
שילוב עם SAP
במאמר הזה נסביר איך לשלב עומסי עבודה תפעוליים של SAP (SAP ECC ו-SAP S/4 HANA) ב-Cortex Framework Data Foundation. בעזרת Cortex Framework אפשר להאיץ את השילוב של נתוני SAP עם BigQuery באמצעות תבניות מוגדרות מראש לעיבוד נתונים עם צינורות עיבוד הנתונים של Dataflow עד ל-BigQuery. בנוסף, Managed Service for Apache Airflow מתזמן ומנטר את צינורות עיבוד הנתונים האלה של Dataflow כדי להפיק תובנות מנתוני התפעול של SAP.
קובץ config.json במאגר Cortex Framework Data Foundation מגדיר את ההגדרות הנדרשות להעברת נתונים מכל מקור נתונים, כולל SAP. הקובץ הזה מכיל את הפרמטרים הבאים של עומסי עבודה תפעוליים של SAP:
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
בטבלה הבאה מפורט הערך של כל פרמטר תפעולי של SAP:
| פרמטר | משמעות | ערך ברירת המחדל | תיאור |
SAP.deployCDC
|
פריסת CDC | true
|
ליצור סקריפטים לעיבוד CDC להרצה כ-DAG ב-Managed Airflow. |
SAP.datasets.raw
|
מערך נתונים גולמי של דפי נחיתה | - | כאן כלי השכפול מציב את הנתונים מ-SAP. אם משתמשים בנתוני בדיקה, יוצרים מערך נתונים ריק. |
SAP.datasets.cdc
|
מערך נתונים שעבר עיבוד ב-CDC | - | מערך נתונים שמשמש כמקור לתצוגות הדיווח, וכמטרה לרשומות שמעובדות ב-DAG. אם משתמשים בנתוני בדיקה, יוצרים מערך נתונים ריק. |
SAP.datasets.reporting
|
מערך נתונים לדיווח SAP | "REPORTING"
|
שם מערך הנתונים שמשתמשי הקצה יכולים לגשת אליו כדי ליצור דוחות, ושבו נפרסות תצוגות וטבלאות שמוצגות למשתמשים. |
SAP.SQLFlavor
|
גרסת SQL למערכת המקור | "ecc"
|
s4 או ecc.
לנתוני בדיקה, משאירים את ערך ברירת המחדל (ecc).
|
SAP.mandt
|
Mandant או לקוח | "100"
|
ברירת מחדל של לקוח או דייר ב-SAP.
לנתוני בדיקה, משאירים את ערך ברירת המחדל (100).
|
SAP.languages
|
מסנן שפה | ["E","S"]
|
קודי שפה של SAP (SPRAS) לשימוש בשדות רלוונטיים (כמו שמות). |
SAP.currencies
|
סינון לפי מטבע | ["USD"]
|
קודים של מטבעות יעד ב-SAP (TCURR) להמרת מטבעות. |
אין גרסה מינימלית של SAP שנדרשת, אבל מודלי ה-ECC פותחו בגרסה המוקדמת ביותר הנוכחית שנתמכת ב-SAP ECC. ההבדלים בשדות בין המערכת שלנו למערכות אחרות צפויים, ללא קשר לגרסה.
מודל נתונים
בקטע הזה מתוארים מודלי הנתונים של SAP (ECC ו-S/4 HANA) באמצעות דיאגרמות של קשרים בין ישויות (ERD).
SAP ECC

SAP S/4 HANA
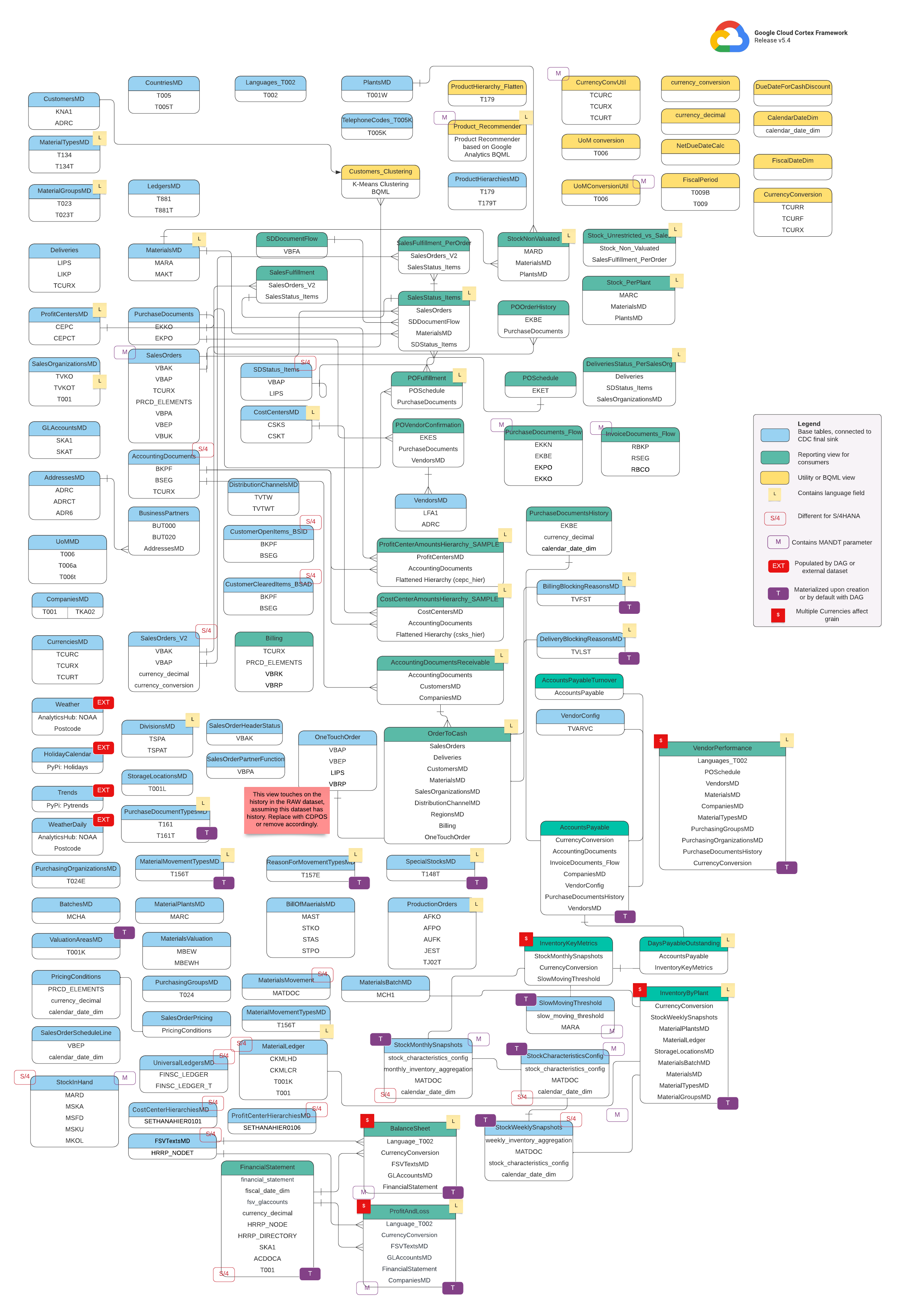
תצוגות בסיסיות
אלה האובייקטים הכחולים בתרשים ERD, והם תצוגות בטבלאות CDC ללא טרנספורמציות, מלבד כינויים מסוימים של שמות עמודות. אפשר לראות תסריטים ב-src/SAP/SAP_REPORTING.
תצוגות של דוחות
אלה האובייקטים הירוקים בתרשים ERD, והם מכילים את מאפייני המימד הרלוונטיים שמשמשים את טבלאות הדיווח. אפשר לראות תסריטים ב-src/SAP/SAP_REPORTING.
תצוגת כלי שירות או BQML
אלה האובייקטים הצהובים ב-ERD, והם מכילים את העובדות והמאפיינים המצורפים. זהו סוג ספציפי של תצוגה שמשמש לניתוח נתונים ולדיווח. אפשר לראות סקריפטים בכתובת src/SAP/SAP_REPORTING.
תגים נוספים
התגים עם קידוד הצבעים בתרשים הזה של ישויות וקשרים מייצגים את התכונות הבאות של טבלאות הדיווח:
| תג | צבע | תיאור |
L
|
צהוב | התג הזה מתייחס לרכיב נתונים או למאפיין שמציין את השפה שבה הנתונים מאוחסנים או מוצגים. |
S/4
|
אדום | התג הזה מציין שמאפיינים מסוימים ספציפיים ל-SAP S/4 HANA (יכול להיות שהאובייקט הזה לא נמצא ב-SAP ECC). |
MANDT
|
סגול | התג הזה מציין שמאפיינים ספציפיים מכילים את הפרמטר MANDT (מייצג את הלקוח או את מזהה הלקוח) כדי לקבוע לאיזה מופע של לקוח או חברה שייך רשומה ספציפית של נתונים. |
EXT
|
אדום | התג הזה מציין שאובייקטים ספציפיים מאוכלסים על ידי DAG או על ידי מערכי נתונים חיצוניים. המשמעות היא שהטבלה או הישות המסומנת לא מאוחסנות ישירות במערכת SAP עצמה, אבל אפשר לחלץ אותן ולטעון אותן ל-SAP באמצעות DAG או מנגנון אחר. |
T
|
סגול | התג הזה מציין שמאפיינים ספציפיים ימומשו באופן אוטומטי באמצעות ה-DAG שהוגדר. |
S
|
אדום | התג הזה מציין שהנתונים בישות או בטבלאות מושפעים מכמה מטבעות. |
דרישות מוקדמות לשכפול SAP
כדאי לשים לב לדרישות המוקדמות הבאות להעתקת נתונים מ-SAP באמצעות Cortex Framework Data Foundation:
- שלמות הנתונים: Cortex Framework Data Foundation מצפה ששכפול הטבלאות של SAP יתבצע עם שמות שדות, סוגים ומבני נתונים זהים לאלה שקיימים ב-SAP. כל עוד הטבלאות משוכפלות באותו פורמט, עם אותם שמות של שדות ועם אותה רמת פירוט כמו במקור, אין צורך להשתמש בכלי שכפול ספציפי.
- שמות טבלאות: שמות הטבלאות ב-BigQuery צריכים להיות באותיות קטנות.
- הגדרת הטבלה: רשימת הטבלאות שמשמשות מודלים של SAP זמינה וניתנת להגדרה בקובץ CDC (Change Data Capture)
cdc_settings.yaml. אם טבלה לא מופיעה במהלך הפריסה, המודלים שתלויים בה ייכשלו, אבל מודלים אחרים שלא תלויים בה ייפרסו בהצלחה. - שיקולים ספציפיים BigQuery Connector for SAP:
- מיפוי טבלאות: מידע על אפשרות ההמרה זמין במאמר בנושא מיפוי טבלאות שמוגדר כברירת מחדל.
- השבתת דחיסת רשומות: מומלץ להשבית דחיסת רשומות, כי היא עלולה להשפיע על שכבת ה-CDC של Cortex ועל מערך הנתונים של הדיווח ב-Cortex.
- שכפול מטא-נתונים: אם לא פורסים נתוני בדיקה ולא יוצרים סקריפטים של CDC DAG במהלך הפריסה, צריך לוודא שהטבלה
DD03Lשל מטא-נתוני SAP משוכפלת מ-SAP בפרויקט המקור. הטבלה הזו מכילה מטא-נתונים על טבלאות, כמו רשימת המפתחות, והיא נדרשת כדי שהכלי ליצירת CDC ופותר התלות יפעלו. בטבלה הזו אפשר גם להוסיף טבלאות שלא נכללות במודל, למשל טבלאות מותאמות אישית או טבלאות Z, כדי ליצור סקריפטים של CDC. טיפול בשינויים קלים בשם הטבלה: אם יש הבדלים קלים בשם הטבלה, יכול להיות שחלק מהתצוגות לא יצליחו למצוא את השדות הנדרשים, כי יכול להיות שבמערכות SAP יש שינויים קלים בגלל גרסאות או תוספים, או כי יכול להיות שבחלק מכלי השכפול יש טיפול שונה מעט בתווים מיוחדים. מומלץ להריץ את הפריסה עם
turboMode : falseכדי לזהות את רוב הכשלים בניסיון אחד. דוגמאות לבעיות נפוצות:- התווים
_מוסרים משדות שמתחילים ב-_(לדוגמה,_DATAAGING). - שמות של שדות ב-BigQuery לא יכולים להתחיל ב-
/. חשוב לעדכן את קוד יצירת הסקריפט של CDC בהתאם להגדרות השכפול.
במצב כזה, אפשר לשנות את התצוגה שנכשלה כדי לבחור את השדה כפי שהוא מופיע בכלי השכפול שבחרתם.
- התווים
שכפול נתונים גולמיים מ-SAP
המטרה של Data Foundation היא לחשוף נתונים ומודלים של ניתוח נתונים לצורך דיווח ואפליקציות. המודלים צורכים את הנתונים ששוכפלו ממערכת SAP באמצעות כלי שכפול מועדף, כמו הכלים שמפורטים במדריכים לשילוב נתונים ב-SAP.
הנתונים ממערכת SAP (ECC או S/4 HANA) משוכפלים בפורמט גולמי.
הנתונים מועתקים ישירות מ-SAP ל-BigQuery בלי שנעשים שינויים במבנה שלהם. היא למעשה תמונת מראה של הטבלאות במערכת SAP שלכם. במודל הנתונים של BigQuery, שמות הטבלאות הם באותיות קטנות. לכן, גם אם שמות הטבלאות ב-SAP הם באותיות רישיות (למשל MANDT), הם מומרים לאותיות קטנות (למשל mandt) ב-BigQuery.
עיבוד של סימון נתונים שהשתנו (CDC)
בוחרים באחד ממצבי העיבוד הבאים של CDC ש-Cortex Framework מציע לכלי שכפול לטעינת רשומות מ-SAP:
- Append-always: הוספת כל שינוי ברשומה עם חותמת זמן ודגל פעולה (Insert, Update, Delete), כך שאפשר לזהות את הגרסה האחרונה.
- עדכון כשמגיעים לדף (מיזוג או upsert): יצירת גרסה מעודכנת של רשומה כשמגיעים לדף ב-
change data capture processed. הוא מבצע את פעולת ה-CDC ב-BigQuery.
התכונה Cortex Framework Data Foundation תומכת בשני המצבים, אבל במצב append-always היא מספקת תבניות לעיבוד CDC. כדי לעדכן חלק מהיכולות, צריך להוסיף להן הערה. לדוגמה, OneTouchOrder.sql וכל השאילתות שתלויות בה. אפשר להחליף את היכולת הזו בטבלאות כמו CDPOS.

הגדרת תבניות CDC לכלי שכפול במצב 'תמיד מוסיפים'
מומלץ מאוד להגדיר את cdc_settings.yaml בהתאם לצרכים שלכם.
תדירויות ברירת מחדל מסוימות עלולות לגרום לעלויות מיותרות אם העסק לא צריך רמת עדכניות כזו של הנתונים. אם משתמשים בכלי שפועל במצב append-always, Cortex Framework Data Foundation מספק תבניות CDC לאוטומציה של העדכונים וליצירת גרסה עדכנית של האמת או תאום דיגיטלי במערך הנתונים שעבר עיבוד ב-CDC.
אפשר להשתמש בהגדרות שבקובץ cdc_settings.yaml אם צריך ליצור סקריפטים לעיבוד CDC. אפשרויות נוספות זמינות במאמר בנושא הגדרה של עיבוד CDC. לנתוני בדיקה, אפשר להשאיר את הקובץ הזה כברירת מחדל.
מבצעים את כל השינויים הנדרשים בתבניות DAG בהתאם למופע של Airflow או Managed Airflow. מידע נוסף זמין במאמר בנושא איסוף הגדרות של Managed Airflow.
אופציונלי: אם רוצים להוסיף ולעבד טבלאות בנפרד אחרי הפריסה, אפשר לשנות את הקובץ cdc_settings.yaml כדי לעבד רק את הטבלאות שצריך, ולהפעיל מחדש את קריאת המודול שצוינה src/SAP_CDC/cloudbuild.cdc.yaml ישירות.
הגדרת עיבוד של CDC
במהלך הפריסה, אפשר לבחור למזג שינויים בזמן אמת באמצעות תצוגה ב-BigQuery או לתזמן פעולת מיזוג ב-Managed Airflow (או בכל מופע אחר של Apache Airflow). ב-Managed Airflow אפשר לתזמן את הסקריפטים לעיבוד פעולות המיזוג באופן תקופתי. הנתונים מתעדכנים לגרסה העדכנית ביותר בכל פעם שפעולות המיזוג מופעלות, אבל פעולות מיזוג בתדירות גבוהה יותר מובילות לעלויות גבוהות יותר. אפשר להתאים אישית את התדירות המתוזמנת לפי הצרכים של העסק. מידע נוסף זמין במאמר בנושא תזמון שנתמך ב-Apache Airflow.
בדוגמה הבאה של סקריפט מוצג קטע מקובץ התצורה:
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
קובץ ההגדרות לדוגמה הזה מבצע את הפעולות הבאות:
- יצירת עותק מ-
SOURCE_PROJECT_ID.REPLICATED_DATASET.adrcאלTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc, אם האחרון לא קיים. - יוצרים סקריפט CDC בקטגוריה שצוינה.
- יצירת עותק מ-
SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6אלTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc, אם האחרון לא קיים. - יוצרים סקריפט CDC בקטגוריה שצוינה.
אם רוצים ליצור DAG או תצוגות בזמן ריצה כדי לעבד שינויים בטבלאות שקיימות ב-SAP ולא מופיעות בקובץ, צריך להוסיף אותן לקובץ הזה לפני הפריסה. הפעולה הזו תעבוד כל עוד הטבלה DD03L משוכפלת במערך הנתונים של המקור והסכמה של הטבלה המותאמת אישית מופיעה בטבלה הזו.
לדוגמה, התצורה הבאה יוצרת סקריפט CDC לטבלה מותאמת אישית zztable_customer ותצוגת זמן ריצה לסריקת שינויים בזמן אמת עבור טבלה מותאמת אישית אחרת שנקראת zzspecial_table:
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
תבנית לדוגמה שנוצרה
התבנית הבאה יוצרת את העיבוד של השינויים. בשלב הזה אפשר לשנות את השם של שדה חותמת הזמן או לבצע פעולות נוספות:
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
לחלופין, אם העסק שלכם דורש תובנות כמעט בזמן אמת וכלי השכפול תומך בכך, כלי הפריסה מקבל את האפשרות RUNTIME.
המשמעות היא שלא ייווצר סקריפט CDC. במקום זאת, תצוגה תסרוק ותביא את הרשומה הזמינה האחרונה בזמן הריצה כדי להשיג עקביות מיידית.
מבנה הספריות של קובצי ה-DAG והסקריפטים של CDC
המבנה של קטגוריית Cloud Storage עבור SAP CDC DAGs מצפה שקובצי ה-SQL ייווצרו ב-/data/bq_data_replication, כמו בדוגמה הבאה.
אפשר לשנות את הנתיב הזה לפני הפריסה. אם עדיין אין לכם סביבה של Managed Service for Apache Airflow, תוכלו ליצור אחת בהמשך ולהעביר את הקבצים אל מאגר ה-DAG.
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
הסקריפטים שמעבדים נתונים ב-Airflow או ב-Managed Service for Apache Airflow נוצרים בכוונה בנפרד מהסקריפטים הספציפיים ל-Airflow. כך תוכלו לנייד את הסקריפטים האלה לכלי אחר שתבחרו.
שדות CDC שנדרשים לפעולות מיזוג
מציינים את הפרמטרים הבאים ליצירה אוטומטית של תהליכי אצווה של CDC:
- פרויקט ומערך נתונים של המקור: מערך הנתונים שאליו מועברים או משוכפלים נתוני SAP. כדי שהסקריפטים של CDC יפעלו כברירת מחדל, בטבלאות צריך להיות שדה של חותמת זמן (שנקרא recordstamp) ושדה של פעולה עם הערכים הבאים, שמוגדרים במהלך השכפול:
- I: להוספה.
- U: לעדכון.
- D: למחיקה.
- Target project + dataset for the CDC processing (פרויקט יעד + מערך נתונים לעיבוד CDC): אם הטבלאות לא קיימות, הסקריפט שנוצר כברירת מחדל יוצר אותן מעותק של מערך הנתונים של המקור.
- טבלאות משוכפלות: טבלאות שצריך ליצור עבורן סקריפטים
- תדירות העיבוד: באיזו תדירות צפויים להפעיל את ה-DAG, בהתאם לסימון של Cron:
- קטגוריה של Cloud Storage שאליה מועתקים קובצי הפלט של CDC.
- שם החיבור: השם של החיבור שבו נעשה שימוש ב-Managed Airflow.
- (אופציונלי) שם טבלת היעד: האפשרות הזו זמינה אם התוצאה של עיבוד ה-CDC נשארת באותו מערך נתונים כמו היעד.
אופטימיזציה של הביצועים של טבלאות CDC
במערכי נתונים מסוימים של CDC, כדאי להשתמש בחלוקת טבלאות ב-BigQuery, באשכולות של טבלאות או בשניהם. הבחירה הזו תלויה בגורמים הבאים:
- גודל הטבלה והנתונים שלה.
- העמודות שזמינות בטבלה.
- צריך נתונים בזמן אמת עם תצוגות.
- נתונים שמוצגים כטבלאות.
כברירת מחדל, הגדרות ה-CDC לא חלות על חלוקת טבלאות למחיצות או על אשכול טבלאות.
אתם יכולים להגדיר את ההגדרות לפי מה שהכי מתאים לכם. כדי ליצור טבלאות עם מחיצות או אשכולות, מעדכנים את הקובץ cdc_settings.yaml עם ההגדרות הרלוונטיות. מידע נוסף זמין במאמרים בנושא חלוקה למחיצות בטבלה והגדרות אשכול.
- התכונה הזו רלוונטית רק כשמגדירים מערך נתונים ב-
cdc_settings.yamlלשכפול כטבלה (למשל,load_frequency = "@daily"), ולא כשמגדירים אותו כתצוגה (load_frequency = "RUNTIME"). - טבלה יכולה להיות גם טבלה מחולקת למחיצות וגם טבלה מקובצת לאשכולות.
אם אתם משתמשים בכלי שכפול שמאפשר מחיצות במערך הנתונים הגולמי, כמו BigQuery Connector for SAP, מומלץ להגדיר מחיצות מבוססות-זמן בטבלאות הגולמיות. סוג המחיצה מתאים יותר אם הוא תואם לתדירות של תרשימי ה-DAG של CDC בהגדרה cdc_settings.yaml
מידע נוסף זמין במאמר שיקולים לתכנון מידול נתוני SAP ב-BigQuery.
אופציונלי: הגדרת מודול המלאי של SAP
מודול המלאי של Cortex Framework SAP כולל תצוגות InventoryKeyMetrics
ו-InventoryByPlant שמספקות תובנות מרכזיות לגבי המלאי.
התצוגות האלה מבוססות על טבלאות של תמונות מצב חודשיות ושבועיות, שנוצרות באמצעות DAGs מיוחדים. אפשר להפעיל את שניהם בו-זמנית והם לא יפריעו אחד לשני.
כדי לעדכן את אחת מטבלאות התמונות או את שתיהן, פועלים לפי השלבים הבאים:
מעדכנים את
SlowMovingThreshold.sqlואתStockCharacteristicsConfig.sqlכדי להגדיר את ערך הסף של תנועה איטית ואת מאפייני המלאי לסוגים שונים של חומרים, בהתאם לדרישות שלכם.כדי לבצע טעינה ראשונית או רענון מלא, מריצים את קובצי ה-DAG
Stock_Monthly_Snapshots_Initialו-Stock_Weekly_Snapshots_Initial.לרענונים הבאים, מתזמנים או מריצים את ה-DAG הבאים:
- עדכונים חודשיים ושבועיים:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- עדכון יומי:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- עדכונים חודשיים ושבועיים:
כדי לראות את הנתונים המעודכנים, צריך לרענן את התצוגות של
StockMonthlySnapshotsושלStockWeeklySnapshots, ואז את התצוגות שלInventoryKeyMetricsושלInventoryByPlants.
אופציונלי: הגדרת התצוגה 'טקסטים של היררכיית מוצרים'
בתצוגה 'טקסטים של היררכיית מוצרים' מוצגים חומרים והיררכיות המוצרים שלהם בצורה שטוחה. אפשר להשתמש בטבלה שמתקבלת כדי להזין לתוסף Trends רשימה של מונחים לאחזור של מידת התעניינות לאורך זמן. כדי להגדיר את התצוגה הזו, פועלים לפי השלבים הבאים:
- צריך לשנות את הרמות בהיררכיה ואת השפה בקובץ
prod_hierarchy_texts.sql, מתחת לסמנים של## CORTEX-CUSTOMER. אם היררכיית המוצרים שלכם מכילה רמות נוספות, יכול להיות שתצטרכו להוסיף הצהרת SELECT נוספת בדומה לביטוי הטבלה הנפוץ
h1_h2_h3.יכול להיות שיהיו התאמות אישיות נוספות בהתאם למערכות המקור. מומלץ לשתף את המשתמשים העסקיים או את האנליסטים בשלב מוקדם בתהליך כדי שיעזרו לזהות את הבעיות האלה.
אופציונלי: הגדרת תצוגות של היררכיה שטוחה
החל מגרסה v6.0, Cortex Framework תומך בשיטוח ההיררכיה כתצוגות דיווח. זהו שיפור משמעותי לעומת הכלי הישן לביטול ההיררכיה, כי עכשיו הוא מבטל את ההיררכיה כולה, מבצע אופטימיזציה טובה יותר ל-S/4 באמצעות שימוש בטבלאות ספציפיות ל-S/4 במקום בטבלאות ECC מדור קודם, וגם משפר משמעותית את הביצועים.
סיכום של תצוגות דוחות
אלה התצוגות שקשורות להשטחת ההיררכיה:
| סוג ההיררכיה | טבלה שמכילה היררכיה שטוחה בלבד | תצוגות להמחשה של היררכיה שטוחה | לוגיקת שילוב של דוחות רווח והפסד באמצעות ההיררכיה הזו |
| גרסת דוח כספי (FSV) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| מרכז רווח | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| מרכז העלויות | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
כשמשתמשים בתצוגות של היררכיה שטוחה, חשוב לשים לב לנקודות הבאות:
- התצוגות של ההיררכיה הרגילה שוות מבחינה פונקציונלית לטבלאות שנוצרות על ידי הפתרון הישן של היררכיה רגילה.
- תצוגות הסקירה הכללית לא נפרסות כברירת מחדל כי הן נועדו להציג רק את הלוגיקה של ה-BI. אפשר למצוא את קוד המקור שלהם בספרייה
src/SAP/SAP_REPORTING.
הגדרת שטוח ההיררכיה
בהתאם להיררכיה שבה אתם עובדים, צריך להזין את פרמטרי הקלט הבאים:
| סוג ההיררכיה | פרמטר נדרש | שדה המקור (ECC) | שדה המקור (S4) |
| גרסת דוח כספי (FSV) | תרשים חשבונות | ktopl
|
nodecls
|
| שם ההיררכיה | versn
|
hryid
|
|
| מרכז רווח | הסיווג של הקבוצה | setclass
|
setclass
|
| יחידה ארגונית: אזור בקרה או מפתח נוסף לקבוצה. | subclass
|
subclass
|
|
| מרכז העלויות | הסיווג של הקבוצה | setclass
|
setclass
|
| יחידה ארגונית: אזור בקרה או מפתח נוסף לקבוצה. | subclass
|
subclass
|
אם אתם לא בטוחים לגבי הפרמטרים המדויקים, אתם יכולים לשאול יועץ SAP בתחום הכספים או הבקרה.
אחרי שהפרמטרים נאספים, מעדכנים את ההערות ## CORTEX-CUSTOMER בכל אחת מהספריות המתאימות, בהתאם לדרישות:
| סוג ההיררכיה | מיקום הקוד |
| גרסת דוח כספי (FSV) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| מרכז רווח | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| מרכז העלויות | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
אם רלוונטי, חשוב לעדכן את ## CORTEX-CUSTOMER התגובות בתצוגות הדיווח הרלוונטיות בספרייה src/SAP/SAP_REPORTING.
פרטי הפתרון
הטבלאות הבאות של מקורות משמשות להשטחת ההיררכיה:
| סוג ההיררכיה | טבלאות מקור (ECC) | טבלאות מקור (S4) |
| גרסת דוח כספי (FSV) |
|
|
| מרכז רווח |
|
|
| מרכז העלויות |
|
|
הדמיה של ההיררכיות
פתרון היררכיה שטוחה של SAP ב-Cortex משטח את כל ההיררכיה. אם רוצים ליצור ייצוג חזותי של ההיררכיה שנטענה, שיהיה דומה למה שמוצג בממשק המשתמש של SAP, צריך להריץ שאילתה על אחת מהתצוגות של ההיררכיות השטוחות עם התנאי IsLeafNode=True.
מעבר מפתרון ישן לשיטוח ההיררכיה
כדי לבצע מיגרציה מפתרון מורכב של היררכיה שטוחה לפני Cortex v6.0, מחליפים את הטבלאות כמו שמוצג בטבלה הבאה. חשוב לבדוק את שמות השדות כדי לוודא שהם מדויקים, כי חלק משמות השדות עברו שינוי קל. לדוגמה, prctr בטבלה cepc_hier
הופך ל-profitcenter בטבלה profit_centers.
| סוג ההיררכיה | להחליף את הטבלה הזו: | עם: |
| גרסת דוח כספי (FSV) | ska1_hier
|
fsv_glaccounts
|
| מרכז רווח | cepc_hier
|
profit_centers
|
| מרכז העלויות | csks_hier
|
cost_centers
|
אופציונלי: הגדרת מודול הכספים של SAP
מודול הכספים של Cortex Framework SAP כולל תצוגות FinancialStatement,
BalanceSheet ו-ProfitAndLoss שמספקות תובנות פיננסיות חשובות.
כדי לעדכן את טבלאות הנתונים הפיננסיים האלה, פועלים לפי השלבים הבאים:
לטעינה ראשונית
- אחרי הפריסה, מוודאים שמערך הנתונים של CDC מאוכלס בצורה תקינה (מריצים את כל ה-DAG של CDC לפי הצורך).
- מוודאים שתצוגות של היררכיה שטוחה מוגדרות בצורה נכונה לסוגי ההיררכיות שבהן אתם משתמשים (FSV, מרכז עלויות ומרכז רווח).
מריצים את תרשים ה-DAG
financial_statement_initial_load.אם הפריסה מתבצעת כטבלאות (מומלץ), צריך לרענן את הפריטים הבאים לפי הסדר על ידי הפעלת ה-DAG המתאים:
Financial_StatementsBalanceSheetsProfitAndLoss
לרענון תקופתי
- מוודאים שHierarchy Flattening Views מוגדרות כראוי ומעודכנות לסוגי ההיררכיות שבהן אתם משתמשים (FSV, מרכז עלויות ומרכז רווח).
תזמון או הפעלה של DAG
financial_statement_periodical_load.אם הפריסה מתבצעת כטבלאות (מומלץ), צריך לרענן את הפריטים הבאים לפי הסדר על ידי הפעלת ה-DAG המתאים:
Financial_StatementsBalanceSheetsProfitAndLoss
כדי להציג את הנתונים מהטבלאות האלה, אפשר לעיין בתצוגות הבאות של הסקירה הכללית:
ProfitAndLossOverview.sqlאם משתמשים בהיררכיית FSV.ProfitAndLossOverview_CostCenter.sqlאם אתם משתמשים בהיררכיית מרכזי עלות.-
ProfitAndLossOverview_ProfitCenter.sqlאם אתם משתמשים בהיררכיה של מרכז הרווח.
אופציונלי: הפעלת DAGs שתלויים במשימות
מסגרת Cortex מספקת באופן אופציונלי הגדרות מומלצות של תלות ברוב טבלאות ה-SQL של SAP (ECC ו-S/4 HANA), שבהן אפשר לעדכן את כל הטבלאות התלויות באמצעות DAG יחיד. אפשר להתאים אותם אישית. מידע נוסף זמין במאמר בנושא Task dependent DAGs.
מה השלב הבא?
- מידע נוסף על מקורות נתונים ועומסי עבודה אחרים זמין במאמר מקורות נתונים ועומסי עבודה.
- מידע נוסף על השלבים לפריסה בסביבות ייצור זמין במאמר דרישות מוקדמות לפריסת Cortex Framework Data Foundation.