACE_*מקבלות עדיפות על פני ההוראהCASE_HANDLING, והן משנות את השם של האובייקטים בדיוק כמו שהן, בלי קשר למאפייןCASE_HANDLING. - אם ההנחיה הזו קיימת בכמה קובצי תצורה עם ערכים סותרים, Database Migration Service יציג שגיאה במהלך ייבוא הסכימה.
צריך להשתמש בפורמט הבא:
CASE_HANDLING OPTION
הערך OPTION יכול להיות אחד מהערכים הבאים:
-
UPPERCASE: ממיר את כל שמות האובייקטים לאותיות רישיות. -
LOWERCASE: ממיר את כל שמות האובייקטים לאותיות קטנות (התנהגות ברירת המחדל). -
PRESERVE_ORIGINAL: שומר על האותיות הרישיות והקטנות המקוריות מסכימת המקור. האפשרות הזו שימושית אם האפליקציות שלכם משתמשות במזהים שרגישים לאותיות רישיות.
דוגמה:
CASE_HANDLING PRESERVE_ORIGINAL
GENERATE_MISSING_PK
בטבלאות ללא מפתחות ראשיים לא מובטחת שכפול עקבי. Database Migration Service מעביר רק טבלאות שיש להן מפתחות ראשיים. כברירת מחדל, כש ממירים את קוד המקור והסכימה, סביבות העבודה להמרה ב-Database Migration Service יוצרות אוטומטית את כל המפתחות הראשיים שחסרים בטבלאות היעד.
אפשר לשלוט ביצירה האוטומטית של המפתח הראשי באמצעות ההוראה GENERATE_MISSING_PK. כדי להשבית את יצירת המפתחות האוטומטית, מגדירים את ההנחיה הזו לערך 0.
דוגמה:
GENERATE_MISSING_PK 0
ההנחיה הזו משפיעה על כל האובייקטים בסביבת עבודה ספציפית של המרות. אי אפשר להשבית את היצירה האוטומטית של מפתח ראשי רק לטבלה ספציפית.
Database Migration Service יכול להעביר רק טבלאות שיש להן אילוצים של מפתח ראשי בגרסאות PostgreSQL המומרות שלהן. אם משביתים את היצירה האוטומטית של מפתחות ראשיים, צריך ליצור מפתחות ראשיים או אילוצים ייחודיים באופן ידני בטבלאות שהומרו במסד הנתונים של היעד אחרי שמחילים את הסכימה שהומרה. כדי לראות דוגמאות לפקודות SQL, מרחיבים את הקטעים הבאים.
יצירת מפתחות ראשיים באמצעות עמודות קיימות
יכול להיות שלטבלה כבר יש מפתח ראשי לוגי שמבוסס על עמודה או על שילוב של עמודות. לדוגמה, יכול להיות שיש עמודות עם אילוץ ייחודי או אינדקס מוגדר. משתמשים בעמודות האלה כדי ליצור מפתח ראשי חדש לטבלאות במסד הנתונים של המקור. לדוגמה:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME);
יצירת מפתח ראשי באמצעות כל העמודות
אם אין לכם אילוץ קיים שיכול לשמש כמפתח ראשי, אתם יכולים ליצור מפתחות ראשיים באמצעות כל העמודות בטבלה. חשוב לוודא שלא חורגים מהאורך המקסימלי של המפתח הראשי שמותר באשכול PostgreSQL. לדוגמה:
ALTER TABLE TABLE_NAME ADD PRIMARY KEY (COLUMN_NAME_1, COLUMN_NAME_2, COLUMN_NAME_3, ...);
כשיוצרים מפתח ראשי מורכב כמו זה, צריך לציין במפורש את כל שמות העמודות שרוצים להשתמש בהן. אי אפשר להשתמש בהצהרה כדי לאחזר את כל שמות העמודות למטרה הזו.
יצירת אילוץ ייחודי באמצעות פסאודו-עמודה ROWID
במסדי נתונים של Oracle נעשה שימוש ב
ROWID פסאודו-עמודה כדי לאחסן
את המיקום של כל שורה בטבלה. כדי להעביר טבלאות של Oracle שלא כוללות מפתחות ראשיים, אפשר להוסיף עמודה ROWIDבמסד הנתונים של PostgreSQL ביעד. Database Migration Service (שירות העברת מסד נתונים) מאכלס את העמודה עם הערכים המספריים התואמים מפסאודו-העמודה ROWID של Oracle במקור.
כדי להוסיף את העמודה ולהגדיר אותה כמפתח הראשי, מריצים את הפקודה הבאה:
ALTER TABLE TABLE_NAME ADD COLUMN rowid numeric(33,0) NOT NULL; CREATE SEQUENCE TABLE_NAME_rowid_seq INCREMENT BY -1 START WITH -1 OWNED BY TABLE_NAME.rowid; ALTER TABLE TABLE_NAME ALTER COLUMN rowid SET DEFAULT nextval('TABLE_NAME_rowid_seq'); ALTER TABLE TABLE_NAME ADD CONSTRAINT CONSTRAINT_DISPLAY_NAME PRIMARY KEY (rowid);
שינוי השם של אובייקטים (RENAME_*)
אפשר לשנות את השם של אובייקטים שונים במסד הנתונים במהלך ההמרה. Database Migration Service מעדכן אוטומטית את כל ההפניות לקוד (בתצוגות, בפרוצדורות מאוחסנות, בפונקציות וכו') כדי להשתמש בשמות החדשים.
תחביר כללי
RENAME_OBJECT_TYPE SOURCE_NAME1:DESTINATION_NAME1 SOURCE_NAME2:DESTINATION_NAME2 ...
שיקולים חשובים
-
ההוראות
RENAME_*הן תלויות באותיות רישיות בשם אובייקט היעד, והן מקבלות עדיפות על פני ההוראהCASE_HANDLING. לדוגמה, אם משתמשים בשתי ההוראות:SCHEMA MySchema CASE_HANDLING PRESERVE_ORIGINAL # Destination objects are renamed exactly # to 'SoMe_tAbLe' and 'RenamedView', respecting the case # despite the CASE_HANDLING directive RENAME_TABLES some_table:SoMe_tAbLe RENAME_VIEWS MyView:RenamedView
-
במקרה של
SOURCE_NAME, תמיד צריך להתייחס לשם האובייקט המקורי, גם אם משתמשים בהנחיות אחרות כמוMOVE_*. לדוגמה, אם רוצים לשנות את השם של אחד מאובייקטי התצוגה ולהעביר אותו לסכימה חדשה, צריך לציין את שם התצוגה המקורי בשני סוגי ההוראות:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- ההוראה
RENAME_TABLESמבטלת את ההוראהREPLACE_TABLESבקובץ יחיד. אם רוצים גם לשנות את השם של טבלה וגם להעביר אותה, מומלץ להשתמש בהנחיהMOVE_*במקום זאת. -
הפורמט המלא של המשתנה
SOURCE_NAMEתלוי בשאלה אם משתמשים גם בהוראהSCHEMA:- עם ההנחיה
SCHEMA: משתמשים בשמות לא מלאים, לדוגמהMyTable. - בלי ההנחיה
SCHEMA: צריך להשתמש בשמות מלאים, לדוגמהMySchema.MyTable.
- עם ההנחיה
הוראות RENAME_* הנתמכות
-
RENAME_SCHEMA: שינוי השם של סכימה.
קובץ תצורה יחיד יכול להכיל רק הנחיה אחת מסוגRENAME_SCHEMA. אם מציינים את הוראתSCHEMA, אפשר לשנות את השם של הסכימה המסוימת הזו בלבד באמצעותRENAME_SCHEMA. -
RENAME_TABLES: שינוי שם של טבלאות. המאפיין מחליף את הערך שלREPLACE_TABLESבאותו קובץ. -
RENAME_COLUMNS: שינוי שמות של עמודות בטבלאות. מבטל את ההנחיהREPLACE_COLSבאותו קובץ. צריך להשתמש בפורמט הבא:RENAME_COLUMNS TABLE1.SRC_COL:DEST_COL TABLE2.SRC_COL:DEST_COL
אם משתמשים בהוראה
SCHEMA, צריך להשתמש בשמות טבלאות לא מלאים. אם לא משתמשים בהוראהSCHEMA, צריך לכלול את השמות המלאים של הטבלאות, כמו SCHEMA.TABLE1. RENAME_VIEWSRENAME_MATERIALIZED_VIEWSRENAME_SEQUENCESRENAME_FUNCTIONSRENAME_STORED_PROCEDURESRENAME_TRIGGERS-
RENAME_PACKAGES: Database Migration Service ממיר חבילות של Oracle לסכימות של PostgreSQL. אם הסכימה שלכם מכילה חבילות עם שמות משותפים, יכול להיות שקוד PostgreSQL ייתקל בקונפליקטים של שמות כשינסה ליצור שתי סכימות עם אותו שם. כדי להימנע מהתנגשויות כאלה, אפשר להשתמש בהנחיה הזו.לדוגמה, אם יש לכם חבילות כמו
SALES.REPORTING_PKGו-HR.REPORTING_PKG, אתם יכולים לשנות את השמות שלהן לשמות ייחודיים:RENAME_PACKAGES SALES.UTILS:SALES_UTILS RENAME_PACKAGES HR.UTILS:HR_UTILS
RENAME_USER_DEFINED_TYPESכינוי זמין:
RENAME_UDTS.
הזזת אובייקטים (MOVE_*)
אפשר להעביר אובייקטים לסכימות שונות במסד הנתונים של היעד. האפשרות הזו שימושית לארגון מחדש של מבנה מסד הנתונים במהלך ההעברה. Database Migration Service מעדכן אוטומטית את כל ההפניות לקוד בתצוגות, בפרוצדורות מאוחסנות, בפונקציות וכו'.
תחביר כללי
MOVE_OBJECT_TYPE SOURCE_NAME1:DESTINATION_SCHEMA1 SOURCE_NAME2:DESTINATION_SCHEMA2 ...
שיקולים חשובים
-
במקרה של
SOURCE_NAME, תמיד צריך להתייחס לשם האובייקט המקורי, גם אם משתמשים בהנחיות אחרות כמוRENAME_*. לדוגמה, אם רוצים לשנות את השם של אחד מאובייקטי התצוגה ולהעביר אותו לסכימה חדשה, צריך לציין את שם התצוגה המקורי בשני סוגי ההוראות:RENAME_VIEWS MyView:MyRenamedView MOVE_VIEWS MyView:MyOtherSchema
- ההנחיה מצפה רק לשם
DESTINATION_SCHEMA, ולא לשם האובייקט המלא. -
הפורמט המלא של המשתנה
SOURCE_NAMEתלוי בשאלה אם משתמשים גם בהוראהSCHEMA:- עם ההנחיה
SCHEMA: משתמשים בשמות לא מלאים, לדוגמהMyTable. - בלי ההנחיה
SCHEMA: צריך להשתמש בשמות מלאים, לדוגמהMySchema.MyTable.
- עם ההנחיה
הוראות MOVE_* הנתמכות
-
MOVE_TABLES: מעבירה טבלאות לסכימה אחרת. ההגדרה הזו קודמת להגדרהREPLACE_TABLESכשמדובר בשינויים בסכימה בקובץ הגדרה יחיד. MOVE_VIEWSMOVE_MATERIALIZED_VIEWSMOVE_SEQUENCESMOVE_FUNCTIONSMOVE_STORED_PROCEDURESMOVE_USER_DEFINED_TYPESכינוי זמין:
MOVE_UDTS.
דוגמה: ארגון מחדש של סכימות
SCHEMA LegacyApp # Moves the 'LegacyApp.Users' and 'LegacyApp.Orders' tables # to the 'data' schema. MOVE_TABLES Users:data Orders:data # Moves the 'LegacyApp.CreateUser' and 'LegacyApp.ProcessOrder' # stored procedures to the 'api' schema MOVE_STORED_PROCEDURES CreateUser:api ProcessOrder:api # Moves the 'LegacyApp.SalesSummary' views to the 'reporting' schema MOVE_VIEWS SalesSummary:reporting
DATA_TYPE
אפשר להשתמש בהנחיה הזו כדי למפות באופן מפורש כל סוג נתונים נתמך בין תחביר Oracle לבין תחביר PostgreSQL. ההנחיה הזו
מצפה לקבל רשימה של מיפויים שמופרדים בפסיקים. ההגדרה כולה צריכה להיות בשורה אחת, אבל קובץ ההגדרות כולל כמה הנחיות DATA_TYPE. צריך להשתמש בפורמט הבא:
DATA_TYPE ORACLE_DATA_TYPE1:PGSQL_DATA_TYPE1 DATA_TYPE ORACLE_DATA_TYPE2:PGSQL_DATA_TYPE2...
כאשר ORACLE_DATA_TYPE ו-PGSQL_DATA_TYPE הם סוגי נתונים שנתמכים בגרסאות המתאימות של Oracle ו-PostgreSQL שבהן אתם משתמשים בהעברה. מידע על גרסאות נתמכות זמין במאמר סקירה כללית של התרחישים.
דוגמה:
DATA_TYPE REAL:double precision,SMALLINT:integer
מידע נוסף על סוגי נתונים של Oracle ו-PostgreSQL זמין במאמרים הבאים:
- סוגי הנתונים של Oracle במסמכי התיעוד של Oracle.
- סוגי נתונים של PostgreSQL בתיעוד של PostgreSQL.
MODIFY_TYPE
ההנחיה MODIFY_TYPE מאפשרת לכם לקבוע לאיזה סוג נתונים Database Migration Service ימיר עמודה ספציפית בטבלת המקור.
ההנחיה הזו מצפה לרשימה של מיפויים שמופרדים בפסיקים.
ההגדרה כולה צריכה להיות בשורה אחת, אבל קובץ ההגדרות שלך כולל כמה הנחיות MODIFY_TYPE.
צריך להשתמש בפורמט הבא:
MODIFY_TYPE SOURCE_TABLE_NAME1:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE MODIFY_TYPE SOURCE_TABLE_NAME2:COLUMN_NAME:EXPECTED_END_RESULT_DATA_TYPE...
כאשר:
- SOURCE_TABLE_NAME הוא שם הטבלה שמכילה את העמודה שבה רוצים לשנות את סוג הנתונים.
- COLUMN_NAME הוא שם העמודה שרוצים להתאים אישית את מיפוי ההמרות שלה.
- EXPECTED_END_RESULT_DATA_TYPE הוא סוג הנתונים של PostgreSQL שבו רוצים להשתמש בעמודה שהומרת.
דוגמה:
MODIFY_TYPE events:dates_and_times:DATETIME,users:pseudonym:TEXT
PG_INTEGER_TYPE
כברירת מחדל,השירות להעברת מסדי נתונים ממיר את הסוגים NUMBER(p,s)לסוג DECIMAL(p,s) של PostgreSQL.
אפשר לשנות את ההתנהגות הזו באמצעות ההוראה PG_INTEGER_TYPE. מגדירים את הערך שלו ל-1 ומכריחים את כל הסוגים NUMBER עם דיוק וקנה מידה (NUMBER(p,s)) להמרה לסוגים smallint, integer או bigint של PostgreSQL על סמך מספר הספרות של הדיוק.
צריך לכלול את ההגדרה הבאה בקובץ מיפוי ההמרות:
PG_INTEGER_TYPE 1
PG_NUMERIC_TYPE
מגדירים את ההנחיה הזו לערך 1 אם רוצים להמיר את כל סוגי NUMBER עם דיוק וקנה מידה (NUMBER(p,s)) לסוגי real או float ב-PostgreSQL (על סמך מספר הספרות אחרי הנקודה העשרונית).
אם מגדירים את ההנחיה הזו לערך 0, הערכים של NUMBER(p,s)
שומרים על הערך המקורי המדויק שלהם ומשתמשים בסוג הנתונים הפנימי של PostgreSQL.
צריך לכלול את ההגדרה הבאה בקובץ מיפוי ההמרות:
PG_NUMERIC_TYPE 1
DEFAULT_NUMERIC
ההגדרה של ברירת המחדל להמרות של NUMBERs ללא דיוק
משתנה בהתאם לשימוש גם בהנחיה
PG_INTEGER_TYPE:
- אם משתמשים בהוראה
PG_INTEGER, המערכת ממירה את הערכיםNUMBERs ללא דיוק לערכיםDECIMAL. - אם לא משתמשים בהנחיית
PG_INTEGER, ערכיNUMBERללא דיוק מומרים לערכיBIGINT.
אפשר לשנות את ההתנהגות הזו ולהשתמש בהנחיה DEFAULT_NUMERIC
כדי לציין באיזה סוג נתונים צריך להשתמש עבור סוגים NUMBER בלי לציין נקודות דיוק.
צריך להשתמש בפורמט הבא:
DEFAULT_NUMERIC POSTGRESQL_NUMERIC_DATA_TYPE
כאשר POSTGRESQL_NUMERIC_DATA_TYPE הוא אחד מהערכים הבאים: integer, smallint, bigint.
דוגמה:
DEFAULT_NUMERIC integer
REPLACE_COLS
אפשר להשתמש בהנחיית REPLACE_COLS כדי לשנות את השם של עמודות בסכימה שהומרה. ההנחיה הזו מצפה לקבל רשימה של מיפויים שמופרדים בפסיקים.
צריך להשתמש בפורמט הבא:
REPLACE_COLS SOURCE_TABLE_NAME1(SOURCE1_TABLE1_COLUMN_NAME1:DESTINATION_TABLE1_COLUMN_NAME1,SOURCE_TABLE1_COLUMN_NAME2:DESTINATION_TABLE1_COLUMN_NAME2),SOURCE_TABLE_NAME2(SOURCE_TABLE2_COLUMN_NAME1:DESTINATION_TABLE2_COLUMN_NAME1,SOURCE_TABLE2_COLUMN_NAME2:DESTINATION_TABLE2_COLUMN_NAME2)...
כאשר:
- SOURCE_TABLE_NAME הוא שם הטבלה שמכילה את העמודה שרוצים לשנות את השם שלה. אם לא משתמשים בהנחיה SCHEMA, צריך להשתמש בשם המלא של הטבלה:
SCHEMA_NAME.SOURCE_TABLE_NAME - SOURCE_COLUMN_NAME הוא שם העמודה במקור שרוצים לשנות את השם שלה.
- DESTINATION_COLUMN_NAME הוא השם החדש של העמודה שרוצים להשתמש בה בסכימה שהומרה.
דוגמה:
REPLACE_COLS events(dates_and_times:event_dates),users(pseudonym:nickname)
REPLACE_TABLES
אפשר להשתמש בהנחיית REPLACE_TABLES כדי לשנות את השם של טבלאות או להעביר אותן לסכימה חדשה. ההנחיה הזו מצפה לרשימה של מיפויים שמופרדים באמצעות רווחים. כדי לקבל מידע נוסף על התחביר של כל תרחיש שימוש, אפשר להרחיב את הקטעים הבאים.
אם לא משתמשים בהנחיית SCHEMA, צריך לוודא שמשתמשים בשמות המלאים של הטבלאות במירכאות גם למשתני המקור וגם למשתני היעד:
"SCHEMA_NAME.SOURCE_TABLE_NAME""SCHEMA_NAME.DESTINATION_TABLE_NAME"
שינוי השם של טבלאות
כדי לשנות את השם של טבלאות בסכימה שהומרה, משתמשים בפורמט הבא:
REPLACE_TABLES SOURCE_TABLE_NAME1:DESTINATION_TABLE_NAME1 SOURCE_TABLE_NAME2:DESTINATION_TABLE_NAME2
כאשר:
- SOURCE_TABLE_NAME הוא השם של טבלת המקור שרוצים לשנות את השם שלה בסכימה שהומרה.
- DESTINATION_TABLE_NAME הוא השם החדש של הטבלה שרוצים להשתמש בה בסכימה שהומרה.
דוגמה:
REPLACE_TABLES "events:login_events" "users:platform_users"
העברת טבלאות בין סכימות
אתם יכולים להשתמש בהנחיה הזו כדי להעביר טבלאות בין סכימות על ידי הוספת קידומת הסכימה לשם הטבלה החדש. אפשר להשתמש במנגנון הזה בלי קשר לאופן שבו משתמשים בהנחיה SCHEMA עבור קובץ ההמרה כולו. לדוגמה:
REPLACE_TABLES "events:NEW_SCHEMA_NAME.login_events"
כינויים להתאמה אישית של סוגי נתונים
כשמשתמשים בהוראות המרה כדי לשנות את האופן שבו Database Migration Service ממיר סוגי נתונים שונים (לדוגמה, באמצעות ההוראות
DATA_TYPE,
MODIFY_TYPE או
PG_NUMERIC_TYPE), אפשר להשתמש בשמות חלופיים במקום בסוגי הנתונים של SQL במקור.
כדי לראות את רשימת הכינויים של סוגי הנתונים שנתמכים על ידי Database Migration Service, מרחיבים את הקטע הבא.
כינויים של סוגי נתונים
| כינוי | הומר לסוג PostgreSQL |
|---|---|
bigint, int8 |
BIGINT |
bool, boolean |
BOOLEAN |
bytea |
BYTEA |
char, character |
CHAR |
character varying, varchar |
VARCHAR |
date |
DATE |
decimal, numeric |
DECIMAL |
double precision, float8 |
DOUBLE PRECISION |
real, float4 |
REAL |
int, integer, int4 |
INTEGER |
int2 |
SMALLINT |
interval |
INTERVAL |
json |
JSON |
smallint |
SMALLINT |
text |
TEXT |
time |
TIME |
timestamp |
TIMESTAMP |
timestamptz |
TIMESTAMPTZ |
timetz |
TIMETZ |
uuid |
UUID |
XML |
XML |
קובץ לדוגמה של מיפוי המרות
הנה קובץ מיפוי המרות לדוגמה שמשתמש בחלק מההנחיות הנתמכות להמרת סכימה:
EXPORT_SCHEMA 1 SCHEMA root # Preserve original casing for all objects CASE_HANDLING PRESERVE_ORIGINAL # Data type conversions PG_NUMERIC_TYPE 0 PG_INTEGER_TYPE 1 DEFAULT_NUMERIC integer DATA_TYPE NUMBER(4\,0):integer MODIFY_TYPE events:dates_and_times:TIMESTAMP # Renaming objects using the RENAME_* directives # These allow case-sensitive destination names RENAME_TABLES events:LoginEvents users:PlatformUsers RENAME_COLUMNS events.dates_and_times:EventDates users.pseudonym:Nickname RENAME_VIEWS InternalReport:FinInternalReport # Moving objects to new schemas using the MOVE_* directives MOVE_TABLES audit_log:archive MOVE_VIEWS InternalReport:reporting
התוצאות של השימוש בקובץ הזה הן:
EXPORT_SCHEMA 1היא הוראה נדרשת.-
SCHEMA rootגורם להחלת ההוראות האחרות על אובייקטים בסכימהroot, אלא אם נעשה שימוש בשמות מלאים. -
CASE_HANDLING PRESERVE_ORIGINALמוודא שכל שמות האובייקטים מסכימת המקורrootישמרו על האיות המקורי שלהם ביעד (אלא אם יש הוראהRENAME_*שמבטלת את זה). -
PG_INTEGER_TYPE 1גורם ל-Database Migration Service להמיר את כל סוגי הנתונים המספריים של Oracle שנמצאים בטבלאות בסכימהrootלסוגים ספציפיים של PostgreSQL במקום לסוגים מספריים ניידים של ANSI. DEFAULT_NUMERIC integerגורם ל-Database Migration Service להמיר ערכים שלNUMBERשלא צוינה להם נקודת דיוק לסוגINTEGERשל PostgreSQL.DATA_TYPE NUMBER(4\,0):integerגורם ל-Database Migration Service להמיר ערכים ספציפיים שלNUMBER(4,0)ל-PostgreSQLINTEGER.- ההנחיה
MODIFY_TYPE events:dates_and_times:TIMESTAMPגורמת ל-Database Migration Service להמיר את הנתונים בעמודהdates_and_timesבטבלת המקורeventsבאופן ספציפי לסוגTIMESTAMPשל PostgreSQL. RENAME_TABLES events:LoginEvents users:PlatformUsersמשנה את השם של הטבלאות, תוך שמירה על האיות שצוין:- השם של הטבלה
eventsשונה ל-LoginEvents. - השם של הטבלה
usersשונה ל-PlatformUsers.
- השם של הטבלה
RENAME_COLUMNS events.dates_and_times:EventDates user.pseudonym:Nicknameמשנה את השם של העמודות, תוך שמירה על האותיות הגדולות והקטנות שצוינו ביעד:- בטבלה
LoginEvents(השם המקוריevents), השם של עמודהdates_and_timesמשתנה ל-EventDates. - בעמודה
PlatformUsers(השם המקוריusers), השםpseudonymמשתנה ל-Nickname.
- בטבלה
-
RENAME_VIEWS InternalReport:FinInternalReportמשנה את השם של התצוגהInternalReportל-FinInternalReport. -
MOVE_TABLES audit_log:archiveמעביר את הטבלהaudit_logמהסכימהrootלסכימהarchive. -
MOVE_VIEWS InternalReport:reportingמעביר את התצוגהInternalReportלסכימהreporting. התצוגה הזו מקבלת גם את השםFinInternalReportבגלל ההוראהRENAME_VIEWS. Database Migration Service מטפל בתלות: קודם משנים את השם של האובייקט ואז מעבירים אותו.
סביבות עבודה מדור קודם להמרות
סביבות עבודה להמרות מדור קודם הן סוג ישן יותר ומוגבל יותר של סביבות עבודה להמרות. בסביבות עבודה להמרות מדור קודם אין תמיכה בתכונות המרה משופרות באמצעות Gemini או בכלי האינטראקטיבי לעריכת SQL. אפשר להשתמש בהם רק כדי להמיר את סכימת המקור באמצעות כלי ההעברה Ora2Pg.
אנחנו לא ממליצים להשתמש בסוג הישן של סביבות עבודה להמרות לצורך העברות. אם התרחיש שלכם מחייב שימוש בסביבות עבודה מדור קודם של המרות, אתם יכולים לעיין במאמר בנושא עבודה עם סביבות עבודה מדור קודם של המרות.
המאמרים הבאים
מידע על שימוש בסביבות עבודה של המרות